| Log In | Not a Member? |
Support
|
|
|
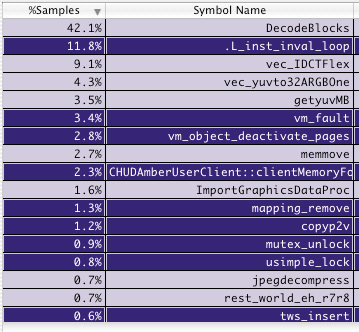
Quick Start Guide for AltiVecThis section is for developers who want to get started quickly with AltiVec. We begin with a few words about optimization. We present a road map for adding vector code to your application by simply calling our vectorized libraries. Next we outline steps required to start writing your own AltiVec code, and finally devote a few words to the many pages provided to help you write top speed vector code on this site.Notes About OptimizationMost applications will see dramatic performance gains by optimizing only a small number of key functions. It is usually not productive, and sometimes counter-productive to optimize everything. This is because often only a small handful of functions are responsible for the vast majority of the CPU time used by your application. Optimizing code that is never or rarely executed wastes your time and frequently results in larger functions that needlessly take up more system resources. The good news is that this means that just a little bit of work applied to the right functions will likely result in large improvements in overall speed.Because only a small number of your application's functions are relevant to its performance, it is important to take a scientific, data-driven approach to optimizing your application. Choosing which functions to optimize based on a best guess or gut feeling is usually not successful, because such approaches lead to incorrect guesses. (Common sense: you likely have already fixed those parts of your application that you knew were going to be too slow.) Instead, find high level tasks that are perceived to be too slow by the user, and collect information about why they run slowly using a profiler such as gprof or a sampling utility such as Sampler and Shark (from the CHUD toolkit). Use the output timing / sampling data to determine which functions to optimize based on which ones use the most CPU time. Here is a more complete description of available tools for measuring performance. Here is some sample Shark output from an application that decodes JPEG images:
Shark stops the application every few milliseconds and records what function is currently executing. Do this enough times and you have a statistical representation of how much CPU time is spent in each function. The left column is the number of times Shark stopped the application and found it in a particular function. The right column is the function name. Focus on optimizing the functions that use the most CPU time. In this case, you might choose to optimize the DecodeBlocks function, which uses 42.1% of the CPU time used by this application. If we are able to optimize that so that it only takes 10% of the CPU, then the entire application will be running at (100% / (100% - 42.1% + 10%)) = 147% of its previous speed, a 47% improvement. That is pretty good for just optimizing one function. When you are done, run the timing experiment again and see if any other functions look to be likely optimization candidates. Repeat as often as necessary until performance is satisfactory.
Libraries You Can CallIf you are a developer who would like to make more use of AltiVec in your application, you should first explore the functionality that is available in Apple's Accelerate.framework (previously available as vecLib.framework). This framework can be found in /System/Library/Frameworks on any MacOS X installation. There you will find many highly optimized routines for a diversity of tasks. There are single and double precision FFTs. Some of these are up to five times faster than FFT-W. There are also convolutions, 1D and 2D matrix operations and much, much more. MacOS X.2 (Jaguar) rounds this out with a full BLAS and LAPACK implementation in both single and double precision. These functions also work on G3 and earlier processors, meaning that you can call them safely regardless of what machine you are running on. The following table enumerates library functions that may be used immediately without writing AltiVec code.
To link against vecLib.framework using GCC, use the -framework vecLib flag. Here are some examples:
If you use another compiler, please consult your compiler vendor about how best to link to Apple frameworks. FORTRAN users will wish to see the "Getting Started in Fortran" page. The Accelerate.framework is a standard part of every MacOS X.3, Panther, installation.
Writing Your Own AltiVec CodeThe first thing you need to do is set up your compiler to accept the AltiVec C API. A tutorial on how to write a simple AltiVec application using GCC, Project Builder or Metrowerks CodeWarrior can be found here. For other compilers, please consult with your compiler vendor about how best to use AltiVec. Unlike some other vector implementations, you do not need to program AltiVec using assembly language. A description of the AltiVec C programmers interface with some additional details is available. This interface will allow you to program AltiVec from C, C++ and Objective C. Here is a complete reference on the various AltiVec operations (select the AltiVec PIM) available to you. We have them separately listed by category too. There are also additional materials like white papers from Apple's Advanced Computation Group on specific topics, and an AltiVec presentation. In addition, you may find further educational materials provided by third parties and an active independent mailing list for AltiVec at simdtech.org. AltiVec has some data alignment constraints of which you should be aware. Finally, we have a discussion of how best to make sure that programs that use AltiVec work properly on processors that do not have a AltiVec unit, such as the G3. Developers looking to write their own AltiVec accelerated functions will find vectorized versions of many math library functions in vecLib.framework. Examples include vectorized versions of functions like sine, cosine, power and square root. In addition, vecLib also provides functions for handling large integers. A white paper about mutiprecision arithmetic is also available. Apple provides AltiVec sample code too.
Improving Your Vector CodeThe pages to follow present information that we think is important to master on your way to becoming a world class vector programmer. Certainly, you need know little to none of this information to simply use the vector unit. However, if you want to be sure you are getting the most out of the processor, they should help you better understand the basic ground rules for speed. The Single Instruction Multiple Data approach reorganizes data in a way similar to how object oriented programming reorganizes data. Using both to full effect in many cases requires a change in how you think about and approach data and the use of data in certain programming problems. The Performance sections starts with a basic discussion about how best to think about and use SIMD. Next is a description of efficient ways to organize and handle larger data structures beyond the size of a single AltiVec vector, followed by a discussion of factors that contribute to the rate at which you can move data in and out of the processor. In some cases, the speed of your code will be limited by the speed of data flow in and out of the processor than by the speed of the AltiVec unit, itself. Next we present a discussion of function throughput and latency, and what factors contribute to each. Most AltiVec functions (the fast ones, anyway) operate on very large amounts of data. For these functions, throughput is the most important factor contributing to overall application speed. Finally, we conclude with some tips for micro-optimizing code and a list of some fast vector algorithms for selected tasks. New for the G5 is a segment about G5 specific details that you should be aware of for writing high performance code for the PowerPC 970. We've also added a discussion about FORTRAN. Other Resources Developers interested in performance should also examine:
Performance Reference Library
|
|
Get information on Apple products. Copyright © 2008 Apple Computer, Inc. |