| Log In | Not a Member? |
Support
|
|
Performance MeasurementProgramming for a vector machine is not as transparent as writing for a normal scalar microprocessor, which makes performance evaluation tools indispensable. To this end, the following collection of tools have been made available to assist programmers in AltiVec performance checking. They are provided by Apple, IBM and Motorola:
The MacOS X native command line version of Sim_G4, amber and the other CHUD tools are part of the Computer Hardware Understanding Developer kit (CHUD). MONster and Shark are most suitable for applications level or OS level performance measurement. They are a good way of identifying which applications or which functions might benefit from performance tuning and why. As such they are somewhat above the scope of the sorts of optimizations discussed here. These are the sorts of tools you should use first to discover what to vectorize. The actual process of verifying that your optimizations are working as intended however relies much more heavily on trace utilities and simulators like Sim_G4 and Acid. As these can be highly information rich, we will describe here in detail how to use them and how to interpret the results. Machine SetupUsing these tools is relatively simple. The following are the steps involved in generating the profile of a program to study the performance of a given program. The following is a step by step description of the use of these tools. Amber is a MacOS X command line application that may be used to prepare TT6e traces on that operating system. It may be used to trace any application without recompiling, as long as that application can be executed from the command line.
A somewhat more complete set of options might include:
The -I option tells amber to start sampling in response to an illegal or supervisor level instruction (e.g. mfspr result, 1023) and to stay on the thread that issued the illegal instruction. The -x 5000 option will tell it to stop sampling after 5000 instructions. For a CFM Carbon app, you'll need to use LaunchCFMApp to launch the app (this is all one line):
As TT6 traces can be very large and slow to gather, amber provides two ways to instrument just the select portions of the application that you are interested. From the command line you can specify a starting and stopping address to begin and end the trace using the -b and -e options. In addition, using the -i or -I flag, you may instruct amber to start and stop in response to supervisor level instructions. Identifying Poor PerformersFirst you must know where the performance problems lie inside your application. You will be most successful if you rigorously identify the causes for performance problems before attempting code changes. When you actually know the precise causes of code inefficiency, you may be able to achieve two to three fold performance increases by simple microoptimization of the function. This is a significant advantage over the usual 20-40% improvements cited for scalar code optimization.To make the process of gathering high quality information on code performance as efficient as possible, Apple provides the CHUD toolkit for OS X. It contains a suite of tools, a kernel extension (kext) and a framework that help you identify which functions in your application are consuming a lot of time, and why. In addition to its simple profiler like abilities, you can use the CHUD tools to survey your application for specific problems like unaligned floating point accesses, L1 data cache misses or branch misprediction. CHUD makes use of the G4's hardware performance monitor registers to count hundreds of different kinds of events ( such as branch mispredictions, L1 data cache misses, AltiVec floating point instructions, ICQ full, etc.) without appreciably slowing down your application. Once you have identified specific functions that have performance problems, you can generate a trace of the function using Amber or pitsTT6Lib, which may be used with SimG4 to generate a cycle accurate report of exactly how that function executes on a PPC 7400 or 7410, on an instruction by instruction basis. This will enable you to quickly and precisely identify causes for stalls and opportunities for more speed. Generating a Trace File with Amber
You can generate a trace file with the amber -i option, by writing your own
Note that under normal operation, if you simply start you application from the command line, Analyzing the ResultsInstruction Execution and TimingThe PowerPC processor has many separate instruction execution units that can operate concurrently, thereby providing the potential for a great deal of execution parallelism. For anyone seeking to optimize program execution, the tools to analyze execution timing have been provided. Sim_G4 is a cycle-accurate process analyzer that can be used for this purpose. Before describing how to use and interpret Sim_G4 output, it is necessary to achieve a basic understanding of how the G4 processor executes instructions. Each instruction passes through four phases: the Fetch Phase, the Dispatch Phase, the Execute Phase and the Completion Phase. The fetch, dispatch, and completion phases are performed by the Control Unit, whereas the execution phase is performed by one of the six Execution Units. The Fetch PhaseIn this phase an instruction is fetched from memory into a buffer to prepare for dispatch. There are two dispatch buffers, so two instructions can be ready for dispatch at the same time. The Dispatch PhaseIn this phase an instruction is moved from one of the dispatch buffers to the portal of the appropriate execution unit. At the same time the necessary operands are fetched from cache. The execution unit used depends on the type of instruction. This process takes one machine cycle on a PowerPC 7400, and up to two instructions may be dispatched per cycle. On a PowerPC 7450, 3 instructions can be dispatched per cycle and on a PowerPC 970 (G5) four instructions can be dispatched per cycle, plus one additional branch instruction. Before an instruction can be dispatched, it must be assigned a rename register to hold the results, and needs a slot in the Instruction Completion Queue. If either there are no available rename registers (7400 has 6, 7450 has 16 and G5 has 48) then the instruction will stall here, blocking instructions behind it.Similarly if the processor runs out of instruction completion queue slots (7400 has 8, 7450 has 16) or available instruction groups (G5 has 20) it will also stall. The Issue PhaseThis phase doesn't show up on simg4, but is a part of the G5. In front of each execution unit on a 970, there is a queue where dispatched instructions reside until the data that they need becomes available so that they can execute. While the G4 is considered an out of order execution machine, the instructions dispatched to a particular execution unit all execute in the order that they appear in the instruction stream. This is not necessarily true on a G5, where instructions may be delayed in the issue queue and other instructions can move past them and execute if they are ready. Also the G5 has two load store units (LSU) and two floating point units (FPU) so instructions can pass one another that way too. Each LSU or FPU has a separate issue queue. Execution PhaseIn this phase the instruction is actually executed by the execution unit to which it was dispatched. Different execution units have different numbers of stages through which the instruction must pass. If an instruction has completed one stage and another instruction is ready for that stage, it will proceed to execute. When the final stage of an execution unit for a particular instruction has executed, that instruction is said to be finished and can enter the Completion Phase. The Execution UnitsThere are seven execution units that can perform concurrently on a 7400:
The 7450 has:
The 970 (G5) has:
The VALU is divided into three sub-units, only one of which can begin execution each cycle:
The Execution TimingEach execution unit has a particular number of stages required to complete an instruction. In most cases, including all vector instructions, each stage requires a single cycle; therefore the number of cycles and the number of stages are equal. There are some exceptions, however, such as the fixed-point divide instruction, which takes 19 cycles on a 7400. The following table shows the number of stages required by each execution unit and the worst-case cycle times for each unit, not including exceptional circumstances such as divides or cache misses. The last stage of execution leaves the instruction in a finished or retired state.
In general, these values can be used to determine how much parallelism you need to use in your code to keep the execution units busy. Please be aware that some machines have more than one of a particular execution unit. For example, the G5 has two floating point units. You would need (2 floating point units * 6 cycle pipeline latency =) 12 independent instructions executing in parallel to keep them busy. When unrolling, typically one should unroll as much as is reasonably possible. Future processors are likely to have longer pipelines than current processors. This should help make sure that your code scales linearly with processor frequency on new machines. The cost of unrolling too much is small as long as you don't run out of registers. The cost of unrolling too little can be quite large due to data dependency stalls. The Completion PhaseIn this phase the instruction result is copied from the rename register back to the architected register, the instruction is retired (R) and the rename and instruction completion queue slots are returned to the free pools. An instruction can only complete if the instruction ahead of it in the instruction completion queue has completed. This makes sure that the program executes in the order that is intended, but can also make for long stalls if one instruction takes a long time. In the case of a cache miss for a load instruction, for example, the load instruction can stall for potentially hundreds of cycles. Since nothing can move past it in the instruction completion queue, the load will eventually make its way to the head of the queue and stay there, blocking instructions behind it from completing. Within a few cycles the instruction completion queue will fill up, preventing more instructions from being dispatched. On the G5, all instructions in the instruction group must finish execution before the instruction group can be retired. Analyzing The Timing with SimG4Sim_G4 analyzes the tt6e-formatted trace file from the execution of a program on the G4 processor in order to provide execution and timing information about that program. SimG4 can run from the MacOS X terminal prompt as:
Sim_G4 can run as a stand-alone application or as an MPW command. If invoked by MPW, the parameters are entered in the standard MPW command format. For example,
If the GUI application is used, parameters are entered into two Macintosh dialog boxes, one for command line options and one for simulation parameters. The various options and parameters are described in the Sim_G4 User's Guide. This page discusses the options and parameters that are most commonly needed for AltiVec program analysis. 1. General Options
2. Scrollpipe Output Options
3. Completion Report Options
4. Completion Report Options
A simple execution of Sim_G4 with no parameters other than the .tt6 input file produces a report with a great deal of information: number of clock cycles required for execution of the traced code, instruction flow statistics, dispatch stalls, execution unit stalls, etc. By invoking the output scrollpipe options, Sim_G4 will generate a file showing an instruction-by-instruction execution analysis in one of two possible formats: horizontal, depicting one instruction per line; or vertical, depicting one cycle per line. These outputs provide a detailed visual representation of the execution characeristics of your traced program; they can be very helpful in determining how performance can be improved. Here we will use the packAndUnpackPixel routine, contained in Programming Examples, to demonstrate how scrollpipe information is presented and interpreted. The source code is as follows: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

Since execution tracing is on, a file named PackAndUnpackPixel.tt6 is generated. You can now use Sim_G4 to generate a pipeline file. We will generate a vertical file using the following steps:
|
|
1. |
Launch Sim_G4. |
|
|
2. |
Select Command Line Options from the Configuration Menu. |
|
|
3. |
Check the -sp option and type in the name of the file to contain the pipeline output. If there are any spaces in the name, enclose it in quotes ("). |
|
|
4. |
Check the -st option and enter 0 for horizontal pipeline output, 1 for vertical. |
|
|
5. |
Click OK. |
|
|
6. |
Select Open TT6 File from the File Menu |
|
|
7. |
Select the TT6 file of interest. |
The file you specified in step 3 will be generated. The vertical pipeline output is shown below; several labels and comments have been added to assist understanding:
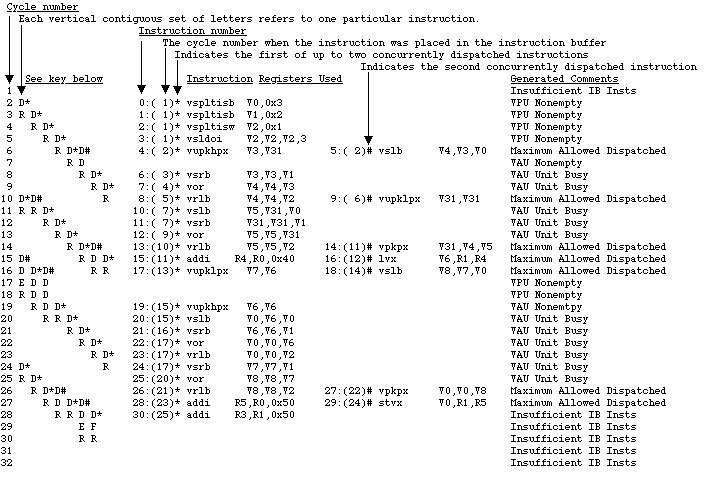

The Completion Cycle Report The completion cycle report is enabled with the -oc flag. This report contains the clock cycles during which instructions are completed. The default format is a binary format consisting of 4 bytes for each instruction completion cycle. The instruction order in the output file is identical to that of the order of the input instruction trace. A more detailed format is also available (using the -cf option) that includes the instruction address, opcode and completion cycle. Outputting the report in ASCII text is done by adding the -ca option. Using the ASCII output also reports the original instruction mnemonic. Using the both the -cf and -ca options (or by using the -cfa option) would produce a file of the following format:
For information about the PowerPC 970 (G5) cycle accurate simulator, please see the G5 page. |
||||||||||||||||||||

|
Get information on Apple products. Copyright © 2008 Apple Computer, Inc. |