| Log In | Not a Member? |
Support
|
|
|
Algorithms and Special TopicsHere you will find a series of tricks, tips and some perhaps non-obvious ways to micro-optimize code. In addition are also presented how to do a few common tasks like integer division, single precision floating point division and square roots. Division and Square Root (AltiVec) Division and Square Root (AltiVec)AltiVec provides estimator instructions for both reciprocals and reciprocal square roots. To get the full precision reciprocal and reciprocal square root (within a few bits), you have to do one round of Newton-Raphson refinement. To get something that is close to the correctly rounded IEEE result (with a infrequent 1-2 ulp error), a second round of Newton-Raphson iteration is used using the result as the new estimate.
Please note that these functions should not be considered IEEE-754 correct. Not only are they typically off by a few ulps, their edge case behavior may be very different. For example, division by zero may return a NaN instead of Inf. Integer division is a bit trickier. There is no good way to either do integer division or generate an integer reciprocal directly. If you need to do these, the best thing to do is to use the VFPU to generate a reciprocal. In some cases, it is best to also do the following multiplication in the VFPU as A * (1/B), as the precision is greater. However, if you need to divide a series of integers by the same value and 12-15 bits of precision is enough, then in many cases you may find vec_mradds() to be better. Because this gives you 8-way parallelism, it is potentially twice as fast. In addition, you don't have to suffer the overhead of conversion to float and back. The following sample will divide an array of vector shorts by another vector short. We didn't bother with doing a Newton-Raphson optimization on the reciprocal because the extra three bits only survive the conversion to integer space if your input value is between -7 and 7. If you feel you need the added precision, then you can easily substitute the Reciprocal() function above, where vec_re() appears here:
Integer square roots are best done in the FPU. Apple provides a suite of correctly rounded integer divides in vecLib.framework. These are available in signed and unsigned variants from 8 bit integers up to 1024 bit integers. See headers vBasicOps.h and vBigNum.h. Square Root and Reciprocal Square Root (Scalar)Those interested in square roots in the scalar domain would be happy to know that the techniques used for AltiVec above may be used there as well. The standard libm (a.k.a. MathLib) sqrt() function could be faster if you are willing to be a little bit sloppy with your calculations. The least significant bit from a Newton-Raphson result is often wrong, so Newton-Raphson can not be used to generate a IEEE result from fsqrte, but if you don't need that last bit, it could be used to generate a result that is perfectly fine for your application. Second, math.h specifies sqrt() return the square root of a single value. This calculation leaves the processor somewhat data starved. You can get much better performance if you write your own functions to do three square roots simultaneously, providing significant performance advantages. Best of all, you can tune the function to give you the best trade off between accuracy and speed. Please note that these functions are tune for the G3 and PowerPC 7400 and 7410, which have a 3 cycle FPU pipeline. For PowerPC 7450 and 7455, which have a five cycle FPU pipeline you may find some performance advantage to doing four or five square roots simultaneously. If a zero is a possible input for inverse square root, then the algorithms described above should be modified as follows to avoid getting a NaN: #if defined( __GNUC__ ) inline float FastScalarInvSqrt( float f )
} Fast Floor (Scalar)AltiVec has a floor() instruction for floating point work, but frequently developers find they need a fast floor function for scalar code. While the libm floor function is very fast, there are code segments that would greatly benefit from being able to inline floor into inner loops. The following works for the default round to nearest FPU rounding mode on PowerPC for all values except for -0.0, for which it returns 0.0 instead of -0.0:
Please note that some compilers may have difficulty scheduling __fsel() properly. It may be required that you unroll and inline by hand for optimal performance. We find the above code to be at least 2-3 times faster in our tests. For rounding modes that are not the default, the function produces identical output to floor over the range –2**105 ... 2 ** 105 (-4.05648e31 to 4.05648e31), except for -0.0 as noted above. Operating across a vectorIn general, you should try to always add among vectors, rather than across a single vector. However, in certain situations, it cannot be avoided. Here is the quickest way (we know of) to do this by type. Those based on vec_sums() return the result in the last cell. Those that use vec_sld will return the result in all cells. If you want to convert the former into the latter, use vec_splat().
Notice that when adding across a vector the hard way (as per vector float), it is not necessary to rotate one float and add each time. Rotate two, add then rotate one and add. When you need to add across more than one vector, it can in some cases be more efficient to do a matrix transpose and add between the rows of the transposed matrix. You can even do the adding while you are doing the transpose, as the permute unit and the VALU can execute concurrently. This not only increases concurrent execution, but also reduces the number of permute instructions required as the each operation reduces the amount of data. It also gives you a result as a vector, rather than a scalar stored in a vector, making it more efficient to use downstream:
While four calls to vec_sums finishes in seven cycles, rather than ten, you are left with the problem of how to efficiently use the result, which would be four largely empty vectors. The NaN Method for Partial Vector ComparesWith proper planning, it is rarely necessary to do conditional tests on some but not all elements in a vector. However in rare circumstances it is unavoidable. When testing vector floats, there is a special trick one might use with NaN (Not a Number) to avoid testing some of the elements. The key is to notice that any test against a NaN always returns false. So, for example, if you want to determine whether both of the second or third elements are negative, you can test to see if they are less than { NaN, 0.0, 0.0, NaN }:
Bit-wise NOR for NOTYou can use vec_nor() to quickly and cheaply find the bit-wise compliment of a value.
In some cases vec_andc() (vector and with compliment) is appropriate instead. Bit CountingA small number of algorithms count the number of bits in a byte. This is usually done most quickly in the vector unit by using vec_perm to do a lookup table:
The above function returns the number of 1 bits in each byte. Since the maximum result for any byte is 8, you can safely accumulate the byte results for 31 iterations before needing to accumulate the results into a larger integer. Accumulation into a larger integer type is probably most efficiently done using vec_sum4s. Shortly before returning you can use vec_sums to add across the accumulation vector used by vec_sum4s. Byte SwappingThere are two ways to accomplish this. One can simply rotate each element of a vector short by 8 bits, using vec_rl() to get a byte swapped vector short. To byte swap a vector long, byte swap it as a vector short, then use vec_rl to rotate each 32 bit element by 16 bits.Another way to do it is to use XOR with a permute constant. In this case, create a identity permute with
Then XOR it with (vector unsigned char) (dataSize - 1):
This generates the appropriate permute constant to do the byte swap operation. You can also XOR the higher bits of the permute register to swap the orders that elements appear in a vector Note that we have named each permute constant like a function. This is a handy convention for naming permute constants, which makes sense if one considers vec_perm to be a data driven function... Type ConversionThere are a suite of routines for converting among vector chars, shorts, longs, pixels and floats.
Those above the arrows move the data type to the right along the conversion line. Those below the arrow, are for conversions that go from right to left. Shorts and LongsAn example: Looking at conversions from vector char to vector short, we see vec_unpackh, vec_unpackl, vec_mergeh and vec_mergel. Both vec_unpack and vec_merge* have high and low variants because in the conversion of 16 chars to 16 shorts, we go from one vector to two. The high and low designation indicate whether to expand the first set of 8 or the second set of eight elements from the vector char into the vector short. Whether vec_unpack or vec_merge* is used depends on whether you want a signed (sign extended) or unsigned (zero extended) result. Vec_mergeh() is used with a vector full of zeros as the first argument. In the short to char direction, there are three variants of vec_pack. Since conversion from a short to a char may overflow the char, we can handle the overflow using a modulo operation (vec_pack) or by saturating the value at the largest or smallest representable char (vec_packs or vec_packsu). The saturated conversions are available in signed and unsigned versions. The conversions between vector short and long work similarly. Pixels32-bit to 16-bit pixel conversion is fairly straightforward in the 32->16 direction. The only caveat is that the least significant bit of the alpha channel propagates into the alpha bit in the 16-bit pixel, not the most significant bit. Things are less straightforward in the 16->32 bit direction, as the 5 bit color channel values from the 16-bit pixel end up in the low order five bits of the 32-bit pixel channels. A few rotates and an OR are required to do the complete conversion:
Ints and FloatsFinally conversion between vector ints and vector floats is fairly straightforward. Each conversion function contains a literal five bit constant to indicate the position of the of the decimal point in the fixed point notation. Unfortunately, as there are 33 possible positions for the decimal and only 32 of them are representable in a 5 bit literal, one of them is missing. This is the one that you would need if you commonly use 0.32 fixed point notation. Happily, conversion between ints and floating point can also be done using vec_madd() in many cases, so even if you have a strange fixed point format, the conversion can still be done. The basic conversion method is covered in the IBM PowerPC Compiler Writers Guide (p83). (The IEEE-754 floating point format is documented in a number of places, including the Motorola Programming Environments Manual for 32-bit Implementations of the PowerPC Architecture.) It is easily translated into the vector domain. Direct conversion from vector shorts and vector chars is possible with this general method, and in many cases can be faster than the more standard method. What is more, in some cases, you can fold an ensuing constant multiply add fused into the operation for free. The following is a simple example that converts a 0.32 vector unsigned long to a vector float:
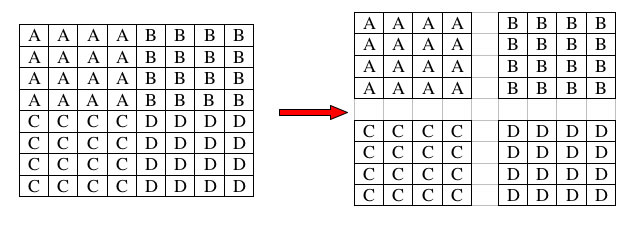
Please note that only the top 23 bits of precision in the 0.32 fixed point quantity are preserved with this method. Matrix TransposeAs noted in the Code Optimization section, and elsewhere, matrix transposes are highly efficient tools to deal with interleaved data formats. Thus, their utility extends far beyond the small number of uses generally found in linear algebra. For example, you can easily turn 4 interleaved vectors:
...into 4 uniform vectors:
... in 8 vector instructions. This second format is usually a lot easier to work with. The general transpose algorithm is executed as a series of vec_merge(h/l)() instructions that interleave like rows above and below the vertical midpoint of the matrix. This is done iteratively to progressively reduce the height of the matrix by a factor of two each time, while at the same time doubling its width, until the matrix reaches dimension N2 x 1. This array is the result. If you simply recast the array[N2] as a matrix[N][N], it is the matrix transpose of the input matrix. The operation is represented graphically in this 8x8 example:
The method is fairly general for square matrices. Similar approaches can be used for rectangular matrices with some creativity. This method requires at least N+1 registers to do the transpose, though implementations that use 2N registers are common. For large matrices, the best approach is to take a hybrid approach between simple scalar element swap algorithms and the vector merge approach suggested here. Block out the matrix into smaller chunks, each suitably sized for the merge algorithm. Load two complimentary chunks in, transpose them, then store each where the other came from. For example, for an 8x8 matrix of floats, break the matrix down into 4 quadrants, each containing a 4x4 matrix:
The two quadrants along the diagonal (A and D) can be simply transposed in place. For B and C, load both into register, transpose each, then save B where C used to be and C where B used to be. Matrix MultiplicationSometimes in order to get an efficient vector implementation, one must approach a problem with a modified algorithm that does things in ways suitable for the vector unit. One example is matrix multiplication. The central problem facing would-be vectorizers for this task, is that using the traditional algorithm, rows of matrix A are multiplied by columns of matrix B, which may mean transposing matrix B. In addition you then have to sum across the result, which is not very efficient.
|

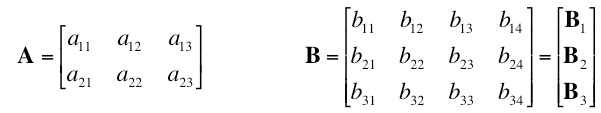
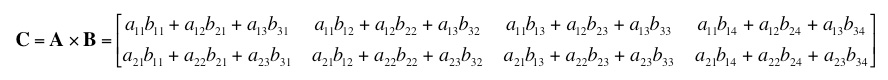
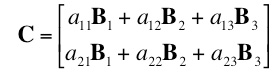
| Ahigh = (A & 0xFFFF0000) >> 16 | Bhigh = (B & 0xFFFF0000) >> 16 | |
| Alow = A & 0xFFFF | Blow = B & 0xFFFF |
2) Here is multiplication of 32 bit quantities by 16 bit parts
result = Alow * Blow + ( Ahigh * Blow + Bhigh * Alow ) <<16 + (Ahigh * Bhigh) << 32
Since we are returning only the low 32 bits, we don't have to worry about the Ahigh * Bhigh term, and we need only do the following:
result = Alow * Blow + ( Ahigh * Blow + Bhigh * Alow ) <<16
In AltiVec, we could do this as a series of 3 vec_mule's and vec_mulo's with some adds. However, as described here, vec_mule and vec_mulo are somewhat wasteful, in that they do half as many multiplies as a vec_msum(), and no addition for the same cost. By simply swapping the high and low parts of one of the vectors, we can do all the multiplications involving high parts of the 32 bit terms, in a single vec_msum. This swap is easily done, using vec_rl() by 16 bits. Here it is in code. This does the vector equivalent to mullw:
typedef vector unsigned short vUInt16;
typedef vector unsigned int vUInt32;
vUInt32 vec_mullw( vUInt32 A, vUInt32 B )
{
//Set up constants
vUInt32 sixteen = vec_splat_u32(-16);
vUInt32 zero = vec_splat_u32(0);
vUInt32 Bswap, lowProduct, highProduct;
//Do real work
Bswap = vec_rl( B, sixteen );
lowProduct = vec_mulo( (vUInt16)A,(vUInt16)B );
highProduct = vec_msum((vUInt16)A,(vUInt16)Bswap, zero);
highProduct = vec_sl( highProduct, sixteen );
return vec_add( lowProduct, highProduct );
}
Load and Splat a Scalar
Commonly when working with constant terms in vector code, it is desirable to be able to load a scalar and splat it across a register. Because the alignment of a scalar loaded into a vector register is generally not known at compile time, you can't simply use vec_splat. This can be done by rotating the data to a known position and then splat. In this case, we observe that splatting the permute map is the same as splatting the data, so we can use that to hide a bit of latency.
In this code example, the scalar being loaded must be naturally aligned. (e.g. a float must be 4 byte aligned.)
#define TYPE float
typedef vector unsigned char vUInt8;
vector TYPE vec_loadAndSplatScalar( TYPE *scalarPtr )
{
vUInt8 splatMap = vec_lvsl( 0, scalarPtr );
vector TYPE result = vec_lde( 0, scalarPtr );
splatMap = (vUInt8) vec_splat( (vector TYPE) splatMap, 0 );
return vec_perm( result, result, splatMap );
}
Note: Permute Naming Conventions
Permute operations can produce output that is hard to understand. This is true both because vec_perm is so flexible and also because fast permute constant generation schemes can be highly convoluted. It is suggested that you adopt a naming convention for permute constants that makes it clear what they do. Since each permute constant is actually a function stored as data, it may be appropriate to name the permute constant using function naming conventions. For example, "fixAlignment", "pivotMatrixColumn" and "reverseElementOrder" are a lot more informative than "permute1". Their use as the third argument of vec_perm() makes it clear what kind of data they are, and transfers their meaning to the vec_perm operation itself.
|
Get information on Apple products. Copyright © 2008 Apple Computer, Inc. |