| Log In | Not a Member? |
Support
|
|
AltiVec Address AlignmentUnlike the scalar Integer and Floating Point units, the AltiVec unit does not automatically or transparently handle unaligned loads and stores for you. If you try to load or store to an address that is not 16-byte aligned, the address will be silently rounded down to the nearest aligned address, in a operation similar to (addr & ~15), and the data is loaded/stored from there. The
Unaligned Loads and Stores of Entire VectorsUsing two 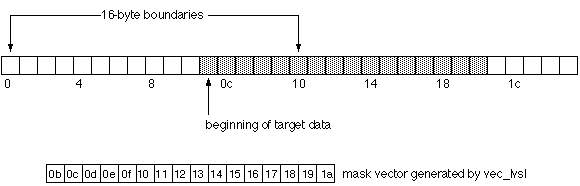 Overly simplified, the target data is located at However, while this approach appears in the AltiVec Programming Environments Manual (3.1.6.1), it is not safe to do misaligned loads and stores that way, if the target address is 16-byte aligned. If the target pointer is 16 byte aligned, the first load (MSQ) will load all 16 bytes, and the LSQ will load 16 bytes of completely unknown data. If the target pointer happens to be pointing to the last aligned vector in a page, then pointer + 16 will point to a completely new page. That page might be unmapped, in which case the load will trigger a segmentation fault. Direct use of the algorithms in the AltiVec PEM (section 3.1.6.1) for handling misaligned loads and stores may crash your application and is strongly discouraged. The solution is to use pointer + 15 for the second load instead of pointer + 16. If pointer is not 16 byte aligned, then pointer + 15 will yield the same results as a load using pointer + 16 would. If pointer is 16 byte aligned, then pointer + 15 falls on the same vector as the one pointed to by pointer + 0. In this way, we always load vectors that contain valid data. (A vector load is always safe to do if at least one byte in the vector is known to exist.)
Similarly, you can use the vector unit to do unaligned stores, though the operation is somewhat more complicated. You must load in the two aligned vectors that bracket the store destination, write your data onto those vectors being careful to preserve those areas that are not to be overwritten, and then store them back. The code below uses the +15 technique to avoid crashing with aligned pointers:
Some caution is still in order when using the
The only way to solve the thread safety problem is to store data using vector element stores. Here is one function that does that:
...but the above function is clearly still too expensive to be satisfactory for general use. It is also slightly dissatisfying because it is not atomic, which is why it isn't labeled to be completely safe. There is no way to do an atomic misaligned AltiVec load or store without falling back on other atomic synchronization primitives like a mutex or the operations in OSAtomic.h. For reasons of performance and code simplicity, it is usually better simply to avoid misaligned stores. The best, fastest and simplest approach is to "just" align your store data. When that can't be done, it is often just fine to use the scalar engine to do the unaligned cases at the edges of the array and handle the aligned part in the middle using the vector unit. This approach can fail in two common cases:
In these cases, the optimum solution is a hybrid of store by element and full vector stores. Use element stores to do the partial vector stores at the edges of the misaligned array. That will prevent you from running into any threading issues with other data near the edges of your data structures as your code matures. Then use aligned full vector stores with appropriately shifted data to do the aligned region in the middle, optimized to remove redundant work in the middle. Here is a sample function that adds two arrays together to produce a third with arbitrary alignment that follows this strategy. (Option-click to download as a .c file.) It may be quickly modified to do a variety of different arithmetic operations. For best performance, if you have to choose between unaligned loads and unaligned stores, pick unaligned loads. Unaligned Loads and Stores of Single ElementsYou may also load and store data from vector registers a single element at a time. Here too, the vectors must be quadword (16 byte) aligned. The address that you pass to vec_lde() or vec_ste() will be rounded down to the nearest 16 byte boundary, and the actual element stored or loaded will be the one which corresponds to the actual address you pass. The data will be taken from or written to the appropriate element in the aligned vector. This example illustrates where an unsigned short loaded from 0x14 ends up in the resulting vector unsigned short.
When the load is complete, the values in the other seven elements are undefined. That is to say that even though you may observe the other elements to be zeroed today, that may not always happen, so do not depend on that behavior. As another example, if we store the third element in a vector to an aligned vector:
In this example, where the location of the value in the result vector is difficult to predict, because we may not know the alignment of To load a 16 byte aligned scalar from memory and splat it across all values of a vector, simply load the value and splat it out:
Unfortunately, the second argument of vec_splat must be a literal constant, so that method is only useful for scalars whose alignment within a 16 byte segment is known at compile time. Clearly not every scalar has known alignment at compile time. In some cases, you can force data to have 16 byte alignment by union with a vector type. Where this is not possible, scalars that are naturally aligned (i.e. the scalar itself is 1, 2, or 4 byte aligned as appropriate for its size) can be rotated into a known position and splatted from there:
For scalars with arbitrary alignment, you must load the complete vector at the address and possibly the vector immediately following it. You must only load the second vector if the scalar spills over onto the second vector. Otherwise, a unmapped memory exception could occur. This can be done safely without branching as follows:
Data Alignment in MacOSBlocks returned by the MacOS heap are all at least sixteen byte aligned. To obtain a page-aligned heap block on MacOS X, you may use valloc(). In Carbon, you may use MPAllocAligned(), to create blocks that are aligned to a size that you specify. The MacOS stack frame is 16 byte aligned. Likewise, global storage also starts 16 byte aligned. Thus, maintaining proper alignment is typically just a matter of preserving the alignment of the memory areas given to you. In the stack, globals and data structures (classes, structs) the compiler will automatically align data with vector type to 16 bytes. However, in some cases, you may wish to access scalar arrays with the vector unit. In these cases, a good method of ensuring 16 byte alignment of a scalar array is to union it with a vector type:
Unions are also a good way to transfer data from the scalar units to the vector unit, since they place data in areas of known alignment.
Please note that it is usually highly inefficient to pass data between the scalar units and the vector unit because the data cannot be transferred directly between register files. It is written out to the caches and read back in to the new unit. If you are transferring data between units frequently, you are likely to be better off doing more or all of your calculation in the vector unit. This is also true for calculations that frequently transfer data between the two scalar units. The vector unit can convert between integer and floating point types much more quickly, with no added load / store overhead, so if you are doing a lot of calculation that hops back and forth between the scalar integer and scalar FP units, you may be better off doing the whole thing in the vector unit, even if you only have a single int or float to work on. This is especially true on the G5, where doing so can cause a pipeline fail, flush and retry due to a store and load to the same address in the same dispatch group. (See section on type conversion.) |

|
Get information on Apple products. Copyright © 2008 Apple Computer, Inc. |