|
|
1. PISA: Predicting the Impact of Specification Alternatives[The unabridged version of this report is also available.] Moderators:
Participants:
This report briefly summarizes the work of the "Informal versus Formal Specifications" working group. In the initial discussion, it became clear that it would be useful to have some idea of the tradeoffs between using informal and formal specifications, so that became the main goal of the group. The result was a model that helps predict the impact of alternative specification methodologies, which we called PISA.
There are several issues that arise in trying to understand how the distinction between informal and formal specifications affects reuse. For example, one issue is what is the exact distinction. We believe that there is a spectrum of formality of specification, from completely informal to completely formal. Another issue is that various "customers" of the specification have differing needs. The customer may play one of (at least) four roles: the writer, the implementer, the tester of the implementation, and the client (i.e., reuser) of the implementation. Additional concerns include the differing levels of expertise that the customers have in whatever level of formalism is being used, and the amount of tool support that is available.
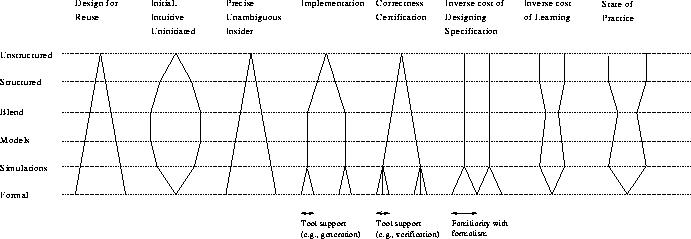
Figure 1: The PISA Model. The width of lines for each column represents relative benefit; more width corresponds to more benefit (or lower cost). In the model, illustrated in Figure 1, the spectrum of formality is represented on the vertical axis. Each column represents an activity or task, and the relative benefit obtained for a particular task is represented by the width separating the pair of lines forming each column. Larger widths represent larger relative benefit; there are also various annotations given to show other aspects that might have an effect (such as level of tool support). The most informal specification is unstructured natural language, such as comments. Next is structured natural language, which is essentially comments that contain enough structure to allow simple forms of tool support (such as the javadoc system). The "blend" level represents the combined use of formal and informal specifications. Models represent diagrams used to describe the behavior of the process or data. These can be made fairly precise and yet are still accessible to those unfamiliar with mathematical notations. If models are taken to the point where they can be put in executable form, then they make it easier to do some forms of analysis. We called such executable models "simulations." Prototypes and queuing models are examples of this. Finally, we have completely formal specifications that are expressed in some mathematical notation and backed up by a semantic model. In Figure 1, the columns represent benefits, inverse costs, and current support for different levels of formality. The first five columns show the benefits for the different software development activities. The first column represents the effort required by the specification designer to produce a specification. The next two apply to the client (reuser). The "Uninitiated" column is for someone who is new to the specification and formalism, or who is not interested in the details; the "Insider" column is for someone who is trained and needs precise information. The next two columns apply to the coders and testers. The "Implementation" column describes the ease of implementation for the different levels of formality, and the "Certification" column shows the benefits for checking that the implementation performs as required. Columns 6 and 7 show the inverse costs for the production of the specification and the cost to learn the formalism. The final column shows the current state of practice with respect to the current state of the art.
In this section, we give one example of how the model might be used. Further examples are given in the full report (see Section 9). Each example is a scenario consisting of a description of assumptions about a software development team; these assumptions set various parameters for the model. We then use the model to help us make recommendations for how the team can improve the benefits it gets from specifications, while minimizing extra cost. The scenario we consider here is one in which the development team has no experience with formal specifications and there is no tool support for any kind of formalism. The issue here is how far a specification should be formalized. The model tells us that for relatively little cost the level of formalism can be moved up to structured natural language, or even simulation (but not to a blend or model). Either choice will improve confidence in correctness of design, still retain some amount of easy understanding of what a specification means, and be more precise (than unstructured natural language). There will still be ambiguity in the specifications, and consequently there will not be complete confidence in the implementation.
The first insight is that the shape of the "learning cost" curve reflects the "state of practice" curve. It could be that the perception of how difficult it is to learn a level of formalism is based on what we see as the state of practice, or it could be that the adoption of a level of formalism is based on difficulty of learning it. It is interesting that structured natural language and/or models and simulation do well in many scenarios that we studied. We believe that structured natural language and models complement each other well. One hypothesis is that these activities encourage one to ask the right questions: using models helps one fix a vocabulary that is fairly precise, which can then be used to write down an appropriate contract in terms of pre- and postconditions. This is like the more formal approach of designing the set of abstract values and then using them to write pre- and postconditions, but avoids the learning costs of mathematical formalisms. PISA may also be used to decide who might benefit the most from training in formalisms. For example, if the same person designs and implements a specification, then there seems to be a large benefit to training that person in formal techniques, especially if that person repeatedly does design and implementation.
There are some obvious questions about the model that need to be settled by future work. One set of questions concerns the informality/formality spectrum. For example, it is not clear that the ordering we chose really reflects increasing formality. It is also likely that there are more points in the spectrum that we should consider. Another set of questions concerns the relative widths given in the model. We emphasize that these widths are only educated guesses based on the collective expertise of the group.
Although our model may be, and probably is, inaccurate in some respects, we hope that it will have the effect of promoting discussion about the costs and benefits of formal and partially informal specifications. We hope that the model will help people to examine their understanding of the costs and benefits of formality. We also hope that it helps identify places where there is disagreement, and thus the potential for future work.
Thanks to all the members of the group for their vital contributions to the work reported here. Thanks to Wayne Heym and John Penix for corrections to an earlier draft. Leavens’ work was supported in part by NSF grant CCR-9503168. Tempero’s work was carried out while visiting the Oregon Graduate Institute.
|
|
|