|
|
PISA: Predicting the Impact of Specification AlternativesGary T. Leavens
Abstract:Various points along the spectrum between formal and informal specifications are identified. A model is presented that helps to describe where along this spectrum one should be to get various benefits for reuse, depending one one's situation.
IntroductionThis report summarizes the work of the ``Informal versus Formal Specifications'' working group, which grew out of the original ``Rigorous Behavioral Specification as an Aid to Reuse'' working group. The topic was chosen because it was a common theme behind why many of the people chose the original working group. The participants of the group were: Dean Allemang from Organon Motives, Paulo Buccifrom The Ohio State University, Wayne Heym from Otterbein College, Larry Latour from University of Maine, Gary Leavens from Iowa State University, Marjan Mernik from University of Maribor, John Penix from University of Cincinnati, Stephen Seidman from Colorado State University, Ewan Tempero from Victoria University of Wellington, Jim Wagner from The Ohio State University, and Sergey Zhupanov from The Ohio State University. In the initial discussion, it became clear that it would be useful to have some idea of the tradeoffs between using informal and formal specifications, and that became the main goal of the group. The result was a model that helps predict the impact of alternative specification methodologies, or PISA.
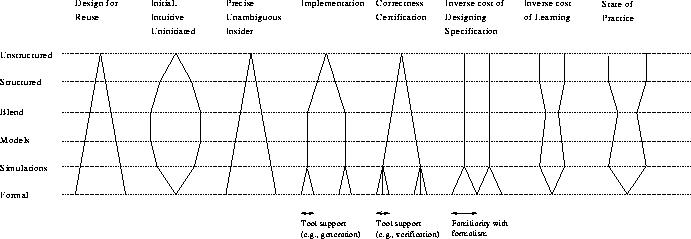
OverviewThere are several issues that arise in trying to understand how the distinction between informal and formal specifications affects reuse. For example, one issue is what the exact distinction is. We believe that there is a spectrum of formality of specification, from completely informal to completely formal. Another issue is the needs of various ``customers'' of the specification. The customer may play one of (at least) four roles: the writer, the implementor, the tester of the implementation, and the client (i.e., reuser) of the implementation. Then there are the questions of the level of expertise that the customers have in whatever level of formalism is being used, and the amount of tool support that is available. The group's attempt to resolve these different issues resulted in a model of the benefits for different customers and tasks, compared at different levels of formality (Figure 1). This model was then refined by considering scenarios in which software development teams operate at different levels of formality, from those whose members have no experience at all, to those at the other end of the formality spectrum. The remainder of this paper is organized as follows. Section 3 describes the model itself. Section 4 describes various scenarios. Following these, we summarize the insights given by the model, and discuss future work, related work, and offer some conclusions.
ModelWe present the details of our model in this section. The model presented is essentially to the one arrived at by the working group. See Section 6 for a discussion of limitations of this model. In the model, the spectrum of formality is one major dimension, and the relative benefits obtained for a particular task is the second major dimension. Larger widths represent larger relative benefit; there are also various annotations given to show other aspects that might have an effect (such as level of tool support). The model is shown in Figure 1.
The Spectrum of FormalityAs mentioned above, we see a spectrum of formality, from completely informal to completely formal. The most informal is unstructured natural language. This is at the level of using descriptive names and comments to convey the expected behavior and intended use. Next is structured natural language. This represents such things as comments that contain enough structure that they can be parsed, and so potentially allow some simple forms of tool support. The Java Development Kit's javadoc system [Sun] is an example of this. More structured forms of informal specifications (with for example, pre and postconditions) are used by Liskov and Guttag in their book [LG86]. For example, they might specify a square root routine as follows. sqrt(x: real) returns(result: real)
REQUIRES: x is positive
ENSURES: result is an approximation to the positive square root of x
The ``blend'' level represents the combined use of formal and informal specifications. For example, in Larch/C++ [Lea96, Lea97], a string of text preceded by the keyword informally can be used as a boolean-valued formula; this allows such informal text to be freely combined with formal text in assertions. For example, one might write the following postcondition for an output procedure. result == out \and informally "a printed representation of self is added to out"Such a blend allows both an escape from formality and avoids the need to formally specify the entire universe (which may be unnecessary, impractical, or even impossible). In Z [Hay93], the use of ``given sets'' also allows one to avoid specifying everything formally. We envisioned ``models'' as diagrams or pictures of data or processes. For example, in learning about LISP lists, one often draws ``box and pointer'' diagrams to display the effect of various operations. The utility of such models was first emphasized in our group by Larry Latour. Object interaction diagrams [Boo94] are also models in this sense, although they help one visualize processes instead of data. Such models help the specifier understand what it is that is being specified. Their value is that, although they can be made fairly precise, they can also be used by those not familiar with various mathematical notations. Although static structure can also be displayed by diagrams (for example, ``Booch diagrams'' [Boo94] display the various relationships between classes), we primarily thought of models of the dynamics of a specification. Pictorial models of data can be seen as playing the same role in informal specifications as the formal models of abstract values used in VDM [Jon90], Z, or the various Larch [GHG93] and RESOLVE [OSWZ94] interface languages. If models are taken to the point where they can be put in executable form, then they make it easier to do some forms of analysis. We called such executable models ``simulations.'' Prototypes and queuing models are examples of this. Finally, at the extreme of formality, we have completely formal specifications that are expressed in some mathematical notation and backed up by a semantic model. By this we meant mathematical specifications written in a notation such as Z or VDM.
Benefits versus Costs for ReuseIn Figure 1, the columns represent benefits, inverse costs, and current support for different levels of formality. The benefits for various software development activities are given in the first five columns, which are roughly ordered as stages in a development process. The next two columns give inverse costs. In each column, the width at a given level of formality represents how well that level of formality supports the given task, relative to the best possible, that is, wider is better. Thus, in the inverse cost columns, wider means cheaper. The ``Design for Reuse'' column represents the benefit that the designer of the specification gets by working at a particular level of formality. Our opinion is that working at more formal levels of specification forces the designer to ask more questions about the required behavior than she might if working at a less formal level, and so is more likely to produce the ``right'' specification. The next two columns apply to the client (reuser). For reuse, clients use a specification to determine whether the implementation will meet their needs and to determine how to correctly use it (e.g., preconditions and interface information). The first of these columns represents the benefits of a given level of formality for someone seeing the specification for the first time, who is only interested in a rough idea of what it does, or who is not familiar with the formalism being used. For such users, a certain level of informality is better than complete formality. However, if a completely precise, unambiguous understanding is needed, or if this reuser is familiar with the formalism being used, then a completely formal specification is better. The next two columns apply to those who have to implement the specification and certify the correctness of such implementations (coders and testers). We recognize that these tasks are often carried out by the same person, and that the designer of the specification is often also the implementor. These considerations have an impact on the expected benefits, but we leave full consideration of this issue for future work. In the ``Implementation'' column, the benefit is ease of implementation from the specification. We believe completely informal specifications are worse for this because they might leave many important aspects of behavior ambiguous. For example, teachers often get complaints when their programming problems are not specified precisely enough for their students to know what to do. However we believe that adding structure will significantly affect the ease of implementation. If the implementor is dealing with completely formal specifications, then the situation changes somewhat. It may be the case that the implementation can be mechanically generated from the specification, in which case the implementation will be easy and it will be easy to certify correctness. Note that this will be true even if the ``implementor'' has little understanding of the specification! However if there is no mechanical generator, then the level of confidence depends on the level of understanding of the formalism; if she does not understand the formalism well, it may be more of a struggle to produce and certify a component than would be the case if less formal techniques were used. The first of the inverse cost columns is ``Inverse cost of designing specifications''. Here it is not clear what should be the relative costs. For example, a completely unstructured informal specification might be cheap, since it might consist of just a few sentences; on the other hand, a completely unstructured informal specification might be more expensive, since the writer might struggle a lot to clarify something that would be easy to write quickly and precisely with a formal specification. The ``Inverse cost of learning'' column shows the cost of learning to deal with the different levels of formality. Interestingly, we believe simulations will be cheaper to learn than models. This because simulations can be done by programming, which, we assume, is a skill already known to the people involved. The final column shows the state of the practice of the different levels of formality. Note that this is relative to the state of the art, and so the narrower sections show that there are state of the art techniques available, but not in widespread use.
Using the ModelIn this section, we demonstrate how the model might be used. Each scenario consists of a description of assumptions about a software development team; these assumptions set various parameters for the model. We then use the model to help us make recommendations for how the team can improve the benefits it gets from specifications while minimizing extra cost. We also give the cost of following those recommendations. Since we are interested in costs and benefits, the assumptions about the team must cover all the other dimensions of our model. So, for each role (specifier, implementor, reuser, tester) we give their level of experience with the specification formalism, and their level of tool support (if appropriate).
Scenario 1
Scenario 2
Scenario 3
Scenario 4
Scenario 5
Scenario 6
InsightsOne measure of worth of a model is whether it provides any unexpected insights. We report a few such insights in this section. The first insight is that the shape of the ``learning cost'' curve reflects the ``state of practice'' curve. Exactly what this means is unclear. It could be that the perception of how difficult it is to learn a level of formalism is based on what we see as the state of practice, or it could be that the adoption of a level of formalism is based on difficulty of learning it. It is interesting that structured natural language and/or models and simulation do well in many scenarios that we studied. We believe that structured natural language and models compliment each other well. One hypothesis for this is that these activities encourage one to ask the right questions: using models helps one fix a vocabulary that is fairly precise, which can then be used to write down an appropriate contract in terms of pre- and postconditions. This is like the more formal approach of designing the set of abstract values and then using them to write pre- and postconditions, but avoids the learning costs of mathematical formalisms. In hindsight, these insights are not stunningly surprising. In fact, had we thought of them first, we might have used them to guide the development of our model. However we did not think of them first, and so it gives us some confidence in the validity of the model. PISA may also be used to decide who might benefit the most from training in formalisms. For example, if the same person designs and implements a specification, then there seems to be a large benefit to training that person in formal techniques, especially if that person repeatedly does design and implementation.
Limitations/Future workThere are some obvious questions about the model that need to be settled by future work. One set of questions concerns the informality/formality spectrum:
Another set of questions concerns the relative widths given in the model. We emphasize that these widths are very much educated guesses based on the collective expertise of the group. We are very aware that our expertise did not cover all areas, and what we did have did not necessarily allow us to make very precise judgements. Experimental evidence for such costs and benefits is needed. While there is a distinction to be made between informal and formal techniques in all areas of formal methods, the group focused on specifications. It would be interesting to see whether the model can also be applied to other aspects of formal methods.
Related workIn terms of comparing costs and benefits of formal and informal methods, the most closely related work is that of Pfleeger and Hatton [PH97]. These authors analyze data from the design and implementation of an air traffic control system, and analyze the benefits of the use of formal and informal methods in various parts. They found (page 41) that ``the predelivery fault profile showed no difference between formally designed code and informally designed code. On the other hand, the unit testing data showed fewer errors in formally designed code, and postdelivery failures were significantly less for formally designed code.'' Although the results of a single case study such as this must be interpreted cautiously, such results do not invalidate the ``correctness certification'' column in our model. Several other authors discuss the costs and benefits of formal methods. According to Larsen, Fitzgerald, and Brookes [LFB96], the formal specification language VDM can be used with benefit in early development stages with ``no significant cost or time overhead,'' provided industrial-strength tools are available. In a survey of current industrial practice, Criagen, Gehart, and Ralston [CGR95] also noted the importance of tool support; these authors also noted that formal notations need to be carefully designed to communicate with the intended users, a point we emphasize as well. Our ideas for a design process that makes use of both informal and formal methods, sometimes starting with informal specifications and moving towards the formal ones and then back, have been previously expressed by several authors. For example, France and Larrondo-Petrie [FLP95] advocate integrations of informal and formal specification techniques. In their ``loosely integrated model'' informal specifications are done first, followed by formalization. They also describe a ``probe-elaborate-validate'' process in which after the formal specification is written, it is compared to the informal specification for validation purposes. These authors advocate informal specifications, such as entity-relationship diagrams and data flow diagrams, for recording the results of the ``probing phase'' of design, whereas the formal techniques, such as Z, are better suited for the ``elaboration'' phase. Andrews and Gibbins [AG88] advocate a similar process; Fraser, Kumar, and Vaishnavi survey several others with similar processes [FKV94, page 78,]. In our work we did not make such fine distinctions between parts of the design phase. Although our model is mostly concerned with software and component design specifications, its view of formal and informal languages as useful for different audiences is similar to the view taken in much of the work on requirements specifications. The work on requirements specifications has long been concerned with both informal and formal languages. This is because the desires and wishes of users are, at least at first, informally expressed [Win90, page 19,]. For example, Fraser, Kumar, and Vaishnavi discuss technical ways to bridge the gap between formal and informal requirements specification languages [FKV91]. Like us, they see formal and informal languages as ``complimentary, not competing.'' The bridge they attempt to build is between data flow diagrams, as used in structured analysis, and VDM. In a later work these authors cite some ``preliminary evidence from cognitive science'' that ``in the early stages of problem solving, when the problem area is relatively ill-structured, the use of formal representations is detrimental to the quality of the outcome'' [FKV94, page 76,]. A similar approach to the above is to take existing informal techniques and make them more formal. This compliments our model's approach of choosing an appropriate level of formality for various tasks, but not necessarily changing the techniques in use. Enhancing informal techniques to be more formal, however, gains many of the advantages of formal methods (especially precision). It has the additional advantage of greater acceptance by reusers, due to their previous experience with informal versions of the technique [tHvdW92]. Several examples of this line of work exist that formalize the data flow diagrams used in structured analysis [DL91, LPT94, FLP94]. Wing and Zaremski [WZ91] show how to integrate formal specifications with both structured analysis and structure charts. Others have shown how to translate entity-relationship data models into Z [Led96]. Other authors have also given advice on how to best use formal methods [BH95, GHW82, Hal90, LG97]. In contrast to our work, however, these authors do not make much room for informal methods. Fraser, Kumar, and Vaishnavi divide the spectrum of formality into three parts ``informal,'' ``semiformal,'' and ``formal,'' in contrast to our five [FKV94, pages 78-79,]. Their semiformal methods include mostly graphical notations, such as data flow diagrams; our model does not really have place for such techniques. Instead, we provide a spectrum of techniques that they might classify as nongraphical and semiformal techniques.
ConclusionsAlthough our model may be, and probably is, inaccurate in some respects, we hope that it will have the effect of promoting discussion about the costs and benefits of formal and partially informal specifications. We hope that the model will help people to examine their understanding of the costs and benefits of formality. We also hope that it helps identify places where there is disagreement, and thus the potential for future work.
AcknowledgementsThanks to all the members of the group for their vital contributions to the work reported here. Thanks to Wayne Heym and John Penix for corrections to an earlier draft. Leavens's work was supported in part by NSF grant CCR-9503168. Tempero's work was carried out while visiting Oregon Graduate Institute.
References
About this document ...PISA: Predicting the Impact of Specification Alternatives This document was generated using the LaTeX2HTML translator Version 96.1 (Feb 5, 1996) Copyright ⌐ 1993, 1994, 1995, 1996, Nikos Drakos, Computer Based Learning Unit, University of Leeds. The command line arguments were: The translation was initiated by Ewan Tempero on Wed Apr 30 12:48:28 PDT 1997 Ewan Tempero Wed Apr 30 12:48:28 PDT 1997 |
|
|