



|
| Volume Number: | 8 | ||
| Issue Number: | 2 | ||
| Column Tag: | Assembly workshop | ||
Efficient 68000 Programming
If a new CPU speeds up inefficient code, what do you think it will do to efficient code?
By Mike Scanlin, MacTutor Regular Contributing Author
The dew is cold. It is quiet. I hear nothing except for crackling sounds coming from the little fire burning two inches to the left of my keyboard. It wasn’t there a minute ago. Seems that Doo-Dah, the god of efficient programming, is upset with me for typing “Adda.W #10,A0” and just sent me a warning in the form of a lightning bolt. I hate it when he does that. You’d think that after three years in his service, researching which 68000 assembly language instructions are the most efficient ones for any given job, that he would lighten up a little. I guess that’s what makes him a god and me a mere mortal striving for enlightenment through the use of optimal instructions. As I extinguish the fire with a little Mountain Dew, I reflect upon the last three years.
My first lesson in the service of Doo-Dah was that proficiency in assembly language is a desirable skill in programmers so long as performance is a desirable attribute of software. The nay-sayers who depend upon faster and faster CPUs to make their sluggish software run at acceptable speeds don’t realize the underlying relativeness of the universe. If a new CPU will speed up a set of non-optimal instructions by 10%, then it will also speed up a set of optimal instructions by 10%. One should strive to be right on the edge of absolute maximum performance all the time. Users may not notice the difference in a 2K document but when they start working with 20MB documents they will soon be able to separate the optimal software from the non-optimal.
In the months following that lesson, I was given the task of compiling a list of instructions that should only very rarely appear in any program executing on a 68000 (and only then because you’re dealing with either self-modifying code or special hardware that depends on certain types of reads and writes from the processor). They are:
Don't Use Use Save
Move.B #0,Dx Clr.B Dx 8 cycles, 2 bytes
Move.W #0,Dx Clr.W Dx 8 cycles, 2 bytes
Clr.L Dx Moveq #0,Dx 2 cycles
Move.L #0,Dx Moveq #0,Dx 8 cycles, 4 bytes
Move.L #0,Ax Suba.L Ax,Ax 4 cycles, 4 bytes
Move.L #[-128..127],Dx Moveq #[-128..127],Dx 8 cycles, 4 bytes
Move.L #[-128..127],ea Moveq #[-128..127],Dx 4 cycles, 2 bytes
Move.L Dx,ea
Move.L #[128..254],Dx Moveq #[64..127],Dx 4 cycles, 2 bytes
Add Dx,Dx
Move.L #[-256..-130],Dx Moveq #[-128..-65],Dx 0 cycles, 2 bytes
Add.L Dx,Dx
Lea [1..8](Ax),Ax Addq #[1..8],Ax 0 cycles, 2 bytes
Add.W #[9..32767],Ax Lea [9..32767](Ax),Ax 4 cycles
Lea [-8..-1](Ax),Ax Subq #[1..8],Ax 0 cycles, 2 bytes
Sub.W #[9..32767],Ax Lea [-32767..-9](Ax),Ax 4 cycles
Asl.W #1,Dx Add.W Dx,Dx 4 cycles
Asl.L #1,Dx Add.L Dx,Dx 2 cycles
Cmp.x #0,ea Tst.x ea 4-10 cycles, 2 bytes
And.L #$0000FFFF,Dx Swap Dx 4 cycles
Clr.W Dx
Swap Dx
In addition, if you don’t care about the values of the condition codes then the following may be optimized:
Don't Use Use Save
Move.W #nnnn,-(SP) Move.L #ppppnnnn,-(SP) 4 cycles, 2 bytes
Move.W #pppp,-(SP)
Move.L #$0000nnnn,-(SP) Pea $nnnn 4 cycles, 2 bytes
Move.B #255,Dx St Dx 2 cycles, 2 bytes
Move.L #$00nn0000,Dx Moveq #[0..127],Dx 4 cycles, 2 bytes
Swap Dx
Movem (SP)+,Dx Move (SP)+,Dx 4 cycles
Ext.L Dx
Movem.L Dx,-(SP) Move.L Dx,-(SP) 4 cycles, 2 bytes
Movem.L (SP)+,Dx Move.L (SP)+,Dx 8 cycles, 2 bytes
Movem.L (SP)+,<2 regs> Move.L (SP)+,<reg 1> 4 cycles
Move.L (SP)+,<reg 2>
Note that pushing 2 regs or popping 3 with Movem.L is equivalent in cycles to doing it with multiple Move.L’s, but popping 3 regs with Move.L’s costs you two extra bytes. An easy rule to remember is to always use Movem.L whenever you’re dealing with 3 or more registers.
There are other optimizations you can make with minimal assumptions. For instance, if you are making room for a function result then don’t use Clr:
| Don't Use | Use | Save |
| Clr.W -(SP) | Subq #2,SP | 6 cycles |
| _Random | _Random | |
| Clr.L -(SP) | Subq #4,SP | 14 cycles |
| _FrontWindow | _FrontWindow |
If you’re trying to set, clear, or change one of the low 16 bits of a data register and you don’t need to test it first, then don’t use these:
| Don't Use | Use | Save |
| Bset #n,Dx | Or.W #mask,Dx | 4 cycles |
| Bclr #n,Dx | And.W #mask,Dx | 4 cycles |
| Bchg #n,Dx | Eor.W #mask,Dx | 4 cycles |
You should use registers wherever possible, not memory (because memory is much slower to access). If you need to test for a NIL handle or pointer, for instance, do this:
| Don't Use | Use | Save |
| Move.L A0,-(SP) | Move.L A0,D0 | 16 cycles, 2 bytes |
| Addq #4,SP | Beq.S ItsNil | |
| Beq.S ItsNil | ||
Use the “quick” operations wherever you can. Many times you can reverse the order of two instructions to use a Moveq (since Moveq handles bigger numbers than Addq/Subq):
| Don't Use | Use | Save |
| Move.L D0,D1 | Moveq #10,D1 | 6 cycles, 4 bytes |
| Add.L #10,D1 | Add.L D0,D1 |
Also, use two Addq’s or Subq’s when dealing with longs in the range of 9..16:
| Don't Use | Use | Save |
| Addi.L #10,D0 | Addq.L #2,D0 | 4 cycles, 2 bytes |
| Addq.L #8,D0 |
The following three optimizations will reduce the size of your program but at the expense of a few cycles. This is good for user interface code, but you probably don’t want to use these optimizations in tight loops where speed is important:
| Don't Use | Use | Save |
| Move.B #0,-(SP) | Clr.B -(SP) | -2 cycles, 2 bytes |
| Move.W #0,-(SP) | Clr.W -(SP) | -2 cycles, 2 bytes |
| Move.L #0,-(SP) | Clr.L -(SP) | -2 cycles, 4 bytes |
Most of the optimizations from here onward are only applicable in some cases. Many times you can use a slightly different version of the exact code given here to get an optimization that works well for your particular set of circumstances. These optimizations don’t always have the same set of side effects or overflow/underflow conditions that the original code has, so use them with caution.
Shifting left by 2 bits (to multiply by 4) should be avoided if you’re coding for speed:
| Don't Use | Use | Save |
| Asl.W #2,Dx | Add.W Dx,Dx | 2 cycles, -2 bytes |
| Add.W Dx,Dx |
Use bytes for booleans instead of bits. They’re faster to access (and less code in some cases). If you have many booleans, though, bits may be the way to go because of reduced memory requirements (of the data, that is, not the code).
| Don't Use | Use | Save |
| Btst #1,myBools(A6) | Tst.B aBool(A6) | 4 cycles, 2 bytes |
| Btst #1,D0 | Tst.B D0 | 6 cycles, 2 bytes |
Avoid the use of multiply and divide instructions like the plague. Use shifts and adds for immediate operands or loops of adds and subtracts for variable operands. For instance, to multiply by 14 you could do this:
| Don't Use | Use | Save |
| Mulu #14,D0 | Add D0,D0 | many cycles, -4 bytes |
| Move D0,D1 | ||
| Lsl #3,D0 | ||
| Sub D1,D0 |
If you have a variable source operand, but you know that it is typically small (and positive, for this example), then use a loop instead of a multiply instruction. This works really well in the case of a call to FixMul if you know one of the operands is a small integer -- you can avoid the trap overhead and the routine itself by using a loop similar to this one (in fact, the FixMul routine itself checks if either parameter is 1.0 before doing any real work):
| Don't Use | Use | Save |
| Mulu D1,D0 | Move D0,D2 | many cycles, -8 bytes |
| Neg D2 | ||
| @1 Add D0,D2 | ||
| Subq #1,D1 | ||
| Bne.S @1 |
Likewise, for division, use a subtract loop if you know that the quotient isn’t going to be huge (and if the destination fits in 16 bits):
| Don't Use | Use | Save |
| Divu D1,D0 | Moveq #0,D2 | many cycles, -10 bytes |
| Cmp D1,D0 | ||
| Bra.S @2 | ||
| @1 Addq #1,D2 | ||
| Sub D1,D0 | ||
| @2 Bhi.S @1 |
Don’t use Bsr/Rts in tight loops where speed is important. Put the return address in an unused address register instead.
| Don't Use | Use | Save |
| Bsr MyProc | Lea @1,A0 | 8 cycles, -4 bytes |
| ;<blah> | Bra MyProc | |
| @1 ;<blah> | ||
| MyProc: | MyProc: | |
| ;<blah blah> | ;<blah blah> | |
| Rts | Jmp (A0) |
You can eliminate a complete Bsr/Rts pair (or equivalent above) if the Bsr is the last instruction before an Rts by changing the Bsr to a Bra:
| Don't Use | Use | Save |
| Bsr MyProc | Bra MyProc | 24 cycles, 2 bytes |
| Rts |
Don’t use BlockMove for moves of 80 bytes or less where you know the source and destination don’t overlap. The trap overhead and preflighting that BlockMove does make it inefficient for such small moves. Use this loop instead (assuming Dx > 0 on entry):
| Don't Use | Use | Save |
| _BlockMove | Subq #1,Dx | many cycles, -6 bytes |
| @1 Move.B (A0)+,(A1)+ | ||
| Dbra Dx,@1 |
I base this conclusion on time trials done on a Mac IIci with a cache card. The actual results were (for several thousand iterations):
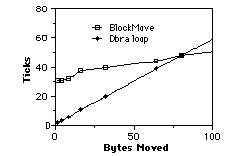
Figure 1: How fast do blocks move?
I did the same tests on a Mac SE and found that it was only beneficial to call BlockMove on that machine for moves of 130 bytes or more. However, since you should optimize for the lowest common denominator across all machines, you should only use the Dbra loop for non-overlapping moves of 80 bytes or less.
Be warned, though: on the Quadras, BlockMove has been modified to flush the 040 caches because of the possibility that you (or the memory manager) are BlockMoving executable code. So don’t use the above loop for moving small amounts of code (like you might do in some INIT installation code). Apple did this for compatibility reasons with existing non-040 aware applications running in 040 copy-back mode (high performance mode). However, because of this, your non-code BlockMoves are unnecessarily clearing the caches, too. I don’t know if it’s worth it to write a dedicated BlockMove for non-code moves, but it seems like it’s worth doing and then timing to see if there’s a difference.
Unroll loops. At the expense of a few extra bytes you can make any tight loop run faster. This is because short branch instructions that are not taken are faster than those that are taken. Here’s an even faster version of the above loop:
;1 Subq #1,Dx @1 Move.B (A0)+,(A1)+ Subq #1,Dx Bcs.S @2 Move.B (A0)+,(A1)+ Subq #1,Dx Bcs.S @2 Move.B (A0)+,(A1)+ Dbra Dx,@1 @2
Beware when using the above trick, though, because it doesn’t work for long branches. In that case, a taken branch is faster than a branch not taken.
Preserving pointers into relocatable blocks across code that moves memory: If you need to lock a handle because you’re going to call a routine that moves memory but the handle (and the dereferenced handle) isn’t a parameter to that routine, then you can usually avoid locking the handle with a trick (which has the desirable side effect of reducing memory fragmentation). Assume the handle is in A3 and the pointer into the middle of the block is in A2. All you really have to do is save/restore the offset into the block; you don’t care if the block moves or not:
| Don't Use | Use | Save |
| Move.L A3,A0 | Sub.L (A3),A2 | many cycles, 4 bytes |
| _HLock | ||
| ;<move memory> | ;<move memory> | |
| Move.L A3,A0 | Add.L (A3),A2 | |
| _HUnlock |
If the end of a routine is executing the same set of instructions two or more times, then you may be able to use this trick to save some bytes (at the expense of a few cycles). If the end of the routine looks like a subroutine, then have it Bsr to itself, like this (this example is drawing a BCD byte in D3):
| Don't Use | Use | Save |
| Ror #4,D3 | Ror #4,D3 | many bytes |
| Move.B D3,D0 | Bsr @1 | |
| And #$000F,D0 | Rol #4,D3 | |
| Add #'0',D0 | ||
| Move D0,-(SP) | ||
| _DrawChar | ||
| Rol #4,D3 | ||
| Move.B D3,D0 | @1 Move D3,D0 | |
| And #$000F,D0 | And #$000F,D0 | |
| Add #'0',D0 | Add #'0',D0 | |
| Move D0,-(SP) | Move D0,-(SP) | |
| _DrawChar | _DrawChar | |
| Rts | Rts |
Use multiple entry points to set common parameters. Suppose you have a routine that takes a boolean value in D0 as an input and suppose you call this routine 20 times with the value of True and 30 times with the value of False. It would save code if you made two entry points that each set D0, and then branched to common code. For instance:
| Don't Use | Use | Save |
| St D0 | Bsr MyProcTrue | many bytes |
| Bsr MyProc | ||
| Sf D0 | Bsr MyProcFalse | |
| Bsr MyProc | ||
| MyProcTrue: | ||
| St D0 | ||
| Bra.S MyProc | ||
| MyProcFalse: | ||
| Sf D0 | ||
| MyProc: | MyProc: | |
| ;<blah> | ;<blah> | |
| Rts | Rts |
Clean up the stack with Unlk. If your routine already has a stack frame and you create some temporary data on the stack (in addition to the stack frame) then you don’t always need to remove it when you’re done with it -- the Unlk will clean it up for you. For instance, suppose you make a temporary Rect on the stack. You would normally remove it with Addq #8,SP but if it’s near the end of a function that does an Unlk, then leave the Rect there; it’ll be gone when the Unlk executes.
Well, hopefully Doo-Dah has many more learned disciples now. Don’t forget to sacrifice a copy of FullWrite in his honor at least once a year. That makes him happy.
P.S. If you want even more 68000 optimizations there is an excellent article by Mike Morton in the September, 1986, issue of Byte magazine called “68000 Tricks and Traps” (pgs. 163-172). There are more than half a dozen or so tricks in that article not covered in this article (sorry for not listing them here but I didn’t want to get sued for plagiarism).



- SPREAD THE WORD:

- Slashdot

- Digg

- Del.icio.us


- Newsvine
