



|
| Volume Number: | 7 | |
| Issue Number: | 2 | |
| Column Tag: | HyperChat |
db_VISTA III and HyperCard
By Joseph S. Terry, Jr., Adam R. Joyner, Ajalon Corporation
 Note: Source code files accompanying article are located on MacTech CD-ROM or source code disks.
Note: Source code files accompanying article are located on MacTech CD-ROM or source code disks.
Introduction
This article is about database design using the network database model. This is not an exhaustive explanation of the pro’s and con’s of the different database models. We believe that the network model with relational database extensions is the best combination for “serious” database systems. Serious database systems in this context would be those systems that required maximum performance while handling very large amounts of information.
Also, this article is about the need to have sophisticated database engines on the Macintosh1 for developers using many different tools. And lastly, this article is about standards and about the developer community choosing wisely among all technologies, even those developed on other platforms. Someone, who writes an application should have the confidence that another application can read certain “export” files they may wish to create, without resorting to the “anyone can read ASCII” cop-out. Look at the dbase2 file format in the DOS world. If your application can write dbase files almost any other application can not only read, but probably make sense, of the files content and find that information quickly. The Macintosh needs a general file interchange format (GIFF). And in the future, with System 7.0 around the corner, We developers-You and us-need to help Apple define more AppleEvents and useful ones too. When our applications begin talking to each other let’s hope that its’ not a tower of babel.
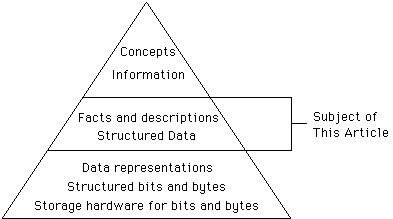
Figure 1. Database Levels
Database Models
There are three main database models: Relational, Network and Hierarchical.
The relational model is based on the theory of sets and derives power and simplicity from this related notion. Much of the activity surrounding the relational model is due to the ability to analyze relational structures readily with mathematical tools. This is especially true in query optimization, a field of study which has given us very flexible ubiquitous SQL3 servers and SQL based databases.
Performance is not one of the variables in all those equations that can be optimized so neatly. In the real world of daily computing the flexibility of the relational model is proven, but it’s performance is guaranteed to be less than a network model defined for the same problem definition. Of course, that flexibility can come in handy if your users will continue to come up with queries you never imagined they would!
The network model is based on the association. First, you define independent entities or record types, then the possible connections between them is defined through Parent/Child associations or sets. All “links” of interest are predefined so that the operations on the database stress navigation between bound data elements. Of course some operations have to do with reading and writing data.
One thing to keep in mind is that you can define many different record types, but they don’t actually come into existence (read - use disk space) until you create an instance of a record type. This has very important implications (for performance and space usage) and the “class-like” nature of a network view should be familiar to those who have experience with Object-oriented languages. That doesn’t mean that a network model database is Object-oriented. True Object-oriented databases (OODB) have other features that characterize them, not the least of which is that certain operations or transformations occur just by storing data into the database, without the program doing the storing knowing anything about it. OODB’s do different things based on the content/type of the information stored in them.
The hierarchical model is a specialization of the network model with the additional constraint that each collection of specific parents and specific children are distinct hierarchies. Children cannot be the parents of themselves or their parents (although they can be parents to their grandparents).
The network model uses direct addresses of data to “relate” one record to another. This “address” usually includes the file and the record within the file. The network model rarely duplicates information, except when it will enhance performance. As contrasted with the relational database model which duplicates key field information (Sometimes this is good), and keys are the “key”, so to speak, to the utility of the relational model. Keys are found in the record to be related, the key, and the record that is the object of the relation. (see figures 2 and 3)
 Figure 2 Relational Model
Figure 2 Relational Model
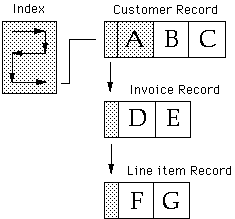
Figure 3 Combined Relational/Network Model
The shaded areas in figures 2 and 3 point out the overhead inherent in each technology for a given problem. There are three record types: the customer record, invoice record and line item record. For the relational model, Each customer will have one customer record and several invoices, with several line items per invoice. To relate invoices to a customer, a unique customer code (Account Number) is stored in each invoice record as a key. To find the invoices for a customer, you would search the index for this customer code. In the combined relational/network model, the customer record contains a key field, but no other record need contain that field. One customer has many invoices; one invoice has many line items. No redundant data is required because record addresses relate one record to another. Access is direct and therefore fast. If you need to change a record, you make only the one change, as no other records are affected. This means that referential integrity is assured (the same logical data is actually identical throughout the database).
Database technology is very complex. We don’t pretend to have given the best or even a totally adequate overview of the issues involved in database design. Design, whether in programming, architecture, dance, graphic arts or whatever is always the hardest part, implementation is just a matter of fulfilling the promise of the design (If it was promising at all).
Our Database
The example database which we are developing is called Technical Information Management System or TIMS for short. TIMS was designed to maintain a database of technical information contained in books, magazines, and journal articles. The original TIMS design was for the text interface only of some other kinds of computers. We took the exact same database and gave it a face lift and now we call it Hyper_TIMS.
Please note: the descriptions of the records/sets and other database definitions used in this article about Hyper_TIMS are not in some C language pseudo-code. They are written in the data description language (DDL) for db_VISTA III. These descriptions are input to the db_VISTA schema compiler and that spits out a database dictionary that the runtime system (from C, HyperCard, SuperCard, etc.) uses to manipulate the database. HyperCard is used to generate the user interface and Hyper_VISTA, db_VISTA for HyperCard, is used to do the database part. All the programming code and the example program were written in HyperTalk for HyperCard 2.0.
The info record type:
record info
{
unique key char id_code[16];
/* dewey dec. or own coding tech.*/
char info_title[80];
/* title of book, article, mag.*/
char publisher[32];
/* name of publisher - prob. coded*/
char pub_date[12];
/* date of publication (e.g. most recent copyright) */
short info_type;
/* 0 = book, 1 = magazine, 2 = article */
}
We are storing a unique 15 character id for the item (db_VISTA requires a NULL or binary zero at the end of every character field) , a 79 character title, a 31 character publisher, 11 characters for the publication date and a short integer (2 bytes, -32,000 to 32, 000) for the information class or type; book, magazine or article. You can define integers and longs as unsigned, if for instance you wanted to store numbers larger than 2 billion, but less than 4 billion. (Why ask why?)
Also, notice that the id code is preceded by the words “unique” and “key”. Key means that this field will/must have an index entry for each record instance. Unique means that each of those mandatory key entries must be different than all the others. We say that the keys are mandatory because you can have optional keys as well in db_VISTA. An optional key would be created only on those record instances which you wanted to be “keyed” in a certain way (read - quick to find). That really reduces overhead when your tracking “old ladies from Pasadena” in your “Bikers for Armageddon” database.
We want to store the author’s name of course, but why don’t we put it in the info record? Because, we may have several works by the same author and we don’t want to have duplicate information around (if there is no good reason). We’re going to propose that we have another record type that stores the author’s name. We’ll call it ... the author record.
record author
{
key char name[32];
/* author’s name: “last, first” or editor’s name */
}
So, we have a nice record with 31 characters of author name. Something else we would like to keep track of is an abstract containing a few words to a few paragraphs describing the content of each info entry. That calls for another record type. This time we will call it ... the abstract record. NO! sorry. We don’t want an abstract record.
If this abstract will be from 30 to 300 characters long we need a way of representing variable length data in a database that only allows fixed length records. You can’t have just one type of abstract record. The solution is that although you can have only fixed length records, you can dynamically link as many of those fixed length records very efficiently. So we will define a record type called “text”.
record text
{
char line[80]; /* line of abstract text */
}
Now to collect all the lines of text that might be included with an abstract we will define a SET called abstract.
set abstract
{
order last;
owner info;
member text;
}
This set called abstract is “owned” by the info record and has “members” that are text records. This is called a one-to-many relationship in the terminology of network databases. One info record may own many text records which together comprise the abstract. The phrase “order last” means that all new record instances added to a set will be added on the end of the list in entry order. The other possibilities are:
order first
new members are added (inserted at the front of the list)
order ascending
new members are added in ascending order based on the fields(s) indicated in the “by” clause of the “member” statement. (not shown)
order descending
new members are added in decending order based on the fields(s) indicated in the “by” clause of the “member” statement. (not shown)
order next
new members are added immediately following the current member of the set.
First, last, and next are the fastest ordering for inserting data into a set (retrieval is a constant (fast) time for all sets, all orderings), but ascending and descending are very powerful insertion ordering settings, especially since you can do the insertion on a “compound key”, a key made up of more than one field.
If there is less than or just 79 characters then I can store that abstract in one text record. If there are 80 characters then I will need two text records and waste 78 characters of space on the disk. If the user adds 50 characters to the abstract then I will not need any new record creations or record “hole” shuffling to store the additional data and will speed along at a clip that a variable length database would truly envy.
Fixed length records are both a blessing and a curse. If you like things simple and reliable then fixed length is for you. Fixed length database records are also quite handy in the event of a disaster. If you have a known good starting point, then you can even “read” the data in a text editor such as QUED4.
You may say that if there are no bugs in the database software (your’s or their’s) then you will never have a failure. Our experience tells us something quite different. Many of you have never suffered from electrical power problems. We have, or more precisely, we have had clients that did. Same difference. We suffered.
If you hate wasting even one byte then you had better stay up late nights thinking of clever and time consuming ways to keep the data as small as theoretically possible. Of course, we didn’t discuss data compression/encryption on the fly ... with very secure keys (well, not completely secure, we survived to tell about it) ... that get blown along with log file... (who did what?)
Ok. so we have the abstract. We should also keep a list of topical key words on each info record that are indexed for fast retrieval of info records based on a word or phrase. This calls for a record type and a set to relate the keywords to the info record.
record key_word
{
unique key char word[32];
/* subject key words or classification */
}
We have a problem. If we have a set that relates a key word to an info record something like:
set info_to_key
{
order last;
owner info;
member key_word;
}
You know that a set can have only one “owner” record instance (you know because we just told you), then if we use the same keyword for more than one info record we will be creating redundant data again, because each info record will have to own a duplicate of that particular keyword record.
This “limitation” of one-to-many sets is really an efficiency issue rather than a logical position. It’s almost a biological argument. Each set that a record is a member of enables that record to contain three record addresses. The owner record, the member before the current record and the member afterward. Each set that a record owns enables that record to contain just two record addresses the first member in the list and the last member record. Any owner record also has a counter, for each set, so that finding how many members are there is very quick and does not require counting.
A record can belong to more than one set and you can have two or five or ten sets with owners from record type A and members from record type B. This would mean that a member record from type B could have up to ten “fathers/owners” each enabled from a different set relationship. They could even be the same record, record 31 from type A owning record 76 from type B ten times.
This might serve some purposes very well indeed. The problem is that if you can only have ten “fathers” what happens when father number eleven shows up. In the context of our discussion. If we have ten info records “using” the same keyword, what happens when we want to add another info record and use that keyword. Create another keyword record? Well, at least we have reduced the redundancy by a factor of ten, n’est pas? NO CAN DO! That simply wouldn’t be civilized.
Now, the set/network stuff really gets hairy. What we want is to reuse keywords for more than one info record. This is reasonable. If the keyword were “Macintosh” there would be lots of references in our library.
So, let’s define a set like the following:
set info_to_key
{
order last;
owner info;
member intersect;
}
another set like this:
set key_to_info
{
order last;
owner key_word;
member intersect;
}
And an intersect record that looks like this:
record intersect
{ /* copy of info_type to save I/O */
short int_type; /* when looking only for, say, books */
}
What we have done is quite awesomely simple and yet one of the most subtle powers of the network model. We have an info record, say it’s info record A. Info record A “owns” intersect record B. Intersect record B is also owned by keyword record C. A record can have as many “owners” as you want. In this case instead of the owners being from the same record type they are from different record types.
One little ole’ intersect record will tie together one particular keyword record with one particular info record. If I have a keyword, all the members of my key_to_info set have owners (of their info_to_key sets) that are all the info records to which the keyword applies. If I have an info record, all the members of my info_to_key set have owners (of their key_to_info sets) of their that are all the keyword records which describe the info record.
There is a many keyword records to many info records relationship. The famous many-to-many network model concept as implemented in db_VISTA. No matter how many info records and keyword records are created. You can locate one or the other group of records very quickly and that’s a simple example. Also note, that a single keyword of a particular type is stored ONCE in the database. The myriad connections between info records and keywords are represented by many intersect records whose main purpose is to be a cog in the wheel of Hyper_TIMS.
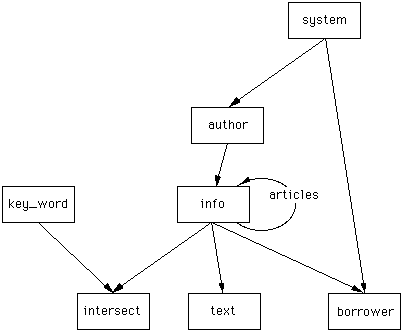
Figure 4 Hyper_TIMS Database Schema
Now we should clear up some design decisions and get on with the database implementation. In db_VISTA there is a record called the System record which is automatically created for you when your database starts up. Any sets that have the System as their owner are initialized for you to have a current owner and a current first member. There is only one instance of this record and it contains no data. This is the root record of choice when you are using a set and don’t have a ready made owner picked out. You don’t ever have to use the system record, but it is convenient. The network model and many of the navigation commands assume an owner, any owner, exists. The two sets author_list and loan_history are used to initialize an owner that will never be used other than to hold a place as owner of those respective records.
Since you will want to find records in the set author_list, this implementation is only sufficient for a small library of say less than 100 authors, if you get beyond that, then you would have to look into creating an index on the author name and using that to find authors. Take note that you would continue to use set connections for the author to info or info to keyword connection. In the case where you will be doing lots of searching then keys work better on large data sets. If you will be creating and maintaining relationships/associations among record instances then sets will be far more efficient and save on redundant data.
There is a set called loaned_books which connects the borrower record to the info record for the loaned item. These borrower records will remain in the system even when the book is returned to provide a book/magazine/article loan history. The set loan_history will browse through the borrower records without an info record. If the info record is deleted then the borrower records for that item are deleted as well. Also, notice the set article_list. This set has info records as both owners and members. This is perfectly legal in db_VISTA and represents some info records which are articles and members of a set whose owner is the magazine (another info record) the articles appeared in. That functionality is not implemented in the demo program, but its’ nice to know that it can be done.
In the record borrower, there are two dates. Each date is defined as an unsigned long integer. The reason for this is that the data is stored as seconds since January, 1 1904. This is the time value that can be retrieved from the internal Macintosh Clock.
The set has_published links authors with the info records. Because that set definition includes the line “member info by info_title”, all the info records will be in ascending alphabetical order within a particular author.
Here is the complete Hyper_TIMS Database Schema as input to the db_VISTA database definition language processor (DDLP):
/* 1 */
/*--------------------------------------------------------
Technical Information Management System (TIMS) Database
----------------------------------------------------------*/
database tims
{
data file “tims.d01” contains system, info, intersect;
data file “tims.d02” contains author, borrower, text, key_word;
key file “tims.k01” contains name, id_code;
key file “tims.k02” contains friend, word;
timestamp records;
record author
{
key char name[32];
/* author’s name: “last, first” */
} /* or editor’s name */
record info
{
unique key char id_code[16];
/* dewey dec. or own coding tech.*/
char info_title[80];
/* title of book, article, mag.*/
char publisher[32];
/* name of publisher - prob. coded */
char pub_date[12];
/* date of publication (e.g. most recent copyright) */
short info_type;
/* 0 = book, 1 = magazine, 2 = article */
}
record borrower {
key char friend[32]; /* name of borrower */
unsigned long date_borrowed;
unsigned long date_returned;
/* dates are stored as numeric in seconds since 01/01/1904 */
}
record text {
char line[80]; /* line of abstract text */
}
record key_word {
unique key char word[32];
/* subject key words or classification */
}
record intersect { /* copy of info_type to save I/O */
short int_type; /* when looking only for, say, books */
}
set author_list {
order ascending;
owner system;
member author by name;
}
set has_published {
order ascending;
owner author;
member info by info_title;
}
set article_list {
order last;
owner info;
member info;
}
set loaned_books {
order last;
owner info;
member borrower;
}
set abstract {
order last;
owner info;
member text;
}
set key_to_info {
order last;
owner key_word;
member intersect;
}
set info_to_key {
order last;
owner info;
member intersect;
}
set loan_history {
order last;
owner system;
member borrower;
}
}
We now know enough to begin examining the functionality that Hyper_TIMS represents and the kind of system that can be generated with Hyper_VISTA.
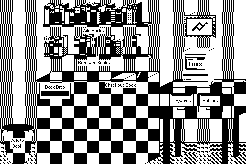
Figure 5 The Hyper_TIMS navigation scene
The Hyper_TIMS navigation scene represents the various operations that can be performed. Starting at the top you can Add Books, See Borrowed Books, Checkout Books, Return(Drop) Books, Search the database by Keyword, Search the database by Author and Delete a Book. The picture on the wall is the Ajalon Logo and is an about box, the Macintosh on the table is the place to open the database. The stack/program doesn’t automatically open a database upon starting up to give the user the option of maintaining multiple databases for different libraries around the house. Opening another database automatically closes the current one.
Let’s look at the OpenStack script for Hyper_TIMS:
--2 on OpenStack global KEYWORD, AUTHOR_LIST, NAME, KEY_TO_INFO, INFO_TO_KEY, INTERSECT global HAS_PUBLISHED, THELINE, ABSTRACT, LOANED_BOOKS, LOAN_HISTORY, AUTHOR global INFO_TITLE, ID_CODE, INFO, DATE_RETURNED, BORROWER, ARTICLE_LIST, KEY_WORD global TEXT -- set up the Database constants -- Record Name Constants put 10000 into AUTHOR put 10001 into INFO put 10002 into BORROWER put 10003 into TEXT put 10004 into KEY_WORD put 10005 into INTERSECT -- Field Name Constants put 0 into NAME put 1000 into ID_CODE put 1001 into INFO_TITLE put 2002 into DATE_RETURNED put 3000 into THELINE put 4000 into KEYWORD -- Set Name Constants put 20000 into AUTHOR_LIST put 20001 into HAS_PUBLISHED put 20002 into ARTICLE_LIST put 20003 into LOANED_BOOKS put 20004 into ABSTRACT put 20005 into KEY_TO_INFO put 20006 into INFO_TO_KEY put 20007 into LOAN_HISTORY hide menubar end OpenStack
The database constants are found in an output file from the DDLP. This file is normally in the format of a C language header file. Hyper_VISTA includes utilities that convert this format into a standard openStack handler that you can then modify. Here we hide the menubar.
Once you have opened a database by clicking on the Hyper_TIMS Macintosh you might click on the keywords drawer just below the Mac. That would allow you to double click on a keyword or single click and press the “publications” button. Here is the publications button script.
--3 on mouseUp -- do a keyword search if the clickLine is empty then exit mouseUp get the value of the clickline send “findKeyword it” to card field “Publication List” end mouseUp
Take the selected line and send it to the scrolling field “Publication List”. So, the field does the work of filling itself.
Here’s the field script.
--4
on findKeyword searchFor
global d_status, KEYWORD, KEY_TO_INFO, INFO_TO_KEY
global HAS_PUBLISHED, NAME
set lockscreen to true
if searchFor is empty then exit findKeyword
set scroll of me to 1
set cursor to watch
get d_(keyfind, KEYWORD, searchFor)
if ErrorHandler() then exit findKeyword
-- Scan through KEY_TO_INFO Set
get d_(setor, KEY_TO_INFO)
if ErrorHandler() then exit findKeyword
get d_(findfm, KEY_TO_INFO)
if ErrorHandler() then exit findKeyword
repeat while d_status is “OK”
get d_(findco, INFO_TO_KEY)
get d_(recread)
put it into theRecord
get d_(findco, HAS_PUBLISHED)
get d_(crread, NAME)
put it into theName
put return & “ID Code: “ && first line of theRecord after buffer
put return & “Author: “ && theName after buffer
put return & “Title: “ && second line of theRecord after buffer
put return & “Publisher: “ && third line of theRecord after buffer
put return & “Date Published: “ && fourth line of theRecord after
buffer
put return after buffer
put return & “Key Words:” & return & “----------” after buffer
put return & KeyWords() after buffer -- list any associated with
this entry
put return & “Abstract:” & return & “----------” after buffer
put return & Abstract() after buffer -- list any associated with
this entry
put return & “=====================================” after buffer
get d_(findnm, KEY_TO_INFO)
end repeat
delete line one of buffer
put buffer into me
end findKeyword
The first Hyper_VISTA command we see is d_keyfind. All Hyper_VISTA commands are functions that return a value in the global “it”. For most commands the value is empty or null. Every Hyper_VISTA command also fills the global variable “d_status” with the value “OK” or an error message. Armed with this knowledge and the appendix at the end of the article you will be able to examine and understand the scripts throughout Hyper_TIMS.
So, we do a keyfind on the keyword field of the keyword record type (the only field), using the value “searchFor” which came from the other scrolling list. We then check for an error condition. The error handler is located in the stack script so that it will be available to the entire stack from anywhere.
The Errorhandler looks like this:
--5
function ErrorHandler
global d_status
if d_status is not “OK” then
if d_status contains “database not opened” then
put “Please open a database by clicking on the TIMS Macintosh”
into theMessage
answer theMessage with “OK”
else
put “result is (“ && d_status && “)” into the message box
return true
end if
end if
return false
end ErrorHandler
This simple error handler has proven all that we needed to develop Hyper_TIMS. A serious development effort would include much more extensive error handling, but we have found that once simple database logic bugs are dealt with, the stack doesn’t generate error conditions. In Hyper_VISTA there are two types of error messages, User and System. User errors are errors that shouldn’t happen under “normal” circumstances, like sending a field constant to a routine that requires a set constant. These correspond to programming errors on the part of the user/programmer. System errors on the other hand indicate perhaps fatal errors such as running out of disk space or memory.
After finding the correct keyword we perform a d_setor with the key_to_info set, and a d_findfm with the key_to_info set. The command d_setor “Sets the owner of a set from the current record”. Hyper_VISTA has a concept of a current record, current owner (for each set) and current member (for each set). d_keyfind sets up the current record by finding something. The command d_setor sets up an owner for key_to_info and d_findfm locates the first member of key_to_info and makes that member the current member and the current record.
Now, we execute a repeat loop until there are no more info records that are related to this key. First we do a d_findco which finds the current owner of the current member of key_to_info in the info_to_key set. This is our many-to-many navigation. And produces an info record as the current record. We read that record in using d_recread and store it into the container called “theRecord”. We perform another d_findco, this time looking for the owner of the current info record in the has_published set, which yields an author record and a name. The name is retrieved by the command d_crread which reads the field represented by the NAME constant from the current record (an author record). That name and information from the saved info record is used to display information about the book entry.
Next, we execute the function Keywords and then Abstract. We will show you the Keywords script first. It is located in the stack script so that it would be accessible from anywhere in the stack. Also, it is a function so that it only depends on the state of the database but could report its findings to any handler - button, card or field in the stack.
--6
function KeyWords
global d_status, INFO_TO_KEY, HAS_PUBLISHED, KEY_TO_INFO, KEYWORD
-- the current member of the HAS_PUBLISHED Set is the info
-- record whose key words are to be listed
get d_(setom, INFO_TO_KEY, HAS_PUBLISHED)
if ErrorHandler() then return empty
-- get number of members of INFO_TO_KEY
put d_(members, INFO_TO_KEY) into NumMembers
if NumMembers > 0 then
-- save current member of KEY_TO_INFO
put d_(csmget, KEY_TO_INFO) into DatabaseAddress
get d_(findfm, INFO_TO_KEY)
repeat while d_status is “OK”
-- find, read, and display corresponding Key Word
get d_(findco, KEY_TO_INFO)
if ErrorHandler() then exit KeyWords
get d_(crread, KEYWORD)
put return & it after buffer
get d_(findnm, INFO_TO_KEY)
end repeat
put return after buffer
get d_(csmset, KEY_TO_INFO, DatabaseAddress)
end if
delete line 1 of buffer
return buffer
end KeyWords
With the current member of has_published set up prior to arriving at the keywords function we want to first set up that info record as the owner of the info_to_key set using the d_setom command. This command sets the current owner of the first set from the current member of the second set. This assumes that the current member record type of the second set can be a legal owner of the first set. So, whew! Now, I want to know how many members (keywords or intersect records) are in the info_to_key set. I put that value into the container “NumMembers”.
If there are any then we save the current intersect record in the key_to_info set. The only reason we do that here is that in the future we may want the keywords function to return all the keywords attached to an info record and then to return another kind of traversal of the keywords themselves using the key_to_info set with the same intersect record that it entered the function. The command d_csmget retrieves the database address of the current member of the set key_to_info. This is stored in the container databaseAddress.
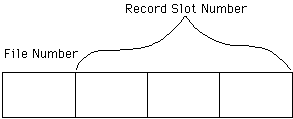
Figure 6 db_VISTA/Hyper_VISTA database address
A database address is a four byte structure. First, there is just one byte that indicates which of the 0 - 255 files the data record is stored in and then a three byte record slot address (remember all the records are fixed length within a record type). This slot address can be any number between 1 and 16,777,215. The zeroth record slot is reserved for internal use. Once a record is created, that record is assigned a slot number within a file for it’s lifetime. The database address of a record instance will not change. The speed of db_VISTA is partly due to the fact that the retrieval of a record instance once you have the database address is a simple “offset + (record length * slot number)”, then read “record length” bytes. The offset is a value that indicates the record type overhead at the beginning of the file. This overhead involves sets and keys and is minimal.
You could take a database address and store it in a file and then shut down the system. Upon bringing the system up you could read that file, make that database address the current record and read the data from that very record. That should stimulate your database imaginings. Well, we have saved the address and now we find the first member of info_to_key using the d_findfm command and loop finding the owner of the key_to_info set (remember we are looking at an intersect record), this will be a keyword attached to our info record. We read the keyword using d_crread which simply reads the field indicated by the constant sent down returns that value. The we put a return character and “it”(the return value from all Hyper_VISTA functions) into a local variable/container called “buffer”.
In HyperCard the first use of a local variable defines it. HyperCard is essentially a typeless language. Hyper_VISTA is a strongly typed database and merely assumes that the user enters proper information. Hyper_VISTA will store “12345” as a string if that’s what the database field your trying to stuff it into is defined as or it will store it as a number if that is what the field is defined as. Hyper_VISTA doesn’t care to meddle in your business. If you want to put error checking in your program, that’s fine. Don’t expect HyperCard or Hyper_VISTA to care.
Except for a d_csmset command to restore the current member of the key_to_info set that is all there is to the keyword collector. Let’s look at the Abstract collector handler from the stack script.
--7
function Abstract
global d_status, ABSTRACT, HAS_PUBLISHED, THELINE
get d_(setom, ABSTRACT, HAS_PUBLISHED)
if ErrorHandler() then return empty
-- get number of lines in ABSTRACT
put d_(members, ABSTRACT) into NumLines
if NumLines > 0 then
get d_(findfm, ABSTRACT)
if ErrorHandler() then exit Abstract
repeat while d_status is “OK”
-- find, read, and display corresponding Key Word
get d_(csmread, ABSTRACT, THELINE)
put return & it after buffer
get d_(findnm, ABSTRACT)
end repeat
end if
delete line 1 of buffer
return buffer
end Abstract
First, we perform a d_setom command, then find out the number of lines of abstract. If there are any we find the first member of the abstract set and loop until they have all been read in and concatenated into the “buffer” container. The buffer container is then fixed up and returned.
We hope that your appetite for a look at db_VISTA and Hyper_VISTA has been wetted and that you will look at the rest of the scripts to understand how they work as well. For the developer using db_VISTA under THINK C or MPW C, the HyperCard version is a good tool to prototype interface elements and to deliver simple utilities. For the serious HyperCard developer, well ... we need to talk. SuperCard is supported as well. We also hope to support Object Pascal, BASIC, Fortran, etc. in the near future. A multiuser version for HyperCard will be out coincident with the release of System 7.0 (Tell us, when is that?). Actually, we may be a few months late ...
This HyperCard stack is available on the MacTutor Source code disk and you’re welcome to try all the commands available. Remember that Hyper_VISTA needs the XFCN with the name “d_” and ALL the CCOD resources. Also, be sure to copy the “STR#” resources with ID’s 2000 and 4000. These contain the user and system error messages respectively. Hyper_VISTA will return error numbers without the string resources, but since you don’t have the documentation ... Also, Hyper_VISTA is totally dependent on the “tims.dbd” file which contains the data dictionary. Actually you can copy the resources all you want, but you’ll always be using a document storage and retrieval database. There are some “key” commands that are not in the version on the MacTutor disk. How else do you expect us to buy all our Mac Toys.
Thank you, enjoy and Happy Hyper-ing.
Ajalon
Appendix
In this appendix is a list of all the commands that db_VISTA/Hyper_VISTA has defined for this demo stack. Not all of the commands were used in the stack and afford the interested reader the opportunity to implement features we did not using some of the unused commands. Again, this is NOT a complete command set from db_VISTA or from Hyper_VISTA. This is for demonstration purposes only. For information on the full set of commands and the C language version please contact Ajalon directly at (206) 946-8178.
Operation Usage Explanation
d_close d_(close) Will close all open database
d_cmtype d_(cmtype, SET) Return the type/class of the current member of the SET
d_connect d_(connect, SET) Connect current record to set
d_cotype d_(cotype, SET) Return the type/class of the current owner of the SET.(Use mainly for database consistency checking)
d_crget d_(crget) Returns the database address of the current record. used with d_crset
d_crread d_(crread, FIELD) Return a single field of data from the current record
d_crset d_(crset, DatabaseAddress) Assign the current record from the database address given. used with crget
d_crtype d_(crtrype) Returns the record type/class of the current record
d_crwrite d_(crwrite, FIELD, value) Write a value into FIELD on the current record.
d_csmget d_(csmget, SET) Get database address of current member of SET
d_csmread d_(csmread, SET, FIELD) Get FIELD from current member of SET
d_csmset d_(csmset, SET, databaseAddress) Assign the current member of SET from the database address given. The current owner of SET is also set to the “owner” of the record at databaseAddress
d_dbdpath d_(dbdpath, STRING) Set the path to the data dictionary file(s). This must be called before any database is opened
d_dbfpath d_(dbfpath, STRING) Set the path to the data and key file(s). This must be called before any database is opened
d_delete d_(delete) Delete the current record from the database. The record must be removed from all sets of which it is an owner or member, otherwise you will get an error message “S_ISMEM” or “S_HASMEM”. Has member or is member? Get it?
d_discon d_(discon, SET) Disconnect current member of SET from the SET
d_disdel d_disdel(disdel) Disconnects all members that are owned by current record and disconnects the current record from any sets of which it is a member and then deletes the record.
d_fillnew d_fillnew(RECORD, value) Create and fill a new record of RECORD type/class with the values given. In Hyper_VISTA fields are separated by returns in a “container”
d_findco d_(findco, SET) Find the owner of the current record in SET and make it the current record
d_findfm d_(findfm, SET) Find first member of SET and make that record the current member of SET and the current record
d_findlm d_(findlm, SET) Find last member of SET and make that record the current member of SET and the current record
d_findnm d_(findnm, SET) Find the next member of SET, according to the ordering set in the DDL. Make that record the current member of SET and the current record
d_findpm d_(findpm, SET) Find the previous member of SET according to the ordering set in the DDL. Make that record the current member of SET and the current record
d_keyfind d_(keyfind, FIELD, value) Find a record by key/index. The value given can be from another file, the user or an expression. Make that record the current record
d_keyfrst d_(keyfrst, FIELD) Find the record with the first key in FIELD. Make that record the current record
d_keynext d_(keynext, FIELD) Find the record with the next key after the current record in FIELD. Make that record the current record
d_keyread d_(keyread) Return the value of the last found key in a key retrieval function, such as keyfind, keyfrst, keylast, keynext, etc.
d_members d_(members, SET) Return the number of members currently in SET for the current owner of SET
d_open d_(open, STRING) Open the databases indicated in the STRING variable. Multiple databases can be opened at one time. To open two databases “tims” and “joe” you would use d_(open, “tims;joe”), separating databases by a semicolon. Many commands accept an optional parameter on the end which indicates which database is being addressed.
d_recread d_(recread) Returns the current records fields in a <CR> delimited “container”. Numbers are converted to a string representation.
d_setmo d_(setmo, MSET, OSET) Assign the current owner of OSET to be the current member of MSET
d_setmr d_(setmr, SET) Set the current member of SET from the current record
d_setom d_(setom, OSET, MSET) Assign the current member of MSET to be the current owner of OSET
d_setor d_(setor, SET) Set the current owner of SET from the current record
d_setpages d_(setpages, dbpages, ovpages) Specify the number of pages to be used in the internal virtual memory cache of db_VISTA (dbpages) and the number of pages to be used in the transaction overflow file cache (Multiuser Only).
d_setro d_(setro, SET) Make the current owner of SET, the current record as well
Footnotes
1 Macintosh is a registered trademark of Apple Computer, Inc.
2 dbase is a trademark of Ashton Tate, Inc. (As we write this Ashton Tate has LOST a round in district court to uphold their copyright on the dbase language, WOW!)
3 Structured Query Language, developed in the 60’s by IBM (I. B. ought M. acintosh)
4 QUED is a trademark of Paragon Software and is an excellent text editor for programmers which can read binary data almost as easily as regular printable ASCII.



- SPREAD THE WORD:

- Slashdot

- Digg

- Del.icio.us


- Newsvine
