



Das folgende Kapitel verschafft Ihnen einen ersten Überblick über die vorhandenen Auszeichnungssprachen und hilft Ihnen, XML in die bisher bestehenden Standards einzuordnen. Lernen Sie Stärken und Schwächen von SGML und HTML kennen, und erfahren Sie, warum in XML eine Chance für die Zukunft der Textbeschreibung liegt.
Betrachten wir eine moderne Textverarbeitung wie etwa Microsoft Word, dann bietet uns diese zum Erstellen unserer Texte zahlreiche Möglichkeiten der Formatierung. Im Gegensatz zu den Ursprüngen der Textgestaltung haben wir heute Möglichkeiten, die früher nur dem Drucker oder Setzer vorbehalten waren. Dem normalen Anwender standen selbst mit einer komfortabel anmutenden modernen elektrischen Schreibmaschine nur sehr begrenzte Layoutfunktionen zur Verfügung. Neben hoch- und tiefgestellten Buchstaben konnte man auf Sperrschrift oder Fettschrift zurückgreifen. Von einem befriedigenden Ausdruck oder gar einer befriedigenden Textgestaltung konnte man hier wohl nicht reden.

Abb. 2.1: Ein professionelles Dokument zeichnet sich nicht unbedingt durch die Vielzahl der genutzten Funktionen aus.
Eine Textverarbeitung im heutigen Sinne bietet jedem Anwender jene zahlreichen Möglichkeiten der Gestaltung, die früher nur den Profis vorbehalten waren. Angefangen bei Fettschrift, kursiv oder unterstrichenem Text handelt es sich hier in erster Linie um optische Elemente, die wir verändern können. Und seit die ersten Apple-Macintosh-Computer das Licht der Welt erblickten, ist WYSIWYG (»What you see is what you get«) in aller Munde. Jeder, der ein solches Programm bedienen kann, wird in die Lage versetzt, schon am Bildschirm den Text genau so gestalten zu können, wie er anschließend aus dem Drucker kommt.
Spätestens wenn wir wieder einmal ein Dokument erhalten, in dem sieben verschiedene Schriftarten eingesetzt sind, wissen wir: hier wurde mit einem DTP-Programm (»Desktop Publishing«) gearbeitet. Diese Programme haben eins gemeinsam: Sie bieten auch dem Laien unüberschaubar viele Möglichkeiten, auf die visuelle Darstellung des Textes Einfluß zu nehmen. Am Rande sei bemerkt, daß dies dem Aussehen des Textes nicht immer zum Vorteil gereicht.
Auszeichnungssprachen wie HTML verfolgen aber primär eine andere Richtung der Textauszeichnung. Hier geht es nicht in erster Linie um die optische Gliederung eines Textes, sondern viel mehr um eine inhaltliche Abgrenzung.
Text allein reicht natürlich heute kaum noch zur angemessenen Darstellung von Informationen aus. Aber auch im Zeitalter von Multimedia, in denen zahlreiche Tonwiedergaben und Grafikanimationen und Videosequenzen Internet-Seiten nicht immer nur bereichern, ist der wichtigste Bestandteil einer Seite der Text. Das Internet ist trotz aller anders klingenden Verlautbarungen ein deutlich textorientiertes Medium, schon allein aus dem Grund, weil nur Text hard- und softwareunabhängig von jeder Computerplattform dargestellt werden kann.
Wenn Sie sich eine Internet-Seite, die heute üblicherweise noch in HTML programmiert wird, einmal genauer anschauen, erkennen Sie allerdings, daß mit dieser Textauszeichnungssprache doch noch mehr zu machen ist als nur einfachen Text darzustellen.
Ein Dokument dient als Grundlage zur Strukturierung einer Seite. In dieser Struktur ist festgelegt, welche weiteren multimedialen Inhalte integriert sind. Das heißt auch, eine Seite ohne Text benötigt eine Textauszeichnungssprache als Basis zur Definition des Inhaltes.
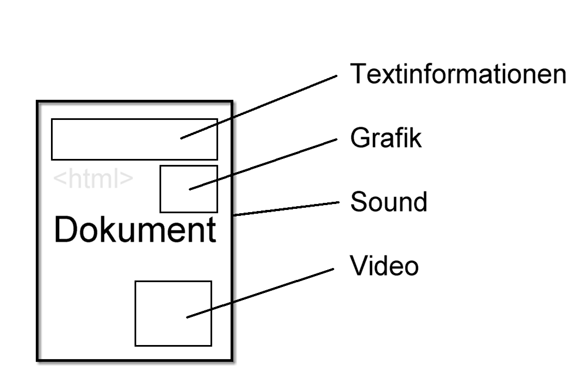
Abb. 2.2: Im HTML-Dokument sind alle Bestandteile der Seite integriert.
In dem Dokument ist bestimmt, welche Bilder, Videos oder Sounds zur Seite gehören. Der gesamte visuelle Eindruck muß hier bestimmt werden. So ist auch zu verstehen, daß trotzt deutlicher multimedialer Ausrichtung des Internets kein völlig neues Format, sondern ein über lange Zeit entwickeltes Textformat die Aufgabe übernimmt, und zwar als integrative Basis für darauf aufbauende Informationsinhalte.
Eine von der WYSIWYG-Welt unabhängig entwickelte Idee ist es aber, Informationen nicht nach rein visuellen Gesichtspunkten aufzubauen, sondern strukturiert nach Inhalten festzulegen.
Diese Idee ist nicht ganz so neu, und eigentlich ist sie zumindest in der EDV-Welt schon älter als die Idee des Desktop Publishing. Schon 1967 beschäftigte sich William Tunnicliffe mit dem sogenannten »Generic Coding«.
Er trennte die Informationsstruktur des Textes von seinem optischen Erscheinungsbild. Zu dieser Zeit war es noch so, daß allein der Setzer für das spätere Druckbild verantwortlich war und der Autor lediglich Anmerkungen und Hinweise für den Druck notieren konnte.
Damals begann man langsam, die ersten Texte auch digital mit Hilfe des Computers zu speichern. Der Autor konnte zwar notieren, daß eine Überschrift beispielsweise groß und in Fettschrift gedruckt werden sollte, die Information, daß es sich dabei aber um eine Überschrift handelte, ging bei der Computerverarbeitung leider verloren. Die Weiterentwicklung von William Tunnicliffe kennen wir heute übrigens als SGML-Standard.
Die Auszeichnungssprachen, von denen im folgenden die Rede sein wird, sind also in erster Linie Hilfen, um einen Text strukturell zu definieren. Natürlich ist der Übergang beispielsweise bei HTML heute fließend zwischen optischer und inhaltlicher Auszeichnung. Selbstverständlich bietet diese Sprache heute bereits zahlreiche Möglichkeiten, Text auch optisch auszuzeichnen.
Aber wir wollen hier die Grundintention nicht vergessen: Informationen durch den Computer nicht nur darzustellen, sondern auch inhaltlich auszuwerten.

Abb. 2.3: Die drei Teile des Dokuments können auch in einer
Datei gespeichert sein.
Die heutige Entwicklung geht dazu über, ein Dokument in drei Teile zu zerlegen. Ein Teil stellt die reine Text und Bildinformation, also den Inhalt, dar. Zusätzlich ist die Struktur der Information elektronisch gespeichert. Der nächste logische Schritt ist, für die vorhandene und definierte Struktur auch ein bestimmtes Layout als Formatvorlage festzulegen. Ob man dabei alle drei Teile in dem Dokument selbst oder in externen Dateien ablegt, spielt für das Endergebnis keine Rolle.
Ein großer Vorteil einer solchen Struktur gerade für den Online-Bereich ist, daß der Desktop-Computer diese Daten nach der Übertragung selbst weiterverarbeiten kann. Der PC, mit dem man im Netz surft, ist meist mit der Darstellung von Webinhalten chronisch unterfordert. Die meiste Zeit wartet man wohl darauf, daß Webserver die eigenen Such- oder Datenbankanfragen verarbeiten und Ergebnisse senden. Die neue XML-Technologie schafft die Möglichkeit, einen Teil der Datenverwaltung auf den Desktop-PC zu übertragen, und ist so vielleicht ein neuer Schritt zum schnelleren Web.

Abb. 2.4: Die Möglichkeiten der Strukturierung in den verschiedenen Datenformaten.
In die bisherigen Technologien zur Strukturierung eingeordnet, steht XML zwischen dem völlig unstrukturierten Text und den Möglichkeiten zur komplexen Datenstruktur einer Datenbank.
Es gibt eine Reihe von alternativen Formaten, die für die inhaltliche Auszeichnung und Strukturierung entwickelt wurden und sich auch heute noch zahlreich im Einsatz befinden.
Jedes Datenbankprogramm stellt eine solche Form von inhaltlicher Auswertung dar. In einer Datenbank können in mehr oder weniger starren Datensätzen einzelne Datenfelder gespeichert werden. Der Nachteil liegt auf der Hand: Aufgrund der starren Datenstruktur, die vorgegeben wird, ist ein sinnvoller Einsatz dieser Lösung nur für gleichmäßige, homogene Datenmengen möglich.
Abb. 2.5: Für gleichmäßige Datenstrukturen bieten sich spezielle Datenbankformate an.
Jede Datenbank ist von einer speziellen Software und damit einem bestimmten Computer- System abhängig, auf dem sie entwickelt wurde. Auch wenn inzwischen viele übergreifende Formate existieren, die den Datenaustausch ermöglichen, besteht dieses Problem grundsätzlich.
Viele Formate nutzen zusätzlich zur Speicherung ein binäres Format, das den Austausch zwischen verschiedenen heterogenen Sprach- und Rechnersystemen nicht gerade erleichtert.
Ein Ansatz zum Dokumentenaustausch zwischen verschiedenen Systemen besteht in der Verwendung des sogenannten MIME-Standards. Dieser beschreibt weniger einen einheitlichen Standard zu Informationsspeicherung, als vielmehr eine Möglichkeit der Verständigung zwischen Sender und Empfänger darüber, welches Format zum Einsatz kommt.
Im praktischen Einsatz teilt der Web-Server dem Browser, der die Daten anfordert, mit, um welchen MIME-Typ es sich handelt. Der Browser kann dann auf die entsprechend ankommenden, meist binären Daten angemessen reagieren. Entweder kann der Browser die Daten selbst verarbeiten, respektive anzeigen oder er greift auf die Hilfe eine Zusatzprogramms (ein sog. »Plug-In«) zurück.
Eine MIME-Typ-Bezeichnung besteht aus zwei Bestandteilen: dem Haupttyp und dem Subtyp. Der folgenden Tabelle können Sie einige Standard-MIME-Typen entnehmen. Einige MIME-Typen, wie z.B. Word oder Excel, gehören nicht zum ursprünglichen Standard, wurden von uns aber der Vollständigkeit halber hinzugefügt.
Im Internet findet sich das MIME-Verfahren im HTTP-Protokoll wieder; es informiert den Browser darüber, welche Art von Daten gesendet werden. Die Standard-MIME-Typen sind in der Norm RFC 1590 definiert.
Einige Formate, die heute breite Anwendung vor allem im Druckbereich finden, möchten wir kurz vorstellen. Sie zeigen, daß portable Dokumentformate auch außerhalb des Webs eine hohe Bedeutung erlangt haben. Vielleicht wird auch XML in das eine oder andere dieser Segmente vorstoßen können und eine sinnvolle Alternative für den Austausch von Dokumenten in allen Bereichen der elektronischen Informationsverarbeitung darstellen
Gerade in großen Unternehmen, in denen eine Flut von Dokumentationsmaterial anfällt, möchte man sich nicht gerne auf ein systemgebundenes Datenformat festlegen. Schließlich möchte man auch in vier oder fünf Jahren, wenn das Textverarbeitungsprogramm bereits drei Versionsnummern weiter ist, auf die vorhandenen Informationen zurückgreifen.
Außerdem muß der Austausch zwischen verschiedenen Ländern und Systemen, zumindest zwischen PC-Welt und Macintosh, sichergestellt werden, Formate also, die den Autoren oder Nutzer von der Wahl des Werkzeuges unabhängig machen. Für diese Anforderungen existieren einige Formate, die sich breiter Zustimmung erfreuen.
Mit PostScript existiert eine komfortable Lösung zum Austausch von Dokumenten zwischen unterschiedlichen Computer-Plattformen. Die Besonderheit besteht darin, daß sich PostScript-Dateien unter jedem Betriebssystem ohne weitere Software auf einem PostScript- Drucker ausgeben lassen. Die meisten hochwertigen Drucker und Satzbelichter sind zum PostScript-Standard kompatibel. PostScript-Dokumente werden typischerweise von der Textverarbeitung oder dem Grafikprogramm automatisch aus dem programminternen Format übersetzt und dann zum Drucker geschickt.
Der große Vorteil von PostScript liegt in der großen Hardware-Unabhängigkeit. Die Datei beschreibt lediglich das Aussehen der Seite, macht aber keine Annahmen über Bildschirm oder Drucker. So kann dieselbe Datei sowohl auf einem 75 -dpi-Bildschirm als auch auf einem 600-dpi-Lasedrucker oder 2400-dpi-Satzbelichter ausgegeben werden. In der Praxis bedeutet das, vor der teuren und hochwertigen Belichtung kann ein einfacher Probeausdruck auf einem handelsüblichen Laser- oder Farbtintenstrahldrucker erstellt werden.
Als Erweiterung zum PostScript-Format hat die Firma Adobe das Portable Document Format entwickelt. Zusätzlich können mit ihm Seiten- und Inhaltsstrukturen erfaßt werden. Der Text wird am Bildschirm lesbar und durchsuchbar.

Abb. 2.6: Das PDF-Format bietet einen Ansatz zur plattformübergreifenden Verbreitung von Dokumenten. Es findet heute auch im Web großen Zuspruch. Zahlreiche downloadbare Handbücher finden sich bei fast allen Herstellern.
Das PDF-Format findet heute breite Anwendung im Print-on-Demand-Bereich. Viele Softwarehersteller verzichten heute auf eine gedruckte Dokumentation und geben dem Kunden lediglich PDF-Dateien als Ersatz mit auf den Weg.
Es bedarf allerdings für die Portabilität (Übertragbarkeit) dieser Daten sehr komplexer Software-Anforderungen. Adobe ist mit dem Adobe Acrobat Reader das marktführende Produkt im Rennen. Trotzdem erklärte Adobe PDF zum offenen Format und hat die Format-Spezifikationen öffentlich bekanntgegeben. Erste Bestrebungen gehen in die Richtung, Anwendungen zu entwickeln, die XML-Dokumente automatisch in das PDF-Format überführen.
Das von Microsoft entwickelte Rich Text Format (RTF) ähnelt in seiner Struktur Adobes PDF-Format, bietet aber längst nicht so zahlreiche Ausdrucksmittel und ist nur begrenzt portabel.
Sowohl PostScript, PDF als auch RTF stellen rein physische Auszeichnungssysteme dar. PostScript und PDF haben darüber hinaus den Nachteil, daß Sie sich nur sehr schlecht oder gar nicht nachträglich editieren lassen.
Obwohl Adobe versucht, PDF als Format für das Web zu vermarkten, eignet sich natürlich eine rein physische Auszeichnung nur bedingt als Basisformat für die Informationsübermittlung. In Zukunft ist das XML-Format sicherlich auch in diesem Bereich eine gute Alternative. Denkbar wäre auch ein Programm, das aus dem XML-Format PDF-Dokumente konvertiert.
Einige Bedingungen, die aus dem Zusammenhang im vorausgegangenen Kapitel an eine neue Auszeichnungssprache gestellt werden müßten, möchten wir hier noch einmal auflisten. So viel schon im voraus: XML erfüllt diese Anforderungen und setzt sie in der Sprachdefinition um.
Das bedingt natürlich schon, daß es sich um einen offengelegten Standard handelt, der von jeder interessierten Person oder Institution möglichst ohne zusätzliche Lizenzkosten in eigene Programme aufgenommen werden kann. Denn erst durch große Verbreitung von Programmen, die das Format einheitlich unterstützen, ist auch die Möglichkeit gegeben, ein solches Format wirklich zum Standard werden zu lassen. Und nur ein solcher durch die Nutzer angenommener Standard verschafft dem Anwender wirkliche Vorteile bei seiner täglichen Arbeit.
Im Kapitel über die Bedeutung des W3-Konsortiums finden Sie die Forderungen, die sich das XML-Entwicklerteam als Maßgabe für seine Arbeit an der neuen Metasprache gesetzt hat.
Sie haben inzwischen einiges über Auszeichnungssprachen und deren Bedeutung erfahren. Wir möchten es dennoch nicht versäumen, Ihnen nun eine theoretische Definition dieses Begriffs zu geben, den wir bisher immer mit einiger Selbstverständlichkeit und sicherlich im Zusammenhang auch verständlich eingesetzt haben.
Anschließend wird Sie die kleine Reise durch die Geschichte der vorhandenen Auszeichnungssprachen führen, und wir werden das Kapitel mit einem genaueren Einstieg in die Sprachen SGML, HTML und XML beenden.
In der Auszeichnungssprache selbst sind verschiedene Befehle definiert, die der optischen und inhaltlichen Strukturierung von Informationen dienen. Auf Basis einer Auszeichnungssprache können dann Dokumente verfaßt und verarbeitet werden.
Die Datenart, die sich weltweit der weitesten Verbreitung und der leichtesten Portierbarkeit erfreut, ist die Textdatei. Doch auch auf dieser einfachen Basis und mit dem gänzlichen Verzicht auf binäre Daten bestehen zwei Hauptprobleme, die eine Auszeichnungssprache lösen muß.
Als erstes existieren weltweit Hunderte von verschiedenen länderspezifischen Zeichen. Und wenn man sich bei der Verwendung für die 128 Zeichen des weitverbreiteten US-Zeichensatzes entscheidet, müssen Möglichkeiten gefunden werden, diese Zeichen darzustellen. Aber selbst der erweiterte Zeichensatz mit 255 Zeichen reicht beispielsweise für die Hunderte von verschiedenen Schriftzeichen des japanischen oder chinesischen Alphabets nicht aus.
Das erste Problem, das eine Auszeichnungssprache zu lösen hat, haben wir auf den vorangegangenen Seiten schon angesprochen: Text allein reicht zur angemessenen Darstellung von Informationen kaum aus. In reinen Texten können keine Schriftarten, Überschriften, Fußnoten, Kursiv- oder Fettschrift verwendet werden. Es müssen Möglichkeiten gegeben werden, die Wirkung der online abgerufenen oder ausgedruckten Dokumente inhaltlich und visuell zu gestalten. Außerdem müssen sie helfen, Text, Grafik und andere Multimedia-Elemente zu verbinden.
In der Praxis wird dieses Problem durch den Einsatz von vorher festgelegten Auszeichnungen
gelöst. Beispielsweise wird mit der Auszeichnung <B> in HTML definiert, daß der Text
in Fettschrift darzustellen ist.
<B>Dieser Text wird in Fettschrift dargestellt</B>
<I>Dies ist Kursivschrift (Italic)</I>
Der englische Begriff für Auszeichnung ist »Markup«. Daher können wir den geläufigeren Begriff »Markup Language« für Auszeichnungssprache analog verwenden. In HTML hat sich für die Textauszeichnungen der Begriff »Tag« durchgesetzt. Der komplette Text, für den die Auszeichnung gelten soll, wird in Tags eingeschlossen. Ein »Start-Tag« definiert den Beginn und ein »Schluß-Tag« das Ende einer Auszeichnung.
Jeder Auszeichnungsbefehl muß durch spezielle vorher definierte Zeichen eingegrenzt werden. In den meisten bekannten Markup-Sprachen nutzt man hierzu die Größer- und Kleiner- Zeichen (»<«, »>«). Bei dieser Eingrenzung von Textstellen, die einer besonderen Verarbeitung bedürfen, spricht man auch von Delimitierung. Im günstigsten Fall setzt man hier zwei Zeichen ein, die sonst im übrigen Text nur eine geringe Bedeutung haben und selten genutzt werden, denn diese Zeichen kann man anschließend im normalen Text nur über Umwege darstellen.
Verschiedene Möglichkeiten der Delimitierung eines Befehls:
<BEFEHL>
<BEFEHL />
<!BEFEHL>
<?BEFEHL>
<!-- KOMMENTAR -->
Man unterscheidet grundsätzlich zwischen zwei verschiedenen Arten von Auszeichnungen, beide verfolgen eine andere Zielrichtung. Die erste Möglichkeit ist die logische oder semantische Auszeichnung; daneben können Informationen auch physisch, also nach visuellen Gesichtspunkten, ausgezeichnet werden. Beide Alternativen stellen wir im Detail in den nächsten Abschnitten vor. Die meisten Auszeichnungssprachen verwenden beide Arten. Die Dominanz einer Richtung ist allerdings je nach verwendeter Sprache stärker oder schwächer ausgeprägt.
XML ist in bezug auf die Syntax der Markups strenger als beispielsweise HTML. Hier konnte der Autor die schließenden Tags auch schon einmal vernachlässigen, ohne irgendwelche Probleme befürchten zu müssen.
<BEFEHL>Hier steht der Text</BEFEHL>
Jedes geöffnete XML-Tag muß auch wieder ordnungsgemäß geschlossen werden. Die höhere Flexibilität von XML erfordert gleichzeitig ein höheres Maß an syntaktischer Genauigkeit.
Bei den logischen Auszeichnungen handelt es sich, wie der Begriff schon signalisiert, um eine inhaltliche Definition des Textes. Beispielsweise kann festgelegt werden, ob es sich bei dem gekennzeichnet Begriff um einen Namen, ein Zitat oder eine wichtige Überschrift handelt.
HTML kennt einige logische Auszeichnungen, die eine spätere Auswertung des Textes z.B. durch Suchmaschinen erleichtern. Die folgende Anweisung gibt den Autoren des Dokuments an:
<AUTHOR>Gunter Wielage</AUTHOR>
Ein logisch ausgezeichneter Text bedingt nicht unbedingt eine andere visuelle Darstellung. So kann beispielsweise ein Name in gleicher Textart und Stärke dargestellt werden, wie ein Zitat.
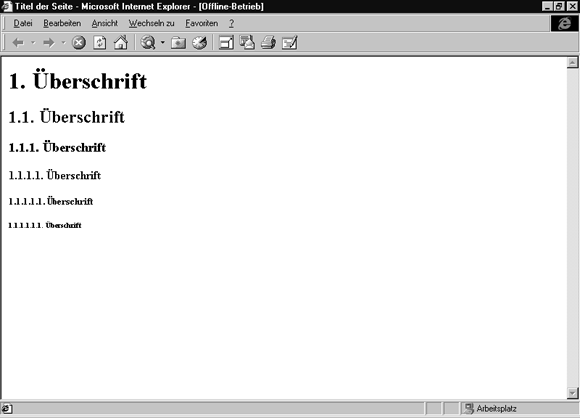
Abb. 2.7: Verschiedene Überschriftenebenen - als logische Auszeichnungen - im Microsoft Internet Explorer dargestellt.
Ziel des Programms zur Darstellung solcher Dokumente wird es natürlich trotzdem sein, einzelne Auszeichnungen auch visuell unterscheidbar zu machen. Aber in erster Linie wird die logische Auszeichnung dazu verwandt, Informationen und deren Strukturen durch EDV- Programme auswertbar zu machen. So könnte beispielsweise eine Suchmaschine im Internet gezielt nach dem Namen des Autors oder dem Titel der Seite suchen und so ein wesentlich genaueres Ergebnis bieten als eine reine Stichwortsuche über den gesamten Textinhalt.
Physische Auszeichnungen verfolgen das alleinige Ziel, Möglichkeiten zur visuellen Textdarstellung zu geben. Ein als Fettschrift definierter Text wird auch in dieser Schrift angezeigt. Es werden allerdings keine Aussagen darüber gemacht, wie wichtig dieser so ausgezeichnete Text für das ganze Dokument ist.
Eine Textverarbeitung wie Microsoft Word tendiert im Format eher in Richtung physischer Formatierungsbefehle. Hier spielt es keine Rolle, ob Word weiß, daß Sie gerade ein Zitat eingebracht haben. Das Programm kann mit dieser Information sowieso nicht viel anfangen und diese vielleicht auswerten. In dieser Situation ist diese Auszeichnungsform also absolut angemessen. Denn hier zählt, wie das Dokument anschließend aus dem Drucker kommt.
Gerade bei Datenaustausch können sich solche physischen Auszeichnungen allerdings leicht als störend erweisen. Denn was tut der Apple-Macintosh-Anwender, wenn er beispielsweise von Ihnen ein Dokument in der ihm unbekannten Schriftart »Arial« erhält oder wenn ein Amerikaner ein sauber auf das europäische Papierformat DIN A4 ausgerichtetes Dokument auf seinem etwas kürzerem US-Letter-Format ausdrucken möchte.
Unabhängig vom Druckbereich und zurück zum Online-Dokument besteht auch hier das Problem der Hardware-Unterschiede. Unterstütze Farbanzahl, Bildschirmgrößen und -auflösungen variieren einfach zu stark.
Aus diesen Gründen tendiert man gerade im Internet zunehmend in Richtung logischer Auszeichnungen. Alle bekannten Auszeichnungssprachen halten aber neben den logischen auch physische Befehle zur Textauszeichung bereit.
Eine typische physische Anweisung in HTML definiert beispielsweise die Benutzung eines speziellen Fonts zur Zeichendarstellung (hier die Schriftart »Arial«):
<FONT FACE="ARIAL">Dies ist die Schriftart Arial</FONT>
Es existieren inzwischen auch einige Formate, die nahezu systemübergreifend zumindest PC- und Macintosh-Welt problemlos miteinander verbinden und ein an physischen Auszeichnungen orientiertes Format anbieten. Beispielsweise das Postscript-Format oder das PDF-Format (Adobe Acrobat). Mit diesen ist es möglich, Dokumente optisch nahezu identisch auf den verschiedenen Plattformen anzuzeigen oder auszudrucken. Die elektronische Weiterverarbeitung oder Auswertung der Informationen ist allerdings nicht so problemlos möglich. Teilweise ist es sogar recht mühsam, aus diesen Formate wieder den reinen Textgehalt zu filtrieren.
Der Trend gerade bei der Entwicklung der Sprache HTML ging in letzter Zeit immer stärker in Richtung visueller Auszeichnung des Textes. Viele neue Befehle zielen nur noch darauf ab, dem Autor Möglichkeiten zu geben, eine Webseite möglichst optisch genau zu gestalten. Mit der Entwicklung von XML strebt das W3C wieder zur ursprünglich strukturorientierten Sprache, die auch HTML anfangs einmal war.
In der Internet-Entwicklergemeinde hat sich zusätzlich zum Ausdruck »physische Tags« und »logische Tags« noch ein dritter Begriff durchgesetzt, der vor allem für XML an Bedeutung gewinnt. Die sogenannten »semantischen Tags« beschreiben weder Formatanweisungen noch die logische Struktur, sondern geben Rückschlüsse über den Inhalt des zwischen den Tags stehenden Textes.
<GEBURTSDATUM>10.05.1970</GEBURTSDATUM>
Diese semantischen Tags (oder engl. »semantics«) geben der späteren Anwendung die Möglichkeit, die entsprechenden Felder auszuwerten oder beispielsweise genau nach einem Geburtsdatum zu suchen. Insbesondere für die Verknüpfung von XML-Dokumenten mit Datenbankanwendungen oder bei der Suche von bestimmten Informationen spielen die semantischen Tags eine wichtige Rolle. In XML werden fast ausschließlich Markups dieses Typs definiert.
In einem Netz wie dem Internet, an dem inzwischen weltweit Millionen von Teilnehmern mit unterschiedlichster Rechnerausstattung angeschlossen sind, sind offene Standards für die Datenübermittlung Voraussetzung. Ein offener Standard, der der ständigen Weiterentwicklung unterliegt, könnte nicht funktionieren, wenn niemand über diese Standards wachen oder zumindest Entwicklungen verfolgen würde.

Diese Aufgabe hat seit Jahren das W3-Konsortium (W3C = World Wide Web Consortium) übernommen. Es handelt sich dabei um einen freiwilligen Zusammenschluß von Firmen und Institutionen, der die Entwicklung des Internets vorantreibt.
Im Mai 1994 fand in Genf die erste internationale WWW-Konferenz statt. Tim Berners-Lee gründete dann mit dem W3C im Oktober 1994 am Massachusetts Institute of Technology ein neutrales und offenes Forum für die Weiterentwicklung des weltweiten Netzes. Im April 1995 schloß sich auch das französische nationale Forschungsinstitut für Computertechnologie als europäische Sektion dem Konsortium an.
Weltweit sind über 255 Mitglieder aus Industrie und Forschung, wie Software-Hersteller, Telekommunikations-Gesellschaften, Internet-Provider, Regierungsstellen und akademische Einrichtungen, dem Gremium angeschlossen. Prominenteste deutsche Mitglieder dieses Gremiums sind beispielsweise SAP AG, Deutsche Telekom AG, Deutsches Forschungsnetz e.V. (DFN) oder die Universität Karlsruhe.
Obwohl theoretisch jeder dem W3-Konsortium beitreten kann, besteht für wirtschaftlich orientierte Unternehmen eine finanzielle Hürde in einem gewissen Mindestumsatz. So werden nur Unternehmen mit großer Marktpräsenz und damit Marktbedeutung als Mitglieder zugelassen, um eine gewisse Beschränkung einzuführen. Für öffentliche Organisationen und Forschungsinstitute besteht diese Zugangsvoraussetzung nicht.




Abb. 2.9: Prominente deutsche Mitglieder des W3C.
Das W3C möchte nach eigenen Aussagen das volle Potential des Webs durch die Entwicklung von einheitlichen Protokollen ausschöpfen. Gleichzeitig steht die Weiterentwicklung bestehender Standards und eine Sicherstellung der Interoperabilität (Austauschbarkeit von Daten) im Mittelpunkt der Aktionen.
Gerade der letzte Themenkreis macht deutlich, daß sich das W3C nicht nur der Technologie, sondern auch der sozialen und gesellschaftlichen Verantwortung bewußt ist, denn das Internet betrifft heute alle Bereiche unseres Lebens. Dazu gehört auch ein Schutz von Kindern vor jugendgefährdenden Inhalten und die Sicherheit der Privatsphäre durch Verschlüsselung und die digitale Unterschrift.
Für den Ablauf zur Verabschiedung eines neuen Standards durch das W3C existieren feste formale Regeln. Zunächst bildet das W3C eine Arbeitsgruppe, die sich mit diesem neuen Thema beschäftigt. Diese Gruppe erarbeitet dann zunächst einen ersten Vorschlag. Dieser Vorschlag wird als sogenannter »Working Draft« im Internet öffentlich zur Diskussion gestellt, denn jeder interessierte Teilnehmer des Internets soll sich theoretisch an der Weiterentwicklung beteiligen können. Nach zwei weiteren öffentlich diskutierten Entwürfen, folgt dann in den meisten Fällen die öffentliche Empfehlung des Vorschlags zum Standard.
Für die Formaterweiterung Extensible Style Language (XSL), die noch in der Entwicklung ist, sieht der geplante Zeitablauf wie folgt aus:
Zeitablauf Extensible Style Language (XSL 1.0)
Jahrelang schien es fast so zu sein, als ob die Aufgabe des W3C nur noch darin bestand, neue Funktionen, die von Netscape und Microsoft in rasanter Folge in die eigenen Browser implementiert wurden, abzusegnen.
Jeder dieser Hersteller versuchte, durch eigene Erweiterung des HTML-Standards neue De- facto-Standards hervorzubringen und damit der eigenen Browsersoftware einen Marktvorteil zu verschaffen. Teilweise war es so, daß noch nicht offiziell bestätigte Befehle längst im Netscape Navigator und Microsoft Explorer zu finden und mit 90 Prozent Marktabdeckung auch weltweit anerkannt waren, man sie aber in den W3C-Empfehlungen immer noch vergeblich suchte.
Doch mit XML geht das W3C auch in dieser Hinsicht neue Wege und bringt eine echte Innovation und Weiterentwicklung hervor, die nicht aus dem Konkurrenzdruck zweier Firmen entstanden ist.
Das Internet und HTML haben auf die Entstehung von XML einen sehr großen Einfluß gehabt. Es ist möglich, HTML-Dokumente in XML-Dokumente zu konvertieren oder auf der Basis von XML die Sprache HTML zu definieren.
Der folgende Abschnitt gibt einen kurzen Überblick über die wichtigsten bisher bestehenden Auszeichnungssprachen und deren Bedeutung. Es wird die Frage geklärt, warum wir überhaupt eine neue Sprache wie XML benötigen. Außerdem erhalten Sie im Anschluß daran bereits einen ersten Eindruck der neuen Extensible Markup Language.
Die chronologische Entwicklung der heute eingesetzten Auszeichnungssprachen:
In den letzten turbulenten Jahren der Entwicklung des Internets konnte sich HTML als Industrie-Standard für die Erstellung von Websites durchsetzen. Heute ist es fast jedem möglich, einen leichten Einstieg in die Programmiersprache zu erlangen. Selbst ohne großes Fachwissen sind mit HTML schnelle Anfangserfolge sicher. Nachdem sich die sprunghafte Entwicklung von HTML in der letzten Phase etwas beruhigt hat, stehen wir jetzt mit XML vor einem großen Neuanfang.
Insbesondere die fehlende Datenbankverbindung von HTML macht neue Standards nötig. Außerdem wird die weitere Verbreitung von HTML durch eine umständliche Übertragbarkeit auf andere Medien wie Papier oder CD-ROMs gehemmt.
Die zunehmende Überschneidung von Medien zwingt uns momentan zu einer Mehrarbeit durch die Übersetzung in die verschiedenen Datenformate. Gerade größere Unternehmen sehen hier ein ungenutztes Potential für Einsparungen. Die Forderungen nach einer neuen Sprache, die diese Faktoren berücksichtigt, werden immer lauter. Es geht bei XML nicht mehr um eine Sprache fürs Web, sondern um eine einheitliche Basis für die gesamte Daten- und Informationsverarbeitung eines Unternehmens.
Insgesamt kann man die hier behandelten Sprachen in drei Gruppen aufteilen: Metasprachen, Beschreibungssprachen und Formatvorgaben. HTML ist eine klassische Sprache zur Beschreibung von Dokumenten. Sie umfaßt einen festen Stamm von definierten Befehlen und ist nicht erweiterbar.
Dagegen sind SGML und XML Metasprachen. Mit ihrer Hilfe lassen sich eigene neue Sprachen zur Dokumentenbeschreibung erstellen. Beispielsweise läßt sich mit Hilfe von XML die Sprache HTML definieren. Eine Metasprache bietet Werkzeuge und eine normierte Syntax zur Beschreibung von »Grammatiken«.
Im Gegensatz zur sehr schwerfälligen und umfangreichen SGML-Sprache kommt XML klein und schlank daher und ist so konstruiert, daß jedem Autoren ermöglicht wird, eine auf die persönlichen Belange zugeschnittene Grammatik zu erstellen. Die SGML-Definition des W3C umfaßte 1986 über fünfhundert Seiten. Die aktuelle XML-Definition kommt »light« auf knapp 33 Seiten daher. Man hat also hier auch aus der Vergangenheit gelernt und an die Weiterentwicklung nicht nur von HTML, sondern insbesondere auch von SGML gedacht.
Die Zusammenhänge der drei wichtigen Sprachen stellen sich folgendermaßen dar: XML ist eine Teilmenge von SGML, also keine völlige Neuentwicklung oder gar Ablösung. HTML war bisher auf der Basis von SGML definiert, inzwischen ist aber auch eine Definition auf der Basis von XML möglich.

Abb. 2.10: Die Beziehungen zwischen von SGML, HTML und XML grafisch dargestellt.
CSS stellt eine Erweiterung von HTML dar, die die Sprache um Formatvorgaben ergänzt. Diese Formatvorgaben sind aber auch unter XML einsetzbar. Dagegen ist die neuste Entwicklung XSL eine reine Ergänzung, die für den Einsatz ausschließlich unter XML gedacht ist.
Das Prinzip des Hypertextes ist recht einfach. Sie können innerhalb des Textes Verweise auf andere Textstellen legen. So könnte zum Beispiel der Mausklick auf ein wissenschaftliches Fremdwort direkt zum Glossar und zur entsprechenden Erklärung des Wortes führen. Mitte der 60er Jahre zur Zeit der ersten Großrechneranlagen an den Universitäten wurde dieses Prinzip entwickelt.
Der Begriff »Hypertext« wurde bereits 1950 von Ted Nelson veröffentlicht: Die Idee war schon damals geboren:

Abb. 2.11: Menschen-lesbare Informationen miteinander in zwangloser Reihenfolge verknüpft.
Es hat lange gedauert, bis man auf die Idee kam, diese Hypertexte weltweit auf Rechnern abzulegen und zu verknüpfen. Denn mit HTML können Sie nicht nur Verknüpfungen auf Text in einem Dokument legen, sondern weltweit auf jeden angeschlossenen Rechner.
Das heißt im Beispiel: Sie lesen gerade einen Firmennamen in Ihrem Text und können mit einem Klick auf der Firmengeschichte landen, die sich auf einem tausend Kilometer entfernten Rechner befindet.
Gerade bei wissenschaftlichen Arbeiten gibt es keinen festen Wissensstand; die Entwicklung geht immer weiter, und die Erkenntnisse wachsen. Genauso dürfte es auch keinen statischen Text geben; man müßte immer wieder Querverweise auf weiterführende Literatur geben. Durch Hypertext wird diese Möglichkeit eröffnet, und er lädt jeden ein, sich selbst mit weiterführenden Quellen zu beschäftigen und die individuellen Interessen zu vertiefen.
Die Geschichte der Sprache HTML ist untrennbar mit dem Namen Tim Berners-Lee verbunden. Ende 1989 startete der junge britische Informatiker im Kernforschungszentrum CERN in Genf seine ersten Versuche, das Internet für sich zu nutzen. Er entdeckte das System Hypertext und setze es für das Internet um. Ziel von HTML war es auch, eine einheitliche Definition zu schaffen, die der Endanwender mit einem speziellen Programm online anzeigen konnte. Damals entstand aufgrund der weltweiten Verweise, die ein Dokument beinhalten konnte, der Begriff »World Wide Web«.

Abb. 2.12: Der Ausgangspunkt des WWW: das Kernforschungszentrum CERN in Genf.
Was als textorientierte Idee begann, wurde 1993 von Marc Andreessen beim NSCA (National Center for Supercomputing Applications) in Illinois weiterentwickelt. Damals entstand im März 1993 der erste WWW-Browser mit grafischer Benutzeroberfläche. Er vereinfachte die Internet-Navigation erheblich. Der kostenlos verfügbare Browser »Mosaic« brachte die Lawine ins Rollen.

Abb. 2.13: Marc Andreessen entwickelte den ersten HTML-Browser »Mosaic«.
Schnell erkannte Marc Andreessen den kommerziellen Nutzwert des Internets und stieg aus dem Projekt »Mosaik« aus, um seine eigenen Entwicklungen fortsetzen zu können. Im April 1994 wurde die Firma Netscape von Marc Andreessen und Dr. James H. Clark in den USA gegründet. Dr. James H. Clark hatte vorher das Unternehmen Silicon Graphics gegründet. Schon ein halbes Jahr später wurde der Netscape Navigator veröffentlicht.
Heute beschäftigt Netscape über 2.000 Menschen in 17 Ländern, und der Netscape-Browser gehört immer noch zu der weltweit beliebtesten Zugangssoftware zum Internet, wenn auch Microsoft inzwischen große Marktanteile übernehmen konnte und in Zukunft den weitverbreitesten Browser stellen kann.
HTML ist eine SGML-Anwendung. In HTML ist eine ganze Reihe von festen Befehlen und deren Syntax vereinbart, derer sich der Webdesigner bedienen kann. Es ist allerdings nicht möglich, selbst Auszeichnungsbefehle zu erfinden und zu definieren.
Obwohl HTML in den vergangenen Jahren stetig ausgebaut wurde, hat HTML auch in der aktuellen Version 4.0 mit rund sechzig Befehlen noch gewisse Grenzen. Die begrenzte Auswahl an Elementtypen erleichtert natürlich einerseits den Einstieg in diese Sprache und ermöglicht es jedem, ohne ausführliches Informatik-Studium innerhalb von Tagen eigene Internet-Dokumente zu erstellen, andererseits schränkt sie aber auch ein.
Außerdem ist in der Entwicklung von HTML ein stetiges Auseinanderdriften des Standards zu beobachten. Schon auf Version 3.0 konnte man sich nicht gemeinschaftlich einigen, und so wurde diese Version nie verabschiedet. Inzwischen sind die Wogen mit Version 3.2 und Version 4.0 zwar wieder geglättet, aber die ständige Weiterentwicklung gerade im multimedialen Sektor erfordert eine neue Möglichkeit.
Erst 1989 begann mit dem von Tim Berners-Lee vorgelegten Entwurf einer Auszeichnungssprache für Hypertexte die Entwicklung von HTML. Sie erfuhr ständige Weiterentwicklung z.B. 1993 mit dem grafischen Browser Mosaic.
Schon damals begannen die Hersteller der Browserprogramme, mit eigenen nicht offiziell definierten sogenannten proprietären Befehlen die Entwicklung voranzutreiben. Ein wahrer Krieg entbrannte in den folgenden Jahren, nachdem neben der Firma Netscape auch Microsoft groß ins Geschäft mit dem Internet einstieg. Jeder versuchte und versucht noch heute, durch eigene Entwicklungen dem Konkurrenten Marktanteile zu entziehen.
Die HTML-2.0-Spezifikation war die erste Version von HTML, die konsequent nach dem SGML-Standard entwickelt wurde. Aus diesem Grunde hören wir heute auch nichts mehr von einer HTML-1.0-Spezifikation. HTML 2.0 bildet heute die Basis aller Dokumente im World Wide Web. Sie ist als Standard weltweit verbreitet, und jedes Browserprogramm beherrscht heute zumindest die Syntax dieser Version.
Jedes Dokument nach dem SGML-Standard sollte in der ersten Zeile Auskunft darüber geben, welche Sprache Verwendung findet. Dieser sogenannte »Public Identifier« (öffentliche Identifizierung) lautet für HTML 2.0:
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
Die dann folgende Grundstruktur eines HTML-Elements besteht aus einer Reihe von elementaren Befehlen (»Tags« oder »Markups«):
<HTML>
<HEAD>
<TITLE>Hier steht der Titel des Dokuments</TITLE>
</HEAD>
<BODY>
Hier folgt der eigentliche Text-"Körper"
<H1>Eine wichtige Überschrift erster Ordnung</H1>
<H2>Eine Überschrift zweiter Ordnung</H2>
</BODY>
</HTML>
Bei HTML-Befehlen und -Attributen wird im Gegensatz zu XML nicht zwischen
Groß- und Kleinschreibung unterschieden.
Zu vielen Befehlen können zusätzliche Optionen, sogenannte Attribute, eingesetzt werden.
Beispielsweise läßt sich mit ALIGN die Ausrichtung eines Elements beeinflussen. Die Voreinstellung
(Linksbündig) wurde im folgenden Beispiel auf Zentriert umgestellt:
<TABLE ALIGN="middle"></TABLE>
Zu Recht können Sie in diesem Buch keine vollständige Spezifikation des HTML-Standards erwarten. Wir werden zwar immer wieder vergleichend auf Analogien hinweisen, aber Sie werden auch ohne HTML-Kenntnisse problemlos die Metasprache XML verstehen.
Nachdem es mangels Einigung 1995 nicht zu einer offiziell normierten HTML- Version 3.0 kam und Netscape mit eigenen Entwicklungen vorpreschte, einigte sich das W3-Konsortium schließlich gemeinsam mit einigen großen Entwicklungsfirmen auf den Sprachstandard 3.2. Aus diesem Grund taucht in der Abfolge der offiziellen HTML-Normen nie eine Version 3.0 auf. HTML 3.2 wurde im Mai 1996 als Internet-Draft vorgelegt und schließlich als Referenz-Spezifikation im November 1996 verabschiedet.
Die Zeile zur Identifizierung eines Dokuments als HTML 3.2 Standard lautet nach den SGML-Regeln:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 3.2 Final//EN">
In Doctype wird ein Verweis zur sogenannten Document-Type-Definition (DTD) integriert. Die oben genannten Beispiele greifen auf die offiziellen Dokumenten-Definitionen des W3- Consortiums zurück. Durch den Zusatz PUBLIC wird kenntlich gemacht, daß es sich um eine vom W3C öffentlich zugänglich gemachte Version handelt. Die DTDs haben bei der Verwendung von XML wesentlich an Bedeutung gewonnen. Wir werden in diesem Buch noch einmal ausführlich auf deren Einsatz und Struktur eingehen.
Der Zusatz EN bedeutet, daß die Sprache der Definition (und nicht die Sprache des Dokuments) Englisch ist. Andere Sprachen sind hier für HTML nicht vorgesehen. Neben den oben genannten Versionen sollten Sie für HTML keine anderen Definitionen verwenden. Im Anhang finden Sie eine Liste aller sonst noch möglichen Sprachcodes nach ISO 639.
Mit der aktuellen Version von HTML unterstützt die Sprache verstärkt die Einbindung von multimedialen Elementen, Skriptsprachen und Stilvorlagen (Stylesheets). Gegen die Bestrebungen, HTML zu einer Art Desktop-Publishing-Sprache verkommen zu lassen, wurden allerdings klare Akzente gesetzt. Auch die Internationalisierung und Unterstützung beliebiger Sprachen wurde weiter vorangetrieben. Insbesondere für körperlich benachteiligte Menschen wurden weitere Erleichterungen zum Beispiel zur Ausgabe von Braille-Schrift integriert.
In HTML 4.0 wurden vorwiegend kleine Veränderungen und Anpassungen der vorhergehenden Version vorgenommen. Tim Berners-Lee sagte dazu: »Die Entwicklung von HTML nähert sich ihrem Ende. Jetzt ist es eher notwendig, einige lose Enden zusammenzufügen.«
Für die Identifizierung eines Dokuments, als HTML 4.0 codiert, ist nach SGML-Standard in der ersten Zeile folgender Code einzufügen:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0//EN">
Zusätzlich sind in der Version 4.0 einige weitere Dokumentendefinitionen veröffentlicht worden, die die eingesetzte Sprache näher spezifizieren. Insbesondere wurden in der aktuellen Version einige Markups entfernt, deren Nutzung sich als nicht sinnvoll durchgesetzt hat. Mit dem Attribut »Transitional« (übersetzt: übergangsweise) kennzeichnet man beispielsweise ein Dokument, daß zwar HTML 4.0 verwendet, aber noch nicht auf die nicht mehr empfohlenen Befehle aus älteren Versionen verzichtet.
<!DOCTYPE HTML PUBLIC
"-//W3C//DTD HTML 4.0 Transitional//EN">
Das Gegenteil des Attributs »Transitional« ist »Strict«. Ein so ausgezeichnetes Dokument muß sich streng an die Empfehlungen zur Version HTML 4.0 halten und darf ausschließlich HTML-4.0-Befehle verwenden.
<!DOCTYPE HTML PUBLIC "-//W3C/DTD HTML 4.0 Strict//EN">
Setzen Sie auf Ihrer Seite die sogenannten Frames ein und enthält die Seite lediglich die Framedefinition, so kennzeichnen Sie diese mit »Frameset«. Der Frameset enthält keinen eigenen Informationsinhalt, sondern lediglich die Bezüge auf die in den Rahmen anzuzeigenden Dokumente und deren Abmessungen.
<!DOCTYPE HTML PUBLIC "-//W3C/DTD HTML 4.0 Frameset//EN">
Im Anhang haben wir Ihnen eine Übersicht aller HTML-Befehle und der zugehörigen Versionsnummer zusammengestellt. Zusätzlich sind dort auch proprietäre Kommandos, die von Netscape oder Microsoft integriert wurden, gelistet.
Die zur Zeit aktuelle Version von HTML, Version 4.0, wurde vom W3C im Dezember 1997 verabschiedet. Einige der dort eingebrachten Änderungen fanden in den meisten Browsern schon vorher Unterstützung. Erst jetzt wurden z.B. die weitverbreiteten Frames (Rahmen) offiziell als Standard dokumentiert. Einige Befehle, die sich in der Vergangenheit als nicht sinnvoll oder wenig einsetzbar erwiesen haben, wurden in der aktuellen Version entweder durch neue ersetzt oder ganz entfernt. Der HTML-3.2-Standard enthält bereits über 70 Befehle und 50 weitere mögliche Attribute, und diese Flut von Befehlen wollte man etwas einschränken. Um also ganz korrektes HTML 4.0 zu programmieren, muß man auf einige ältere Befehle verzichten. Allerdings unterstützt bis heute noch immer kein Programm alle in Version 4.0 vorgelegten Veränderungen.
Den Begriff »Stylesheet« kann man im Deutschen mit Formatvorlage oder Layoutvorlage übersetzen. Dabei handelt es sich eigentlich um eine Vorlage zur Umwandlung der logischen Auszeichnungen in die physischen Auszeichnungen. Die Cascading Style Sheets, die für die Verwendung unter HTML vorgesehen sind, sind inzwischen in der Version 2.0 erschienen.
In der CSS-Definition wird beispielsweise angegeben, daß eine Überschrift erster Ordnung in der Schrift »Arial« Punktgröße 28 in Fettschrift ausgegeben wird. Sofern der Browser also Stylesheets unterstützt, wird statt der voreingestellten Formatierung die von Ihnen gewünschte Formatierung gewählt.
In HTML sieht eine Style-Sheet-Definition wie folgt aus:
<STYLE TYPE="text/css">
H1 { background-color : black; color : white }
H2 { background-color : blue; color : red }
H3 { background-color : blue; color : black }
H4 { background-color : blue; color : red }
H5 { background-color : blue; color : black }
</STYLE>
Sie kann direkt in den HTML-Source-Code integriert oder auch als externe Datei einem Dokument zugeordnet werden.
Neben der Definition von neuen Formaten für bereits bestehende Befehle können mit Hilfe der Stylesheets auch sogenannte Unterklassen von Befehlen gebildet werden.
<STYLE TYPE="text/css">
H1.wichtig
{ background-color : yellow; color : black }
H1.unwichtig
{ background-color : white; color : grey }
</STYLE>
Im Beispiel wurden für eine Überschrift <H1> die zwei Klassen wichtig" und unwichtig"
gebildet. Die erste Klasse wird mit schwarzer Textfarbe und gelbem Hintergrund angezeigt.
Die zweite definierte Klasse des Tags wird mit grauer Textfarbe und weißem Hintergrund
dargestellt.
Um im HTML-Quellcode diese Formatvorlagen anwenden zu können, rufen Sie das Tag wie
gewöhnlich auf und übergeben ihm zusätzlich als Attribut CLASS, damit klar ist, welche definierte
Klasse verwendet werden soll:
<BODY>
<H1>Normale Überschrift 1. Ordnung</H1>
<H1 CLASS="wichtig">Wichtige Überschrift</H1>
<H1 CLASS="unwichtig">Nicht so wichtige Überschrift</H1>
</BODY>
Mit Hilfe dieser Klassendefinitionen wurde die Funktionalität von HTML stark erweitert. Formatvorlagen, wie sie sonst aus jeder Textverarbeitung bekannt sind, werden so auch für Webdokumente möglich. Die Arbeit des Webdesigners und Autors wird durch deren Einsatz wesentlich erleichtert.
Mußten früher alle Änderungen im ganzen Quellcode durchgeführt werden, genügt jetzt eine einzige Änderung im Stylesheet. Beim Einsatz von CSS ist darauf zu achten, daß längst noch nicht alle Browser diese Erweiterung unterstützen.
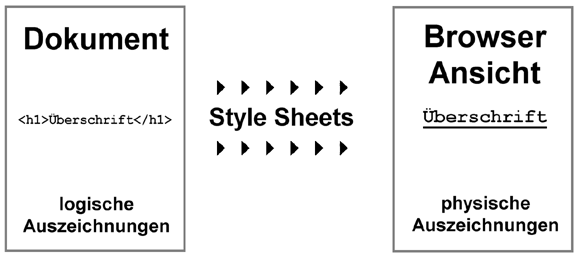
Abb. 2.14: Umwandlung der logischen Auszeichnungen in visuelle Informationen.
Mit Hilfe der CSS werden die logischen Auszeichnungen, in unserem Beispiel die verschiedenen Überschriftenebenen, in physische Informationen umgesetzt. Ohne CSS waren diese Umsetzungen ausschließlich durch den Browser vordefiniert. Das bedingte, daß jeder Browser hier Unterschiede machte.
Durch Style Sheets ist der Webdesigner nicht mehr darauf angewiesen, auf logische Auszeichnungen
weitgehend zu verzichten und ausschließlich physische Markups einzusetzen,
um eine genau definierte optischen Darstellung zu erzielen. Wenn beispielsweise eine wichtige
Überschrift in Arial, Fettschrift, Größe Punkt 26 dargestellt werden sollte, blieb dem
Autoren nichts anderes übrig, als auf die logische Auszeichnung <H1> zu verzichten und statt
dessen mit Hilfe der physischen Tags das entsprechende Layout einzustellen. Jetzt kann die
logische Auszeichnung beibehalten und statt dessen deren Aussehen direkt verändert werden.
Mit Dynamic HTML bezeichnet man im allgemeinen alle Bemühungen, InternetSeiten noch interaktiver zu gestalten. Das heißt, Inhalte sollen sich flexibel an die Belange des Nutzers anpassen und auf dessen Eingaben reagieren. Der große Durchbruch gelang DHTML mit dem Erscheinen der vierten Browsergeneration. Bis dahin waren Text und ein wenig Animation mit Hilfe des CompuServe-GIF-Formats schon der Höhepunkt der Interaktivität.
DHTML ist der Oberbegriff für verschiedenen alternativ einsetzbare Techniken. In den meisten Fällen handelt es sich um kleine Mini-Applikationen, die innerhalb des Browsers ablaufen. In erster Linie werden heute JavaScript, Visual Basic Script (kurz VBScript) oder ActiveX eingesetzt.
Obwohl auch HTML schon eine hohe Interaktivität bietet, liegt der Unterschied beim Einsatz von DHTML darin, daß nicht für jede Veränderung des Inhalts eine neue Seite vom Server angefordert und übertragen werden muß, sondern die vorhandene Seite kann durch den Browser selbst verändert werden.
Bei allen Lösungen, die um dynamische Websites bemüht sind, handelt es sich in erster Linie um proprietäre Lösungen, die keinem übergreifenden Standard zugeordnet werden können.
Mit Blick auf XML hat das W3C das sogenannte Document Object Model (DOM) verabschiedet. Es schafft eine einheitliche Schnittstelle (API) für den Zugriff auf die Elemente einer Website. Damit wird die Veränderung und Verarbeitung beispielsweise von eingebundenen Grafiken, Text oder Überschriften möglich. Um diese Schnittstelle nutzen zu können, wird eine objektorientierte Programmier- oder Skriptsprache, wie beispielsweise C++, Java, VBScript oder JavaScript, benötigt. Das Document Object Modul wird nicht nur unter XML, sondern auch unter HTML einsetzbar sein.

Abb. 2.15: Ein einfaches interaktives Spiel als DHTML-Demo
(Quelle: Mark Kaufmann).
Für das bisherige Chaos unter HTML, wie verschiedene Browser auf die einzelnen Elemente der Seite zugreifen konnten, wurde also jetzt eine einheitliche Lösung gefunden. Damit wird es hoffentlich bald der Vergangenheit angehören, für anspruchsvolle Interaktivität für jeden Browser eine spezifische Lösung programmieren zu müssen. Heute muß man vielfach schon beispielsweise für das vergleichbar einfache programmgesteuerte Öffnen einer neuen Instanz des Browsers (neues Browserfenster) zwischen drei oder vier Lösungen unterscheiden, die jeweils nur mit einer Browserversion funktionieren.
Nach Expertenmeinung gehört DHTML zu einer der Schlüsseltechnologien des Internets. Bisher konnte sie sich aber aufgrund der hohen Fehleranfälligkeit, die zahlreiche Browserabstürze nach sich zieht, noch nicht richtig etablieren. Beispielsweise wird DHTML noch von keinem Macintosh-Browser fehlerfrei unterstützt.
Schon auf der ersten WWW-Konferenz 1994 in Genf hatte man die Vision, das Internet in Richtung 3-Dimensionalität weiterzuentwickeln. Damals erlangte auch das Wort Cyberspace seine heutige Bedeutung. Erstmals wurde der Begriff »Cyberspace« übrigens von dem Science-Fiction-Autoren William Gibson in seinem bekanntesten Roman »Neuromancer« genannt.
VRML bringt uns dem Web der Räumlichkeit und virtuellen Realität ein Stück näher. Mit der Sprache VRML können virtuelle Einkaufsstraßen oder Städte erschaffen werden, in denen der Besucher sich frei bewegen kann. VRML ist stark an HTML angelehnt, und diese beiden Dokumenttypen lassen sich auch problemlos miteinander verbinden. Beispielsweise läßt sich beim Klick auf einen virtuellen Gegenstand ein HTML-Dokument aufrufen.
Ursprünglich hatte man dieser neuen Entwicklung sehr große Chancen eingeräumt, und alle aktuellen Browser unterstützen den VRML-Standard heute. Aber sowohl die Anforderungen an Hardware als auch an die Bandbreite sind doch enorm hoch, so daß sich das Internet noch nicht von der zweidimensionalen Darstellung lösen konnte. Bis heute existieren eher experimentelle Lösungen, die breite Masse an Anwendungen fehlt.
Doch die Entwicklung geht weiter, und wir kommen der Vision des Cyberspace täglich ein Stück näher. Vielleicht wird diese Vision nicht mit VRML umgesetzt, aber die Faszination des virtuellen Raums geschaffen im Internet ist aktueller denn je.
SGML ist die Mutter aller Auszeichnungssprachen im Web. Sie wurde bereits 1986 als ISO 8879 verabschiedet und bildet heute die Basis aller Auszeichnungssprachen. Charles Goldfarb entwickelte die Sprache, um die logische Struktur von wissenschaftlichen Texten beschreiben zu können.
Als Metasprache können mit SGML Auszeichnungssprachen wie HTML definiert werden. SGML ist wesentlich komplizierter und unhandlicher als XML. Viele Erfahrungen, die mit der Benutzung von SGML in den letzten 12 Jahren gemacht wurden, finden wir heute in verbesserter Form in XML wieder. XML versteht sich als Teilmenge von SGML.
Mit SGML wurde die Idee, Texte nicht nur visuell (oder physisch) zu strukturieren, sondern logisch und inhaltlich zu codieren, fortgeführt. Ursprünglich geht diese Entwicklung auf die allgemeine Codierung (Generic Coding), die von IBM 1960 entwickelt wurde, zurück. Es wurde zwischen Inhalt (engl. »content«) und Darstellung (engl. »presentation«) differenziert. SGML stellt Fähigkeiten zur Verfügung, mit denen Sie explizit festlegen können, welche Auszeichnungen in Ihren Dokumenten verwendet werden. Mit Hilfe dieser Definition können dann darauf basierende Dokumente erstellt werden.
In SGML wurde der Einsatz der sogenannten DTD (Document Type Definition) eingeführt. Eine DTD beschreibt den strukturellen Aufbau von Dokumenten. Die DTD definiert im einzelnen die einsetzbaren Befehle und deren zusätzliche Optionen.
Ohne jetzt schon näher auf die Bedeutung der einzelnen Befehle einzugehen, sehen Sie im
folgenden Listing die Beschreibung des HTML-Markups IMG zum Einbinden einer Grafik in
ein HTML-Dokument:
<!ELEMENT IMG -->
<!ATTLIST IMG
src %URL #REQUIRED
alt CDATA #IMPLIED
align %IAlign #IMPLIED
height %Pixels #IMPLIED
width %Pixels #IMPLIED
border %Pixels #IMPLIED
hspace %Pixels #IMPLIED
vspace %Pixels #IMPLIED
-->
Neben dem IMG-Markup ist die komplette Syntax einschließlich aller erforderlichen und optionalen Attribute angegeben. Die Übersicht zeigt die Definition des Befehls nach dem aktuellen HTML-4.0-Standard. Im Dokument kann der Befehl dann beispielsweise wie folgt eingesetzt werden:
<IMG SRC="bild.gif" HEIGHT="200" WIDTH="150">
Üblicherweise schreibt man nicht für jedes Dokument eine neue DTD, sondern verwendet diese in einer Klasse von Dokumenten. Themen, die einer eigenen Dokumentenklasse zuzuordnen sind, könnten beispielsweise sein: Mathematik, Literatur, aber auch Versandhauskataloge.
Jede dieser Klassen zeichnen sich durch eine durchgängige Struktur aus: spezielle Bedürfnisse des Mathematikers z.B., um Formeln korrekt und einfach anzeigen zu können.
Für die einzelnen Versionen von HTML existiert jeweils nur eine einzige DTD. Das erleichtert uns einerseits natürlich die Arbeit damit, andererseits schränkt dieser kleinste gemeinsame Nenner aber auch ein. Auch in XML können eigene DTDs definiert werden, aber natürlich viel einfacher als mit SGML. Es existieren auf dem Markt außerdem keine HTML- Browser, die eine DTD einlesen könnten. Daher hat die Verwendung von DTDs bisher keine Rolle gespielt; die aktuellen HTML-Definitionen waren und sind einfach fest und unveränderlich in den Browser integriert und können frühenstens beim nächsten Browser-Update an aktuelle Veränderungen angepaßt werden.
Jedes SGML-Dokument beginnt mit der SGML-Deklaration. In diesem Teil der Datei finden wir einige Hinweise zur Konfiguration, beispielsweise die Festlegung des verwendeten Zeichensatzes.
Mit der folgenden Zeile beginnt ein SGML-Dokument:
<!SGML ISO8879:1986>
Sie gibt die Version des verwendeten Standards wieder. Zusätzlich zur ISO-Norm ist die Jahreszahl der Veröffentlichung mit angegeben.
Die wichtigsten Bestandteile einer SGML-Applikation sind:
SGML findet heute meist als Ausgangsbasis für die Weiterverarbeitung von Informationen seinen Einsatz. Dokumente werden ausgehend von SGML - meist automatisch - in visuelle Formate überführt, denn zum Anzeigen und Ausdrucken des SGML-Formats selbst existieren fast keine Möglichkeiten. Auf der Basis eines SGML-Textes ist es aber ohne weiteres möglich, beispielsweise TeX-Dateien oder PDF-Dokumente zu erstellen, die sich dann problemlos zu einem druckbaren Ergebnis umsetzen lassen.
Existierende SGML-Dokumente können in XML-Dokumente konvertiert werden, wenn einige Voraussetzungen erfüllt sind. In erster Linie muß dabei berücksichtigt werden, daß in der verwendeten DTD keine Features eingesetzt werden, die in XML nicht erlaubt sind. Einige manuelle Änderungen sind allerdings in den meisten Fällen trotzdem notwendig. In XML sind übrigens im Gegensatz zu SGML auch Dokumente ganz ohne Verweis auf eine DTD erlaubt. XML vermindert die gewaltige Komplexität von SGML und ermöglicht so einen wesentlich leichteren Zugang zu der Sprache sowie eine schneller Umsetzung in praktische Ergebnisse.
Folgende SGML-Konstrukte sind in XML nicht erlaubt:
<!-- Kommentar -->
ATTLIST-Deklarationen
sind nicht erlaubt.
CDATA, RCDATA-Befehle oder Minimierungs-Parameter
möglich.
#CURRENT oder #CONREF sind als Werte für Attribute nicht erlaubt.
RCDATA, TEMP, IGNORE oder INCLUDE markieren.
SDATA, CDATA und SUBDOC Befehle in internen oder externen Entities einsetzen.
SHORTREF, USEMAP, LINKTYPE, LINK, USELINK, IDLINK
Eine ganz neue Entwicklung, die erst auf der Basis von XML möglich war, präsentierte das W3C im Sommer 1998. Die neue deklarative Sprache Synchronized Multimedia Language (SMIL) wurde konkret als Unterstützung von Multimedia-Präsentationen im Web konstruiert. Sie schafft damit endlich einen eindeutigen Standard und macht Webdesigner nicht mehr abhängig von Dynamic HTML, Java-Script oder Plug-ins wie RealPlayer2 oder Shockwave.
Es handelt sich bei SMIL um eine Metasprache wie XML, die sich dann auch als Untermenge des XML-Sprachstandards deklariert. Mit SMIL können Multimediainhalte, wie Video, Audio oder Text, zeitlich koordiniert abgespielt werden. Die Empfehlung enthält allerdings keine detaillierten Vorschriften zu den verwendeten Multimedia-Formaten.
SMIL-Anweisungen lassen sich einfach in HTML-Quellcode integrieren und haben in ihrer Syntax eine große Ähnlichkeit mit der bekannten Hypertextsprache. Mit optionalen Attributen kann man steuern, wann eine Sequenz startet und wie lange sie läuft. Video- und Audioausgaben lassen sich so leicht synchronisieren. Durch die Trennung von Videobild und Tonausgabe können Videos in verschiedenen Sprachen ausgegeben werden, indem lediglich eine andere Audiosequenz eingespielt wird.
Ein weiterer entscheidender Vorteil von SMIL liegt nicht nur in der einfachen Einsetzbarkeit, sondern in den je nach vorhandener Bandbreite veränderbaren Anweisungen. Bei geringer Bandbreite wird dann beispielsweise keine zeitraubende Videosequenz gesendet, sondern eine reduzierte Version übertragen.
Zur Zeit existiert allerdings kaum Software für diesen neuen Standard, und auch die aktuellen Browserversionen unterstützen SMIL noch nicht. Microsoft zum Beispiel betrachtet die bestehenden Standards als ausreichend und sieht für eine Berücksichtigung von SMIL derzeit keinen Anlaß.
XML ist keine SGML-Anwendung, wie beispielsweise HTML, sondern ein SGML-Profil. Man spricht hier von einem »generalized markup« (verallgemeinerte Auszeichnung). Das ermöglicht es, eigene neue Sprachen zu definieren. Das heißt, Ihre Seiten werden letztendlich auch nicht mit XML, sondern mit einer darauf definierten Sprache verfaßt.
Eine solche Sprache könnte z.B. einem bestimmten Fachgebiet zugeordnet sein und insbesondere Befehle enthalten, die dort benötigt werden. Vorstellbar ist eine mathematisch orientierte Auszeichnungssprache, mit deren Hilfe sich komplexe Formeln darstellen lassen.
Einige solcher auf der Basis von XML definierten Auszeichnungssprachen existieren inzwischen schon oder befinden sich im Aufbau:
XML ist eine Teilmenge von SGML. Die Sprache wurde entworfen, um eine einfachere Implementierung neuer Elemente zu ermöglichen.
In den ersten Entwürfen zu XML war eine Kompatibilität zu SGML noch nicht gegeben. Man hat dann in den folgenden Entwicklungen große Anstrengungen unternommen, um XML zu einer Teilmenge von SGML zu machen. Letztlich wäre die vollständige SGML- Konformität nicht ohne Einschränkungen des XML-Standards möglich. Also hat man sich im Dezember 1997 dazu entschlossen, SGML entsprechend zu erweitern.
Letztlich bedeutet das in der Praxis, daß sich XML-Applikationen nicht immer ganz problemlos in SGML-Code umwandeln lassen.
XML unterscheidet sich zu HTML unter anderem dadurch, daß Informationsanbieter eigene Markup-Befehle und Attribute nach Bedarf definieren können. Dokumentenstrukturen können in Ihrer Komplexität an die erforderlichen Informationen angepaßt werden. Jedes XML- Dokument kann weitere optionale Beschreibungen seiner Grammatik enthalten, mit deren Hilfe eine Applikation dann eine strukturelle Überprüfungen durchführen kann.

Abb. 2.16: XML als Ausgangssprache für die Weiterverarbeitung.
Die Vision von XML für die Zukunft ist es die Sprache als Basis für jede Art von Daten zu etablieren. Aus diesen Daten können dann fast beliebig andere Dokumententypen erzeugt werden. Die heute anfallende Doppelarbeit bei Erfassung und Konvertierung fällt weg. Deutlich wird dabei auch, daß nicht mehr einzig und allein die Verarbeitung von Dokumenten im Vordergrund steht, sondern selbst Datenbanken wie beispielsweise Artikelstammdaten mit Hilfe von XML verarbeitet werden können.
In unserem Beispiel eines Versandhauses bildet eine Artikelübersicht auf der Grundlage von XML die Basis. Diese Artikelbeschreibungen können einerseits direkt in eine Lagerverwaltung konvertiert, andererseits aber auch in jede andere Form gebracht werden. Eine mühsame Mehrarbeit für die Erstellung des Online-Angebots oder der druckreifen Vorlagen entfällt.
Man erkennt allerdings schnell, daß unsere wunderbare und arbeitssparende Zukunftsvision nur funktionieren kann, wenn eine möglichst breite Schicht an Anwenderprogrammen den neuen Standard annimmt und unterstützt. Gegenwärtig sieht es so aus, als ob die Vision Realität werden könnte. In den USA ist ein wahrer XML-Boom ausgebrochen, der uns mit der üblichen Zeitverzögerung von einigen Monaten inzwischen erreicht. Software-Entwickler setzen alles daran, XML-fähige Versionen ihrer Produkte auf den Markt zu bringen. Allen voran hat Microsoft sich der Technologie angenommen und bietet in der neuen Office-2000- Version eine umfangreiche XML-Unterstützung an.
Ergänzend zu den Cascading Stylesheets kümmert sich XSL speziell um die Formatvorlagen zu XML. Sie bestimmen das Layout einer Seite oder wandeln Dokumente beispielsweise in HTML-fähige Konstrukte um. Die bekannten Cascading Style Sheets lassen sich zwar auch unter XML nutzen, XSL soll aber noch stärker auf die Belange von XML zugeschnitten sein.
Die Entwicklung von XSL wurde entscheidend durch die Firmen Microsoft, Inso und ArborText vorangetrieben, und so verwundert es auch nicht, daß die von Microsoft entwickelte Version als Vorschlag vom W3C übernommen wurde.
Bisher befindet sich XSL allerdings noch in einer sehr frühen Entwicklungsphase. Eine endgültige Version liegt noch nicht vor. Wir können frühestens im Mai 1999 mit einer offiziellen Verabschiedung des Standards rechnen. XSL ist abgeleitet von der »Document Style Semantics and Specification Language« (kurz DSSSL), die ihren Ursprung in der SGML-Entwicklung hat. Wesentliche Grundzüge von CSS bzw. der neueren Version CSS 2.0 fanden in XSL natürlich auch Eingang.
Eine neue Technologie für die Verwendung von Stylesheets unter XML wurde notwendig, da die Cascading Style Sheets doch mit einigen wichtigen Einschränkungen daherkommen. Die größte Einschränkung ist wohl das völlige Fehlen von typischen Elementen einer Programmiersprache. Beispielsweise lassen sich weder bedingte Abfragen definieren, noch werden Variablen unterstützt. So lassen sich mit Hilfe von CSS noch nicht einmal Seitenzahlen automatisch generieren.

Abb. 2.17: Mit Hilfe von XSL läßt sich aus XML-Dokumenten
automatisch HTML-Quellcode erstellen (Quelle: Microsoft).
Die Aufgaben von XSL liegen vor allem in zwei Bereichen:
Stylesheets haben für XML erheblich an Bedeutung gewonnen, denn abweichend von HTML kennt der Browser bei selbst definierten Befehlen nicht das Format, in dem er es anzeigen soll.
XML wurde von einer eigenen Arbeitsgruppe des W3C unter dem Vorsitz von Jon Bosak von Sun Microsystems entwickelt. Das W3C gründete diese Gruppe 1996 als Fortführung des SGML Editorial Review Board. Die zehn wichtigsten Ziele zum Entwurf der neuen Metasprache haben wir hier kurz zusammengefaßt:
In der Spezifikation werden folgende bereits bekannte Standards eingesetzt:
Die Tabellen dieser wichtigen ISO-Normen finden Sie im Anhang.
Gerade in einem Werk über XML erwarten Sie als Leser natürlich auch eine Einschätzung der Autoren zur zukünftigen Entwicklung mit kritischer Distanz zum Thema.
Soviel vorab: XML wird HTML, die Lingua Franca des Internets und Intranets, niemals ersetzen. Das stellt auch das W3-Konsortium in seinen Kommentaren kategorisch zu dieser Frage fest.
Die Entwicklung von HTML wird ausdrücklich weiter fortgeführt, und die oft gehörte Behauptung, XML sei der Nachfolger von HTML, ist somit hinfällig. Sicherlich werden wir auch noch eine HTML-Version 5.0 erleben, auch wenn die Entwicklung hier in Zukunft wesentlich langsamer vorangehen wird, denn durch XML muß nicht jedesmal ein neuer HTML-Standard vom W3C ausgerufen werden, wenn ein neuer Befehl erforderlich ist. Der Vorzug von XML liegt ja gerade in der Erweiterbarkeit. Auch müssen die Browserhersteller nicht ständig ihre Software überarbeiten - zumindest nicht aus dem Grund, weil eine neue HTML-Version verabschiedet wurde. Lediglich eine funktionierende XML-Unterstützung muß implementiert werden. XML ist auch keine neue Browsererweiterung oder ein Plug-in, sondern eine völlig neue Entwicklung zur Verwaltung, Verarbeitung und Veröffentlichung von strukturierten Daten.
Es stellt sich allerdings die Frage, warum überhaupt eine neue Metasprache zur Definition von Auszeichnungssprachen notwendig ist. Kann man den heutigen Erfordernissen von Multimedialität nicht einfach durch den weiteren Ausbau der Sprache HTML gerecht werden?
Die Ausrichtung von XML ist allerdings, wie Sie in den vergangenen Abschnitten erfahren haben, eine ganz andere. Wer heute HTML einsetzt, kümmert sich in erster Linie darum, wie die Informationen auf den Bildschirmen der Anwender erscheinen. XML ist dagegen stärker darauf ausgerichtet, Informationen so aufzubereiten, daß sie leicht weiterverarbeitet werden können.
Das folgende Beispiel einer einfachen Adressendefinition könnte in der vorhandenen Struktur in eine Datenbank überführt werden.
<ADRESSE>
<NACHNAME> Meier </NACHNAME>
<VORNAME> Hans </VORNAME>
<STRASSE> Waldweg 3 </STRASSE>
<PLZ> 33102 </PLZ>
<ORT> Paderborn </ORT>
</ADRESSE>
Eigentlich rücken hier Aspekte wieder in den Vordergrund, die in den ersten HTML-Versionen noch eine übergeordnete Rolle gespielt haben. Es geht nicht darum, wie die Informationen auf dem Monitor dargestellt werden, sondern viel stärker darum, wie sie strukturiert sind.
In der kommenden Zeit werden weitere neue Technologien zu XML unterstützend hinzukommen. Die Entwicklung geht also weiter, beispielsweise die schon erwähnten Extensible Style Sheet Language (XSL) oder Dynamic HTML mit dem Document Object Model. Größtenteils befinden sich diese zur Zeit noch in der Entwicklung und sind noch nicht ganz ausgereift.
In Zukunft wird HTML nicht durch XML ersetzt, aber HTML wird auf Basis von XML neu definiert und ist damit leichter an individuelle Belange anzupassen. Das W3C möchte bis ungefähr Ende 1999 die Entwicklung der nächsten HTML-Generation abgeschlossen haben. Diese Version wird deutlich von der Entwicklung der Expanded Markup Language geprägt sein.
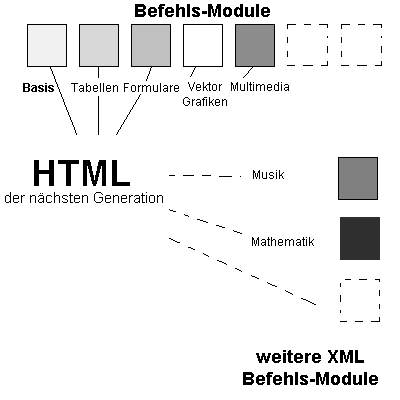
Abb. 2.18: Die Zukunft liegt in einer Verbindung von
HTML und XML (Quelle: W3C).
Die zukünftige HTML-Version wird aus einzelnen Befehlsmodulen (beispielsweise für Tabellen oder Multimedia-Elemente) bestehen, die je nach Bedarf dem Dokument hinzugefügt werden können. Neben dem Basismodul werden verschiedene vorgegebene aber optionale Module zur Verfügung stehen. Zusätzlich zu diesem Befehlskern, der die heute bekannten Tags enthält, ist es durch das Modulsystem möglich, eigene Befehlssätze auf XML-Basis zu schaffen und diese in die bestehende Struktur zu integrieren. Denkbar sind Module für den wissenschaftlichen Einsatz beispielsweise in der Mathematik.
Es besteht also mit XML kein Anlaß zur Sorge, jetzt bei Null anfangen und alle Befehle, mit denen man unter HTML so gut vertraut war, selbst neu erfinden zu müssen. Otto Normalanwender wird auch in den nächsten Jahren keinen Blick auf XML werfen müssen und seine Seiten weiterhin mit HTML erstellen. HTML wird weiterhin Grundlage für die unabhängigen und einfachen Dokumente im Web sein.
XML wird sich vor allem im professionellen Bereich der Dokumentenverarbeitung seinen Weg bahnen. Dort kann es mit seinen vielfältigen Möglichkeiten an die spezifischen Bedürfnisse insbesondere von größeren Projekten angepaßt werden.
Die Entwickler sind allerdings gefragt, sich der neuen Technologie anzunehmen. Den reinen Webdesigner, der sich nur mit der Präsentation im Netz beschäftigt, wird es so in Zukunft nicht mehr geben.
Vielmehr wird sich das Berufsbild auf die Realisierung von Konzeptionen zur Unternehmenskommunikation ausweiten. Aufgabe wird sein, Lösungen zu finden, die alle Informationen eines Unternehmens in einem Format zusammenführen.
Weg vom Design - hin zur Konzentration auf die Strukturierung der vorhandenen Daten. Der Bereich Webdesign wird sich nicht mehr völlig autark das bestehende Informationsmaterial zusammensuchen und zu einer Online-Präsenz formieren. Von der bereits vorhandenen Information beispielsweise aus dem Print-Bereich oder der Artikeldatenbank ist die fertige Internet-Präsentation dann nur noch einen Mausklick entfernt.
Also ist es gerade in diesem neu entstehenden und sich ständig verändernden Berufsfeld wichtig, sich flexibel an die neuen Gegebenheiten anzupassen. Aber hier besteht weniger Gefahr für alle, die zur Zeit von dieser Tätigkeit leben, denn eine Internet-Seite in HTML zu erstellen ist denkbar einfach, und mit dieser Fähigkeit allein kann und wird in Zukunft niemand mehr sein Geld verdienen können. Für die Erstellung komplexer Informationsstrukturen und die Umsetzung in XML sowie für die Porgrammierung von DTDs werden dagegen in Zukunft zunehmend Profis gefordert sein.
