 Mnozφ z nßs se dostßvajφ do problΘmu, jak
archivovat hmotnou p°edlohu textu do poΦφtaΦe a nemusφ to b²t nutn∞ jen papφr, tiskne se
i na dalÜφ a mΘn∞ skladnΘ materißly.
D∙le₧itΘ je p°edlohy sprßvn∞ naskenovat a nejlΘpe, s co nejmenÜφ nßmahou,
je p°evΘst do textovΘ
podoby pro zp∞tnou editovatelnost. Proto₧e se nßm poda°ilo pro Chip zφskat
plnou verzi rozpoznßvacφho programu FineReader 5 Sprint v ΦeskΘ a slovenskΘ
lokalizaci (instalace), rozhodli jsme se tΘto otßzce v∞novat vφce
vΦetn∞ teorie OCR. Pro ·plnost jsme oprßÜili
i poslednφ test stolnφch
skener∙ a recenzi nejnov∞jÜφ verze FineReader
6.0.
Mnozφ z nßs se dostßvajφ do problΘmu, jak
archivovat hmotnou p°edlohu textu do poΦφtaΦe a nemusφ to b²t nutn∞ jen papφr, tiskne se
i na dalÜφ a mΘn∞ skladnΘ materißly.
D∙le₧itΘ je p°edlohy sprßvn∞ naskenovat a nejlΘpe, s co nejmenÜφ nßmahou,
je p°evΘst do textovΘ
podoby pro zp∞tnou editovatelnost. Proto₧e se nßm poda°ilo pro Chip zφskat
plnou verzi rozpoznßvacφho programu FineReader 5 Sprint v ΦeskΘ a slovenskΘ
lokalizaci (instalace), rozhodli jsme se tΘto otßzce v∞novat vφce
vΦetn∞ teorie OCR. Pro ·plnost jsme oprßÜili
i poslednφ test stolnφch
skener∙ a recenzi nejnov∞jÜφ verze FineReader
6.0.
OCR a Φo s t²m
alebo Ako previes¥ papierov· predlohu do textovΘho s·boru
Skenovanie:
Tak₧e ak to chceme spravi¥, musφme ma¥ skener, ktor²m obraz predlohy zosnφmame
do poΦφtaΦa. M⌠₧e to by¥ aj digitßlny fotoaparßt, ale ten mß na tento ·Φel pomerne
nφzke rozlφÜenie. NaÜ¥astie to u₧ prestßva plati¥, ale musφ by¥ k nemu statφv,
dobr² /rovnomern²/ zdroj svetla a rozlφÜenie aspo≥ 2MPx. Nezabudnime na to,
₧e v tejto etape dostaneme do poΦφtaΦa iba bitov· mapu, nie hotov² text!
D⌠le₧it² je v²ber vhodnΘho skeneru. Budem hovori¥o skeneroch pre domßce pou₧itie,
kateg≤ria SOHO, teraz do cca 3-4000,- Sk. Na knihy s· pomerne nevhodnΘ skenery
s CCD snφmaΦom - tie najlacnejÜie a naj╛ahÜie niekedy ani nepotrebuj· napßjacφ
zdroj. Rozoznaj· sa aj t²m, ₧e u nich je zdrojom svetla pßs na zeleno svietiacich
di≤d. Daj· sa pou₧i¥ iba na jednotlivΘ listy, preto₧e maj· mal² sveteln² v²kon,
maximßlne na 1mm od skla. Obvykle s· aj v²razne pomalÜie. Odpor·Φam skenery
s vlastnou lampou, Φi u₧ halogΘnovou - /Umax/ alebo lampou so studenou kat≤dou
/Microtek/. HalogΘnovΘ lampy maj· r²chlejÜφ nßbeh, ale nieko╛kokrßt menÜiu ₧ivotnos¥,
studenokat≤dovΘ by mali chvφ╛u be₧a¥, k²m sa ustßli ich sveteln² tok. Obraz
je obvykle ostr² a₧ do 20mm, rozoznate╛n² do 30mm. Pokia╛ maj· extern² zdroj,
r²chlosti s· podobnΘ - Φi u₧ s· s rozhranφm SCSII, USB, paraleln² port. Be₧ne
zosnφmaj· stranu A4 v rozlφÜenφ 300DPI a vo farbe /25MB/ do dvoch min·t, 600DPI
/100MB/ do Ütyroch min·t. Pri 300DPI a 8bit Üedej A4 trvß cca 40-60sek·nd. USB
a SCSII mßvaj· r²chlejÜφ nßh╛ad, do 20 sek·nd. ╚o som sk·Üal naprφklad Microtek2000,
napßjan² cez USB - je dobr², ale z·falo pomal². Na rozlφÜenφ nezßle₧φ, vÜetky
zvlßdaj· rozlφÜenie 300DPI /bodov na palec/, ani pri skenovanφ obrßzkov nemß
v²znam φs¥ vyÜÜie - iba pri skenovanφ negatφvov je potrebnΘ aspo≥ 1200DPI, dianßstavec
a skener musφ vedie¥ vypn·¥ vlastn· lampu.
Medzi skenermi vybaven²mi USB a paraleln²m portom, prφpadne SCSII nie je v r²chlosti
v²razn² rozdiel, robieva to asi 10-20% v prospech USB /SCSII/, ale r²chlos¥
procesora sa podpφÜe ve╛mi v²razne. Naprφklad PII 700 oproti P100 robφ na r²chlosti
viac ako 100%!
MultifunkΦnΘ zariadenia sa daj· takisto pou₧i¥ /naprφklad HP/, ale musφme si
uvedomi¥, na ak² ·Φel sa bude pou₧φva¥ skenovaciu Φas¥. Ak mß celΘ zariadenie
tvar tlaΦiarne, m⌠₧eme do≥ vlo₧i¥ iba jednotlivΘ listy a na oskenovanie zviazanej
bro₧·ry m⌠₧eme zabudn·¥. VhodnejÜie /a drahÜie a vΣΦÜie/ s· s rovnou doskou
pre skenovanie - ale s· univerzßlnejÜie.
V poslednom Φase sa objavili skenery s rozhranφm USBII. Ich mechaniky s· stavanΘ
na r²chlejÜφ pohyb, nßh╛ad b²va do 10 sek·nd, Φo bolo eÜte nedßvno v²sadou ÜpiΦkov²ch
SCSII skenerov. Pre t²ch, Φo maj· ve╛a skenovania s· zrejme vhodnejÜie.
Dos¥ ve╛a zßle₧φ od vhodnΘho ovlßdaΦa pre skener. V₧dy nejak² Φas trvß, k²m
v²robca vychytß muchy, tak₧e ak pri skenovanφ poΦφtaΦ padß alebo je skenovanie
prφliÜ pomalΘ, nevßhajme a stiahnime si novÜφ ovlßdaΦ zo strßnky v²robcu. Mne
naprφklad novÜφ ovlßdaΦ /skener Microtek V6USL/ zr²chlil skenovanie skoro o
polovicu.
S vhodn²m skenerom sa dß skenova¥ cca 200strßn za hodinu /100 snφmkov/, pri
nastavenφ 300DPI, 8bit Üedej /gray scale/, dve strßnky A5 na jeden raz, jeden
snφmok potom zaberie asi 7MB. Treba rßta¥ aj s dostatoΦne ve╛k²m diskov²m priestorom
cca 500 - 1000MB na jednu knihu. Nezßle₧φ na v²stupnom formßte, ten si prednastavφ
skener a bolo by ho potrebnΘ stßle meni¥ - staΦφ pou₧i¥ nekomprimovan² TIFF,
BMP, PCX, ka₧d² modern² OCR /Optical Character Recognition - OptickΘ rozoznßvanie
znakov/ ich poznß. NajvhodnejÜφ je nekomprimovan² Tiff, naprφklad PNG z AcdSee3
mi FineReader6 nezobral, zatia╛ Φo z XnView bol bez problΘmov.
Ak strßnka obsahuje grafiku, ktor· chceme zachova¥, je vhodnΘ si v₧dy urobi¥
nßh╛ad /preview/, text potom zosnφma¥ ako odtiene Üedej a obrßzok ako pravΘ
farby /true color/. OCR to obvykle sφce zvlßdne, ale vΣΦÜinou je potrebnΘ obrßzky
mierne natoΦi¥, oreza¥ na sprßvnu ve╛kos¥, pou₧i¥ vhodn² filter, vymaza¥ chyby,
upravi¥ ·rovne... Ak ide iba o text, staΦφ si raz nastavi¥ v²rez a potom u₧
iba od¥ukßva¥ a otßΦa¥ strany.
Program na prezeranie obrßzkov ACDSee /od verzie 3.00/ alebo XnView /freevare/
maj· mo₧nos¥ Acquire /vyu₧φvaj· Twain rozhranie na zφskanie obrßzkov/. V polo₧ke
Acquire setup nastavφme adresßr, do ktorΘho ukladßme obrßzky, formßt a sp⌠sob
automatickΘho Φφslovania a dßme Acquire now. Program zavolß rozhranie Twain
a v ≥om sa sa u₧ iba odklepne SCAN. ACDSee v pozadφ preberß obrßzky, konvertuje
do zvolenΘho formßtu a Φφsluje ich.
Skenova¥ sa dß aj priamo z OCR - bu∩ pomocou Twain rozhrania alebo priamo z
programu. V takom prφpade staΦφ v²razne menÜφ diskov² priestor ale naprφklad
FineReader verzie 5 na Win 98 je v tomto re₧ime hßklivejÜφ, ╛ahÜie padß.
╚asom som priÜiel na jednu vec, ako zlepÜi¥ obraz poΦas skenovania. Dlho som
toti₧ laboroval s nastavenφm jasu a kontrastu - ve╛mi to nepomßha, tak₧e ich
ponechßvam na default hodnotßch. Ale v²razne pomßha v nastavenφ Twain v zßlo₧ke
Advanced Image Correction: White/Black Points - najprv dßm Auto - t²m sa automaticky
odstrßnia prßzdne okraje a potom ¥ahßm ╛av² /Φierny/ trojuholnφk doprava. T²m
sa odstrßni za₧ltnutos¥ strßn a vyblednutos¥ textu.
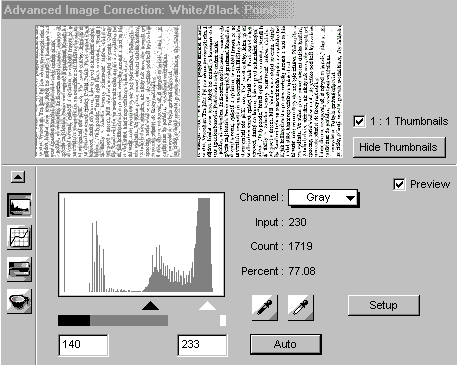
Prevod do textu:
Je jasnΘ, ₧e oskenovan² obrßzok zaberß prφliÜ ve╛a priestoru. Dß sa zmenÜi¥
pri pou₧itφ vhodnej kompresie, zmenÜenφm poΦtu bodov, farebnej hσbky, orezanφm
na vhodn² rozmer, pou₧itφm vhodn²ch filtrov - ale stßle je to obrßzok, v ktorom
sa rozumn²m sp⌠sobom nedß text editova¥.
Na tento ·Φel s· vytvorenΘ r⌠zne programy typu OCR, ktorΘ pomocou inteligentn²ch
algoritmov, vektorizßcie textu a zabudovan²ch slovnφkov rozoznßvaj· text z bitmapy,
prφpadne ho priamo prevßdzaj· do textu alebo do tabuliek. Pre naÜe ·Φely m⌠₧eme
pou₧i¥ vlastne iba dva produkty - Recognita z ma∩arskej firmy Recognita, teraz
u₧ OmniPage a Finereader od ruskej firmy Abbyy. Oba produkty s· vo verzii 5,
6, u₧ s· ve╛mi sluÜne pou₧ite╛nΘ. Ja osobne preferujem Abby Finereader, preto₧e
mß lepÜie v²sledky pri prevode - menej ch²b, nemß problΘmy pri farebnom pozadφ
a pri ve╛mi zlom podklade, z domovskej strßnky sa dß stiahnu¥ vo verzii Office
alebo Pro + prφsluÜnΘ slovnφky pod╛a v²beru + interface v slovenΦine, Φestine....
Nev²hody - je pomalÜφ ako Recognita, stiahnutß verzia je typu Try & Buy
/30 spustenφ, vo verzii 6 u₧ iba 15 spustenφ/ a je hßkliv² na zmeny hardwaru
a softwaru. Stiahnutß inÜtalaΦka /verzia 5, iba anglick² jazyk/ zaberß asi 24MB,
nainÜtalovanß verzia cca 37MB.
Oficißlna strßnka programu Abby Finereader je
www.abbyy.com, je mo₧nΘ si odtia╛
stiahnu¥ prφsluÜn· demoverziu. Odpor·Φam φs¥ aj na strßnku www.nupseso.cz, kde
s· k dispozφcii cennφky, aktualizßcie, lokalizovanΘ demoverzie a nßvody na pou₧itie.
Strßnka programu Recognita je www.recogita.hu, na ktorej vidie¥, ₧e preÜla pod
ochrannΘ krφdla OmniPage. Kedysi tam bola demoverzia Recognity 5, dnes u₧ iba
podpora pre zak·pen² produkt.
╚o sa t²ka stability programu FineReader, je to r⌠zne. Verzia 5 mi chodila
bez problΘmov na Win98, Win98SE i WinXP /s patchom na ·pravu registrov/, zatia╛
Φo 6 mi na Win98 pri skenovanφ so s·Φasn²m rozoznßvanφm textu pomerne spo╛ahlivo
asi po 30 stranßch spadla /aj s operaΦn²m systΘmom - chyba modulu Scanman/.
Tßto chyba zostala i na∩alej, i ke∩ sa tvrdφ, ₧e v novom builde sa zmenil skenovacφ
modul. V takom prφpade je najlepÜie najprv oskenova¥ a FineReader /∩alej iba
FR/ potom pusti¥ iba na obrßzky. Inak na tom istom HW, s t²mi ist²mi univerzßlnymi
ovlßdaΦmi pod WinXP bez problΘmov - a je tam aj r²chlejÜφ.
Pre t²ch, Φo chc· experimentova¥ s ·pravou FR, naprφklad maj· verziu bez jazykovej
mutßcie a chc· si ju doinÜtalova¥, pozor. FR si ve╛mi chrßni integritu svojich
modulov a pri v²mene kni₧nφc skonΦφ trialovß verzia s nulov²m poΦtom dnφ. Naprφklad
╚ediΦa /http://cedic.bonusweb.cz// svojho Φasu do₧ralo, ₧e FR6 nemal lokalizßciu,
upravil prφsluÜn· dll - fungovalo to, ale ak ju pou₧ijeme na najnovÜom builde
/647/, okam₧ite je po sk·Üanφ. Dß sa tomu pom⌠c¥ iba tak, ₧e si zazßlohujeme
systΘmov² disk /naprφklad programom NortonGhost alebo Powerquest DriveImage
eÜte pred inÜtalßciou FR/ a ak sa vßm podarφ zruÜi¥ sk·Üanie, vrßtime si systΘm
do p⌠vodnΘho stavu a inÜtalujeme znovu. Pozor, vytvßranie Restore Point vo WinXP
nepom⌠₧e.
Porovnanie medzi pln²mi verziami FR5 a 6 je z m⌠jho h╛adiska takΘto: FR6 zaberß
viac miesta, je r²chlejÜφ, vie lepÜie rozoznßva¥, trial verzia je iba na 15
spustenφ. V²robca tvrdφ, ₧e vie preΦφta¥ aj zaheslovanΘ pdf s·bory, ale je to
tak, ₧e si ich vytlaΦφ do bmp a tie potom rozoznßva - sφce s ve╛kou presnos¥ou,
ale aj tak...
Tak₧e ∩alej o programe Abbyy FineReader 5, 6 /plnß verzia/:
Po inÜtalßcii programu a jeho ·speÜnom spustenφ je potrebnΘ najprv zvoli¥ pracovn²
adresßr, kde sa ukladaj· texty, obrßzky a v²sledky - bu∩ nov² - File/New Batch
alebo otvori¥ predchßdzaj·ci - Open Batch. Potom je potrebnΘ zvoli¥ jazyk, prφpadne
viac jazykov naraz, ak sa vyskytuj· v texte.
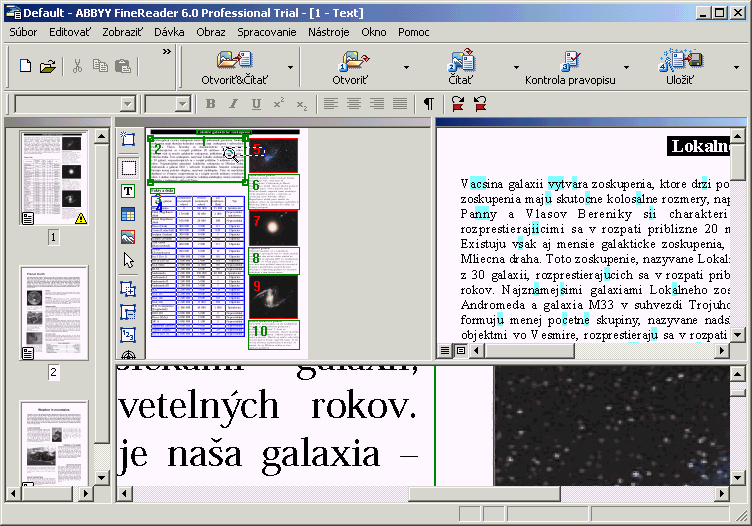
Ak sa bude prevßdz¥ text priamo zo skeneru, musφte ho najprv nastavi¥ - Tools/Options/zßlo₧ka
Scan/Open Image/Select Source.
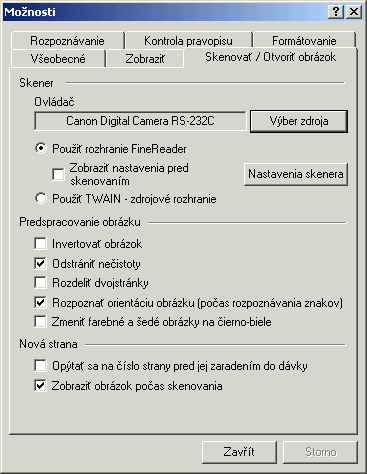
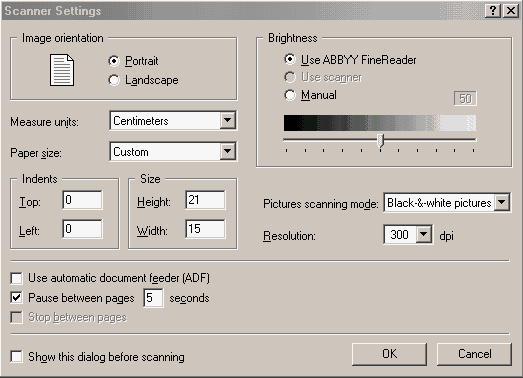
Ak sa bude prevßdza¥ u₧ naskenovan² obrßzok, potom staΦφ cez tlaΦφtko alebo
File/Open Image - formßty bmp, dcx, jpg, pcx, png, tiff.
Program obrßzky naΦφta, vyberie vlastn² nßh╛ad, natoΦφ do sprßvnej polohy, preΦφta,
do druhΘho okna vlo₧φ text, prφpadne upozornφ na chyby.
Samozrejmos¥ou je mo₧nos¥ natoΦenia obrßzka, ruΦnΘho upravovania ve╛kosti rßmcov,
ich typu /obrßzok, text, tabu╛ka, Φiarov² k≤d/ ... - po t²chto ·pravßch treba
prφsluÜn² dokument znovu preΦφta¥. V²sledn² text sa dß u₧ priamo editova¥, ale
ja si to nechßvam na nesk⌠r, po naΦφtanφ v²slednΘho dokumentu do Wordu. Vyplatφ
sa naÜtudova¥ si uΦiaci proces - hlavne pri Φastej prßci a rovnak²ch podkladoch
- naprφklad program si niekedy m²li ∩ a d'...
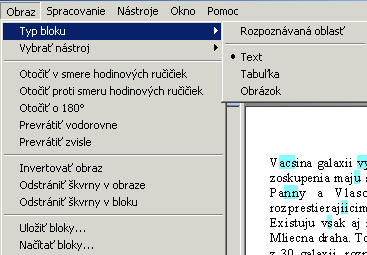
Ak u₧ boli naΦφtanΘ vÜetky podklady, treba ulo₧i¥ v²sledn² dokument. Ja ho ukladßm
do s·boru, vo formßte txt, vÜetky strßnky do jednΘho s·boru, s odstrßnenφm vÜetk²ch
formßtovacφch znaΦiek, bez obrßzkov, vo ve╛kosti A5. Ak chceme zachova¥ obrßzky,
ulo₧φme dokument ako dokument Word /bude vo formßte rtf, tak sa neΦudujme, ₧e
m⌠₧e narßs¥ aj na nieko╛ko sto MB/ a po otvorenφ vo Worde ho ulo₧φme ako html.
Obrßzky tam bud· dvakrßt, tie menÜie vyma₧eme a t²m mßme /skoro/ originßlny
naskenovan² obrßzok, ktor² si m⌠₧ete upravi¥ pod╛a vlastnej chute. Ale prφliÜ
sa neteÜme, preto₧e je pri nich pou₧itß silnß kompresia /JPEG/ a detaily sa
dos¥ v²razne zlievaj·. Tak₧e ak chceme zφska¥ dobrΘ obrßzky, najprv podklad
oskenujeme, FR pustφme a₧ na skeny a obrßzky si robφme nezßvisle.
V prφpade, ₧e ponechßme vo╛bu "Zachova¥ formßtovanie", FR vytvorφ
ve╛kΘ mno₧stvo Üt²lov, ktorΘ sa sna₧ia Φo najvernejÜie kopφrova¥ vzh╛ad p⌠vodnΘho
dokumentu. LφÜia sa od seba navzßjom nepodstatn²mi drobnos¥ami - naprφklad ve╛kos¥
pφsma sa lφÜi o 0,5 bodu, odsadenie okrajov v 0,1mm, rozÜφrene a z·₧enie pφsma
o 0,01mm... V dlhÜom texte ich m⌠₧e by¥ aj nieko╛ko stoviek. Dß sa to pre₧i¥
vtedy, ak s t²m textom u₧ ∩alej nebudeme pracova¥ a ak je toho iba nieko╛ko
strßn. Ak je toho viac, je lepÜie sa formßtovania zbavi¥ a upravova¥ ho a₧ pri
korekt·re.
╚o sa t²ka nßroΦnosti na hardware - je vysokß. Ak pustφme rozoznßvanie textu
na Celeron 400, je to asi r²chlejÜie klepa¥ ruΦne, pri 850MHz nem⌠₧ete spusti¥
₧iadnu in· ·lohu, ale stφha v reßlnom Φase - t.j. k²m sa jedna strana oskenuje,
predchßdzaj·ca sa stihne rozozna¥ a pri procesore nad 1000MHz u₧ m⌠₧ete popritom
aj vypa╛ova¥ CD.
Porovnanie verzie Sprint a plnej verzie:

Po ·speÜnej inÜtalßcii m⌠₧ete doΦasn² adresßr C:\ABBY vymaza¥.
Verzia Sprint je ve╛mi zjednoduÜenß, hlavn² rozdiel je v tom, ₧e neumo₧≥uje
naΦφta¥ viacero obrßzkov a dßvkovo ich spracova¥. To znamenß, ₧e v₧dy sa dß
otvori¥ iba jeden obrßzok, rozozna¥ ho a ulo₧i¥ v²sledok do s·boru iba ako txt
alebo rtf. To istΘ platφ aj pre skenovanie, v₧dy sa spracovßva iba jedna strana.
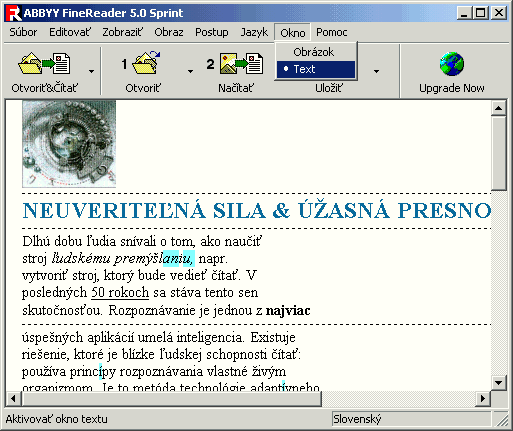
Nepodporuje viacstranovΘ tif-y, ktorΘ vytvßra FR6, tak₧e je ich vhodnΘ najprv
prekonvertova¥ do png. Okrem toho umo₧≥uje pou₧i¥ iba jeden rozoznßvacφ jazyk,
je vidie¥ iba jedno okno - bu∩ obrßzok alebo rozoznan² text, nie oboje naraz,
nedß sa upravi¥ nßstrojovß liÜta. Tie₧ ch²ba re₧im uΦenia a vytvßranie u₧φvate╛sk²ch
slovnφkov. Kvalita rozoznßvania je ve╛mi dobrß, na poΦudovanie aj funguje celkom
svi₧ne /₧eby preto Sprint?/. Na obΦasnΘ pou₧itie je tßto verzia dostaΦuj·ca.
Ak by bolo ale potrebnΘ spravi¥ knihu s nieko╛ko sto stranami, potom je vhodnejÜie
ju naprv cel· naskenova¥ a na obrßzky pusti¥ pribalen· FR6 trial verziu, prφpadne
k·pi¥ pln· ako uprage na verziu Sprint.
Formßtovanie a ·pravy textu:
Najprv troÜku vÜeobecne. Po digitalizßcii dokumentu v texte v₧dy zostane urΦitΘ
mno₧stvo znaΦiek, ktorΘ mo₧no prßve teraz problΘmy nerobia, ale nesk⌠r sa mo₧no
prejavia - bu∩ pri konverzii do in²ch formßtov, alebo pri Φφtanφ v nov²ch Φφtacφch
programoch. Naprφklad Word mß urΦitΘ rezervy, ve╛a vecφ ignoruje - ale Φo ke∩
sa to niekedy trafφ? HTML strßnky tie₧ niekedy na konci riadka pridßvaj· znaΦku,
ktor· potom musφme odstrßni¥.
NajjednoduchÜie sa formßtovacie znaΦky odstrßnia tak, ₧e cel² dokument sa ulo₧φ
ako prost² text. Ten sa potom otvorφ bu∩ priamo vo Worde alebo /lepÜie/ text
sa cez schrßnku /Vybra¥ vÜetko alebo Ctrl+A, Skopφrova¥ do schrßnky alebo Ctrl+C/
vlo₧φ do dokumentu /Vlo₧i¥ alebo Ctrl+V/.
Normßlne nevidite╛nΘ znaky si zobrazφme tlaΦφtkom pre ich zobrazenie
 . Potom
je vidie¥ naprφklad koniec odstavca, oddielu, viacnßsobnΘ medzery, volite╛nΘ
rozdelenie, ktorΘ be₧ne nevidφme.
. Potom
je vidie¥ naprφklad koniec odstavca, oddielu, viacnßsobnΘ medzery, volite╛nΘ
rozdelenie, ktorΘ be₧ne nevidφme.

Vo Worde pou₧φvam funkciu Rozvrhnutie dokumentu
 , pod╛a m≥a je vhodnejÜia ne₧
Obsah. Umo₧≥uje r²chly pohyb po dokumente a dobr² preh╛ad. Vyvolßva sa tlaΦφtkom
alebo z menu Zobrazit / Rozvr₧enφ dokumentu.
, pod╛a m≥a je vhodnejÜia ne₧
Obsah. Umo₧≥uje r²chly pohyb po dokumente a dobr² preh╛ad. Vyvolßva sa tlaΦφtkom
alebo z menu Zobrazit / Rozvr₧enφ dokumentu.
Ak je dokument zle naformßtovan², rozvrhnutie je nepreh╛adnΘ, nachßdzaj· sa
v ≥om k·sky textu... Vtedy je lepÜie oznaΦi¥ cel² dokument /Ctrl+A/ a z tlaΦφtkovΘho
menu èt²ly vybra¥ Normßlny, prφpadne Vymaza¥ formßtovanie.
Potom sa daj· jednotlivΘ nadpisy oznaΦova¥ prφsluÜn²m Üt²lom. Ak aj nebude hne∩
vyhovova¥, nevadφ, po ukonΦenφ oprßv sa daj· naraz upravi¥ z menu Formßt / èt²l
/ Upravi¥ / Formßt - odstavca alebo pφsma....
╚φslo strßnky sa obvykle nachßdza na zßpΣtφ strßnky, upravi¥ jeho formßt je
mo₧nΘ po poklepanφ. Ak chceme zmeni¥ niektorΘ vlastnosti - naprφklad nezobrazova¥
Φφslo strßnky na prvej strane alebo zaΦa¥ Φφslova¥ nie od 1, nßjdeme to v menu
Vlo₧i¥ / ╚φsla strßnek / Formßt.
Word mß mo₧nos¥ korekcie pravopisu - samozrejme, musφ by¥ nainÜtalovanß. Vie
sφce automaticky rozpoznßva¥ jazyk, ale nie je to slßvne. LepÜie je oznaΦi¥
cel² dokument a z menu Nßstroje / Jazyk / Nastavit jazyk vybra¥ prφsluÜn² jazyk.
Ak chceme ma¥ slovß na konci strßnky rozde╛ovanΘ, /preferujem, dokument sa lepÜie
Φφta, s· v ≥om menÜie medzery/, je to dostupnΘ z menu Nßstroje / Jazyk / D∞lenφ
slov.
V prφpade, ₧e chceme pou₧i¥ pφsma mierne neÜtandardnΘ /okrem klasick²ch naprφklad
Ariel, Times/, je dobrΘ ma¥ povolen· funkciu Vlo₧it pφsma True Type z menu Nßstroje
/ Mo₧nosti / Ulo₧it. Ak povolφme funkciu Vlo₧it pouze pou₧itΘ znaky, m⌠₧e sa
pri otvorenφ na druhom poΦφtaΦi sta¥ to, ₧e dokument bude otvorite╛n² iba pre
Φφtanie a nebude sa da¥ editova¥. Pom⌠₧e vybra¥ cel² obsah cez schrßnku a ulo₧i¥
ako nov² dokument.
A na koniec:
Mnoho ╛udφ si myslφ, ₧e po prehnanφ podkladu cez OCR zφska na 100% tak² ist²
text. Nie je to pravda. Pod╛a kvality podkladu sa zφska text s urΦitou chybovos¥ou
- ak je dobr², b²va 1-2 chyby na strßnke, ale m⌠₧e by¥ i nieko╛ko desiatok.
Nerßtam v to zßhlavia a Φφsla strßnok, ktorΘ vlastne tie₧ treba odstra≥ova¥.
Preto v₧dy musφme po OCR eÜte skontrolova¥ v²sledn² dokument a porovna¥ ho s
originßlom, upravi¥ formßtovanie, aby sa zhruba podobalo na originßl a aby sa
dal dobre Φφta¥ na obrazovke. Inak pri takomto porovnßvanφ Φasto prφdete na
mno₧stvo ch²b aj v p⌠vodnom dokumente, tak sa ve╛mi neΦudujme. A v tomto okam₧iku
si m⌠₧eme by¥ istφ, ₧e v 100 stranovom dokumente mßme eÜte asi 10-20 ch²b, ktorΘ
sme prehliadli. Preto nastupuje Φlovek, naz²vam ho korektor, ktor² si tento
text preΦφta - obvykle nemusφ ma¥ podklad a bu∩ priamo opravuje chyby v texte
alebo ich vyznaΦφ farbou, prφpadne ich ulo₧φ do textovΘho s·boru a poÜle nßm
ho naspΣ¥. My tieto opravy bu∩ prijmeme alebo zamietneme. Dobr² text zφskame
vtedy, ak si ho preΦφtaj· aspo≥ dvaja r⌠zni korektori. Ak si teraz niekto pomyslφ,
₧e staΦφ, ke∩ si to po sebe preΦφta eÜte dvakrßt, tak je na omyle - t²ch ch²b
nßjde ove╛a menej.
OCR je dobrß vec, ale obrßzok niekedy tie₧...
RoboV
