Princip rozpoznßvßnφ textu
Mnoho u₧ivatel∙ ji₧ °adu let pou₧φvß programy pro rozpoznßvßnφ obraz∙ (OCR) ke zp∞tnΘ transformaci textov²ch informacφ a k jejich nßslednΘmu zpracovßnφ. V∞tÜina z nßs ale nemß p°edstavu, jak²m zp∙sobem tyto programy fungujφ.
V∞deckΘ v²zkumy v oblasti poΦφtaΦovΘho vid∞nφ postupujφ pom∞rn∞ pomalu. Donedßvna byl zßkladnφm prvkem v t∞chto systΘmech fotoΦlßnek, kter² mohl m∞°it jas v jednom bodu. O kvalitativnφ ·rovni t∞chto systΘm∙ nemß smysl hovo°it. Mohou pouze urΦovat p°φtomnost nebo absenci n∞jakΘho objektu nebo urΦit jeho p°ibli₧nΘ rozm∞ry. Ale s v²vojem digitßlnφ techniky se objevily skenery a digitßlnφ kamery. Zßkladem jejich konstrukce je Φip s n∞kolika miliony CCD prvk∙ citliv²ch na sv∞tlo. Novß technika znaΦn∞ rozÜφ°ila mo₧nosti t∞chto senzor∙, kterΘ dodßvajφ informace z okolnφho prost°edφ pro dalÜφ zpracovßnφ a anal²zu. NicmΘn∞ bez ohledu na neustßlΘ vylepÜovßnφ techniky a algoritm∙ jsou pro plnohodnotnΘ rozpoznßvßnφ obraz∙ nutnΘ v²poΦetnφ kapacity zcela jinΘho °ßdu.
Vznikl zde takΘ nov² problΘm, spojen² s nedostatkem poznatk∙ o tom, jak se zpracovßvß vizußlnφ informace v lidskΘm mozku potΘ, co sv∞tlo zaost°enΘ oΦnφ ΦoΦkou dopadne na tyΦinky a Φφpky sφtnice naÜeho oka.
Existuje jeÜt∞ jedna d∙le₧itß zvlßÜtnost v lidskΘm vid∞nφ. Na rozdφl od poΦφtaΦe m∙₧eme jeden a ten sam² objekt vnφmat r∙zn∞: bu∩ odd∞len∞, nebo jako Φßst jinΘho objektu nebo celku - v zßvislosti na okolφ. ProblΘm vyhledßvßnφ a vyΦlen∞nφ jednoho objektu dnes nem∙₧e b²t vy°eÜen v souΦasn²ch OCR algoritmech kv∙li slo₧itosti zrakovΘho vnφmßnφ Φlov∞ka.
Obvykle se dokumenty pro nßslednΘ rozpoznßvßnφ skenujφ v 256 odstφnech Üedi. Pro efektivnφ rozpoznßvßnφ ale pot°ebuje mφt OCR algoritmus dokument v dvoubarevnΘm formßtu, aby mohl rychle a jednoduÜe rozeznat a odliÜit barvu pozadφ a barvu textu nebo linie. Samoz°ejm∞ ₧e se dß skenovat dokument okam₧it∞ v dvoubarevnΘm formßtu a soubory jsou tak osmkrßt menÜφ. Ale proto₧e algoritmy skener∙ transformujφ zobrazenφ do dvoubarevnΘho formßtu h∙°e ne₧ algoritmy, kterΘ se pou₧φvajφ v OCR programech, je p°ece jen lepÜφ skenovat v 256 odstφnech Üedi.
Rozpoznßvßnφ formulß°∙ - tiskopisyJednß se o formulß°e, kterΘ se obvykle tisknou v tiskßrnßch a majφ standardnφ rozm∞ry, ale polφΦka se v nich zapl≥ujφ psacφm strojem nebo ruΦn∞. Perspektiva neustßlΘho rozpoznßvßnφ standardnφho formulß°e a vyhledßvßnφ nepot°ebn²ch blok∙ nikoho nep°itahuje, proto se v takov²ch p°φpadech obvykle rozpoznßvajφ jednotlivß textovß pole a potom se v²sledek uklßdß ve form∞ tabulky nebo databßze. V jednoduÜÜφm p°φpad∞, kdy jsou tiskopisy v dostateΦn∞ dobrΘ kvalit∞ pro OCR algoritmus, staΦφ ukßzat vÜechna pole nutnß k rozpoznßnφ obsahu ve tvaru obdΘlnφkov²ch oblastφ. Pro reßlnΘ ·koly to vÜak nenφ dostaΦujφcφ. Na standardnφch formulß°φch chybφ jakßkoliv informace o zßkladnφch bodech dokumentu (sou°adnice bod∙, od kter²ch zaΦφnß odpoΦet polφ dokumentu). Vznikß vß₧n² problΘm spojen² s tφm, ₧e automatick² skener ne zcela p°esn∞ uchopφ dokument, nßsledn∞ ho nep°edvφdateln∞ vertikßln∞ nebo horizontßln∞ posune, nebo se dokument dokonce nepatrn∞ pootoΦφ o mal² ·hel. Kv∙li tomu v mφst∞, kde OCR algoritmus oΦekßval textovou informaci, obdr₧φ bu∩ prßzdn² kus dokumentu, nebo jen Φßst pot°ebnΘho pole, a vÜechna prßce OCR algoritmu tak ztrßcφ smysl. Pro vy°eÜenφ tohoto problΘmu je nutnΘ pou₧φt specißlnφ opravn² algoritmus, kter² dokß₧e na zßklad∞ obsahu dokumentu zφskat pot°ebnou informaci o posunu a pootoΦenφ dokumentu pro jeho dalÜφ sprßvnΘ rozpoznßnφ. Slo₧it∞jÜφ je °eÜenφ problΘmu s pootoΦenφm, proto₧e pro pootoΦenφ dokumentu o libovoln² ·hel se pou₧φvajφ operace s pohyblivou °ßdovou Φßrkou. ┌hlovß korekce zabφrß velmi mnoho Φasu, dokonce vφce ne₧ rozpoznßvßnφ polφ. Kv∙li algoritmickΘ slo₧itosti tΘto korekce se prakticky nikde nerealizuje. Ani pro Φlov∞ka to nenφ jednoduch² ·kol, nehled∞ na to, ₧e nßÜ mozek bez zvlßÜtnφ nßmahy neustßle vykonßvß velkΘ mno₧stvφ obdobn²ch operacφ. Krom∞ toho vznikß problΘm spojen² s tφm, ₧e vizußln∞ podobnΘ tiskopisy byly tiÜt∞ny v r∙znou dobu a v r∙zn²ch tiskßrnßch, a proto mohou mφt sou°adnice polφ nepatrn∞ rozdφlnΘ rozm∞ry, co₧ zp∙sobφ posun jedn∞ch polφ vzhledem k jin²m. V t∞chto p°φpadech je pro rozpoznßvßnφ dokumentu jednoho tiskopisu s menÜφmi odchylkami obvykle nutnΘ pou₧φvat n∞kolik podobn²ch Üablon. |
V nejjednoduÜÜφm p°φpad∞ je mo₧nΘ pro transformaci do dvoubarevnΘho formßtu zadat konstantnφ ·rove≥ prahu jasu pro rozd∞lenφ bod∙. Ale kv∙li r∙zn²m parametr∙m jasu a kontrastu p°edloh bude takov² algoritmus informaci zkreslovat v₧dy, kdy₧ se jas dokumentu bude liÜit od standardnφho.
Jestli₧e zaΦneme dokument postupn∞ zesv∞tlovat (zvyÜovat jas), bude se postupn∞ zmenÜovat tlouÜ¥ka liniφ znak∙, dokud nezmizφ jednotlivΘ Φßsti znak∙ a cel² znak se neslije se sv∞tl²m pozadφm. P°i zv²Üenφ jasu m∙₧e stßle menÜφ mno₧stvφ bod∙ p°ekonat mez sv∞tlosti. A pokud budeme naopak dokument zatem≥ovat (sni₧ovat jas), linie znak∙ se budou postupn∞ rozÜi°ovat, dokud se nezaΦnou spojovat se sousednφmi a potom zΦernß celΘ pozadφ. Takovß zkreslenφ znemo₧≥ujφ rozpoznßvßnφ jednotliv²ch znak∙. JeÜt∞ je mo₧nΘ ud∞lat pohyblivou hranici mezi Φernou a bφlou. Nap°φklad urΦit pr∙m∞rn² odstφn a podle n∞j spoΦφtat rozdφlovou mez nebo najφt bod s minimßlnφm a maximßlnφm jasem a hranici spoΦφtat jako jejich pr∙m∞r.
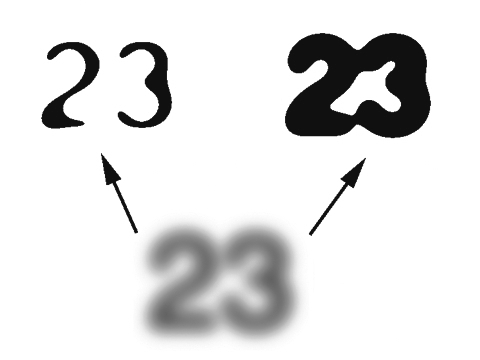
Tyto algoritmy budou ·sp∞Ün∞jÜφ, ale vznikne jin² problΘm, spojen² s nerovnom∞rn²m osv∞tlenφm dokumentu. Nap°φklad levß strana je osv∞tlenß a pravß je zatemn∞nß a mezi nimi je plynul² p°echod. P°edchozφ algoritmus zjistφ mez podle celΘho dokumentu, provede transformaci a vznikne nßsledujφcφ situace: znaky uprost°ed dokumentu budou dob°e viditelnΘ, ale znaky zleva budou Φasto poruÜenΘ, znaky zprava budou zalitΘ Φern∞. Tento problΘm je ne°eÜiteln² pomocφ univerzßlnφch program∙. K tomu je zapot°ebφ intelektußln∞jÜφ algoritmus, kter² bude analyzovat dokument po Φßstech, zjiÜ¥ovat mez a transformovat ho do ΦernobφlΘho formßtu.
┌kol transformovßnφ dokumentu z formßtu 256 odstφn∙ Üedi do dvoubarevnΘho nenφ v praxi a₧ tak jednoduch². Je nutnΘ pou₧φt specializovanΘ algoritmy, pot°ebnΘ pro kvalitnφ zpracovßnφ dokument∙ s rozdφln²m rozlo₧enφm jasu. Tento problΘm je aktußlnφ p°edevÜφm pro dokumenty napsanΘ na psacφm stroji p°es kopφrovacφ papφr. Vzhledem ke zvlßÜtnosti tisku je barva uvnit° obrysu znaku temn∞jÜφ ne₧ zvenΦφ a po p°etransformovßnφ do ΦernobφlΘho formßtu se jednotlivΘ linie znak∙ slΘvajφ, co₧ zp∙sobuje chyby.
Po zφskßnφ dvoubarevnΘho zobrazenφ v dostateΦnΘ kvalit∞ mohou na obrazu z∙stat jednotlivΘ nßhodnΘ body nebo menÜφ skupiny bod∙, kterΘ vnßÜφ chyby do procesu rozeznßvßnφ. Zpracovßnφm zßkladnφch parametr∙ skupin, jako je nap°φklad hustota skupiny, rozm∞r prvku a vzdßlenosti mezi jednotliv²mi sousednφmi prvky, je mo₧nΘ vybudovat filtr pro odstran∞nφ nejr∙zn∞jÜφch Üum∙.
NejΦast∞ji se objevuje vysokofrekvenΦnφ Üum, projevujφcφ se body rozhßzen²mi na pozadφ. K jeho odstran∞nφ je zapot°ebφ provΘst anal²zu sousednφch bod∙, a pokud je plocha jednotlivΘho kousku mnohokrßt menÜφ ne₧ plocha znaku, je mo₧nΘ ho odstranit. Slo₧it∞ji se provßdφ odstran∞nφ "smetφ" st°ednφho rozm∞ru, v₧dy¥ jeho velikost m∙₧e b²t srovnatelnß s rozm∞ry jednotliv²ch Φßstφ pφsma. Stßvß se, ₧e jsou to nßhodnΘ kousky linek nebo Φrt∙.
V souvislosti s tφm, ₧e dokumenty nejsou v₧dy ideßlnφ, mohou b²t pφsmena rozd∞lena trhlinami. V tomto p°φpad∞ m∙₧e vΘst pokus o zv∞tÜenφ rozm∞ru odstra≥ovanΘho st°edn∞frekvenΦnφho Üumu k odstran∞nφ v²znamn²ch Φßstφ znak∙ a k nßslednΘ nemo₧nosti jejich rozpoznßnφ. Proto je mo₧nΘ odstra≥ovat st°edn∞frekvenΦnφ Üum jen v p°φpad∞, kdy₧ je stabilnφ, dob°e rozeznateln² a nekryje se s mo₧nostφ poruÜenφ znaku.
Perceptron
Pro rozpoznßvßnφ jednotlivΘho znaku je mo₧nΘ pou₧φt r∙znΘ algoritmy. Jednφm
z prvnφch byl algoritmus s nßzvem Perceptron. Velmi dob°e se uvedl a ve svΘ
dob∞ znamenal p°evrat v teorii rozpoznßvßnφ obrazc∙. Pro rozpoznßnφ se pou₧φvß
matrice senzor∙, kde ka₧d² senzor odpovφdß za stav skupiny bod∙ v urΦitΘ oblasti.
V²stupem senzoru je bu∩ stav pozadφ, nebo stav barvy jako Φßsti znaku. Podle
toho, kterΘ senzory se nachßzejφ ve stavu Pozadφ a kterΘ ve stavu Znak, je mo₧nΘ
pom∞rn∞ p°esn∞ urΦit, kter² znak se nachßzφ na vstupu Perceptronu, p°φpadn∞
dojφt k zßv∞ru, ₧e jde o neznßm² znak.
Maximßlnφ automatizaceSpecißlnφ formulß°e pro OCR programy |
Tento algoritmus se v nejjednoduÜÜφm p°φpad∞ pou₧φval v n∞kter²ch zemφch na poÜtßch p°i Φtenφ poÜtovnφch sm∞rovacφch Φφsel. V tomto p°φpad∞ byly velmi dob°e znßmy sou°adnice ka₧dΘho znaku a takΘ jeho hranice. Nejsou zde problΘmy se znaky r∙zn²ch velikostφ, m∞°φtko je takΘ znßmΘ, nem∞lo by vznikat ani r∙znΘ naklon∞nφ znak∙. V tomto p°φpad∞ je pou₧itφ algoritmu Perceptron ideßlnφ.
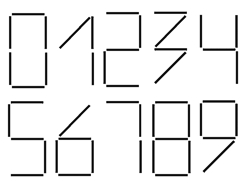 M∞°φtkov²
Perceptron
M∞°φtkov²
Perceptron
Pokud zkusφme pou₧φt Perceptron (urΦen² pro zpracovßnφ fixnφho pφsma) pro rozpoznßnφ
b∞₧nΘho tiÜt∞nΘho textu, pak asi sotva obdr₧φme obstojn² v²sledek. V dokumentu
mohou mφt znaky r∙znΘ rozm∞ry v pixelech, dokonce i kdy₧ majφ shodnΘ rozm∞ry
v milimetrech, proto₧e dokument m∙₧eme skenovat s r∙zn²m rozliÜenφm. Tato skuteΦnost
brßnφ v pou₧itφ "standardnφho" Perceptronu. Ale proto₧e p°edchozφ
algoritmus ve svΘ oblasti pracoval efektivn∞ a nic lepÜφho nebylo k dispozici,
byl nepatrn∞ vylepÜen a na sv∞t∞ se objevil m∞°φtkov² Perceptron.
Zßkladnφ rozdφl mezi nφm a jeho p°edch∙dcem je v tom, ₧e se p°epoΦφtßvajφ horizontßlnφ a vertikßlnφ m∞°φtkovΘ koeficienty podle rozm∞ru znaku. To znamenß, ₧e pokud je znak x-krßt v∞tÜφ ne₧ etalon, zv∞tÜφme na tento rozm∞r sφ¥ senzor∙, pokud je znak menÜφ, p°φsluÜn∞ sφ¥ senzor∙ stlaΦφme. Ve finßle zφskßme sφ¥ senzor∙, kterß se jakoby natahuje na znak nezßvisle na jeho rozm∞rech a ka₧d² senzor se nachßzφ v ekvivalentnφm bod∞ znaku. Takov² algoritmus ji₧ bude pom∞rn∞ spolehliv∞ fungovat p°i rozpoznßvßnφ textov²ch dokument∙.
Neuronovß sφ¥
DalÜφ v²voj tohoto algoritmu pokraΦoval v pokusech o rozpoznßvßnφ rukopisnΘho
textu. ObyΦejn² rukopisn² text se zatφm neda°φ p°eΦφst, vß₧nΘ problΘmy vznikajφ
dokonce p°i pokusu o rozd∞lenφ slova na znaky. Nap°φklad pφsmena "u"
a "i", napsanß souvisle v jednom slov∞, m∙₧e program interpretovat
jak jako "ui", tak i jako "iu". Proto se v²vojß°i vydali
cestou zjednoduÜenφ algoritmu, byly vytvo°eny specißlnφ formulß°e, ve kter²ch
se ka₧d² jednotliv² znak psal do jednoho polφΦka standardnφho rozm∞ru. Pak odpadl
problΘm rozd∞lenφ znak∙, ale z∙stal problΘm rozpoznßnφ znaku. M∞°φtkov² Perceptron,
kter² se tak dob°e hodil pro rozpoznßvßnφ tiÜt∞n²ch znak∙ pevn²m souborem pφsem,
se zde ukßzal jako bezmocn². Zßkladnφ problΘm spoΦφvß v tom, ₧e d°φve jsme rozpoznßvali
tiÜt∞nΘ texty, kdy se jeden a tent²₧ znak prakticky ·pln∞ shodoval se vÜemi
obdobn²mi znaky nanesen²mi jeden za druh²m, a mohli jsme rozmφstnit senzory
v r∙zn²ch oblastech znaku. P°i nastavenφ takovΘ sφt∞ se senzory objevujφ v₧dy
p°esn∞ na stejnΘm mφst∞ znaku a m∙₧eme posuzovat shodu znak∙ podle poΦtu shodujφcφch
se signßl∙ od senzor∙.
S ruΦn∞ psan²mi znaky je vÜe ·pln∞ jinak. Jejich linie nejsou ideßlnφ, mohou se lehce posouvat, tφm se odklßn∞t od senzoru odpovφdajφcφho za danou oblast a dostat se k senzoru sousednφmu. V₧dy vznikß problΘm s nep°esnostφ, kdy₧ m∙₧e linie ΦßsteΦn∞ prochßzet p°es senzor a on m∙₧e se stejnou pravd∞podobnostφ vydat signßl Pozadφ nebo Znak v danΘ oblasti. Tyto problΘmy se ΦßsteΦn∞ poda°ilo vy°eÜit pou₧itφm neuronov²ch sφtφ v roli senzor∙. Ty mohou vydßvat na v²stupu nikoliv pouze binßrnφ signßl, ale mφru pravd∞podobnosti, kterß zachycuje p°φtomnost Φßsti znaku v danΘ oblasti. Koeficient, kter²m se nßsobφ signßl po vstupu na senzor neuronovΘ sφt∞, je mo₧nΘ m∞nit a tφmto zp∙sobem p°izp∙sobovat sφ¥ k rozpoznßvßnφ znak∙, kterΘ se lehce liÜφ jeden od druhΘho. Pou₧itφm neuronovΘ sφt∞ se poda°ilo nauΦit program rozeznßvat tiskacφ znaky psanΘ rukou.
Typy dokument∙Univerzßlnφ dokument s blokovou strukturou OCR algoritmus m∙₧e analyzovat obraz, kter² se vztahuje k jednomu znaku, proto je p°edem pot°eba rozd∞lit textov² blok na °ßdky, °ßdky na slova a slova na jednotlivΘ znaky. V souvislosti s tφm, ₧e se znaky uprost°ed slova mohou Φasto vzßjemn∞ slepit, je lepÜφ pou₧φt r∙znΘ algoritmy pro rozd∞lenφ slov a pro rozd∞lenφ znak∙ ve slov∞. Potom ji₧ mßme vÜechny pot°ebnΘ informace pro rozpoznßvßnφ jednotliv²ch znak∙ - jsou to sou°adnice znak∙ a jejich hranice. |
Bez ohledu na urΦit² ·sp∞ch p°i pou₧itφ neuronovΘ sφt∞ z∙staly i problΘmy. P°i neustßlΘm zv∞tÜovßnφ mno₧stvφ znak∙, na kterΘ byla sφ¥ nauΦena, se zaΦφnß jejφ p°esnost po dosa₧enφ urΦitΘ hranice (okolo 98 % - podle kvality znak∙) zmenÜovat. Je to spojeno s nahromad∞nφm chybn²ch vzor∙. Znaky, na kter²ch se sφ¥ uΦφ, nejsou ideßlnφ, n∞kterΘ z nich nejsou napsßny dostateΦn∞ sprßvn∞. A program, kdy₧ se uΦφ na t∞chto chybn∞ napsan²ch znacφch, odbourßvß sprßvnΘ koeficienty a vytvß°φ mφsto nich novΘ. Pokud budeme program pom∞rn∞ dlouho uΦit, pak (v souvislosti s nahromad∞nφm chybn²ch symbol∙ v jeho znalostech) bude p°esnost rozpoznßvßnφ klesat.
VÜechny v²Üe uvedenΘ metody majφ jeden spoleΦn² nedostatek: pro dalÜφ anal²zu pou₧φvajφ jako zdroj zßkladnφ informace senzory. Tyto senzory jsou p°ipoutßny k urΦitΘ fixnφ oblasti. Ale proto₧e je senzor∙ mnohem mΘn∞ ne₧ pixel∙ v dokumentu, zφskßme hrubÜφ obraz o rozpoznßvanΘm objektu. Tφmto zp∙sobem se sna₧φme zmenÜit objem informacφ urΦen²ch k dalÜφmu zpracovßnφ a zjednoduÜit algoritmus, ale to d∞lß vnφmßnφ obrazu hrubÜφm, ne₧ je ve skuteΦnosti, a vede ke znaΦnΘmu zv²Üenφ pravd∞podobnosti vzniku chyby dokonce u t∞ch obrazc∙, kterΘ se bez zvlßÜtnφho ·silφ vizußln∞ lehce identifikujφ okem Φlov∞ka.
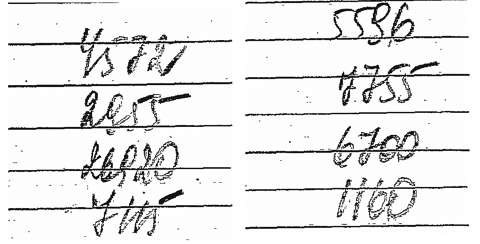
Vektorizace
Na vektorizaci m∙₧eme pohlφ₧et jako na urΦitou fßzi p°i transformovßnφ znak∙,
kterß pom∞rn∞ p°esn∞ zachycuje jejich podstatu bez v²znamnΘ ztrßty u₧iteΦnΘ
informace. Po vektorizaci znaΦn∞ zmenÜφme objem informacφ, kter² je pot°ebnΘ
dßle zpracovat. To zjednoduÜuje algoritmus a program m∙₧e fungovat podstatn∞
rychleji. Krom∞ toho po vektorizaci m∙₧eme vy°eÜit okam₧it∞ n∞kolik velmi slo₧it²ch
problΘm∙, jako nap°φklad urΦenφ m∞°φtka objektu, jeho ·hlovΘ parametry (nap°φklad
spoleΦn² ·hel naklon∞nφ znak∙). Mφsto hledßnφ znaku sφtφ senzor∙ po celΘm dokumentu
(co₧ zabφrß velmi mnoho Φasu) m∙₧eme najφt vÜechny spojenΘ skupiny vektor∙.
Jakmile mßme strukturovan² vektorov² model obrazce, kter² hledßme, m∙₧eme jej
pom∞rn∞ p°esn∞ porovnat. Nap°φklad pro Φφslici jedna bude vektorov² popis asi
nßsledujφcφ: prvnφ vektor svφrß s druh²m ·hel blφzk² 45░, prvnφ vektor je p°ibli₧n∞
dvakrßt v∞tÜφ ne₧ druh². A pro Φφslici sedm: prvnφ vektor svφrß s druh²m ·hel
blφzk² 90░, prvnφ vektor je p°ibli₧n∞ dvakrßt v∞tÜφ ne₧ druh².
ParametrickΘ metody
Obdobn∞ jako vektorizace existujφ metody, kterΘ zobrazenφ sice analyzujφ, ale
p°edem ho nezjednoduÜujφ. Pokud si b∞hem vektorizace sna₧φme p°edstavit obraz
jako strukturu linek a obrys∙, pak parametrickΘ metody naopak vyhledßvajφ jednotlivΘ
v²znamnΘ objekty. Jestli₧e urΦφme, ₧e aktußlnφ bod nßle₧φ k p°φmce, nedß nßm
to ₧ßdnou informaci. D∙le₧it∞jÜφ je v∞d∞t, kde se nachßzφ zaΦßtek a konec linky.
Tyto v²znamnΘ objekty mohou b²t konce linky, p°φmky nebo k°ivky, ale takΘ bod,
ve kterΘm linie ost°e m∞nφ sv∙j sm∞r, nebo bod - pr∙seΦφk liniφ, nebo t°eba
uzav°en² obrys. V takovΘm mimo°ßdn∞ abstraktnφm popisu m∙₧e vypadat nula jako
jeden uzav°en² obrys, osmiΦka jako dva spojenΘ uzav°enΘ obrysy. Takov² popis
m∙₧eme pou₧φt pro rozpoznßvßnφ text∙ natiÜt∞n²ch r∙zn²mi druhy pφsma, napsan²ch
r∙zn²mi lidmi a bude v₧dy fungovat na sto procent, samoz°ejm∞ pokud budou znaky
zobrazeny bez podstatn²ch chyb.
 Bez
ohledu na to, ₧e existujφ pom∞rn∞ p°esnΘ algoritmy pro rozpoznßvßnφ znak∙, mßme
programy, kterΘ umφ spolehliv∞ rozpoznat pouze typografickΘ dokumenty nebo texty
vytiÜt∞nΘ na tiskßrn∞. Zatφm si nem∙₧eme dovolit zapisovat v²sledky na papφru
a potom je rychle, bez zvlßÜtnφho ·silφ, zadat do poΦφtaΦe pro dalÜφ zpracovßnφ.
Bez ohledu na pokusy, se kter²mi se setkßvßme u souΦasn²ch PDA poΦφtaΦ∙, pro
nßs zatφm z∙stane klßvesnice jedin²m rozhranφm do digitßlnφho sv∞ta. VÜe proto,
₧e reßlnΘ obrazce, kterΘ vytvß°φme, se podstatn∞ liÜφ od t∞ch laboratornφch,
na kter²ch se testujφ OCR programy.
Bez
ohledu na to, ₧e existujφ pom∞rn∞ p°esnΘ algoritmy pro rozpoznßvßnφ znak∙, mßme
programy, kterΘ umφ spolehliv∞ rozpoznat pouze typografickΘ dokumenty nebo texty
vytiÜt∞nΘ na tiskßrn∞. Zatφm si nem∙₧eme dovolit zapisovat v²sledky na papφru
a potom je rychle, bez zvlßÜtnφho ·silφ, zadat do poΦφtaΦe pro dalÜφ zpracovßnφ.
Bez ohledu na pokusy, se kter²mi se setkßvßme u souΦasn²ch PDA poΦφtaΦ∙, pro
nßs zatφm z∙stane klßvesnice jedin²m rozhranφm do digitßlnφho sv∞ta. VÜe proto,
₧e reßlnΘ obrazce, kterΘ vytvß°φme, se podstatn∞ liÜφ od t∞ch laboratornφch,
na kter²ch se testujφ OCR programy.
ReßlnΘ obrazce, kterΘ vytvß°φme, obsahujφ velkΘ mno₧stvφ Üumu a je nemo₧nΘ vzφt v ·vahu vÜechny varianty jeho potlaΦenφ. NßhodnΘ skvrny, ka≥ky, teΦky, rozpφjejφcφ se linie, nßhodnΘ Φmßrance, Ükrtance a opravy, p°ekr²vßnφ jednotliv²ch obrazc∙, razφtka a tisky a ΦßsteΦnß ztrßta informacφ na faxech; ohromnΘ mno₧stvφ obrazc∙, r∙znΘ jazyky, podmφneΦnß oznaΦenφ, r∙znΘ druhy pφsma - vÜechny tyto okolnosti dnes znemo₧≥ujφ univerzßlnφ °eÜenφ problΘmu rozpoznßvßnφ textu. Pro °eÜenφ tohoto problΘmu budou zapot°ebφ jeÜt∞ v²konn∞jÜφ poΦφtaΦe a ohromnΘ bloky pam∞ti.
Grigorij LukaÜenko
 |