![[*]](/file/19864/ftp.cs.arizona.edu.tar/ftp.cs.arizona.edu/tsql/doc/bmT123.tex/crossref.png) .
.
The selection component is divided into two parts, one for valid-time
selection and one for selection not involving valid time. See
Figure .
Both parts are based on the same observation. In general, a selection
predicate is built from atomic selection predicates using logical
operators (e.g., and, or, and implies) and
parenthesis. Both parts categorize queries based on the atomic
predicates used in the queries. As several types of atomic predicates
may be used in the same query, queries generally fall into multiple
categories (as indicated in Figure by the Kleene star,
`` * ''). We examine each part of the selection-based taxonomy
in turn.
Atomic valid-time selection predicates are assumed to be of the form
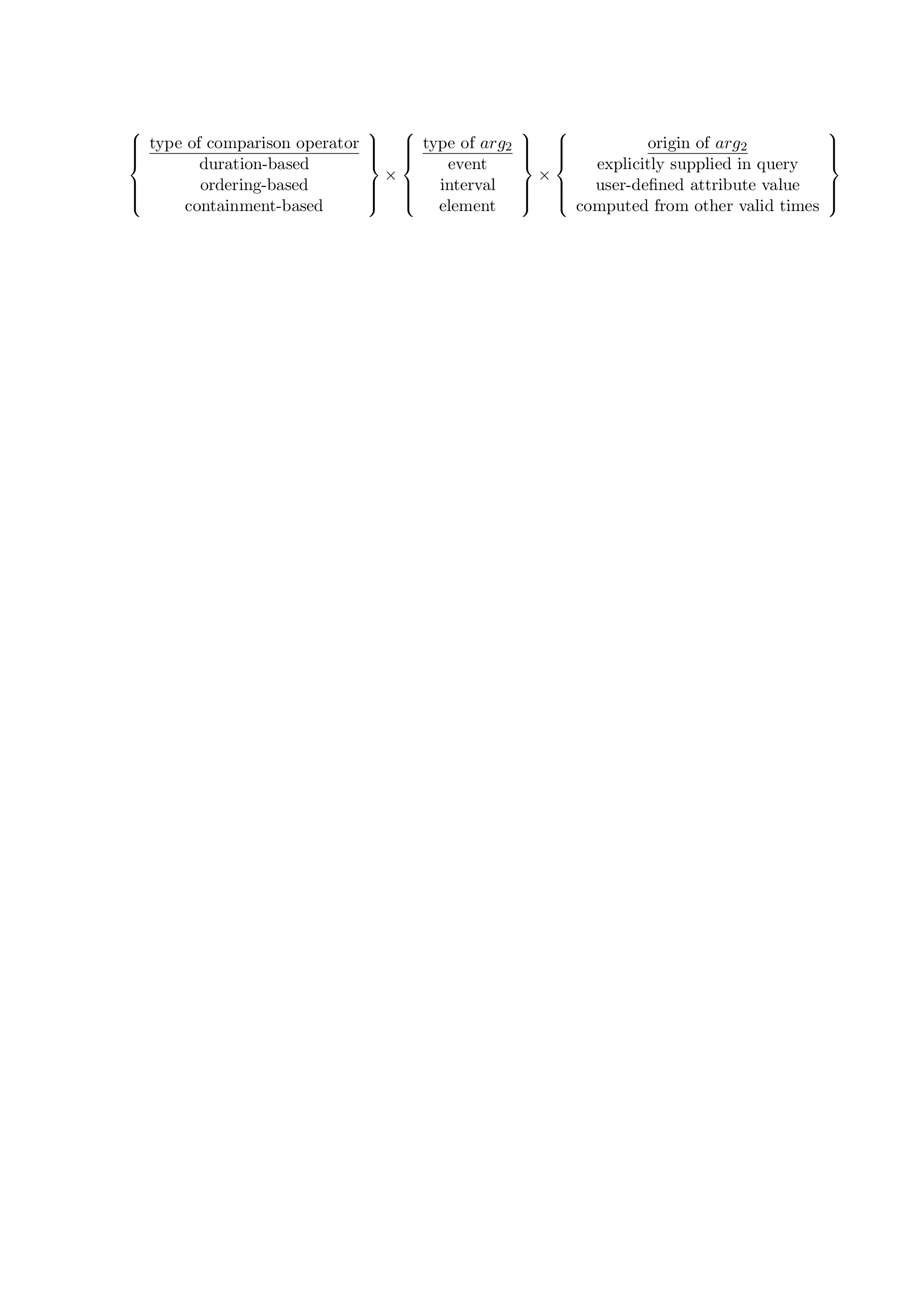
outlines the categories.
Three types of comparison operators are identified. First, a comparison operator may be duration-based. For example the operator spanExceeds returns true if the duration of the first argument is equal to or larger than the duration of the second argument. Second, comparison operators may be based on ordering. Operators in this category include precedes and meets. The first applies to all timestamps and evalutes to true if the largest time in the first argument is smaller than the smallest times in the second argument. Operator meets appears to be useful only for events and intervals. Two timestamps meet if they are not separated by any event (i.e., may be coalesced). Operators based on containment include = (identity), overlaps, and contains.
The second argument (arg2) may be an event, an interval, or an element. Also, it may come from three sources. First, it may be supplied directly in the query, as a constant. Second, it may be the value of a user-defined time attribute in an argument tuple. Note that this is only possible for events if first normal form is required. Third, like the first argument, the second argument may be computed from valid times in the argument tuples.
If the three types of categories are completely orthogonal, this part of the taxonomy will contribute with a total of 27 categories. However, it may be debated whether intervals and elements may be used as values of user-defined attributes (resulting in non-1NF relations).
The final part of the selection-based taxonomy categorizes queries based solely on the part of the selection component that involves only ordinary, non-temporal selection.
Many possibilities for categorization exist. Below, in
Figure , we distinguish between four significant types
of atomic selection predicates. First, an attribute may be compared
with a constant, supplied by the user. Second, attribute values, both
in the same relation, may be compared. Third, a primary key value may
be compared with a matching foreign key value. Fourth, arbitrary
attributes of possibly distinct relations may be compared. In the
figure,
θ : : = < | > |≤|≥| = , i.e., a
combination of equality and/or the one of the two inequality
operators. If we distinguish between situations where only equality is
involved and situations where inequality is involved, this give 8
categories.