

|
|
|
|
Our sponsors make financial contributions toward the costs of publishing Linux Gazette. If you would like to become a sponsor of LG, e-mail us at sponsor@ssc.com.
Linux Gazette is a non-commercial, freely available publication and will remain that way. Show your support by using the products of our sponsors and publisher.
The Whole Damn Thing 1 (text)
The Whole Damn Thing 2 (HTML)
are files containing the entire issue: one in text format, one in HTML.
They are provided
strictly as a way to save the contents as one file for later printing in
the format of your choice;
there is no guarantee of working links in the HTML version.
Got any great ideas for improvements? Send your comments, criticisms, suggestions and ideas.
This page written and maintained by the Editor of Linux Gazette, gazette@ssc.com
Write the Gazette at gazette@ssc.com
|
Contents: |
 Date: Sat, 1 Aug 1998 09:50:38 -0500
Date: Sat, 1 Aug 1998 09:50:38 -0500
From: The Wonus House,
wonus@w-link.net
Subject: Accessing Microsoft SqlServer vi DB-lib or CT-lib
Do you have additional information sources on connecting to MS SqlServer via the Sybase CT/DB libraries? I am most interseted in how this could be done from a Solaris client machine.
Any info is greatly appreciated (thanks), Kevin Wonus
Date: Sun, 2 Aug 1998 21:55:03 -0400 (EDT)
From: Paul 'Tok' Kiela,
tok@gemini.physics.mcmaster.ca
Subject: R2000 Mips 2030
I just recently came into a used R2000 "Mips 2030" desktop slab. Aside from opening the box and finding that it is indeed running an R2000 CPU, I know nothing else about the computer -- literally. I have found absolutely zero information about any computer bearing the markings 'MIPS 2030'. To make matters worse, I don't have a proper BNC monitor to actually use the box yet, but I'm searching. My question, where can I find information about the R2000 port of Linux? I have visited the Linux/MIPS page, but the only mention of the R2000/3000 CPU port is an URL which points at SGI's statistics on the R3000 CPU. I was hoping I could pop Linux on on the box, and happily run it alongside the little army of Linux boxen I have now. Any help would be very appreciated.
Thanks.
Paul.
Date: Thu, 06 Aug 1998 12:57:21 +0000
From: Gulf Resources Co,
grc2000@kuwait.net
Subject: Some Ideas
Anyone there who is dreaming of running Delphi in Linux?
Date: Wed, 12 Aug 1998 09:21:12 +0200
From: Jesus A. Muqoz,
jesus.munozh@mad.sener.es
Subject: LILO Problems
I installed Linux in a secondary IDE hard disk booting from a floppy disk. Then I tried to install LILO in the MBR of the primary IDE hard disk and I did it. My idea was to maintain Windows 95 in the primary disk. I configured LILO to be able to start Windows 95, but after installing LILO the primary disk cannot be seen either by DOS nor by Linux. If I run msdos-fdisk it says that the disk is active but in the row where it should appear FAT16 puts unknown or something like that. Can I recover the information of the hard disk ?
Date: Tue, 11 Aug 1998 09:17:54 +0300
From: Mehmet Mersinligil,
memo@tr-net.net.tr
Subject: Matrox Productiva G100 8M AGP !!???
Is there a way to configure my Matrox Productiva G100 8MB AGP under X? Except buying a a new accelerated X server for 125$ from http://www.xig.com ? What should I do?
Date: Sat, 08 Aug 1998 18:21:54 +0000
From: Alexander I. Butenko,
alexb@megastyle.com
Subject: Some questions to be published
1. I wonder can I use the EPSON Stylus Color 400 printer with Linux... The interesting thing is that my buggy GIMP beta says to be supporting it but can't really print anything....
2. Has anybody encountered such a bug? JavaICQ doesn't run properly under KDE (when I open the send or reply or even preferences window this window closes immediately). This problem is only under KDE... 3. I can't use this Real Player 5.0, because it reports the compression errors even with files obtained from www.real.com or that file that was installed with it on my hard drive...
Date: Thu, 06 Aug 1998 15:33:37 -0400
From: Bob Brinkmann,
Bob.Brinkmann@mindspring.com
Subject: Being new to the Linux community
I'm in the process of developing a secure, encrypted tunnel for access to my company's enterprise network. The clients on the outside dialing into the system will be of a Windows 95, 98, NT 4.0 and probably 5.0 when it decides to rear its ugly head. My question is this, are there solutions on the terminating server side written in Linux to handle clients' tunnel access and also provide for IPSEC level encryption?
A while back I played with Red Hat's 2.0 release of the software and I just purchased Red Hat's 5.1 (Manhattan) version utilizing 2.0.34 kernel and find it to run quite nicely on both a desktop and several Toshiba portables.
Thanks for any advice or information you can provide.
Bob Brinkmann
Date: Wed, 12 Aug 1998 13:07:22 -0500
From: Dennis Lambert,
opk@worldnet.att.net
Subject: Help Wanted : newbie
I recently purchased Red Hat 5.1 and got it running. Evidently I was lucky in that I have a fairly full FAT 32 Win 98 drive and kind of stumbled through the defrag / fips / boot to CD / repartition / full install with LILO process. Everything worked, but I'm a little nonplussed. A few topics I'd absolutely love to get feedback on...
I don't really expect anyone to answer all of these concerns, but any little help would be greatly appreciated.
Dennis Lambert
Date: Mon, 17 Aug 1998 16:54:20 +0100
From:
Fabrice_NORKA_-_SAPHIR@PECHINEY.COM
Subject: Deb to RPM translator
I changed from a Debian distribution to a Red Hat 5.0 lately and was wandering if there were a tool like 'alien' to convert Debian packages to Red Hat packages. My personal e-mail is NORKAF@AOL.com
Thank you and God save Linux community :-)
Date: Mon, 17 Aug 1998 13:18:31 -0400
From: Chris Bruner,
cbruner@compulife.com
Subject: Idea's for improvments and articals
An idea for an article. (You may have already done this but I couldn't find a search engine to look up past articles). I have yet to get my Red Hat 5.1 to connect to the Internet. (Their support is GREATLY overstated.) I'm consquently using Win95 to do my Internet work. The reason for this is that my modem, network adapter and sound card are all Plug and Play (PnP). I would like to see an article detailing step by step, for a Linux beginner, how to install Tom Lee's PnP Package. This would involve recompiling the kernel which I'm not afraid of, but have no idea how to go about it. The more step by step the better. I'm from the DOS world and any assumed knowledge that I have might be wrong.
Thanks for a great magazine.
Chris Bruner
Date: Tue, 18 Aug 1998 21:23:27 +1200
From: Andrew Gates,
andrewga@fcf.co.nz
Subject: Help wanted for a (Cheap) COBOL combiler for Linux
I have a friend who is doing a refresher course in Cobol in a Unix environment. I have suggested that she run Linux, and pick up a cheap / shareware copy of a Cobol compiler for Linux from somewhere. Knowing absolutely nothing about either Linux or Cobol, am I dreaming, or is there a realistic alternative to the compilers I have seen retailing for ~$1,500 US? I'd really appreciate any help/advice anyone can offer.
Andrew Gates
Date: Wed, 19 Aug 1998 18:37:34 +0200
From: ppali@friko6.onet.pl
Subject: RadioAktiv radio tuner
I am one of those Linux users, who are not experts, even after a year or more of working with the OS. I like very much discovering by myself various aspects of Linux, trying out the many programs and help tips. What is important is that it works well and that I can use it for most of the common computer tasks (after a bit of tinkering). Now I have decided for the first time to post a following question:
After trying many radio tuners available on the net and failing to make my RadioAktiv radio card work under Linux I am stuck. Maybe someone would give me a few tips (or one TIP)?
Date: Tue, 25 Aug 1998 15:59:21 -0500
From: Hilton, Bradley D. (Brad),
HiltonBD@bv.com
Subject: Trident 985 AGP
Is it possible to get X running on a Trident 985 AGP video card? What server would I use? Thanks,
Brad Hilton
Date: Mon, 24 Aug 1998 17:19:21 -0700
From: dk smith, dks@MediaWeb.com
Subject: IDE disks
If I could only find a definitive reference on setting up IDE disks, SCSI disks, and partitioning issue for running with Linux, NT, and LILO. I am new to this stuff. The docs at Red Hat, although extensive, were not enough for me.
-dk
Date: Thu, 27 Aug 1998 16:05:15 +1200
From: Mark Inder,
mark@tts.co.nz
Subject: Help Wanted: Looking for an Xwin Server software that runs
under win95/nt
We use a Red Hat 4.2 machine in our office as a communications server. This is running well with the facility of telnet connections for maintenance, diald for PPP dial up - internet and email, and uucp for incoming mail.
I would like to run an X server on my windows PC to be able to use X client software on the Linux PC over the local Ethernet. Does anyone know of a shareware for freeware version which is available.
TIA Mark
Date: Thu, 27 Aug 1998 00:02:28 -0500
From: Todd Thalken,
tdthalk@megavision.com
Subject: Looking Into Linux For PPP Server
I am interested in implementing Linux in our office network.
Specifically, we would like to set up a Linux box as a dial-up PPP server so that remote users can access the office intranet.
Could you explain what hardware (multiport controllers) works best with Linux, and explain the steps necessary to set the Linux box up as a PPP server. Most of our client computers will be using Windows 95/98 dial-up networking. We would like to have the server assign IP addresses dynamically.
This seems like it would be a relatively common question, so if there is already good information available please let me know where I can find it.
I have read a lot about Linux, but still consider myself a green "newbie".
Date: Sun, 02 Aug 1998 18:25:16 +0000
From: Gulf Resources Co,
grc2000@kuwait.net
Subject: Delphi for Linux
I am a Delphi Developer. I am also a big fan of Linux and GNU Softwares.
Anybody there who wants to join me in knocking the doors of Inprise Corp (Borland ) to convince them to port C++ Builder and Delphi to X Window.
If these things happen, Microsoft will be very upset.
What Linux needs is an innovative company like Borland or Symantec.
Date: Mon, 03 Aug 1998 02:16:54 +0100 (BST)
From: Hugo Rabson,
hugo@rabson.force9.co.uk
Subject: response to Ruth Milne
I tell you, .....
Are you familiar with Nietzsche's description of the ordinary man's journey from man to superman? ...how he "goes down" into the abyss and comes up the other side? Moving from Windows to Linux is a bit like that. ;)
My adventure started in late April. I was sick and tired of Windows NT bluescreening. I read an article saying how stable Linux was in comparison. I looked into GUIs & found KDE to be to my liking.
In the end, I vaped NT because I needed the hard disk space. ;-P
It is now August. I have had ro reinstall almost a dozen times because I am still getting used to "The Linux Way". I have been using computers since i was 6; PCs since I was 16; Windows since I was 18. Linux is very stable indeed but it is eccentric & definitely not user-friendly, unless your definition of user differs wildly from mine.
I have written a "HOWTO" so that I can recover quickly if I have to reinstall the entire OS and GUI. It is currently 3500 words long, and tells me how to install RedHat, compile a new kernel, compile&install KDE 1.0, install the BackUPS software, configure dial-up networking & autodial, install AutoRPM, and .. umm... that's it, so far.
Don't get me wrong: Linux _is_ a wonderful thing. It's just ... It's _such_ a leap from Windows! I am convinced my primary client (with a dozen Windows machines) could function very well with Linux & Applixware instead of Windows & Office, just so long as they have someone competent to maintain their systems. Of course, they'll need much less maintenance under Linux than under Windows ;)
Linux requires a lot of competence & intelligence (and downloads!) if you're going to set it up. Windows doesn't. On the other hand, it seems much less prone to these embarrassing GPFs. :)
Hugo Rabson
Date: Thu, 6 Aug 1998 13:01:42 +0200 (CEST)
From: Hugo van der Kooij,
hvdkooij@caiw.nl
Subject: Linux Gazette should not use abusive language!
This is my final note to you about this subject. I have not heard nor seen a single response in the past regarding this issue.
I will however request mirror sites to stop mirroring unless you remove your abusive language from the Linux Gazette.
The following text should be removed from ALL issue's:
The Whole Damn Thing 1 (text) The Whole Damn Thing 2 (HTML)
I presume I am not the only person that find this text not at all suited for a Linux publication. It is in effect offensive and could easily be removed
Hugo van der Kooij
Actually, I have answered you at least twice about this issue. I don't find the word Damn either abusive or offensive and have had no objections from anyone else. So, why don't we put it to a vote? Okay, you guys out there, let me know your feelings about this. Should I remove the "Damn" from "The Whole Damn Thing" or not? I will abide by the majority. --Editor)
Date: Sun, 09 Aug 1998 15:48:34 -0600
From: Mark Bolzern,
Mark@LinuxMall.com
Subject: Some History and Other Things LG #31
http://www.linuxgazette.com/issue31/richardson.html
Marjorie,
Neat issue of the Gazette, thanks for all the hard work. I'm proud to be a sponsor, Just sent another $1K.
One little teensie issue of fact though:
First the quote: The first two issues of Linux Journal were published by Robert Young. After the second issue, Robert decided to start up Red Hat Software, and Specialized Systems Consultants took over as publisher. Also with the third issue, Michael Johnson took on the role of Editor and continued in that role through the September 1996 issue. I became Editor on February 1, 1997 and began work on the May issue.
And the correction: Actually Bob (Robert) started a Linux catalog within the ACC Bookstores. It wasn't until quite a bit later when he met Marc Ewing that he folded ACC into Marc's Red Hat Software.
I wuz there ;->
Thanks
Mark
Date: Sat, 8 Aug 1998 15:06:37 -0700 (PDT)
From: Heather Stern,
star@starshine.org
Subject: Re: those crazy links
On http://www.linuxgazette.com/issue31/tag_95slow.html, the link pointing back to the table of contents points to lg_toc30.html instead of lg_toc31.html. No, wait... all of the issue 31 answer guy pages seem to be mislinked (except the main one.) Also, the "previous section" button on the pages mentioned above seem to be mislinked as well... This isn't really important since most normal people like me use the back button like a religion, but it always helps to be consistent and have links pointing where they should, doesn't it? :)Yes, actually, it *is* important to me, and the base files are mostly generated by a script (making it hard to get wrong). But, I broke some stuff in the footer logic, so I did a proper footer by hand and propoagted it into the tag_ files myself. So, as I go look at the template I used...
Dad-blammit, you're right!! All of the 30's in there should be 31's. (Although the copyright notice is correct.) Mea culpa!
Thanks for your time... --Charles Ulrich. p.s. May be worth the effort to try one of those link checker bots that seem ever so popular on the web these days...Maybe, but it's being worked on in a private Linux network. Most of those "web bots" only access external sites properly.
I should have run the command 'lynx -traversal' at the top of it, so I'd have a badlink report, but I was in a last-minute rush. I've done so now, and found another error that you missed.
One of the beautiful things about the web, is that a minor misprint can actually be undone, unlike the world of print. I've submitted a corrected packet to our editor. Thanks for mentioning it.
-*- Heather Stern -*-
Date: Fri, 7 Aug 1998 11:13:47 +0000
From: kengu@credo.ie
Subject: news from Irish LUG
Hello, I'm involved with the Irish Linux Users Group website and was wondering if you would please mention that we are currently compiling a list of people in Ireland that would be interested in getting the 'Linux Journal' - details are available at our website http://www.linux.ie/.
thanks
Ken Guest
Date: Thu, 06 Aug 1998 17:30:55 +0100
From: James Mitchell,
james-t.mitchell@sbil.co.uk
Subject: Re: The other side of the story (or, on the other, other
hand)
Just before I launch into the meat of this email, I'd like to say that the Linux Gazette is excellent. good articles, and good tips and comments.
I'm writing about the mail in the August issue "The Other Side of the Story", in which Antony Chesser compares the Windows GUI to the shell prompt, especially the line
"When Linux finishes installing, you're left with a # prompt. When WIN95 finishes installing, you've a fairly intuitive GUI that allows you to quickly and easily install and run programs, connect to the net, and **apply updates without re-compiling the kernel**"
My quibble is with the underlying assumption that a GUI (and here I assume that includes Mac, and X, as well as Windows) is more intuitive then a command line. I argue that for a complete novice one is as bad as the other, neither a command line nor a screen full of little coloured icons and a START button are instantly comprehensible to a complete computer novice.
(Before you write me off as insane - remember that a GUI is supposed to shorten the time it takes to learn how to operate the computer, they don't eliminate the time altogether.)
Do you remember the scene in the Star Trek movie (the one with the whales...) where Scotty tries to use a Mac? He talks to it, and nothing happens... the operator says "You need to use this [the mouse]", so Scotty picks up the mouse and uses it like a microphone - "Good morning computer."
Can you see where I'm going? Until someone teaches the "complete novice" the relationship between the pointer and the mouse, and what happens when you click, double-click, or drag with the mouse, they will be just as lost as a novice sitting in front of a command line. Actually, they may be worse off... we have had typewriters for a lot longer then mice, and people will grasp the concept of typing faster then clicking on pictures.
So, in summary, I think that a complete novice will have a learning curve to cope with whether they use a GUI, or a command line; and the rest of us should remember that there is a difference between "ease of use", and "what I'm used to".
Cheers,
James
Date: Thu, 06 Aug 1998 09:22:46 EDT
From: Roger Dingledine, arma@seul.org
Subject: Linux News Standardization/Distribution Project
We've been making progress on our proposal to standardize the format and distribution of Linux news. Our design uses the NNTP protocol to create a network of servers that will quickly and robustly share news that is interesting to the Linux community. This will allow websites like Freshmeat and Slashdot, as well as lists like Threepoint's and linux-announce, to reduce duplication of effort while still customizing their presentation. In addition, this will provide a single easy method of submitting an item of news, whether it's an announcement about a new software release, or a description of the latest article in Forbes magazine.
The end goal of organizing the Linux announcements and news articles is to encourage smaller ISVs to port to Linux, since they will see advertising their software to a wide audience as less of an obstacle. Other important benefits include greater robustness (from multiple news servers), less work for the moderators (messages will be presorted and people can specialize in their favorite type of news, resulting in faster throughput), and a uniform comprehensive archiving system allowing people to search old articles more effectively.
We are currently at the point where we are designing the standard format for a news item. We want to make it rich enough that it provides all the information that each site wants, but simple enough that we can require submissions to include all fields. At the same time we're sorting out how the NNTP-based connections between the servers should work. We've got Freshmeat and Threepoint in on it, and other groups like Debian and LinuxMall are interested. We need more news sites to provide input and feedback, to make sure everybody will want to use the system once it's ready.
If you're interested, please check out our webpage at http://linuxunited.org/projects/news/ and subscribe to the mailing list (send mail to majordomo@linuxunited.org with body 'subscribe lu-news').
Thanks for your time (this is the last mail I will send directly about this),
Roger (SEUL sysarch)
Date: Fri, 14 Aug 1998 23:49:36 +0200
From: Martin Møller,
martin_moeller@technologist.com
Subject: Linux Gazette to be featured on Alt Om Data's CD-ROM
monthly.
This is just to inform you that some of our readers have pointed out that we ought to distribute your magazine on our Cover CD, and after having read through the lisence, I believe this will be no problem. I have, just to be safe, saved a copy of the copy lisence together with the archives and plan on distributing the new issues as the show up.
Keep up the good work!
Martin Moeller.
Date: Fri, 21 Aug 1998 20:52:14 -0400 (EDT)
From: Timothy D. Gray,
timgray@lambdanet.com
Subject: Linux reality letter
In LG#31 Michael Rasmusson wrote: "the majority of Linux users are IT professionals in some way" and alluded to the fact that Linux will be slow to be accepted due to this fact. This is very untrue. Most Linux users are in fact College and high school students. These forward thinking young minds aren't tied down by archaic IT department policy (many of which were penned in the 70's when IT was called the Processing/programming/systems/data-processing department) Linux will explode, it will do so violently. In fact it will explode so fast and vast that Microsoft will say "What happened?" The local Linux Users groups are all populated by 90% college and high school students. What do you think will happen when these students hit the computer departments at large corporations? They will install Linux, they will use Linux, and they will recommend Linux. The "explosion" has already started. Many large companies have already abandoned NOVELL and Microsoft for their servers. (The makers of the CG effects in the movie Titanic are far from small)
Date: Wed, 26 Aug 1998 03:37:22 -0400 (EDT)
From: Paul Anderson,
paul@geeky1.ebtech.net
Subject: Linux and new users
I've been reading the LG mailbag... A lot of people think Linux should be made easier to use. I don't think that's quite right - the idea, IMHO, should be to make it so that Linux can be used by someone who's new to computers, BUT they should have to learn to use it's full power. With power, knowledge must come or disaster will follow instead. The goal, in the end, is that the person becomes a self-sufficient user, capable of sorting out most difficulties without needing help. TTYL!
Paul Anderson
![[ TABLE OF
CONTENTS ]](/file/35578/CDROM27.iso/linux/lg/gx/indexnew.gif)
![[ FRONT
PAGE ]](/file/35578/CDROM27.iso/linux/lg/gx/homenew.gif)
 More 2¢ Tips!
More 2¢ Tips!
 2 Cent Tip from the 'Muse
2 Cent Tip from the 'Muse
You know, I don't think anyones mentioned it before in the Gazette, but there is this little program that is handy as all get out: units. You give it the units you have and specify what you want it converted to and Viola! It converts it for you! It won't do Celsius/Farenheit conversions, but handles Grams/Pounds conversions just fine. And for all those Linux cooks out there, it converts cups to quarts, teaspoons to tablespoons and cups to tablespoons.
Its the units freaks Swiss Army Knife. No hacker forced to make his own Thai curries should be without it.
Michael J. Hammel
Tips and Tricks: Keeping track of your config files
This is my trick for keeping track of the many config files you find on a Linux/Unix system.
Most config files are in the /etc directory. However, particularly on a home machine you won't change them all and sometimes you want to save (e.g. on a floppy) only the files you have changed. Besides, you don't want to have to remember the exact location for every one.
So here's what I do:
Then every time I want to change something I go directly to /root/config. If I want to backup my system configuration, I just copy the files by dereferencing the symlinks, etc. ...
Cheers,
Ryurick M. Hristev
2 cent tip: Cross platform text conversion.
To convert to a DOS text file, mount a DOS floppy and copy the text file.
$ su (you are prompted for a password) # mount /dev/fd0 -t msdos /mnt/floppy (the # says that you are root BE CAREFUL!) # cp myfile.tex /mnt/floppy # exit $For instance, after these, I can use SAMBA to get myfile.tex to an NT network printer (Z:> copy \\mymachinename\mnt\floppy\myfile.tex lpt2). It makes sense if you do this often to have a DOS disk always mounted, but if you mount as above, remember to umount before you try, say, mounting a different floppy.
I find this easier than a solution with the tr command, because I always forget how to do such solutions, but I can remember how to copy.
Jim Hefferon
XFree86 and the S3ViRGE GX2 chipset
At work, we just got in a whole slew of computers that use the S3ViRGE GX2 chipset. Upon trying to install X on these things, I found that the default Red Hat 5.0 XFree doesn't cut it. This is how I've been able to fix the XFree86 problems with the S3V GX/2 chipset. First, do not use the S3V server despite what Xconfigurator says. The GX/2 chipset is not supported for that server. You must use the SVGA server (besides, it's accelerated and supports DPMS). Currently, these are the modes supported as of XFree86-3.3.2pl3:
8bpp:
640x480 works
800x600 works
1024x768 works
1280x1024 works
15/16bpp:
640x480 works
800x600 works
1024x768 works
1280x1024 works
24 bpp:
640x480 works
800x600 works
1024x768 works
1280x1024 works (very picky about monitor modelines though)
32 bpp:
640x480 works
800x600 works
1024x768 does not work
1280x1024 does not work
The card I'm using to test this is a #9 9FX Reality 334 w/8MB RAM. Also
I cannot verify that this works on any version less than
XFree86-3.3.2pl2. pl2 actually has less modes/depth combinations that
work - such as, no 16 bit depths work and 1280x1024 doesn't work in
almost all depths. I suggest upgrading to XFre86-3.3.2pl3. Now onto the
fix.
Step 1. Make sure you're using the SVGA server (ls -l /etc/X11/X for RH users, maybe the same on other distros). It should point to /usr/X11R6/bin/XF86_SVGA. If it's not, link it to it (ln -sf /usr/X11R6/bin/XF86_SVGA /etc/X11/X).
Step 2. Open your /etc/X11/XF86Config file for editing.
Step 3. Find the Graphics Device Section.
Step 4. Find the device that is the Standard VGA Device (usually has the line -
Identifier "Generic VGA"Step 5. Remove the line that says:
Chipset "generic"Step 6. Uncomment the line that says:
VideoRam "256"and change it to recognize the amount of RAM your card has in kilo
VideoRam "8192" # 8MB RAMStep 7. Add the following line (*CRUCIAL*):
Option "xaa_no_color_exp"This turns off one of the accelerated option that gives trouble.
Step 8. Add whatever other options you want (for a list see the man pages on XF86Config, XF86_SVGA, and XF86_S3V)
Step 9. Change the bit depth and resolution to whatever you want.
Step 10. Save and close the file and (re)start X.
Note: I do not claim this will work for all cards using the GX2 chipset. I can only verify for the video card I'm using. I'm interested to hear how other video cards handle it. Hope that helps everyone involved. I've heard from people on Usenet that it works perfectly, and from others it doesn't.
Ti Leggett
Clearing the Screen
A few days ago a classmate "accidentally" cat'ed a file to the screen. He asked asked me what he could do to reset his confused vt100, as "clear" wasn't sufficient.
At first I figured he would need to close and re-open the connection, but then I realized that there are codes to reset a vt100.
Here is some C code that resets, and clears the screen. Save it as vt.C, then run "make vt". Place the executable in your path, and when the screen looks like heiroglyphics, type (blindly at this point) "vt". That should clear it up.
/*
** Small program to reset a confused vt100 after
** `cat'ing a binary file.
*/
#include <stdio.h>
int main(void)
{
printf("\033c"); // reset terminal
printf("\033[2J"); // clear screeen
return(0);
}
/*
For more info, see the following URLs:
www.mhri.edu.au/~pdb/dataformats/vt100.html
www.sdsu.edu/doc/texi/screen_10.html
www.cs.utk.edu/~shuford/terminal/ansi_x3.64.html
They have more vt100 escape codes.
**
*/
Re: Shell Scripting Resources <-- TIP
In issue 31 it was mentioned that someone had been looking for some shell scripting help.
Take a look at http://www.oase-shareware.org/shell/ as I have heard many people mention this site in response to shell scripting queries.
Sean.
Re: Recognising the AMD K5-PR166
I'm wondering whether any other readers have used the AMD K5-PR166 with Linux. It's just that my system seems to think it's a K5-PR133 and states that it's running at 100MHz. Also, the BogoMips value indicates that the processor is running at 100MHz. Anyone any advice?I'm running a K5 P133+ on one of my systems - it actually is running at 100 MHz, that's why it's a "P133+". It's like the Cyrix processors, the name is basically a lie for marketing.
I wouldn't put too much stock in the BogoMips value - it is bogus after all! My system clocks in at an equivalent to a 112 MHz system when I run the distributed.net client - the reason AMD claims a higher clock value is probably because some instructions run faster, and those may just not happen to be the instructions used in to BogoMips loop.
As for your system thinking your K5-PR166 is a K5-PR133, it's probably because you have the motherboard jumpered wrong and/or the BIOS configured wrong. Are you sure that your motherboard & BIOS support the chip?
Shani
Your atapi CDROM
Your /dev directory is the culprit. Current installs use:
/dev/hda /dev/hdb /dev/hdc /dev/hdd (/dev/hde) (/dev/hdf)for the first, second, (and third) ide interfaces, m,s,m,s(,m,s). Older installs had the /dev directory written a little differently. You would have the old standard, which was
/dev/hdnxwhere n was interface, and x was a/b for master/slave.
The only difference is in the names of the files. If you rename them, you will be in compliance. Alternatively, you could run makedev from a recent kernel, though I do not pretend to know all the details of that.
Tips: simulataneous kernel versions
From: Renato Weiner, reweiner@yahoo.comThis may come a bit late, but I am in the process of writing a (mini)HOWTO on this subject. It is not quite trivial, especially with modules lying around, or if you want several kernels with the same version number.
Recently I was looking at the Gazette and I think I have a good suggestion of an article that will be very useful for the Linux community. I have had some technical difficulties of having two simultaneous versions of Kernels in my system. I mean a stable one and a developing one. I searched the net looking for information of how to co-exist both but it's completely fragmented. If somebody more experienced could put all this information together, it will certainly help a lot of people from kernels developers to end-users.
Check out http://huizen.dds.nl/~frodol/howto.html for now. I am still in the process of getting it approved as an official mini-HOWTO.
Frodo
Creating man pages made easy!!!
Below is something I wrote to help lay people create their own man pages easily
---------------------------------------------------------------------------- ----
If you ever wrote a program using gcc in linux, you may have come across this problem. You have just finished your wonderful little program which is of great use to you and you need a man page for it.
Of course, you have absolutely no idea how to write a man page. Don't you need to know how to use troff? Or is it nroff to write a man page? Luckily there is a much easier way to write a man page.
Here I shall describe an easy and quick (and dirty) way of writing a man page without learning troff or nroff. In order to do so, you must have the Perl version 5.004 (or higher) installed on your Linux box.
There is a man page in the various Perl man pages on the creation of a man page using the Perl util "pod2man". It is called "perlpod.1". Below is a step by step guide to finding the man page and the util.
ksiew> su password: #|/root>locate perlpod.1 /usr/man/man1/perlpod.1 #|/root>locate pod2man /usr/bin/pod2manNow, to write your own man pages, you must first read the perlpod.1 man page. You can do this by "man perlpod". However, to read the pod2man man page, you must first create it by using pod2man itself.
#|/root>pod2man /usr/bin/pod2man > pod2man.1 #|/root>ls -al pod2man.1 -rw-r--r-- 1 root root 13444 Aug 16 12:12 pod2man.1 #|/root>mv pod2man.1 /usr/man/man1/pod2man.1Okay, now you can read the pod2man man page you have just created by using the command "man pod2man". After reading it, you can now create your own man pages. As an example, I shall describe a simple man page for one of my own C programs called "addline". I first create a textfile called "addline.pod" and then turn it into a manpage using 'pod2man --center="Addline program manpage" addline.pod > addline.1'.
Finally, I move the addline man page into its proper place using "mv addline.1 /usr/man/man1/addline.1". There; creating your own man page is simple, isn't it?
Below is a sample addline.pod file
-------------------Cut here and do not include this line---------------------
=head1 NAME
addline - addline numbers to textfiles
=head1 SYNOPSIS
B<addline>
[ B<-c> ]
[ B<-v> ]
[ B<-3> ]
[ B<--colon> ]
I<inputfile>
=head1 DESCRIPTION
B<addline> inserts line numbers into textfiles. It was written to automate
the insertion of numbers into a data file of results from a neural network
program.
=head1 OPTIONS
=over 8
=item -c
Ignores comments lines. A comment line is any line that starts with a '#'.
This makes it easier to insert comments in the textfile without messing up
the line numbers.
=item -v
Displays the version number of the addline.
=item -3
Uses 3 digits for the line numbers even if the number requires less than 3
digits. For example, 013 instead of 13. The default is to use as few
digits for the line number as possible.
=item --colon
Separates the line number from the rest of the line with a ':' character.
=back
=head1 EXAMPLES
addline textfile
addline -c textfile
addline -c --colon textfile
=head1 NOTES
Addline is written in C and compiled using gcc version 2.7.8. It uses the
standard C library and is designed to be fast and efficient.
=head1 RESTRICTIONS
Never ever use addline on a binary file.
=head1 BUGS
There are no bugs in addline, there are just some undocumented features.
=head1 AUTHORS
Original prototype by Steven Siew, but so massively hacked over by
his sister such that Steven Siew probably doesn't recognize it anymore.
-------------------Cut here and do not include this line---------------------
2c Tip Re: Cross-platform Text Conversions
In LG31 you published a 2c tip for a unix2dos replacement written in Tcl. The author asserts that "It turned out to be really easy to do this in Tcl." Even easier in Perl, I say. Symlink the following code to the same names (d2u, u2d, m2d, m2u, u2m, d2m) Matt used. Make sure this file has execute permission, of course.
Also, if you just want Perl to edit the input files in place, change the "perl -wp" to something like "perl -wpi.orig"....
Peter Samuelson
#!/usr/bin/perl -wp
#
# Simpler unix2dos2mac utility for 2-cent tip, mainly because Tcl is ugly.
# No comments that Perl is ugly too, please.
#
# Usage: a standard Unix filter:
# input: filename(s) or stdin
# output: stdout
# Buglet: u2m leaves lone CR at the end of file if it didn't end in LF
# (Fixing it would use more memory.)
BEGIN {
$_=$0 =~ s|.*/||;
$pcmd='s/$/\r/' if ($0 eq 'u2d');
$pcmd='s/\r$//' if ($0 eq 'd2u');
$pcmd='s/$/\r/;chop' if ($0 eq 'u2m');
$pcmd='s/\r/\n/g' if ($0 eq 'm2u');
$pcmd='chomp' if ($0 eq 'd2m');
$pcmd='s/\r/\r\n/g' if ($0 eq 'm2d');
unless($pcmd) {
print STDERR "This script must be invoked under one of the names:\n",
" u2d, d2u, u2m, m2u, d2m, m2d\n";
exit 1;
}
}
eval $pcmd;
Un-tar as you download
It's time for fun with pipes. Recently, when downloading the latest kernel over a ridiculously slow connection, I wanted to see where the download was by checking which file in the tarball was being received. After pondering the pipes and GNU utils, this thought came to mind.
You can decompress and un-tar your files as they download, sort of a "streaming decompressor", if you will. Form the command line:
tail -f --bytes=1m file-being-downloaded.tar.gz | tar -zxvTail will display downloaded portion of the file, then remain open displaying bytes as they come. Make sure the 1m (1 megabyte in this case) is LARGER than what you have already downloaded. The piped output of tail goes to tar and the rest is history. Similarly for bz2 files:
tail -f --bytes=1m file.tar.bz2 | bunzip2 - | tar -xvEnjoy!
megaraid drivers
Hi, It's been a long fight to get AMI to produce this patch and the install documentation.
Mike Burns
Re: Suggestion for Article, simultaneous versions of Kernels
I think Hans-Georg is talking about having a stable linux kernel version X and a dev version X (ie not 2.0.34 and 2.1.101 but 2.0.34 and 2.0.34). I assume when you issue: # make modules_install it tromples your old stable modules and gives you errors when you use your stable version X. This is not as trivial a problem as it first seems. However there is a solution. Have a look at the make-kpkg docs (debian distro); specifically the "flavour" option. This will solv your problem. It won't be easy, though.
Have a look at:
/etc/conf.modules
to see what I mean.
R Garth Wood

 The Answer Guy
The Answer Guy

Greetings From Jim DennisWe're all getting used to the idea that Linux can attract corporate users, for deployment as web, ftp, file (SMB and NFS), print and even database servers; and we're getting used to seeing it used for routers, mail, and DNS.
We're even getting used to the idea that corporate user put Linux on their desktops (in places where they might have spent a small fortune on a workstation).
But, what about the home/personal user? Most of us consider this to be an impossible dream. Even those few enthusiasts in the Linux community who dare to hope for it --- have been saying that it will take years to gain any percentage of that market.
However, I'm starting to wonder about that. I've seen a number of trade rag articles naysaying Linux on the desktop. Ironically, when a reporter or columnist explains why Linux isn't suitable for the desktop --- it actually raises the possibility that it is suitable for that role.
A denial or refutation tells us that the question has come up!
What prevents the average IT manager from deploying Linux on their desktop today? In most cases it's fear. The users are used to MS Word, MS Excel, and MS PowerPoint. Any user who uses any of these is forcing all of the rest to do so as well (since these applications all use proprietary, non-portable, file formats).
Everyone who uses Office has to use a PC or a Mac (and many of them switched away from Macs due to lags in upgrades and subtle file compatibility problems between the Mac and PC versions of these applications).
Why do Mac users run VirtualPC --- to deal with the occasional .DOC, .XLS, or .PPT file that they get --- or some other proprietary file format (like some of those irritating CD-ROM encyclopedia) which is only accessible through one application.
However, these proprietary formats are not secret codes. Linux and other Open Source (tm) hackers will turn their attention to them and crack their formats wide open. This will allow us to have filters and converters.
'catdoc', LAOLA, and MSWordView are already showing some progress on this area (for one of these formats).
Microsoft will undoubtedly counter by releasing a new version of their suite which will carefully break the latest third-party viewers and utilities (free or otherwise). They may even apply the most even perversion of intellectual property law yet devised: the software patent.
However. I think that the public, after a decade of following along with this game, is finally starting to wise up. The next release that egregiously breaks file format compatibility may be the end of that ploy (for awhile at least).
But what about the home user. How do home users choose their software? What is important to them?
Most of them don't choose their software --- they use what came on the system and only add things later.
When they go out to buy additional software, home users are the most price conscious of all buyers. Commercial, government, and other institutional buyers can make a business case to justify their purchases. Home users just look in their wallet.
The other common influences on the novice home user include the retail store clerks and their kids. That's one reason why the school and University markets were always so crucial to Apple's success.
I noticed that the Win '98 upgrade was going for $89. I couldn't find a "non-upgrade" box anywhere in that store (CompUSA).
People are starting to hear that for half that price they can get this other OS that includes enough games and applications to fill a 2Gb hard drive.
I think MS is actually starting to price itself out of the market. (It seems that my MS-DOS 5.0 upgrade was only about $35 or $40). If MS Office weren't bundled with so many new systems, there probably would be about a tenth the legal copies in home use.
With a little more work on LyX and KLyX and a few of its bretheren --- and a bit more polishing on the installation/configuration scripts for the various distributions I think we'll see a much more rapid growth in the home market than anyone currently believes. I think we may be at 15 to 20 per cent of the home market by sometime in the year 2000.
So, what home applications do we really need to make that happen.
... because it gives all of us a place to vote on what we would buy.
One class of packages that remember used to be very popular was the "greeting card" and "banner/sign" packages: PrintShop, PrintMaster, and Bannermania. Those used to have the cheesiest clipart/graphics and a fairly limited range of layouts. Limited enough to make any TeXnician scream with frustration.
However, they were incredibly popular precisely because of those constraints. Having a few dozen to a couple hundred choices to pick from is far less intimidating to home users than all the power and flexibility you get with TeX, LaTeX, and the GIMP.
I would dearly love to see a set of pre-designed greeting cards, certificates ("John Doe has Successfully Completed the Yoyodyne Tiddly Winks Seminar" --- with the lacy border --- you know the kind!), etc. all done in TeX or PS or whatever. This and a front end chooser and forms dialog to fill in the text would be a really killer home app.
(Bannermania was geared to creating large banners, either on fanfold paper or as multiple sheets to be cut and pasted together on to a backing board (piece of cardboard).
I think that a new Linux implementation of this sort of app built over the existing software (TeX, GhostScript, etc) would end up being vastly better than anything that was possible under the old PrintShop --- and still be as simple.
I'm sure most of us have that one old DOS, Windows, Mac, or other application or game that we'd like to see re-done for Linux. So, dig out the publisher's address or phone number (assuming they still exist) and let them know what you want. Then post your request to the wishlist.
Even these trivial bits of action can make Linux the choice of home users. I say this because I think it's about time that they had a choice.
July 19,1998
Every tool I have found for Linux and other UNIX environments seems to be designed primarily to backup files to tape or any device that can be used for streaming backups. Often this method of backing up is infeasible, especially on small budgets. This led to the development of bu, a tool for backing up by mirroring the files on another file system. bu is not necessarily meant as a replacement for the other tools (although I have set up our entire disaster recovery system based on it for our development servers), but more commonly as a supplement to a tape backup system. The approach I discuss below is a way to manage your backups much more efficiently and stay better backed up without spending so much money.
 |
© 1998 by mjh |
 |
muse:
|
I've finally started to catch up on my Musings too. This months issue includes discussions on:
Anyway, a review of Blender is a definite future Musing. The last time I tried it the program seemed to be stable, but the interface is rather complex. A general examination showed that this modeller is quite feature rich. Its just that the interface is not intuitive to a 3D newbie, perhaps not even to an experienced 3D graphic artist. A better set of documentation is reported to be on the way, due out some time in September. I'll wait and see what this might offer before stepping up for a review of Blender.
 You
can also keep an eye out for a new and improved Graphics Muse Web site
coming soon. I expect to be able to launch the new site sometime
in the middle to end of September. It will combine the Linux Graphics
mini-Howto with the Unix Graphics Utilities into a single searchable database,
provide recommended reading material and allow you to post reviews of software,
hardware and texts, plus it will provide more timely news related to computer
graphics for Linux systems. And of course all the back issues of
the Graphics Muse column from the Linux Gazette will be there too, in a
semi-searchable format with topics for each month provided next to the
links to each months issue. I'll probably post an announcement about
it to c.o.l.a when its ready.
You
can also keep an eye out for a new and improved Graphics Muse Web site
coming soon. I expect to be able to launch the new site sometime
in the middle to end of September. It will combine the Linux Graphics
mini-Howto with the Unix Graphics Utilities into a single searchable database,
provide recommended reading material and allow you to post reviews of software,
hardware and texts, plus it will provide more timely news related to computer
graphics for Linux systems. And of course all the back issues of
the Graphics Muse column from the Linux Gazette will be there too, in a
semi-searchable format with topics for each month provided next to the
links to each months issue. I'll probably post an announcement about
it to c.o.l.a when its ready.
 |
The ParPov and Pov2Rib HomepageParPov is a free (GNU), object-oriented library written in C++ for parsing Scene Files from the Persistence of Vision (POV-Ray) Ray-Tracer. It will read a scene written using version 1-3 syntax and creates a structure of C++-Objects, representing all details of the original description. You can query those objects and use the information to convert the scene to other formats or many other uses. Pov2Rib is also a freely available progam, which allows you to convert scene files from POV-Ray to a RenderMan Interface Bytestream (RIB). The tool is the first application of libParPov.http://www9.informatik. uni-erlangen.de/ ~cnvogelg/pov2rib/index.html
GQview 0.4.0GQview is an X11 image viewer for the Linux operating system. Its key features include single click file viewing, external editor support, thumbnail preview, thumbnail caching and adjustable zoom. GQview is currently available in source, binary, and rpm versions and requires the latest GTK and Imlib libraries. |
TKMatmanTKMatman is a tool that lets you interactively set and adjust parameters to RenderMan shaders and preview images with the given parameters. It can handle surface, displacement, interior, exterior, atmosphere, light and imager shaders and their combinations. The idea for the program comes from Sam Samai, who wrote the very useful IRIX version. With the availability of the Blue Moon Rendering Tools for different platforms the author of TkMatman thought that a lot more people will use the RenderMan interface and need ways to select their shaders. That's why he published his private LINUX version of MatMan. The program was initially only meant for his own use, but it is in a pretty stable state now. All feedback is appreciated and new versions will be made available at the following site:http://www.dfki.uni-sb.de/
~butz/tkmatman/
ImPressImPress allows you to create good quality documents using vector graphics. You can use ImPress within a web browser with the Tcl/Tk plugin. It's a reasonable desktop publishing and presentation tool in a small package designed for Linux and for integration with Ghostscript.The GPL'd .03alpha release fixes many bugs and adds better web and presentation functionality. |
||
LibVRML97/Lookat 0.7LibVRML97 is a toolkit for incorporating VRML into applications, and Lookat is a simple VRML browser based on that library. This code is currently being developed and is one of the more complete open source VRML browsers available. All VRML97 nodes except Text/FontStyle and the drag sensors (CylinderSensor, Plane, Sphere) are supported. The Script node supports much of the Javascript API with more on the way.Version 0.7 adds Javascript scripting, MovieTextures, TouchSensors, Anchors, Inlines, and command line arguments -url and -geometry for running under XSwallow as a Netscape plugin. |
SlidedrawSlidedraw is a drawing program in Tcl/tk for presentation slides with postscript output and full-featured. You can see snapshots, get slide collections or the very latest package available from it's new web page.URL: http://web.usc.es/~phdavidl/slidedraw/ Beta testers are welcome. Contributors for slide collections and
documentations are also invited.
MindsEye 0.5.27MindsEye is a project to develop a free (in terms of the GPL) available 3D modelling program for Linux. It features modular design, Multi-scene/user concept, Kernel-system view instead of Modeler-system view, Object oriented modelling design and network support in a MindsEye-kernel way. |
||
http://developer.netscape.com/docs/examples/dynhtml/visual/index.html
http://developer.netscape.com/software/jsdebug.html
It took a while, but finally a free server for Weitek P9100 based cards is available. XFCom_P9100 is not yet accelerated and has not received as much testing as we would have liked it to, but it should work fine on most P9100 boards.
XFCom_3DLabs-4.12
With this version of XFCom_3DLabs several problems with earlier versions should be solved. New features and fixes include:
As always, these servers are freely available, the sources to these servers are already part of the XFree86 development source. Binaries for other OSs will be made available, time permitting.
The driver is available from ftp://ftp.suse.com/pub/suse_update/XSuSE/xmatrox/.
Real-time Virtual Worlds are now possible on most workstations and PCs. The challenge is to design user-friendly systems for creating new applications and tools. This special issue of the Visual Computer is dedicated to new algorithms, methods, and systems in Real-time Virtual Worlds. Original, unpublished research, practice, and experience papers are sought that address issues in all aspects of Real-time Virtual Worlds. Topics include, but are not limited to:
| Paper Submission: | October 31, 1998 |
| Acceptance/Rejection Notification: | January 15, 1999 |
| Final Manuscript Submissions: | February 15, 1999 |
| Publication: | Summer 1999 |
Nadia Magnenat-Thalmann
Associate Editor-in-Chief
MIRALab, University of Geneva
Email: thalmann@cui.unige.ch
Daniel Thalmann
Computer Graphics Lab
EPFL
Email: thalmann@lig.di.epfl.ch
Submission guidelines: Authors may submit their paper either as an HTML URL or by ftp. For ftp, the electronic version of your manuscript should be submitted in PDF (preferred) or Postscript (compressed with gzip) using anonymous ftp to ligsg2.epfl.ch. The paper should be submitted as one file. The file name should be first author's name. Please follow the procedure:
Features include:
For further information (screenshots, download) please consult my homepage at:
Kai-Uwe Sattler
http://www.cs.kuleuven.ac.be/cwis/research/graphics/RENDERPARK/
...The computer magazine PC Chip will be publishing an interview with Ton Roosendaal, owner of Not a Number which is the company bringing us the 3D modeller Blender. This interview has been placed online so readers can get an early glimpse at it.
A: I didn't know the answer to this one, but found the following answer on the Gimp-User mailing list (unfortunately I didn't get the responders name - my apologies to that person):
Try the "Script-fu --> Utils --> ASCII 2 Image Layer" command. This allows you to import a text file as one or more layers of text.Note that this Script is available either from the Image Window menu's Script-Fu option or from the Xtns menu's Script-Fu option.
Q: Mark Lenigan (mlenigan@umdsun2.umd.umich.edu) wrote to the Gimp User mailing list:
I'm trying to create a transparent GIF with a drop shadow for the title graphic on my Web page. I'm pretty much following the cookbook from www.gimp.org/tutorials, except that I'm not including the background color layer and using "Merge Visible Layers" to keep the final image transparent. Everything goes fine until I need to convert the image to an indexed image just before I save it in the .gif format file. At that point the shadow in my image immediately disappears and the text seems to lose its anti-aliasing. Can anyone shed some light on to this?A: Simon Budig responded:
Yes. Gimp can only handle 1-bit transparency in indexed color mode. So when you convert an image to indexed the different levels of transparency will get lost. There is the great "Filters/Colors/Semiflatten" plugin. It merges all partially transparent regions against the current Backgroundcolor. Select a BG-Color (i.e. matching to the BG-Color of your Web-page) and watch the effect of the plugin. Then you can convert your Image to Indexed and save it as GIF. (GIF can also handle just 1-bit transparency).
zen@getsystems.com wrote:
One modeller that was not listed in that issue but that looks quite interesting is Blender, which is a commercial package that has only recently been released for free (no source code) to Linux users. I hope to do a review of it soon. However, the last version I tried was not documented sufficiently to allow me to understand how to do even the most basic tasks. The interface is complex and feature rich, but not intuitive to 3D newbies.

But that example was extremely simple. Real world examples often have dynamic pages that are built from multiple databases. And each page often links to other dynamically built pages that provide some, or even all, of the same information from those databases. In other words, parts of each page contain the same HTML formatting and data. How can you avoid having to duplicate that HTML in each page?
With older static page development methods there really weren't any methods for including common regions into multiple pages unless you used frames. The frames allowed you to create a region on the browser display that would be a single page of HTML that could be displayed along with various other pages. In this way you need only maintain a single copy of that one common page. From a Web developers point of view this was an ideal situation - it meant the probability of error in trying to update identical HTML in multiple pages was eliminated. It also meant less work. But to readers of those pages it could mean frustration, since not all browsers at the time supported frames. Even now, frame handling is not consistant between the two main browsers, Netscape Navigator and Microsoft's Internet Explorer. Although frames can be used to produce some terrific Web pages, they are not the ideal solution for supporting different browsers, especially older browsers.
Fortunately, this problem can be overcome with our new friend Perl. The method for inclusion in multiple pages of common formats and data is simple. However, the management of these common regions takes a little thought. Lets first look at how to include Perl code from different files into your main Perl script.
In perl, a subroutine or other piece of common code would be written in a module, a separate file of perl code. Modules can be included at any point within a perl script. By default, Perl looks at a special variable called @INC to determine where to find these modules. Also by default, the current working directly, ".", is listed in the @INC variable as the last directory to search for modules. Note: @INC is a list variable, that is, it is an array of strings with each string being the name of a directory to search for modules.
To include a module into your main Perl cgi script you would use the require function. The format is simple:
When the module is included the code within it is run at the point of inclusion. You can, if you so desire, write the module to have code that runs right then and there using variables with a global scope (ie they are visible to the original program as well as the included module). However, it would probably make more sense to write the module as a subroutine call instead. You can still use globally scoped variables but by making the module a subroutine call you can guarantee the code is not run until you specifically request it. You can also run it more than one time if you want.
So how do you make a subroutine? Just wrap the code inside the following construct:
If you want to pass parameters into the subroutine you can do so as a list. For example:
foreach $arg (@params)
{
# now run through
each parameter one at a time
# and process it.
if ( "$arg" eq ""
)
{
...
}
}
}
 |
libgr - A collection of image librariesMany users of graphics tools discussed in this column will find that those tools are dependent on any number of file format specific libraries. For example, the Gimp needs libraries for JPEG, PNG, PNM, MPEG and XPM in order to support these file formats. The Gimp doesn't understand how to read these files directly - it is dependent on the image format libraries for assistance in reading and writing files in these formats. Since the Gimp (and other tools) don't include these libraries in their source distributions, users are often required to retrieve and install these libraries manually.Normally users would download format specific libraries and build them separately. Each of the formats mentioned earlier, plus a few others, are available somewhere on the Net in source format. Most are available somewhere on the Sunsite archives. Unfortunately, not all of these format specific libraries are easily built on Linux. The Gimp User Mailing list is often flooded with questions about how to get the JPEG library to build shared libraries. By default this library doesn't build a Linux ELF shared library. In fact, even with the proper configuration it still only builds a.out shared libraries. A better solution is needed. Enter libgr. This is a collection of image format libraries that have been packaged together and organized to easily build and install on Linux systems. The package builds both static and ELF shared libraries automatically. The distribution is maintained by Neal Becker (neal@ctd.comsat.com) and is based on the work done originally by Rob Hooft (hooft@EMBL-Heidelberg.DE). The latest version, 2.0.13, of libgr can be retrieved from ftp.ctd.comsat.com:/pub/linux/ELF. Libgr contains the following set of graphics libraries:
FBM is the Fuzzy Pixmap Manipulation library. This package is related to, but not part of, the PBMPlus package by Jef Poskazner. The library can read and write a number of formats, including:
JPEG is actually a standard that defines a suite of encodings for full-color and continuous-tone raster images1. The software for this library, which is essentially the same as the software that comes in the standalone JPEG library package found on the Gimp's ftp site, comes from the Independent JPEG Group and, as far as I can tell, supports the complete JPEG definition. JPEG is a common format for the Web since it is one of the formats listed by the WC3 in the early HTML specifications for Web images. The PBM, PGM, PNM, and PPM formats are all part of the NetPBM/PBMPlus packages. These formats are often used as intermediary formats for processing by the NetPBM/PBMPlus tools. Although these libraries provide the capability of saving image files in these formats, I have not seen this as a common practice. This is probably due to the fact that the files tend to be rather large and the image formats are not generally supported by non-Unix platforms. These formats are widely supported, however, by Unix-based graphics software. The PNG library supports the relatively new Portable Network Graphics format. This format was designed, at least in part, to replace the GIF format which had both licensing as well as a few format limitations. PNG is now an officially supported format by the WC3 although support for these images is not commonly mentioned by either Netscape or MSIE. I'm not sure if either supports PNG yet. RLE is Run Length Encoding, a format from the University of Utah designed
for device independent multilevel raster images. Although the format
is still in use today, you won't see it referenced often in relation to
tools like the Gimp (though the Gimp does support the format) or 3D rendering
engines like BMRT or POV-Ray.
|
||
Finally, the TIFF library is a set of routines for
supporting the reading and writing of TIFF files. TIFF files are
popular because of their wide support on multiple platforms (Mac, MS, and
Unix) and because of their high quality images. However, they tend
to be extremely large images since they do not use any form of compression
on the image data.
Building the packageOnce you have retrieved the libgr package you can unpack it with the following command:
At this point you're ready to use these libraries with other tools, such as the Gimp. Why use libgr vs the individual libraries?Libgr provides support for a large range of image file formats, but it doesn't support every common and/or popular format. So why use it instead of the individual format libraries? One reason is convenience. Instead of having to retrieve a whole slew of packages you can grab one. Second, as mentioned earlier, not all of the individual packages are setup to build proper ELF shared libraries for Linux. Libgr is specifically designed for building these type of libraries.What libraries does libgr not include that you might want? One fairly common X Windows format is XPM. Libgr does not support this format so you'll need to retrieve the XPM library separately. Fortunately, most Linux distributions already come with this library prebuilt and available to you during installation of the operating system. Libgr also does not support any animation file formats. If you have need to read or write files in MPEG, FLI or FLC formats, for example, you will need to locate and install those libraries individually. CaveatsOne minor caveat to using the libgr package exists with the zlib distribution. According to the documentation for libgr (in the NEWS text file) the zlib release numbers went down at some point. This means its possible for you to have an older version of zlib installed even though its version number is higher than the one in libgr. How to resolve this is a tricky question but in my opinion it makes sense to install the zlib that comes with libgr because its known to work with the rest of the image libraries in the libgr package. If you agree with this logic then you will probably want to remove the old version of zlib first, before doing the make install for libgr.
SummaryLibgr is not a drop-in replacement for all your image file format needs,
but it does offer added convenience to the Linux users by providing a Linux-specific,
easy to use build and install environment. Since the libraries included
in the libgr package do not change all that often it makes good system
management sense to deal with the one distribution than to try to deal
with updates to multiple image format packages. And if you're dealing
with building the Gimp, which requires many image libraries, libgr is a
much simpler solution to get you up and running in the least amount of
time and with the least amount of frustration.
1. C. Wayne Brown and Barry J. Shepherd, Graphics File Formats: Reference and Guide, Prentice Hall/Manning, 1995. |
 |
| Online Magazines and News sources
C|Net Tech News Linux Weekly News Slashdot.org Digital Video Computer Graphics World General Web Sites
Some of the Mailing Lists and Newsgroups I keep an eye on and where
I get much of the information in this column
|
 |
Let me know what you'd like to hear about!
More... |
| © 1998 Michael J. Hammel |
 |
# The subroutine to create a table for our ads.
sub setads
{
# Open a connection to the database.
my $dbh1 = Msql->connect();
$dbh1->selectdb('mydb');
# Get the ads from the database.
We assume
# here that there is at least 1 ad in
the
# "ads" table. We also assume
the table has
# the format of
# 1. imagename
# 2. URL
# The results from the database query
are stored
# in the @results variable. This
list variable
# will contain one array element for
each field
# in the "ads" table.
$sth2 = $dbh1->query("SELECT * FROM ads");
while ( (@result = $sth->fetchrow)
{
# Add a <td> entry
with the image for the ad
# linked to the specified
URL. The "a({-href"
# portion is where
we use the CGI.pm
# a() function to
establish the hyperlink.
push
(@tableelments,
td({-align=>'CENTER', -valign=>'CENTER'},
a({-href=>"$result[1]"},
img( { -src=>"/images/$result[0]",
-alt=>"$results[1]",
-border=>'0',
-hspace=>'0', -vspace=>'0' }
)
)
)
)
}
If we now include this module in our main script we can then print out the advertisement table at any time we wish:
print header,
start_html(
-author=>'webmaster@graphics-muse.org',
-title=>'Our Little
Web Site',
-bgcolor=>'#000000',
-text=>'#000000'
),
$adbanner,
table(
{-border=>0, -width=>'100%',
-height=>'97%',
-cellpadding=>0, -cellspacing=>0},
Tr(
td({-align=>'LEFT', -valign=>'TOP',
-rowspan=>2, -width=>'110',
-bgcolor=>'#FFCC00'},
$news_table),
td({-align=>'CENTER', -valign=>'CENTER',
-width=>'78%',
-bgcolor=>'#FFCC00'},
$nav_bar),
td({-align=>'CENTER', -valign=>'TOP',
-rowspan=>2,
-bgcolor=>'#FFCC00'},
$book_table)
),
Tr(
td({-align=>'CENTER', -valign=>'TOP',
-height=>'80%',
-bgcolor=>'#ffffff'}, $qd_table
)
)
);
end_html;
This last bit of code actually comes from the code I'm writing for the new Graphics Muse web site. I have a common table definition for all pages (the table printed after the $adbanner in the last example), and modules for assigning HTML formats and data to the $news_table, $nav_bar and $book_table. Then each main CGI script fills in the $qd_table variable with page specific data. In this way I can make modifications to the way data is displayed in, for example, the news_table by only having to edit one script. Management of the site becomes much more simple than having to edit all the scripts each time a single change to news_table needs to be made and I avoid annoying many users by avoiding the use of frames.
In the short time I've been using Perl I've grown to truly appreciate
both its sophistication and its simplicity. Things that should be
simple to do are simple. Additional tools like CGI.pm and Msql make
integrating Perl with my Web site a breeze. I've managed to rebuild
my Web site from the ground up in less than a a couple of weeks and I'm
not even making full use of what Perl can do for me. If you manage
a Web site and have access to the cgi directory you should definitely consider
learning Perl, CGI.pm, and one of the many databases which Perl supports.
|
 One
of the more interesting plug-ins in the Gimp is Qbist,
written by Jens Ch. Restemeier
and based on an algorithm from Jörn Loviscach that appeared in the
magazine c't in October 1995. I've had quite
a good time playing with this plug-in creating backgrounds for logos and
other images. The filter is really pretty easy to use. The
plug-in dialog is made up of a set of 9 preview windows. By clicking
on any one of these the entire set is updated with new previews and the
preview you clicked on is displayed as the new middle preview. This
central preview is used as a basis to generate the rest of the previews.
You can generate a set of previews that are somewhat similar to the basis
preview by clicking on the middle preview. In most cases, at least
one of the previews will be significantly different from the basis.
Selecting another preview usually generates quite different previews, but
this isn't always guaranteed.
One
of the more interesting plug-ins in the Gimp is Qbist,
written by Jens Ch. Restemeier
and based on an algorithm from Jörn Loviscach that appeared in the
magazine c't in October 1995. I've had quite
a good time playing with this plug-in creating backgrounds for logos and
other images. The filter is really pretty easy to use. The
plug-in dialog is made up of a set of 9 preview windows. By clicking
on any one of these the entire set is updated with new previews and the
preview you clicked on is displayed as the new middle preview. This
central preview is used as a basis to generate the rest of the previews.
You can generate a set of previews that are somewhat similar to the basis
preview by clicking on the middle preview. In most cases, at least
one of the previews will be significantly different from the basis.
Selecting another preview usually generates quite different previews, but
this isn't always guaranteed. 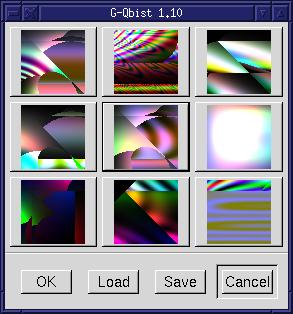 The
algorithm is sufficiently random to make it possible that not only can
the other non-basis previews be radically different, they can also be nearly
exactly the same as the orginal. From a creative standpoint, I find
this rather interesting. At times, when I'm tired of coding or writing,
I pull this filter up and start to become creative. The patterns
it generates are on the edge of randomness, with just enough recognizable
geometry to make you say "No, thats not quite right, but its close".
The problem, of course, is it keeps you saying this ad infinitum until
you realize its long past midnight and you have just enough time for one
cup of coffee and a shower before you have to be to work. But this
is the kind of creativity I used to feel with coding when I first got my
hands on PC (ok, it was a TRS-80, but you get the point). Its refreshing
to feel it again.
The
algorithm is sufficiently random to make it possible that not only can
the other non-basis previews be radically different, they can also be nearly
exactly the same as the orginal. From a creative standpoint, I find
this rather interesting. At times, when I'm tired of coding or writing,
I pull this filter up and start to become creative. The patterns
it generates are on the edge of randomness, with just enough recognizable
geometry to make you say "No, thats not quite right, but its close".
The problem, of course, is it keeps you saying this ad infinitum until
you realize its long past midnight and you have just enough time for one
cup of coffee and a shower before you have to be to work. But this
is the kind of creativity I used to feel with coding when I first got my
hands on PC (ok, it was a TRS-80, but you get the point). Its refreshing
to feel it again.
Once you've selected the preview you want in your image, making sure
its been selected and is displayed as the basis preview, you can add it
to the current layer of your Image Window by clicking on OK.  Qbist
will fill the entire layer, or the active selection, with a scaled version
of the basis preview. Since there are no blend modes for Qbist the
selection/layer will be completely overwritten with the Qbist pattern.
The real trick to using these patterns comes from being able to make selections
out of the geometrically connected pieces, creating drop shadows from the
selections and slipping other images or text inbetween the layers.
Qbist
will fill the entire layer, or the active selection, with a scaled version
of the basis preview. Since there are no blend modes for Qbist the
selection/layer will be completely overwritten with the Qbist pattern.
The real trick to using these patterns comes from being able to make selections
out of the geometrically connected pieces, creating drop shadows from the
selections and slipping other images or text inbetween the layers.
Another problem is that the Save/Load options don't deal with a Qbist-specific directory. A number of other plug-ins manage saved files within directories under the users $HOME/.gimp directory. It shouldn't be difficult to update Qbist to do the same. Its just a matter of getting around to updating the code.
Speaking of the code, a quick examination of the source to Qbist shows
some hard coded values used in various places that appear to be the sort
of values that should be user configurable. The interface could be
expanded to allow the user to change these. I may try this sometime
soon, just as an experiment to see how changes to these values affect the
previews.  Since
I'm not familiar with the algorithm its unclear if these values are necessarily
specific or just good initial seed values. Another option might be
to allow the user to choose some color sets from which Qbist could render
its patterns. Right now Qbist chooses colors on its own, without
input from the user.
Since
I'm not familiar with the algorithm its unclear if these values are necessarily
specific or just good initial seed values. Another option might be
to allow the user to choose some color sets from which Qbist could render
its patterns. Right now Qbist chooses colors on its own, without
input from the user.
Finally, probably the most annoying aspect to Qbist is that there are no blend modes available. I'd love to be able to render a Qbist pattern in one selection and then use another selection to blend a different pattern over a corner of the first selection. I can do this with multiple layers, but it would be more convenient to be able to do this from within Qbist itself. Qbist renders it patterns in both the previews and the image window fairly quickly, so changes like adding blend modes shouldn't cause serious performance problems.
Qbist is a plain fun filter. Like many of the Render menu filters,
Qbist gives you a chance to explore some of your true creativeness.
By letting you wander through a random collection of patterns it lets you
play with your computer in a way that a game can never quite equal.
Although your control over these patterns is a bit limited, the patterns
themselves are sufficiently fascinating to make Qbist a filter well worth
exploring.
|
| © 1997 by Michael J. Hammel |
Today while shopping, I found StarOffice 4.0 (Commercial version) at a local cdrom shop. I already own (and use) ApplixWare, but I could not resist - given the usually positive reviews, I just *had* to try it.
Please note that Caldera currently has a special on StarOffice 4.0 - $49.95US. That is an excellent price for a commercial license. Also note that StarOffice is available via ftp without cost for non-commercial use.
I wanted to see how it would perform on a fairly low performance system, so I loaded it onto my server. In order to benefit others, I thought I would document my installation. I will use it for a few days, after which I will write a review on my 'user' experiences.
StarOffice comes on two cd's, in a jewel case. The first CD contains StarOffice and also appears to contain OpenLinux Lite along with some additional contrib packages. The second CD, a pleasant surprise, appears to be OpenLinux Base. This means I will have a busy couple of nights - I'm going to have to try out OpenLinux.
I read the instructions - and the 'README' file. I logged in using my regular user account, went to /mnt/cdrom/StarOffice_40, and entered './setup'.
After the installation program started up, I got the infamous dialog "line 1: syntax error at token 'I' expected declarator; i.e. File..." prompting me to press ok.
In all honesty, I must admit I was expecting this problem - I remember people asking for help with this very same problem while reading the Linux news groups. I went to Dejanews to find out how people solved this problem.
I used "Staroffice 4.0 RedHat 5.1" as my search string, and got 61 matches.
The very first match was a posting from Simon Gao, who on July 27 wrote:
This is a well known problem with RedHat 5.x. The problem is that StarOffice4 requires libc.5.4.28 above file system. Check out at www.waldherr.org/soffice and you find how to solve this problem.
Off I went to Stefan Waldherr's web site. There I found that the version of StarOffice I purchased today is already outdated - and that I should download the latest version. As most people who purchase the commercial StarOffice package will get the same version I got (and as I did not want to wait to download 4.0.3 yet) I just downloaded the staroffice wrapper and proceeded to see if I could install 4.0 as shipped on the CD.
I become root to install the rpm. The rpm would not install, I was treated to an error message:
Error during install, staroffice tar file not found.
Looking for any of the following files or directories
/tmp/so40sp3_lnx_01.tar.gz
/tmp/so40sp3_lnx_01.tar.gz
Since I *REALLY* did not want to download 4.0.3 yet, I got stubborn.
I looked through some more messages, and based on the information I found, I tried the following:
I ftp'd libc-5.4.46-1rh42.i386.rpm from ftp.redhat.com/pub/contrib/i386, and tried to instal it.
I got a "failed dependencies: ld.so >= 1.9.9 is needed by libc-5.4.46-1rh42.i386.rpm" message.
Good thing I kept my ftp session open. I now ftp'd ld.so-1.9.9-1rh42.i386.rpm. This time I got a pile of glibc conflicts. Nope, there *HAS* to be a simpler way.
Back to the drawingboard - or DejaNews, as the case may be. I found an article by Tommy Fredriksson, originally posted in stardivision.com.support.unix. Tommy wrote:
In article <35A4B35E.CAA00699@actech.com.br>
wrote:
> I just got StarOffice 4.0 ServicePack 3 but I can't run on my RedHat Linux
> 5.1 box, it shows that dreaded "line 1 syntax error at token 'l'", etc. RH
> 5.1 is libc6-based (glibc), but I also put libc-5 on my /lib directory.
> Even this would not make it work. Could someone help me on this?
Put your "libc-pack" anywhere you can find it - tell /etc/ld.so.conf (on top) where you put it and run ldconfig -v and look for errors - if non, install SO. That's all...
Based on this message, I improvised. To save all of you some work, here are some step by step instructions on how to install StarOffice 4.0 on RedHat 5.1:
Following the README, I typed Office40/bin/soffice. After some disk activity, it ran! Note, I did not time how long it took, but it seemed like 20-30 seconds.
I chose to create a new document. I resized the window, and docked the paragraph style floating bar on the left hand side. The text in the default view was pretty poor, so I chose the 'Optimal' view (why don't they default to Optimal?) under the 'View' menu. This looked much better.
I proceeded to type a few lines, and chose to print. I let it print as if to a PostScript printer. Lo and behold, my HP4L printed out the text quite nicely!
I am afraid that a review of StarOffice will have to wait for another day. So far, I like what I see, however I will only be able to intelligently comment on its features after using it for a while.
Caldera or StarDivison has to make installation easier. I fully intend to try OpenLinux, and I am sure that the StarOffice installation will be much smoother than under RedHat. At this point, a Linux beginner who tried to install StarOffice on a RedHat system, and was not used to using excellent resources such as Dejanews, would have a very frustrating experience.
The fine help available on the net from individuals like Tommy Fredriksson, Stefan Waldherr and many others, makes a mockery of the assertion that Linux has no support. I hope their postings and this article will save some time for those trying Linux for the first time.
I hope you enjoyed this article,
William Henning
Alessandro: Can you please dedicate some of your time to us?
Linus: Sure, no problem, I'll try my best.Alessandro: Are you happy with living in the States? I preferred having a Finnish leader rather than another american ruler.. how do you feel in this respect? Do you plan to come back?
Linus: I've been very happy with the move: I really enjoyed being at the University of Helsinki, but I decided that trying out something different was worthwhile, and so far the experience has been entirely positive.
I agree that Finland is a lot more "neutral" in many ways, and that had its advantages in Linux development: I don't think anybody really dislikes Finland, while a lot of people are nervous about or even actively dislike the US. So in some sense that could have been a downside, but I felt that most people trusted me more as a person than as a Finn, so I didn't feel it to be a major issue.
Moving to the US has meant a lot better weather (even though this has been one of the rainiest winters in a _long_ time here in the Bay Area), and has also been very interesting. While I really liked my work at the University, the new stuff I'm doing is more exciting - more on the edge, so to say.Alessandro: We all know about the USA restrictions on cryptography; do they affect Linux features in the field?
Linus: It doesn't seem to be a real issue. The idiocy of the US cryptography export rules were a problem even before I moved here: mainly because if/when we add strong cryptography to the kernel we would have to make it modular anyway in order to let the CD-ROM manufacturers (many of whom are based in the US) take it out in order to sell overseas. So me moving here didn't really change that fact - it only made it apparent that I can't be the person working on cryptography (something that was fairly obvious anyway, as I'm not really an expert in the area).
Anyway, regardless of the above I sincerely hope that the US cryptography rules will be changed in the near future. The US rules have made a lot of things more difficult than they should have been. (In all fairness the US isn't the only country with problems: the French have even more of a problem in this area and are trying to get other European countries to do the same thing. Happily the French are a fringe group of loonies in this matter, while the US has been a real problem due to being so central when it comes to information technology).Alessandro: Did you ever think about leaving your role as Linux coordinator or is it fun like it was in the beginning? If you would leave, what would your next project be?
Linus: I've never seriously considered leaving - the only times the issue has come up is really when somebody has asked me what the succession would be in the case I no longer felt interested. Linux has always been so much fun to coordinate that while it obviously takes a lot of my time I have always felt that it was more than worth it.Alessandro: Out of curiosity, how long do you write code daily, and what is your current main activity?
Linus: I usually don't spend all that much time coding on Linux any more: occasionally I have bursts of things I do when I code full-day for a few weeks or so, but those are fairly rare, and mainly happen when there is some fundamental shift in the kernel that I want to get done. During the last year it's happened four or five times, mainly with regards to SMP or the so-called "dentry" filesystem cache.
Most of the time I spend reading and reacting to emails - coordinating the others working on things, commenting on ideas, and putting together patches. This is by far the most work: I'd say that my coding is only about 10%, while the coordination is 90% of the work.Alessandro: How did you manage to write a free kernel and still earn your living?
Linus: Initially, I was a university student at the University of Helsinki. What that means in Finland is that you get support by the goverment for a number of years in order to be able to finish your degree, and there is also a possibility to get special student loans. I suspect Italy has something similar, although probably not as comprehensive as the Finnish system.
And after a year or two I was actually employed by the university as first a teaching assistant and then later a research assistant, and the university also actively encouraged me to be able to write Linux at the same time.
Right now, I obviously work at a commercial company, but even here I get to do a lot of Linux work even during work hours because even though Transmeta doesn't sell Linux or anything like that, there is a lot of _use_ of Linux inside the company, so me continuing to work on it is obviously supportive of the company.
So I've always been able to do Linux together with doing my "real" work, whether that was studying or working for a university or working for a commercial entity. There has never been much of a clash, even though obviously my working hours aren't exactly nine to five..Alessandro: Why didn't you turn to commercial support like Cygnus did? (I think I know why :-)
Linus: I just never felt the interest to turn any part of Linux commercial: it would have detracted a lot more from my time to maintain a company or something like that, and it was never what I was interested in.
It would also have implicated Linux money-wise: I wouldn't have been free to do what I wanted technically because I would be bound by constraints brought about by having to feed myself and my family. In contrast, working at the University or here at Transmeta, I make a living without having to involve doing Linux-decisions into it - so I'm free to do whatever I want with Linux without having to worry whether it will pay my next months rent..
I feel a lot happier not having those kinds of pressures on Linux, and I think most other developers feel the same way (they don't have to worry about my technical judgement being corrupted by any financial issues).Alessandro: Do you think you changed the world or just fired the straw? (Again, I know you)
Linus: I started it, and I feel very proud of that. I don't hink I "changed the world", but I feel privileged in being instrumental in changing a lot of lives - it's a good feeling to know that what you do really matters to a lot of people.
I wouldn't go as far as saying that it "gives my life meaning", but Linux definitely is a _part_ of my life, if you see what I mean.Alessandro: What's your opinion of Richard Stallman's work and philosophy?
Linus: I personally don't like mixing politics with technical issues, and I don't always agree with rms on a lot of issues. For rms, there are a lot of almost religious issues when it comes to software, and I'm a lot more pragmatic about a lot of things. As a result, we know we disagree about some things, and we actively don't try to work together too closely because we know it wouldn't work out very well.
The above may make it sound like I dislike rms, and at the same time that is not at all true. Rms has obviously been the driving force behind most of the current "free software" or "open source" movement, and without rms the world would be a poorer place. And he _needs_ to be religious about it to be that driven.
So I guess the best way of saying it is that I really admire rms, but I wouldn't want to be him, because our worldviews are different.Alessandro: On the practical side, what's the schedule for 2.2? What are the main differences between 2.0 and the upcoming 2.2?
Linus: As I looks now, 2.2 should be sometime early summer or so, but it's hard to judge: there are a few things that really need to get fixed, and before they are fixed there's no point in even thinking about it. Right now there's a bad TCP performance problem that is holding things up: everything _works_ ok, but it is serious enough that I can't imagine a 2.2 before it is fixed.
The changes 2.2 will have are mainly much more mature support for the new things in 2.0, namely SMP and multiple architectures. There are a _lot_ of other things in there (the new dentry code, totally rewritten NFS etc), but the SMP and architecture maturity is one of the most fundamental things that 2.2 will have.Alessandro: Bruce Perens claims "world domination: 2003"; is that realistic? In your opinion, will the concept of free software gain polularity in the mass market? In this respect, what's your opinion about the move of Netscape Corp.?
Linus: The "World Domination" thing is obviously always a bit tongue-in-cheek, but I think that yes, a five-year timeframe for the free software movement and Linux to make a major noticeable impact is not at all unrealistic. The Netscape open source thing is one of the first indications of this, and I think we'll see others doing similar things.Alessandro: How will the various free OS's coexist, in your opinion?
Linus: I think the current setup where people are aware of each other, but there is no organized or official co-operation is probably how it will continue. The whole point of Linux is that there is definitely room for more than one operating system (especially if that one operating system is a bad one made by microsoft ;), and I don't see that changing - the FreeBSD's and other operating systems will be around. Maybe not in the same form (more specialization etc), but I don't see any fundamental issues here..Alessandro: Or do you think that development of Wine and other tools will lead to the cohexistence of two systems of similar technical value, one free and the other proprietary, running the same application programs? (Horrible question, IMHO).
Linus: No, I think the development of Wine will be an important step for the PC operating systems arena, but that step will be in the way of leveling the playing ground: when just about everybody can run the basic legacy Windows applications like MS Office etc, that allows the systems to really compete on being good at other things.
So rather than having two systems of similar technical value, I think that you'd have many systems that are all able to run the same basic applications, but where the emphasis is on different things. Microsoft, for example, ha salways emphasized mediocrity and high volume, while Linux has (and will continue to) emphasized more technical issues.Alessandro: Currently we lack free office applications. Is this a matter of time, or do you think that these programs will only be available from commercial companies?
Linus: I think that there will always be a niche for commercial programs, and while I think we'll see free office applications proliferate, I don't think that we necessarily _have_ to have them.
The reason I personally want a free operating system and basic applications is that I really think that if the basics aren't stable and you can't modify them to suit your own needs, then you are in real trouble. But when it comes to many other areas, those issues are no longer the most pressing concerns, and then it is not as critical that you have free access to sources.Alessandro: Sometimes we hear of so-called ``standards'' that remain proprietary (like I2O), is this the last rant of dying companies, or is free software at risk?
Linus: I don't worry too much about I2O and other proprietary standards. The whole idea of a proprietary standard has always failed - all of the successful standards these days are fairly open. Sometimes they are proprietary because the company that made them had enough clout to force it to be that way on its own, but I don't think that kind of clout exists anywhere else than at Intel and at Microsoft, and that even those two are being eroded by competition.Alessandro: What is your position about the availability of Linux modules in binary-only form?
Linus: I kind of accept them, but I never support them and I don't like them.
The reason I accept binary-only modules at all is that in many cases you have for example a device driver that is not written for Linux at all, but for example works on SCO Unix or other operating systems, and the manufacturer suddenly wakes up and notices that Linux has a larger audience than the other groups. And as a result he wants to port that driver to Linux.
But because that driver was obviously not _derived_ from Linux (it had a life of its own regardless of any Linux development), I didn't feel that I had the moral right to require that it be put under the GPL, so the binary-only module interface allows those kinds of modules to exist and work with Linux.
That doesn't mean that I would accept just any kind of binary-only module: there are cases where something would be so obviously Linux-specific that it simply wouldn't make sense without the Linux kernel. In those cases it would also obviously be a derived work, and as such the above excuses don't really apply any more and it falls under the GPL license.Alessandro: What do you think about the KDE-Qt question? Is Gnome going to succeed?
Linus: I personally like Qt, and KDE seems to be doing fairly well. I'm taking a wait-and-see approach on the whole thing, to see whether gnome can do as well..Alessandro: An interesting challenge is "band reservation" in the network subsystem; is that going to happen any soon in Linux?
Linus: I'll have to pass on this one. It's not one of the areas I'm personally involved with or interested in, and as such it's not something I'm going to be very involved with any efforts that way. That's how Linux works: the people who need or want something get it done, and if it makes sense on a larger scale it gets integrated into the system..Alessandro: Many people ask why the kernel is written in C instead of C++. What is your point against using C++ in the kernel? What is the language you like best, excluding C?
Linus: C++ would have allowed us to use certain compiler features that I would have liked, and it was in fact used for a very short timeperiod just before releasing Linux-1.0. It turned out to not be very useful, and I don't think we'll ever end up trying that again, for a few reasons.
One reason is that C++ simply is a lot more complicated, and the compiler often does things behind the back of the programmer that aren't at all obvious when looking at the code locally. Yes, you can avoid features like virtual classes and avoid these things, but the point is that C++ simply allows a lot that C doesn't allow, and that can make finding the problems later harder.
Another reason was related to the above, namely compiler speed and stability. Because C++ is a more complex language, it also has a propensity for a lot more compiler bugs and compiles are usually slower. This can be considered a compiler implementation issue, but the basic complexity of C++ certainly is something that can be objectively considered to be harmful for kernel development.Alessandro: What do you think of the Java phenomenon? Did you ever consider integrating a Java VM, like kaffe, in the kernel?
Linus: I've always felt that Java had a lot too much hype associated with it, and that is still true. I _hope_ sincerely that Java will succeed, but I'm pragmatic and I'm not going to jump on the Java bandwagon prematurely.
Linux already supports seamless running of Java applications as it is, and the fact that the kernel only acts as a wrapper for the thing rather than trying to run the Java VM directly I consider to be only an advantage.
This article is reprinted with the permission of Infomedia, Italy. An Italian translation of this article can be found at http://www.pluto.linux.it/journal/pj9807/linus.html. The interview was done by e-mail in February, 1998.
The origin of the current mess can be traced back to a short spell of ultra-liberalism, when the government caved in to the pressure to cut taxes and eliminate the national debt by selling off the road network. Politicaly, it has been a success; taxes are consistently lower than they have been for long, and the man in the street seems to be satisfied.
Of course in the beginning, the situation was quite messy; highway segments were auctioned off, and the result was toll booths everywhere, so you had to stop many times and have a lot of petty cash handy if you wanted to get anywhere.
But then, gradually, a market leader appeared. Federal Transport Corp. bought strategically placed road segments, connected them into a countrywide network, made it impossible for anyone else to do the same, and slowly took over the rest.
By the motorists, it was felt to be a blessing. Sure, prices went up; but you could get by with getting a yearly license and putting the barcode sticker on the roof of your car; you didn't even have to brake anymore when passing the toll station. And the more roads FT acquired, the better the offer they could make their customers; such are the ways of "network externalities".
Obviously as many of us now realise, the net effect was no tax drop at all. The yearly fee to FT is just another tax, if you want to use your car to go anywhere at all; and what's worse, it is paid to an authority we didn't elect ourselves. There has been a groundswell of resistance, such as the freetown (or "open roads") movement, and I sympathise fully with this.
I live in a freetown now; a small one, at the foot of the mountains. Others are on the coast, or around airports. Few are inland. We have our own road network that we own ourselves collectively, just like in the old days. If you want to go to another freetown, you have the options of air, rail and water transport, which are not (yet) under FT's control. If you want to visit people outside freetown land, you have to pay the toll, of course :-( This -- referred to as "gating out" -- is minimized by careful planning.
You may ask, why did I choose to live in a place, and under a regime, that limits my freedom of movement so much? Well first of all, it is my own choice. I don't want to owe my "freedom" to an authority that does not represent me. And then, there are compensations. The people. Freetowners are active, involved citizens; everything is debated, and decisions are taken by informed people. Compare that to the way outside. It's a different culture really, and I like it. They are my kind of people.
And, except in the matter of transport, life in a freetown is just as good or better than outside. There is a lot of employment in hi-tech; as I said, we are a sophisticated lot. And there are no advertisements of FT, like there are everywhere outside, enquiring politely but insistently where you would feel like going today... that really gets my blood pressure up.
These are interesting times we live in; recently the freetown movement has gained a lot of interest and newcomers are flowing in. Resentment at the Federal Transport monopoly is tangible, now that fees are going up and road maintenance is being neglected. Earlier, just after the sell-off, roads were maintained well; you had the option of choosing alternative routes, and the toll revenue was channeled to maintenance and improvement. Now, many road segments seem to be in free fall down towards their natural state. You still have alternative routes to choose from; but they are all under FT's control and in uniformly poor shape.
And then there is this crazy project called the RoadPlane. It is a gigantic vehicle, carrying hundreds of people at 200 mph along the highways, rolling along smoothly on smart-strutted wheels, navigated by satellite, electronic map and road radar. I have heard of people riding one of those things; quite an impressive experience, it appears. FT's slogan is "A Better Plane Than The Plane", but some bad accidents have happened already. It is a very complex system; OK as long as everything works, but winter weather, the poor state of the roads, and errors in the maps -- or an animal straying on to the road -- are hard to foresee and take into account. These problems have generally been glossed over in the media; FT represents a major advertising budget for them.
RoadPlane is FT hybris at its best. It is a white elephant and that fills me with glee. This could be the undoing of FT, who knows. But it will only happen if people take the trouble to inform themselves, understand how they are being ripped off, and become active!
Similarity to real events and circumstances
is, again, purely and wholly intentional.
Not long ago, Javasoft celebrated Java's third birthday. Java, once seen as merely another way to animate and spice up web pages, has become much more than that. Nowadays, well-known software corporations have pledged their support to Java, and new Java APIs are being defined in record time. The Java technology enables programmers to finally write truly multi-platform programs, offers an advanced cross-platform GUI toolkit, embedded threading in the language and much more.
At the same time, we are seeing remarkable events in the computer software world. Microsoft, the behemoth of the industry, is being seriously threatened by anti-trust action from both the Justice Department and 20 different states. Netscape has released the source code for Communicator and may be the first company to break free of Open Software prejudice. This has attracted much interest in Open Software from companies who have traditionally feared the concept.
What do all of these events mean for the Linux operating system? It means we have a window of opportunity. Never before has the time been so right. On one hand, the industry is seriously taking a look at Linux as an open (and free) OS. Hey, if Netscape is doing it with their browser, why not an Open OS? On the other hand, Java technology offers a machine-independant way to write applications, and much of the industry has rallied behind it.
The Linux community itself, however, has always treated Java with an ambivalent attitude. The language that has promised to topple the hegemony of Microsoft, a dream like that of any Linux enthusiast, hasn't been accepted into the mainstream of Linux development. There are several reasons for this.
First and foremost, Java is a proprietary language owned by Sun Microsystems. This means that Sun controls every aspect of the language, the APIs and their licensing conditions. Tactics by Microsoft, like changing APIs in their Java suite J++ and rendering their virtual machine incompatible with other Java virtual machines, have forced Sun to seek exclusive rights to dub a product ``Java-compatible''. Although this may be the only way to fight Microsoft's unfair tactics, never before has a language been so much in the hands of a single corporation. The Linux community was born much in protest of this kind of ownership.
Second, the multi-platform concept of Java, the Java Virtual Machine (JVM), means that programmers feel they are programming for the Java environment and not for the Linux environment. This also means that it's much more difficult to exploit the features of Linux.
Third, Java is still slow. Many promising enhancements are available such as Just-in-Time compilers and Sun's Hotspot (still in beta). Java has certainly improved since it was first created, but it still requires a powerful platform. The Linux world is relatively speed-minded, and one of the main advantages of Linux is its ability to run on obsolete hardware.
Despite all these shortcomings in the nature of Java, it is the only real challenge made in the last few years to Microsoft's rule. It is also an advanced language, written from the ground up with modern programming concepts in mind; all the flaws C++ retained from C for backwards compatibility are gone in Java, along with other complex features (multiple inheritance, for example). An automatic garbage collector removes the need to free memory, drastically reducing development time. Threads are so embedded in the language they become an indispensible tool for the programmer.
I hope Linux developers take a second look at Java as a development language and start using it regularly. Some Linux developers have already made impressive progress with Java tools, including several Java virtual machines (JVMs), several Just-In-Time (JIT) compilers and others. Take a look at these if you are considering using your Linux platform for developing Java. The Java-Linux resources page can be found at: http://www.blackdown.org/java-linux.html
I will now go over some of the key features in JDK 1.1.x. Note that the next version, 1.2 is in beta but should be available soon.
Object serializing means taking an object and flattening it into a stream of bytes. In practice, this is usually used for two things--passing objects through a network and storing objects in files. Usually, a programmer who wishes to store a data structure on disk has to write a specific algorithm for doing so, which can be quite tedious. Java simplifies all this by doing it automatically for you. For example, if you have a tree in memory and wish to pass it to another Java program on the network, all you have to do is to pass the root object--Java will follow the pointers and copy the entire tree. If you have special considerations (like security), you may design the way the object is serialized.
The original AWT, which is the windowing toolkit for Java, was very clunky and uncomfortable. Many components were missing and the programming model was needlessly painful. The current accepted toolkit for Java is code-named Swing. Swing offers a large number of lightweight components; they are fully implemented in Java but do not use the underlying windowing architecure as in AWT. This assures the same functionality across platforms. Another appealing feature is the completely pluggable look and feel, which lets you switch between Windows and Motif, for example, while the program is running. You can also design your own look.
RMI is the Java equivalent of CORBA, which is a way to invoke methods in objects that are in a different JVM (or even machine). For those of you who know the RPC (Remote Procedure Call) frequently used in UNIX machines, RMI (and CORBA) are its object-oriented counterparts. The concept of ``distributed programming'' has gotten very popular lately. In general, it means a very tight integration between programs across the network; objects in different machines can talk to each other simply by calling each other's methods. This is accomplished by having a Java program hold a ``stub'' of a remote object. Then, when a method is invoked on that stub, Java transparently sends the request over the network and returns the requested value. The extent by which distribution and serialization are embedded in Java show the advantage of a modern language designed to support these concepts.
Often programmers can get frustrated when they wish to use the benefits of Java to do something that is system dependant. The JNI allows you to interface with a native-shared object and run its functions. This means you can write system-dependant code in C (or any other language) and use it from Java. Of course, as a result, your program would not be portable unless you supply the shared object to all platforms. This could be useful, for example, to catch signals in UNIX and to access the registry in Windows.
Java Database Connectivity is an SQL database access interface. It provides a database-independent way to perform SQL queries on any database that provides JDBC drivers. Currently, many popular databases do, and those that don't can still be accessed via the JDBC-ODBC bridge, which allows you to use ODBC drivers instead. For a list of database drivers see: http://java.sun.com/products/jdbc/jdbc.drivers.html.
Take a good look at Java. If we could manage to separate the applications from the operating systems running them, we'd have the freedom to choose shich OS we like best. Although in spirit the Linux community has a ``renegade'' non-conformist element in it, Java has a great potential and deserves our attention. The Linux-Java combination can turn into a winning one.
Java home: "http://java.sun.com/
Java developer connection (free registration): http://java.sun.com/jdc/
Swing (JFC): http://java.sun.com/products/jfc/index.html
Java for Linux: http://www.blackdown.org/java-linux.html
You've heard all the hype, and decided to find out what this "Linux" thing is all about. Or maybe you need a low cost alternative to one of the commercial operating systems. Perhaps you need an easy way to connect diverse systems and let them all communicate with each other..tomorrow.. or you'll be encouraged to "seek new employment challenges." In any case, you have a problem that needs a solution, or a curiosity that needs to be satisfied. Well, you have come to the right place. Join me as we take a journey into the exciting world of the Linux operating system. Please keep your hands inside the car at all times, and remain in your seat.
Linux is a freely distributable version of Unix developed by Linus Torvalds and thousands of other programmers scattered all over the world. What started as a hacker's system, designed primarily for the technically adept, has now evolved in to a viable, stable operating system with a robust set of applications and tools making it suitable for both personal and mission critical commercial use.
In just the past six months Linux growth has undergone an exponential expansion. Every day Linux gains more and more press and exposure. Many commercial vendors are announcing support, or ports of their products to the Linux operating system. I saw just the other day that Oracle and Informix, both major players in the Unix database world, have ports to Linux underway.
This is incredibly significant, not just to the techno-geeks (yes, that's me) but to the entire spectrum of computer users. One of the benchmarks of the commercial viability of any product is the support of the application vendors.
While it's great fun for me to write my own programs and applications, most people just need to get some work done, on time, as easily as possible. Or perhaps you want to surf the net for entertainment, or playing games. Without the "killer apps", an operating system is doomed commercially.
What this all means to you is never before has there been an operating system, with a robust set of applications and development tools, available for little or no cost, other than the "sweat equity" required to learn to use it effectively.
An additional point to consider is that as you progress in your Linux education you are also increasing your skill level and, ultimately, your worth in the marketplace.
One of the strengths of Linux is that you have the power to choose the depth of knowledge required to accomplish your tasks. Want to just bang out a document or two, or play games? You can. Want to surf the Internet and exchange e-mail with your friends and coworker's? No problem. Want to learn to program in a variety of different languages? Go ahead.
The point here is Linux can do all these things, and much more. Additionally, with Linux, you are not required to fork over more money for each function you want to add.
While this was the case at one time, here and now, in 1998, it's simply not true. Major advancements have been made in the installation and configuration process, and in most cases Linux is no more difficult to install than any other operating system. With the advent of package managers, Graphical User Interfaces, and "smart" probing of your system's components, installation has become largely a moot issue.
The truth is, you could not have picked a better time to join the Linux world. Granted, once you get to networking issues, there is more to it in a Unix machine than a Windows box, but with the new configuration utilities, combined with an intuitive, easy to understand process, I firmly feel that Linux is about as easy to configure as Windows.
Luckily, there are commercial distributions of Linux available, as well as commercial support contractors who will be happy to help you out. And usually for quite a bit less than the people in Redmond, and the Linux vendors actually answer the phone. And call you back.
Now I'm going to tell you about Linux's secret weapon. Remember, those thousands of people I mentioned before? Well, there is a virtual universe, populated with people who are ready, willing, and able to help you out. You will find them on USENET, commonly called newsgroups, on Internet Relay Chat, commonly called IRC and in your local area, in the form of Linux User's Groups. As a matter of fact, this free noncommercial group of people have made such an impact on the end user community, that in an unprecedented move, Infoworld magazine named the Linux support community as a whole, as the 1997 Product of the Year!
The answer is a resounding yes! Linux will run on anything from a diskless workstation, to an XT, to the latest whizbang hardware. As a matter of fact, I've used these machines for everything from routers to web servers, from dialup servers to file servers. I currently run 2 486 66's as my backup DNS machines, each hosting multiple zones.
This is another one of Linux's strengths. The ability to take "obsolete" machines and do great things with them. This is a great low cost method for nonprofit organizations, and cost conscious organizations to squeeze extra value from "old" machines.
The one exception to this is your video subsystem. X, the Graphical User Interface , is very picky about the video cards it will and will not support. This is primarily due to the fact that many video card manufacturers are reluctant to release specification information to Linux developers.
However, support is improving every day, and there are also commercial X servers available to address these issues. The bottom line here is to try to make sure your video card is supported by X if you want to run more than VGA at 16 colors.
That said, different distributions of Linux have different hardware requirements. And of course, I don't mean to imply that you should not take advantage of a newer machine if you have access to one. I simply want to convey to you that you don't have to have a Pentium II with 256 Megs of RAM, or a 600Mhz Alpha to be able to use Linux.
As a general guideline, any 386 or better with 4MB of RAM or more should run quite nicely. If you plan on running X, 8MB would be better, 16MB better still.
Generally speaking, the more RAM, the better. As a matter of fact, I often tell my clients that I would rather have a slower processor with more RAM, than a faster processor with less RAM.
Contrary to what you may have been told, the processor speed is NOT the primary determining factor of performance. In reality the performance of your system is determined by the amount of RAM you have, The speed of your Disk subsystem, and your processor. In that order.
Any type of IDE HDD, and any ATAPI CD-ROM drive will work quite nicely, as will most SCSI hosts and disks. However, SCSI installations can often be more involved, and will be covered in a separate document.
The first thing you will need to do is pick a distribution. Linux is packaged as collections of programs, applications, utilities, and the operating system, by different people and vendors. These are called distributions. There are many, fine distributions out there, and choosing the "right" one is a nebulous process. This is somewhat analogous to picking the "best" vacation spot, or the "best" outfit to wear.
I will be discussing the Slackware 3.5, and RedHat 5.1, as these are the ones I am familiar with. Many of the descriptions and configuration options, most notably the autoprobing of PCI devices, and support for many newer video cards, are applicable ONLY to these distributions. All my comments and recommendations are just that - comments and recommendations. Your preferences may be entirely different.
Slackware 3.5
The first distribution I ever used, and still my favorite. It has the option for either a Command Line Interface (CLI) install, or a Graphical User Interface (GUI) install. Uses Tarballs, or .tgz package format. I like this because I am not "forced" to install X just to use my system like some of the other distributions ( see below.) I am also given more control over what does and does not get installed. (Upgrade path is not too good.) Best for people who want to really learn about how the system works, and like installing and compiling their own software. A full install will eat up ~400MB of disk space.
RedHat 5.1
This is the current "darling" of the commercial side of the Linux community. Probably the easiest to install. Forces the installation of the X window system, whether you want it or not. Uses the RPM package format to ensure all packages and programs are installed correctly (sort of.) Upgrade path is good. Currently has the lion's share of the media attention, and thus, application support. This is the one I recommend for people who want a working system quickly, and are less concerned about the internal workings of the Operating System. A full install will eat up ~600MB of disk space.
I had originally intended to do an in-depth comparison of the various distributions, but the August issue of the Linux Journal just arrived in my mailbox today, and I see that Phil has beat me to it. I respectfully disagree with regard to the Caldera Distribution. I am overwhelmed by it's cost, and underwhelmed by it's performance. Other than that, I would suggest you refer to his article for a more in-depth comparison. He has done an outstanding job, much better than I could have ever done.
Here you have several options. All the distributions I mention are freely available on the Internet for download. Additionally, RedHat, and Slackware are available for purchase, either directly from the manufacturers, or through third parties. Finally, some or all of them are often bundled with books on Linux or can be had at your local Linux User's Group's Install Party, an event where people bring in their computers and the hosts at your Linux users Group will install the software for you.
IMPORTANT NOTE: While it is possible to install some of these distributions using FTP or NFS, I strongly urge you to acquire a CD-ROM for your first installation. See the resources section at the end of this document for vendors, or check your local book store.
While an Install Party is probably the easiest method to get your system up and running, You will get more out of it by doing the installation yourself. Messing up, and doing it yourself is the best way to learn.
Excellent question. Here are some things to consider:
While it is possible and feasible to have multiple operating systems residing on one system, I recommend using a separate machine if possible, or at least a separate disk or disks on your machine just for Linux.
This will give you the confidence to bang away at it, install multiple times, and decrease the chance of harming your primary OS or data. Also, in later installments, I will show you how to make this machine do all kinds of neat tricks, like serve up your Internet connection, store files and applications, even become the starting point for your own home network.
Check around in the paper, your local Linux user group, your place of employment or even your local community college for one of those "old" machines. They can often be had at little or no cost.
What we are aiming for here is maximizing your chances for a successful installation, there will be plenty of time for you to learn the more esoteric methods as your Unix skills increase.
If at all possible try to get a separate machine, preferably with two Hard Disk Drives, and an ATAPI compliant CD-ROM.
If you absolutely must disregard my warnings, and intend to try out Linux on your primary machine, BACKUP ANYTHING YOU CAN NOT AFFORD TO LOSE ONTO FLOPPY DISK, TAPE, OR WHATEVER BACKUP DEVICE YOU PRESENTLY USE. IF YOU DON'T HAVE ONE, PUT THIS DOWN AND GO GET ONE! YOU HAVE BEEN WARNED. Consider the Slackware distribution. It offers the option of running directly off of the CD-ROM.
If you have not acquired a separate machine, refer to the warning above. BACKUP ANYTHING YOU CANNOT AFFORD TO LOSE.
The first thing you will need to do is create your boot disk, and in some cases, a root or supplemental disk.
If you purchased the commercial distribution of RedHat, the required disks should already be included. The commercial version of Slackware should be bootable directly from the CD-ROM on newer systems.
If you obtained the software bundled with a book, you will probably need to create the disk or disks yourself.
You will need one or two DOS formatted disks for this.
What boot image you need will depend on which distribution you are installing.
For RedHat, look for the /images directory, which should contain two files named boot.img and supp.img. Normally only the boot.img disk will be required.
For Slackware, look for a directory called /bootdsks.144, and another called /rootdsks. Unless you have something other than IDE devices in your machine, the bare.i image is the one you will be looking for as your boot disk. In the rootdsks directory, you will need the color.gz image for your root disk.
The method used for creating your boot and/or root disks will depend on whether you are using a Linux (or Unix) machine, or a DOS based machine.
If you are on a DOS based machine, I.E. Windows 3.x, Windows 95, Windows 98 or Windows NT, you will need to use RAWRITE.EXE to create your images. This program should be included either in the same place as the images we just discussed, or under an /install, or /dosutils directory in some cases.
You will need to open a command prompt (sometimes called a DOS box) on your machine, or exit windows to get to the command prompt.
Then type: RAWRITE <enter> You will be asked for the source file name:bare.i <enter>
You will next be asked for your target drive: A: <enter>
If the program errors out, and complains about "Attempting to DMA across 64k boundary," FTP to sunsite.unc.edu, then cd to:
/pub/Linux/distributions/redhat/redhat-5.1/i386/dosutils/
And retrieve the version of RAWRITE there. It will be smaller than the one you were using (~14k,) and the problem should go away. As I recall this is only an issue on NT and possibly Windows 98 boxes.
If you are on a Linux or Unix box, the command to get it done is:
dd if=<your boot or root image> of=<where to write it to> bs=1440kSo, if you are making a Slackware boot disk:
dd if=bare.i of=/dev/fd0 bs=1440k <:enter>For the root disk:
dd if=color.gz of=/dev/fd0 bs=1440k <enter>
Now insert the boot disk into your floppy drive and re-boot your machine.
At this point, you will be prompted to login as root. After you login, you must partition your disk or disks to prepare the HDD for formatting, and ultimately, the installation of your software.
Linux requires at least two partitions for installation. You must have a partition for your root or top level directory to live in, and you also need a partition for your swap file to live in.
This is just a fancy way of saying you need at least one place on your hard drive to store your operating system, and one place on your hard drive to be used as a temporary storage area for your operating system to put things that are not immediately needed.
If you are familiar with a Windows based system, the root partition is the equivalent of your C:\ drive, and the swap file is the equivalent of your pagefile.sys.
Just as it is always a good idea on a Windows box to store your data on a separate device, apart from the operating system, the same rule applies to Linux. This is why I urge you to have two HDD's in your Linux machine.
Depending on which distribution you choose, the process required to create the necessary partitions will vary. Similarly, whether you have one or two HDD's will also make the best partitioning scheme vary.
Slackware:
Use the cfdisk utility. It is fairly easy to understand, and has decent help.
RedHat:
You will probably want to use Disk Druid here.
For a single disk system, I would suggest two partitions:
One swap partition, between 16 and 32MB in size, depending on how much RAM you have in your machine. The utility you are using, may or may not ask you to specify the hex code to tell Linux that this is a swap partition. If prompted for it, the proper code is type 82.
The rest of the disk should be partitioned as Linux native.
Some might argue that there should be three partitions here, in case something goes wrong with the root partition, thus saving your data. I have rarely seen a disk fail in just "spots", usually if a disk commits suicide it's an all or nothing kind of deal.
I recommend two disks for precisely this sort of situation. The only time I have ever seen two disks fail at once was due to a lightening strike, which smoked the whole machine.
For a two disk system, I would suggest the following:
On the primary or first HDD (usually called hda in most distributions:)
Create two partitions, as stated above.
On the second HDD or secondary IDE interface:
Another swap partition of 16 or 32MB as above.
The rest of the drive should be partitioned Linux native.
After partitioning the disk or disks, you will be prompted to format them.
Depending on the distribution used, at some point you will be asked where you want the Linux native partition or partitions to be mounted. This simply is asking you where in the filesystem hierarchy each formatted partition should reside.
For single disk systems, mount your single Linux native partition as your root, or / partition.
For two disk systems, mount your first disk as described above, then mount the Linux native partition on your second drive as your /home directory. This will be where all of your user specific information and files will be stored, thus preventing an OS failure from taking all your hard work and critical data with it.
THIS IS INTENDED TO COMPLEMENT, NOT REPLACE A DILIGENT, REGULAR BACKUP SCHEME. I CAN'T STRESS ENOUGH THE IMPORTANCE OF REGULAR, RELIABLE BACKUPS.
If I seem to be a bit paranoid about backups, I proudly state that I am. I cannot begin to count the times my clients, friends and coworkers have snickered, giggled, and laughed outright when I talk about this. I am a constant source of jokes and entertainment for them. Until something goes wrong. Then I am suddenly a savior to them.
By the way, when something like this happens to you, and it will, when all the suits are sweating bullets, and looking to you like Moses with the backup tablets in each hand, this is a great time for salary negotiation.
You have, with one notable exception, four possible choices for your Linux installation. I will list them in order, from the smallest to the largest. EXCEPTION - Option one, running directly off of the CD-ROM is not available with the RedHat Distribution.
1. Running directly off of the CD-ROM, called a "live" filesystem.
This is the best option for just trying out Linux with a minimum impact to your present system. Performance will be degraded, particularly if you have a slow CD-ROM. This is the ONLY option I can safely recommend if you are not doing this on a machine other than your primary system.
The exact actions required to accomplish this will vary between the distributions, but will be called something like "run from CD-ROM", or "run from live filesystem"
2. A minimal, or base installation, with just enough stuff to get you up and running.
Slackware:
Select the following disk series:
A
AP (optional)
RedHat:
You can safely accept the defaults. (Not much choice here, accept the default, or it won't boot. You will be assimilated ;-).
3. A well rounded installation, consisting of the base stuff, plus some productivity, network, and development tools
Slackware:
Select the following disk series:
A
AP
F
D
N
X
XAP
RedHat:
To the default selections, add:
X applications
Development tools
4. The entire distribution, sometimes called the "let's see how much this sucker can take" installation.
Slackware:
Select the top option, "complete installation"
RedHat:
Select the "Everything" option.
A couple of suggestions concerning the everything install:
Below the dialog box where you chose "Everything", there will be another box with the phrase "Choose individual packages." Select it.
You will then be taken to another dialog box listing the categories of all the software that will be installed on the system. Scroll down to Documentation.
For some reason RedHat wants to install the How-To's and things in every format known to man, and in every language spoken by man.
Choose the text format and html format of the documents. The one exception to this is if for whatever reason, you would find it useful to have these documents in another language, in which case you should select the appropriate language desired as well. When you are finished, select done. This will save you a significant amount of disk space.
Common to both of the distributions, the following tasks are ones you need to perform regardless of which distribution you use:
Slackware:
Toward the end of the installation process, you will be asked to configure your new Linux system. I strongly recommend making both a lilo bootdisk, and a default, or vmlinuz bootdisk for your new machine, and choosing NO to the install LILO option.
RedHat:
Toward the end of the installation, you will be asked if you want to make a boot disk. Answer yes. Make several.
If prompted to configure either X windows, or your networking, answer no. If you are forced to do either of these things for X, accept the defaults. For networking, if asked for a network address, use 127.0.0.1, or choose the "loopback" option if available. We will be configuring these things in the next installment.
While there are times when it will be useful to be logged into your system as root, most of the time, you will want to be logged in to your own account on the machine.
There are many reasons for this, not the least of which is that when logged in as yourself, just about the worst thing you can do is screw up your own account.
However, when logged in as root, most of the safeguards built into the system go away. You can do anything, even things you should not do. Like hose the entire filesystem. This is both the strength, and the weakness of the superuser account.
Treat it like a loaded gun. Don't pull it out unless you mean to use it. If you mean to use it make sure you have a clear target and put it right back in the holster as soon as you're done.
Now that I hope I've properly scared you, here's what you need to do:
Login as root. Then create a user account for yourself:
adduser rjenkinsYou will be asked a series of questions. You can safely press enter to accept the defaults for these things.
Now you need to password protect the root account and your user account. Logged in as root, use the passwd command to do this for both the root or superuser account, and your personal account.
passwd rootAnd then your user account:
passwd rjenkinsA short comment on password selection and security. Good password discipline is very important, whether you are connected to a network or not. Briefly, here are a few guidelines:
Choose something you can easily remember, say kibble.
Now, add a punctuation mark and a number to it, say ?kibble4.
Finally, for best security, a neat trick is to take the word you can remember easily, in this case kibble, and for each letter in the word, move up one row on the keyboard, and over either to the left or the right.
So for ?kibble4 if we move up and to the left, we get: ?u8ggi34.
If we go up and to the right we get: ?o9hhp44.
This is easy to remember, and will defeat all but the most sophisticated password cracking programs.
The first thing you will want to do is learn how to navigate your system. You will find a wealth of documentation in the /usr/doc directory. In particular, look at the /usr/doc/how-to directory, and check out the installation and user's guide.
If you purchased your CD bundled with a book, make use of it. There should be enough information there, or in the doc directory to get you started.
While the editors and document tools available will vary from distribution to distribution, every distribution should have vi available. You will probably either learn to love or hate it. There does not seem to be any middle ground, but I suggest you at least learn to use it, since it will allow you to plunk down at any Unix machine and use it.
Much abbreviated, here's a short list of relevant commands:
To open a file:
vi filename
To insert text in a file:
Press the i key to enter insert mode, then enter your text.
To write your changes to a file:
Press the escape <Esc> key, then :w <:enter>
To close a file:
Press the escape <Esc> key, then :q <enter>
An even better option is to use the Midnight Commander, if it is available on your system. Simply enter mc.
It looks and acts a lot like the N*rton Commander, and makes an easy transition for anyone who has used that program, or is familiar with the DOSSHELL.
Well, that's about it for now, Congratulations! See, that wasn't so hard now was it? In the next installment, we'll configure the X windowing system and your networking setup.
Software Manufacturers:
RedHat Linux: http://www.redhat.com/
Slackware: http://www.cdrom.com/
Third Party Distributors:
http://www.cheapbytes.com
http://www.linuxmall.com
http://www.infomagic.com/
http://www.cdrom.com
Local User Groups:
Most areas have several local computer-oriented publications available.
Have a look for a local user group in your area. There are also list of
user groups by area at
http://www.ssc.com/glue/groups/
I have purchased a K6-2/266Mhz processor and a Soyo 5EHM Super7 motherboard specifically so that I would be able to benchmark the K6-2 against Intel PII and Cyrix processors. Since I have been running Linux since the v0.10 days, I thought it would be useful to perform some benchmarks under Linux. Here are my findings.
As I have time (and access to equipment) to add additional results, I will update this page. Soon I hope to add PII results (ABIT LX6, 64Mb 10ns Hyundai SDRAM, Riva 128, same 1.6Gb WD hard drive).
| PR Rating | Voltage | Setting | BogoM | User | System | Elapsed | CPU util |
| PR200 | 2.9 | 2.5X66 | 166.30 | 283.22 | 21.26 | 5:28.56 | 92% |
| PR233 | 2.9 | 2X100 | 199.88 | 236.4 | 17.48 | 4:35.97 | 91% |
| PR233 | 2.9 | 2.5X75 | 187.19 | 257.99 | 20.17 | 5:01.32 | 92% |
| PR266 | 2.9 | 2.5X83 | 207.67 | 233.75 | 19.51 | 4:35.40 | 91% |
| PR Rating | Voltage | Setting | BogoM | User | System | Elapsed | CPU util |
| 166 | 2.3 | 2.5x66 | 332.60 | 274.57 | 24.11 | 5:22.43 | 92% |
| 187.5 | 2.2 | 2.5x75 | 374.37 | 244.5 | 20.38 | 4:47.52 | 92% |
| 200 | 2.3 | 3x66 | 398.95 | 242.10 | 21.42 | 4:37.33 | 91% |
| 210 | 2.2 | 2.5x83 | 415.33 | 221.5 | 19.96 | 4:18.61 | 93% |
| 233 | 2.3 | 3.5x66 | 465 | 220.53 | 19.55 | 4:24.61 | 90% |
| 250 | 2.2 | 2.5x100 | 499.71 | 183.13 | 17.64 | 3:43.42 | 89% |
| 266 | 2.3 | 4x66 | 530.84 | 199.90 | 19.55 | 4:04.19 | 89% |
| 280 | 2.2 | 2.5x112 | 558.69 | 164.17 | 15.29 | 3:23.83 | 88% |
| 300 | 2.3 | 4.5x66 | 598.02 | 187.84 | 19.63 | 3:51.50 | 89% |
| 300 | 2.3 | 4x75 | 598.02 | 176.94 | 19.26 | 3:37.84 | 90% |
| 300 | 2.3 | 3x100 | 599.65 | 161.73 | 15.06 | 3:20.87 | 88% |
| PR Rating | Voltage | Setting | BogoM | User | System | Elapsed | CPU util |
| 233 | Default | 3.5x66 | 233.47 | 197.46 | 15.25 | 3:57.26 | 89% |
| 262.5 | Default | 3.5x75 | 262.14 | 180.75 | 12.73 | 3:38.96 | 88% |
| 291.7 | Default | 3.5x83 | 291.64 | 157.49 | 11.69 | 3:12.69 | 87% |
| PR Rating | Voltage | Setting | BogoM | User | System | Elapsed | CPU util |
| 233 | Default | 3.5x66 | 233.47 | 324.07 | 20.19 | 6:08.43 | 93% |
| 262.5 | Default | 3.5x75 | 262.14 | 291.43 | 16.96 | 5:32.61 | 92% |
| 291.7 | Default | 3.5x83 | 291.64 | 262.19 | 16.10 | 5:02.45 | 92% |
Please note, in the comparisons below, only the "User" time of the kernel compilations is used.
BogoMips is equivalent to the megahertz it is running at, and the AMD K6-2 has a BogoMips rating that is twice the megahertz it is run at.In order to be able to make a direct, Mhz-to-Mhz comparison of the processors, I underclocked the K6-2 to run at 2.5x75 (Cyrix PR233 rating) and 2.5x83 (PR266 rating). Comparing the total elapsed time for the compilation, we find that:
| CPU | Cyrix | Amd | Amd % faster |
| 2.5x75 | 257.99 | 244.5 | 5.23% |
| 2.5x83 | 233.75 | 221.5 | 5.24% |
The AMD K6-2 processor seems to be 5.25% faster than a Cyrix MX processor at the same clock speed. The PR rating system would not seem to apply to Linux kernel compilations.
| CPU | Cyrix | Amd | Amd % faster |
| PR233 | 257.99 | 220.53 | 14.52% |
| PR266 | 233.75 | 199.90 | 14.48% |
The AMD K6-2 is 14.5% faster than a Cyrix/IBM 686MX when comparing a K6-2 at the same Mhz as a Cyrix chip is PR rated for.
I wanted to see how the P2 would compare to the K6-2. As I only have a P2-233, I had to overclock it to approach 300Mhz. Please note, I used an extra 3" fan blowing air at the CPU.
| CPU | P2 | Amd | P2 % faster |
| 266Mhz #1 | 180.75 | 183.13 | 1.3% |
| 300Mhz #2 | 157.49 | 161.71 | 2.6% |
NOTES
The P2 was faster for compiling the kernel by less than three percent. There is no point in comparing the K6-2 to the Celeron - see the simulated Celeron benchmarks on the previous page. The Celeron is not suitable for use as a Linux development machine.
As we all know, absolute performance is just part of deciding which processor to get. If cost was no object, we would all be running Kryotech Alpha 767's, or dual PII-400's. For reference purposes, here are some prices, in US$, as 1:14pm PST of July 5 from PriceWatch.
| CPU | 233 | 266 | 300 |
| Cyrix | $49 | $74 | $96 |
| AMD K6-2 | n/a | $113 | $163 |
| AMD K6 | $68 | $93 | $125 |
| Pentium II | $158 | $177 | $235 |
There is no question that the Cyrix processors provide excellent performance for a low cost. The K6 (non-3d) processors are also an excellent value, however as I don't have such a CPU I was unable to run tests on one - but I would expect that on the same motherboard with similar memory and hard disk the performance of the plain K6's would be very close to the K6-2's.
The K6-2 appears to be an excellent value for a developer's machine. A 14.5% increase in speed over the 686MX is difficult to ignore. The P2 is less than three percent faster than the K6-2 at comparable speeds. I do not think that such a small difference in speed justifies the price differential between the P2 and the K6-2.
I hope you found this article to be of use. Please remember that I welcome feedback on this (or other) articles. I can be contacted at editor@cpureview.com.
Regards,
William Henning
A Linux Journal Review: This article appeared in the November 1997 issue of Linux Journal.
Linux is many users' introduction to a truly powerful, configurable operating system. In the past, a Unix-like operating system was out of reach for most. If it wasn't the operating system's 4-digit price tag, it was the hardware. Even the now free-for-personal-use SCO Unixware requires a system with SCSI drives, and most of us are using IDE to keep costs down. Along with the power that Linux brings comes the need to perform a task users have not had to do on simpler operating systems: configure the kernel to your hardware and operations.
Previous installation kernels from 1.2.x and before suggested that you rebuild; however, with the new 2.0.x kernel, rebuilding has almost become a necessity. The kernel that comes with the installation packages from Red Hat, Caldera, Debian and most others, is a generic, ``almost everything is included'' kernel. While rebuilding a kernel may seem like a daunting task and living with the installed kernel may not be too bad, rebuilding is a good introduction to your system.
The standard installation kernels are an attempt to make as many systems as possible usable for the task of installing a workable Linux system. As such, the kernel is bloated and has a lot of unnecessary code in it for the average machine. It also does not have some code a lot of users want.
Then, of course, there's always the need to upgrade the kernel because you've bought new hardware, etc. Upgrading within a series is usually very straightforward. When it comes to upgrading, say from 1.2.something to 2.0.something, now the task is beyond the scope of this article and requires some savvy. Better to get a new distribution CD and start fresh--this is also true for upgrading to the experimental 2.1.x kernels.
All Linux kernel version numbers contain three numbers separated by periods (dots). The first number is the kernel version. We are now on the third kernel version, 2. Some of you may be running a version 1 kernel, and I am aware of at least one running version 0 kernel.
The second number is the kernel major number. Major numbers which are even numbers (0 is considered an even number) are said to be stable. That is, these kernels should not have any crippling bugs, as they have been fairly heavily tested. While some contain small bugs, they can usually be upgraded for hardware compatibility or to armor the kernel against system crackers. For example, kernel 2.0.30, shunned by some in favor of 2.0.29 because of reported bugs, contains several patches including one to protect against SYN denial of service attacks. The kernels with odd major numbers are developmental kernels. These have not been tested and often as not will break any software packages you may be running. Occasionally, one works well enough that it will be adopted by users needing the latest and greatest support before the next stable release. This is the exception rather than the rule, and it requires substantial changes to a system.
The last number is the minor number and is increased by one for each release. If you see kernel version 2.0.8, you know it's a kernel 2.0, stable kernel, and it is the ninth release (we begin counting with 0).
I hate to make any assumptions; they always seem to come back to bite me. So I need to mention a few things so that we're working off the same sheet of music. In order to compile a kernel, you'll need a few things. First, I'll assume you've installed a distribution with a 2.0.x kernel, all the base packages and perhaps a few more. You'll also need to have installed gcc version 2.7 and all the supporting gcc libraries. You'll also need the libc-dev library and the binutils and bin86 packages (normally installed as part of a standard distribution install). If you download the source or copy it from a CD, you'll also need the tar and gunzip packages. Also, you'll need lots of disk real estate. Plan on 7MB to download, another 20MB to unpack this monster and a few more to compile it.
Needless to say, many of the things we will discuss require you to be logged in as root. If you've downloaded the kernel as a non-privileged user and you have write permission to the /usr/src subdirectory, you can still do much of this task without becoming root. For the newcomers to Linux, I highly recommend you do as much as possible as a non-privileged user and become root (type: su - face) only for those jobs that require it. One day, you'll be glad you acquired this habit. Remember, there are two kinds of systems administrators, those who have totally wrecked a running setup inadvertently while logged in as root, and those who will.
Kernel sources for Linux are available from a large number of ftp sites and on almost every Linux distribution CD-ROM. For starters, you can go to ftp.funet.fi, the primary site for the Linux kernel. This site has a list of mirror sites from which you can download the kernel. Choosing the site nearest you helps decrease overall Internet traffic.
Once you've obtained the source, put it in the /usr/src directory. Create a subdirectory to hold the source files once they are unpacked using tar. I recommend naming the directories something like linux-2.0.30 or kernel-2.0.30, substituting your version numbers. Create a link to this subdirectory called linux using the following command:
ln -sf linux-2.0.30 linuxI included the -f in the link command because if you already have a kernel source in /usr/src, it will contain this link too, and we want to force it to look in our subdirectory. (On some versions of ln (notably version 3.13), the force option (-f) does not work. You'll have to first remove the link then establish it again. This works correctly by version 3.16.) The only time you may have a problem is if linux is a subdirectory name, not a link. If you have this problem, you'll have to rename the subdirectory before continuing:
mv linux linux-2.0.8Now issue the command:
tar xzvf linux-kernel-source.tar.gzI have a habit of always including w (wait for confirmation) in the tar option string, then when I see that the .tar.gz or .tgz file is going to unpack into its own subdirectory, I ctrl-C out and reissue the command without the w. This way I can prevent corrupted archives from unpacking into the current directory.
Once you have the kernel unpacked, if you have any patches you wish to apply, now is a good time. Let's say you don't wish to run kernel 2.0.30, but you do want the tcp-syn-cookies. Copy the patch (called tcp-syn-cookies-patch-1) into the /usr/src directory and issue the command:
patch < tcp-syn-cookies-patch-1This command applies the patch to the kernel. Look for files with an .rej extension in in the /usr/src directory. These files didn't patch properly. They may be unimportant, but peruse them anyway. If you installed a Red Hat system with some but not all of the kernel source (SPARC, PowerPC, etc.), you'll see some of these files. As long as they're not for your architecture, you're okay.
As a final note, before we change (cd) into the kernel source directory and start building our new kernel, let's check some links that are needed. In your /usr/include directory, make sure you have the following soft links:
asm - /usr/src/linux/include/asm linux - /usr/src/linux/include/linux scsi - /usr/src/linux/include/scsiNow, you see another reason to standardize the location of the kernel. If you don't put the latest kernel you wish to install in /usr/src/linux (via a link), the above links will not reach their intended target (dangling links), and the kernel may fail to compile.
Once everything else is set up, change directories into /usr/src/linux. Although you may want to stop off and peruse some of the documentation in the Documentation directory, particularly if you have any special hardware needs. Also, several of the CD-ROM drivers need to be built with customized settings. While they usually work as is, these drivers may give warning messages when loaded. If this doesn't bother you and they work as they should, don't worry. Otherwise, read the appropriate .txt, .h (header) files and .c (c code) files. For the most part, I have found them to be well commented and easy to configure. If you don't feel brave, you don't have to do it. Just remember you can always restore the original file by unpacking the gzipped tar file (or reinstalling the .rpm files) again.
The first command I recommend you issue is:
make mrproperWhile this command is not necessary when the kernel source is in pristine condition, it is a good habit to cultivate. This command ensures that old object files are not littering the source tree and are not used or in the way.
Now, you're ready to configure the kernel. Before starting, you'll need to understand a little about modules. Think of a module as something you can plug into the kernel for a special purpose. If you have a small network at home and sometimes want to use it (but not always), maybe you'll want to compile your Ethernet card as a module. To use the module, the machine must be running and have access to the /lib/modules This means that the drive (IDE, SCSI, etc., but could be an ethernet card in the case of nfs), the file system (normally ext2 but could be nfs) and the kernel type (hopefully elf) must be compiled in and cannot be modules. Modules aren't available until the kernel is loaded, the drive (or network) accessed, and the file system mounted. These files must be compiled into the kernel or it will not be able to mount the root partition. If you're mounting the root partition over the network, you'll need the network file system module, and your Ethernet card compiled.
Why use modules? Modules make the kernel smaller. This reduces the amount of protected space never given up by the kernel. Modules load and unload and that memory can be reallocated. If you use a module more than about 90% of the time the machine is up, compile it. Using a module in this case can be wasteful of memory, because while the module takes up the same amount of memory as if it were compiled, the kernel needs a little more code to have a hook for the module. Remember, the kernel runs in protected space, but the modules don't. That said, I don't often follow my own advice. I compile in: ext2, IDE and elf support only. While I use an Ethernet card almost all the time, I compile everything else as modules: a.out, java, floppy, iso9660, msdos, minix, vfat, smb, nfs, smc-ultra (Ethernet card), serial, printer, sound, ppp, etc. Many of these only run for a few minutes at a time here and there.
The next step is to configure the kernel. Here we have three choices--while all do the same thing, I recommend using one of the graphical methods. The old way was to simply type: make config. This begins a long series of questions. However, if you make a mistake, your only option is to press ctrl-C and begin again. You also can't go back in the sequence, and some questions depend on previous answers. If for some reason you absolutely can't use either of the graphical methods, be my guest.
I recommend using either make menuconfig or make xconfig. In order to use menuconfig, you must have installed the ncurses-dev and the tk4-dev libraries. If you didn't install them and you don't want to use the next method, I highly recommend that you install them now. You can always uninstall them later.
To run make xconfig, you must install and configure X. Since X is such a memory hog, I install, configure and startx only for this portion of the process, going back to a console while the kernel compiles so it can have all the memory it needs. The xconfig menu is, in my opinion, the best and easiest way to configure the kernel. Under menuconfig, if you disable an option, any subordinate options are not shown. Under xconfig, if you disable an option, subordinate options still show, they are just greyed out. I like this because I can see what's been added since the last kernel. I may want to enable an option to get one of the new sub-options in order to to experiment with it.
I'm going to take some space here to describe the sections in the kernel configuration and tell you some of the things I've discovered--mostly the hard way.
The first section is the code-maturity-level option. The only question is whether you want to use developmental drivers and code. You may not have a choice if you have some bleeding edge hardware. If you choose ``no'', the experimental code is greyed out or not shown. If you use this kernel for commercial production purposes, you'll probably want to choose ``no''.
The second section concerns modules. If you want modules, choose ``yes'' for questions 1 and 3. If you want to use proprietary modules that come with certain distributions, such as Caldera's OpenLinux for their Netware support, also answer ``yes'' to the second question since you won't be able to recompile the module.
The third section is general setup. Do compile the kernel as ELF and compile support for ELF binaries. Not compiling the proper support is a definite ``gotcha''. You'll get more efficient code compiling the kernel for the machine's specific architecture (Pentium or 486), but a 386 kernel will run in any 32-bit Intel compatible clone; a Pentium kernel won't. An emergency boot disk for a large number of computers (as well as distribution install disks) is best compiled as a 386. However, a 386 will not run a kernel compiled for a Pentium.
Next comes block devices--nothing special here. If your root device is on an IDE drive, just make sure you compile it.
Then comes networking. For computers not connected to a network, you won't need much here unless you plan to use one computer to dial-out while others connect through it. In this case, you'll need to read up on such things as masquerading and follow the suggested guidelines.
SCSI support is next, though why it doesn't directly follow block devices I don't know. If your root partition is on a SCSI device, don't choose modules for SCSI support.
SCSI low-level drivers follow general SCSI support. Again, modules only for devices that don't contain the root partition.
The next section takes us back to networking again. Expect to do a lot of looking for your particular card here as well as some other support such as ppp, slip, etc. If you use nfs to mount your root device, compile in Ethernet support.
For those lucky enough to be needing ISDN support, the ISDN subsection will need to be completed.
Older CD-ROMs may require support from the next section. If you're using a SCSI or IDE CD-ROM, you can skip this one.
Next comes file systems. Again, compile what you need, in most cases ext2 and use modules for the rest.
Character devices are chosen next. Non-serial mice, like the PS/2 mouse are supported. Look on the bottom of your mouse. Many two-button mice are PS/2 type, even though they look and connect like serial mice. You'll almost certainly want serial support (generic) as a minimum. Generic printer support is also listed here.
The penultimate section is often the most troubling: sound. Choose carefully from the list and read the available help. Make sure you've chosen the correct I/O base and IRQs for your card. The MPU I/O base for a SoundBlaster card is listed as 0. This is normally 330 and your sound module will complain if this value is incorrect. Don't worry. One of the nice things about modules is you can recompile and reinstall the modules as long as the kernel was compiled with the hook. (Aren't modules great?).
The final section contains one question that should probably be answered as ``no, kernel hacking''.
Save your configuration and exit.
I have, on several occasions, had trouble editing the numbers in menuconfig or xconfig to values I knew were correct. For whatever reason, I couldn't change the number or config wouldn't accept the number, telling me it was invalid. For example, changing the SoundBlaster IRQ from the config default of 7 to 5, and the MPU base I/O from 0 to 300. If you experience this problem, but everything else went well, don't despair. The file you just wrote when you did a ``Save'' and ``Exit'' is an editable text file. You may use your text editor of choice: Emacs, vi, CrispLite, joe, etc. Your configuration file is in the /usr/src/linux directory and is called .config. The leading dot causes the file to be hidden during a normal directory listing (ls), but it shows up when the -a option is specified. Just edit the numbers in this file that you had trouble with in the configuration process. Next, type make dep to propagate your configurations from the .config file to the proper subdirectories and to complete the setup. Finally, type make clean to prepare for the final kernel build.
We're now ready to begin building the kernel. There are several options for accomplishing this task:
For those of you who wish to speed up the process and won't be doing other things (such as configuring other applications), I suggest you look at the man page for make and try out the -j option (perhaps with a limit like 5) and also the -l option.
If you chose modules during the configuration process, you'll want to issue the commands:
make modules make modules_installto put the modules in their default location of /lib/modules/2.0.x/, x being the kernel minor number. If you already have this subdirectory and it has subdirectories such as block, net, scsi, cdrom, etc., you may want to remove 2.0.x and everything below it unless you have some proprietary modules installed, in which case don't remove it. When the modules are installed, the subdirectories are created and populated.
You could just as easily have combined the last three commands:
make zImage; make modules; make modules_installthen returned after all the disk churning finished. The ; (semicolon) character separates sequential commands on one line and performs each command in order so that you don't have to wait around just to issue the next command.
Once your kernel is built and your modules installed, we have a few more items to take care of. First, copy your kernel to the root (or /boot/ or /etc/, if you wish):
cp /usr/src/linux/arch/i386/boot/zImage /zImageYou should also copy the /usr/src/linux/System.map file to the same directory as the kernel image. Then change (cd) to the /etc directory to configure LILO. This is a very important step. If we don't install a pointer to the new kernel, it won't boot. Normally, an install kernel is called vmlinuz. Old-time Unix users will recognize the construction of this name. The trailing ``z'' means the image is compressed. The ``v'' and ``m'' also have significance and mean ``virtual'' and ``sticky'' respectively and pertain to memory and disk management. I suggest you leave the vmlinuz kernel in place, since you know it works.
Edit the /etc/lilo.conf file to add your new kernel. Use the lines from the image=/vmlinuz line to the next image= line or the end. Duplicate what you see, then change the first line to image=/zImage (assuming your kernel is in the root directory) and choose a different name for the label=. The first image in the file is the default, others will have to be specified on the command line in order to boot them. Save the file and type:
liloYou will now see the kernel labels, and the first one will have an asterisk. If you don't see the label that you gave your new kernel or LILO terminates with an error, you'll need to redo your work in /etc/lilo.conf (see LILO man pages).
We're almost ready to reboot. At this point, if you know your system will only require one reboot to run properly, you might want to issue the command:
depmod -a 2.0.xwhere x is the minor number of the kernel you just built. This command creates the dependencies file some modules need. You'll also want to make sure you don't boot directly into xdm. For Red Hat type systems, this means ensuring the /etc/inittab file doesn't have a default run level of 5, or that you remember to pass LILO the run level at boot time. For Debian systems, you can just type:
mv /etc/init.d/xdm /etc/init.d/xdm.origfor now and move it back later.
Reboot your machine using:
shutdown -r nowWhile typing reboot or pressing the ctrl+alt+del key combination usually works, I don't recommend either one. Under some circumstances, the file systems won't be properly unmounted and could corrupt open files. At the LILO prompt, if you need to boot the old kernel or pass some parameters for bootup and you don't see the boot: prompt, you can try pressing either the shift or ctrl key, and the boot: prompt should appear. Once you have it, press tab to see the available kernel labels. Type the label and optionally enter any parameters for bootup. Normally, however, the default kernel should boot automatically after the timeout interval specified in the /etc/lilo.conf file. During bootup, you may see a few error messages containing: SIOCADDR or the like. These usually indicate that a module (normally a network module) didn't load. We'll handle this shortly. If you got the error, ``VFS, cannot mount root'', you didn't compile the proper disk or file-system support into the kernel.
Due to the different ways in which each distribution handles daemon startup from /etc/inittab, it is difficult in this article to cover all the possible reasons your bootup may not have gone smoothly and the reasons why. However, I can tell you where to start looking.
First, run depmod -a to ensure you have an up-to-date, module dependency file (it will be created in the appropriate subdirectory). If you get a string of errors about unresolved dependencies, old modules are present in the modules subdirectories, and you didn't configure the kernel with ``Module Versions'' enabled. This is not a fatal error. The modules you compiled and installed are good. Check the /etc/conf.modules file and make sure that any lines pointing to /lib/modules are complete:
/lib/modules/`uname -r`/xx(Note: the grave quote on each side of uname -r is located above the Tab key in the upper left corner of the keyboard on a U.S. keyboard).
Make sure kerneld is running and that it is loaded early in the bootup process. If it is, then the system doesn't need to explicitly load modules, kerneld will handle it. Be careful about calling kerneld too early in the first rc script. kerneld will stop the bootup process forcing a hard reboot via the reset button or power switch, if it is called before the system knows its host name. If this happens to you, you can reboot passing LILO the -b argument which prevents init from executing any rc scripts. Next, look in /etc/rc.d/ at the rc, rc.sysinit and rc.modules files. One or more may point to a directory such as /etc/modules/`uname -r`/`uname -v` where a list of bootup modules are located. You can just copy the old file over to the new directory;
mkdir /etc/modules/`uname -r` ; cp /etc/modules/2.0.xx/g#1 Thu 3 Sep 1997.\ default /etc/modules/`uname -r`/\ `uname -v`.default""Your system will almost certainly have a different date for the modules file. Your system also may or may not use the default extension. Pay close attention to the use of grave quotes and double quotes in the above example, since both are needed in the proper places. Once you have found the keys to your system, you should be able to reboot into a properly functioning system. If you experience further problems, the best place to get quick, expert advice is on a mailing list dedicated to your particular distribution. Those successfully running a particular distribution usually delight in assisting novices with problems they may encounter. Why? Because they hit the same brick walls when they were novices and received help with many problems. Lurk a few days on a list, and if your question isn't asked by someone else, ask it yourself. Check the mail-list archives first, if any are present. These archives contain answers to frequently asked questions (FAQ).
While building a kernel tailored to your system may seem a daunting challenge for new administrators, the time spent is worth it. Your system will run more efficiently, and more importantly, you will have the satisfaction of building it yourself.
The few areas where you may encounter trouble are in remembering to rerun LILO after installing the new kernel, but you didn't overwrite your old one (or did you?), so you can always revert to one that worked from the lilo: prompt. Distribution specific problems during bootup may also be encountered during the first reboot but are usually easily resolved. Help is normally only an e-mail away for those distributions that don't come with technical support.
The aim of this article is to introduce new Linux users to an invaluable resource, Larry Wall's patch program. Patch is an interface to the GNU diff utility, which is used to find differences between files; diff has a multitude of options, but it's most often used to generate a file which lists lines which have been changed, showing both the original and changed lines and ignoring lines which have remained the same. Patch is typically used to update a directory of source code files to a newer version, obviating the need to download an entire new source archive. Downloading a patch in effect is just downloading the lines which have been changed.
Patch originated in the nascent, bandwidth-constrained internet environment of a decade ago, but like many Unix tools of that era it is still much-used today. In the February issue of the programmer's magazine Dr. Dobb's Journal Larry Wall had some interesting comments on the early days of patch:
DDJ: By the way, what came first, patch or diff? LW: diff, by a long ways. patch is one of those things that, in retrospect, I was totally amazed that nobody had thought of it sooner, because I think that diff predated patch by at least ten years or so. I think I know why, though. And it's one of these little psychological things. When they made diff, they added an option called -e, I think it was, and that would spit out an ed script, so people said to themselves, "Well, if I wanted to automate the applying of a diff, I would use that." So it never actually occurred to someone that you could write a computer program to take the other forms of output and apply them. Either that, or it did not occur to them that there was some benefit to using the context diff form, because you could apply it to something that had been changed and still easily get it to do the right thing. It's one of those things that's obvious in retrospect. But to be perfectly honest, it wasn't really a brilliant flash of inspiration so much as self defense. I put out the first version of rn, and then I started putting out patches for it, and it was a total mess. You could not get people to apply patches because they had to apply them by hand. So, they would skip the ones that they didn't think they needed, and they'd apply the new ones over that, and they'd get totally messed up. I wrote patch so that they wouldn't have this excuse that it was too hard. I don't know whether it's still the case, but for many years, I told people that I thought patch had changed the culture of computing more than either rn or Perl had. Now that the Internet is getting a lot faster than it used to be, and it's getting much easier to distribute whole distributions, patches tend to be sent around only among developers. I haven't sent out a patch kit for Perl in years. I think patch has became less important for the whole thing, but still continues to be a way for developers to interchange ideas. But for a while in there, patch really did make a big difference to how software was developed.
Larry Wall's assessment of the diminishing importance of patch to the computing community as a whole is probably accurate, but in the free software world it's still an essential tool. The ubiquity of patch makes it possible for new users and non-programmers to easily participate in alpha- and beta-testing of software, thus benefiting the entire community.
It occurred to me to write this article after noticing a thread which periodically resurfaces in the linux-kernel mailing list. About every three months someone will post a plea for a split Linux kernel source distribution, so that someone just interested in, say, the i386 code and the IDE disk driver wouldn't have to download the Alpha, Sparc, etc. files and the many SCSI drivers for each new kernel release. A series of patient (and some not-so-patient) replies will follow, most urging the original poster to use patches to upgrade the kernel source. Linus Torvalds will then once again state that he has no interest in undertaking the laborious task of splitting the kernel source into chunks, but that if anyone else wants to, they should feel free to do so as an independent project. So far no-one has volunteered. I can't blame the kernel-hackers for not wanting to further complicate their lives; I imagine it would be much more interesting and challenging to work directly with the kernel than to overhaul the entire kernel distribution scheme! Downloading an eleven megabyte kernel source archive is time-consuming (and, for those folks paying by the minute for net access, expensive as well) but the kernel patches can be as small as a few dozen kilobytes, and are hardly ever larger than one megabyte. The 2.1.119 development kernel source on my hard disk has been incrementally patched up from version 2.1.99, and I doubt if I'd follow the development as closely if I had to download each release in its entirety.
Patch comes with a good manual-page which lists its numerous options, but 99% of the time just two of them will suffice:
The -p1 option strips the left-most directory level from the
filenames in the patch-file, as the top-level directory is likely to vary on
different machines. To use this option, place your patch within the directory
being patched, and then run patch -p1 < [patchfile] from within that
directory. A short excerpt from a Linux kernel patch will illustrate
this:
diff -u --recursive --new-file v2.1.118/linux/mm/swapfile.c linux/mm/swapfile.c --- v2.1.118/linux/mm/swapfile.c Wed Aug 26 11:37:45 1998 +++ linux/mm/swapfile.c Wed Aug 26 16:01:57 1998 @@ -489,7 +489,7 @@ int swap_header_version; int lock_map_size = PAGE_SIZE; int nr_good_pages = 0; - char tmp_lock_map = 0; + unsigned long tmp_lock_map = 0;
Applying the patch from which this segment was copied with the -p1 switch effectively truncates the path which patch will seek; patch will look for a subdirectory of the current directory named /mm, and should then find the swapfile.c file there, waiting to be patched. In this excerpt, the line preceded by a dash will be replaced with the line preceded by a plus sign. A typical patch will contain updates for many files, each section consisting of the output of diff -u run on two versions of a file.
Patch displays its output to the screen as it works, but this output usually scrolls by too quickly to read. The original, pre-patch files are renamed *.orig, while the new patched files will bear the original filenames.
One possible source of problems using patch is differences between various versions, all of which are available on the net. Larry Wall hasn't done much to improve patch in recent years, possibly because his last release of the utility works well in the majority of situations. FSF programmers from the GNU project have been releasing new versions of patch for the past several years. Their first revisions of patch had a few problems, but I've been using version 2.5 (which is the version distributed with Debian 2.0) lately with no problems. Version 2.1 has worked well for me in the past. The source for the current GNU version of patch is available from the GNU FTP site, though most people will just use the version supplied with their distribution of Linux.
Let's say you have patched a directory of source files, and the patch didn't apply cleanly . This happens occasionally, and when it does patch will show an error message indicating which file confused it, along with the line numbers. Sometimes the error will be obvious, such as an omitted semicolon, and can be fixed without too much trouble. Another possibility is to delete from the patch the section which is causing trouble, but this may or may not work, depending on the file involved.
Another common error scenario: suppose you have un-tarred a kernel source archive, and while exploring the various subdirectories under /linux/arch/ you notice the various machine architecture subdirectories, such as alpha, sparc, etc. If you, like most Linux users, are running a machine with an Intel processor (or one of the Intel clones), you might decide to delete these directories, which are not needed for compiling your particular kernel and which occupy needed disk space. Some time later a new kernel patch is released and while attempting to apply it patch stalls when it is unable to find the Alpha or PPC files it would like to patch. Luckily patch allows user intervention at this point, asking the question "Skip this patch?" Tell it "y", and patch will proceed along its merry way. You will probably have to answer the question numerous times, which is a good argument for allowing the un-needed directories to remain on your disk.
Many Linux users use patch mainly for patching the kernel source, so a few tips are in order. Probably the easiest method is to use the shell-script patch-kernel, which can be found in the /scripts subdirectory of the kernel source-tree. This handy and well-written script was written by Nick Holloway in 1995; a couple of years later Adam Sulmicki added support for several compression algorithms, including *.bz, *.bz2, compress, gzip, and plain-text (i.e., a patch which has already been uncompressed). The script assumes that your kernel source is in /usr/src/linux,, with your new patch located in the current directory. Both of these defaults can be overridden by command-line switches in this format: patch-kernel [ sourcedir [ patchdir ] ]. Patch-kernel will abort if any part of the patch fails, but if the patch applies cleanly it will invoke find, which will delete all of the *.orig files which patch leaves behind.
If you prefer to see the output of commands, or perhaps you would rather keep the *.orig files until you are certain the patched source compiles, running patch directly (with the patch located in the kernel source top-level directory, as outlined above) has been very reliable in my experience. In order to avoid uncompressing the patch before applying it a simple pipe will do the trick:
gzip -cd patchXX.gz | patch -p1
or:
bzip2 -dc patchXX.bz2 | patch -p1
After the patch has been applied the find utility can be used to check for rejected files:
find . -name \*.rej
At first the syntax of this command is confusing. The period indicates that find should look in the current directory and recursively in all subdirectories beneath it. Remember the period should have a space both before and after it. The backslash before the wildcard "*" "escapes" the asterisk in order to avoid confusing the shell, for which an asterisk has another meaning. If find locates any *.rej files it will print the filenames on the screen. If find exits without any visible output it's nearly certain the patch applied correctly.
Another job for find is to remove the *.orig files:
find . -name \*.orig -print0 | xargs -0r rm -f
This command is sufficiently cumbersome to type that it would be a good candidate for a new shell alias. A line in your ~/.bashrc file such as:
alias findorig 'find . -name \*.orig -print0 | xargs -0r rm -f'
will allow just typing findorig to invoke the above command. The single quotes in the alias definition are necessary if an aliased command contains spaces. In order to use a new alias without logging out and then back in again, just type source ~/.bashrc at the prompt.
While putting this article together I upgraded the version of patch on my machine from version 2.1 to version 2.5. Both of these versions come from the current FSF/GNU maintainers. Immediately I noticed that the default output of version 2.5 has been changed, with less information appearing on the screen. Gone is Larry Wall's "...hmm" which used to appear while patch was attempting to determine the proper lines to patch. The output of version 2.5 is simply a list of messages such as "patching file [filename]", rather than the more copious information shown by earlier versions. Admittedly, the information scrolled by too quickly to read, but the output could be redirected to a file for later perusal. This change doesn't affect the functionality of the program, but does lessen the human element. It seems to me that touches such as the old "...hmm" messages, as well as comments in source code, are valuable in that they remind the user that a program is the result of work performed by a living, breathing human being, rather than a sterile collection of bits. The old behavior can be restored by appending the switch --verbose to the patch command-line, but I'm sure that many users either won't be aware of the option or won't bother to type it in. Another difference between 2.1 and 2.5 is that the *.orig back-up files aren't created unless patch is given the -b option.
Patch is not strictly necessary for an end-user who isn't interested in trying out and providing bug-reports for "bleeding-edge" software and kernels, but often the most interesting developments in the Linux world belong in this category. It isn't difficult to get the hang of using patch, and the effort will be amply repaid.
Recently a small, ncurses-based typing tutor program appeared on the Sunsite archive site. Typist is a revision of an old, unmaintained Unix program. Simon Baldwin is responsible for this updated version, and he has this to say about the origin of his involvement:
This program came from a desire to learn 'proper' typing, and not the awkward keyboard prodding I've been doing for the past 10 years or more. Since I usually run Linux rather than Windows or DOS, I looked around for a tutor program, and surprisingly, found nothing in the usual places. Eventually, I stumbled across Typist - a little gem of a program for UNIX-like systems. The original worked great, but after a while I started noticing odd things - some lessons seemed to go missing, and the programs were apt to exhibit some strange behaviours. After fixing a few bugs it seemed that the time was right for something of a rewrite.
Don't expect a Linux version of Mavis Beacon; Typist has a simple but
efficient interface without extraneous graphical fluff. Start it up and here is
what you will see:
Once a choice of lessons has been made, a series of help screens explain
the usage of the program. Here is a lesson screenshot:
The general idea is to type the exact letters or words shown on the screen; if a mistake is made a caret is shown rather than the letter typed. If no mistakes were made, the next section of the lesson appears; otherwise the first section is repeated until there are no errors. After each run through a lesson, a box appears showing typing speed and number of errors.
A Dvorak lesson is even included for those willing to swim against the tide in the pursuit of greater typing speed. I've considered learning the Dvorak system, but have refrained due to my family's occasional need to use my machine. I don't want to make the transition between Windows and Linux systems more of a culture shock than it already is!
Typist's small size and spartan interface does have the advantages of quick start-up and low overhead, making it ideal for quick usage in the intervals between other tasks, or while waiting for a web-site to load.
Typist also exemplifies one my favorite scenarios in the free software world: an old source code archive languishing on an FTP site somewhere is now revived and given new life and new users.
At the moment, the only source of the program seems to be the /pub/Linux/Incoming directory at the Sunsite archive site. Presumably Typist will eventually be filed away elsewhere on the site, but I don't know just where it will end up. Incidentally, Typist has now been re-released under the GNU GPL.
paradigm shift paradigm shift (pair uh dime shift) 1. a profound and irreversible change to a different model of behavior or perception. 2. an epiphany with staying power. 3. a sea change of such magnitude that it alters the course of all who pass through it.
Paradigm shifts. Thinking back over my years in the industry, there haven't been that many. Especially when you consider the thousands of times the term has been used. The move of the center from the glass house to the desktop certainly qualifies. Likewise the rethinking of systems analysis and design, from the physical to the logical, was echoed by structured programming.
But programming was to be swept by a second, perhaps even more fundamental change in perspective as we moved from procedural languages to object oriented. And to put it in everyday terms, there is a whole new mindset today when you connect to the internet than there was when you reached out to touch a BBS.
There have been plenty of impostors: bubble memory, the death of mainframes, quality management, cold fusion, new Coke and "push content" on the web. It's
often impossible to tell the difference between la buzz de jour and the first stirrings of a new-born, honest to baud, as real as the day is long, paradigm shift.
The incubation period can last for years. Eventually, though, a thing either emerges and changes everything or it quietly fades away. Only then can you know for sure. I believe we are at the edge of the largest paradigm shift in the history of the industry. This one will smash the current model beyond recognition. Our children and our children's children will look back at the first age, the first 30 years of personal computing, and see it for the barbaric, archaic, self inhibiting, self impeding dinosaur that it is.
A paradigm shift does not mean one thing is simply replaced by another. A new force field appears, draws attention to itself, and may coexist with, perhaps even languish alongside for some period of time, the model that it will replace.
There may even be a longer period of time during which the original gradually fades away. The shift occurs, quite simply, when you wake up one day and find yourself seeing things in a new way, from a new perspective.
The glass house and the personal computer? That one has been underway for many years. Microsoft has eclipsed IBM as the largest seller of software in the quarter just ended.
The shift, by definition, never occurs in isolation. There must be related spheres, energizing pulses, co-dependent orbs circling the prime. It is when the catalyst works its magic that you are transported. Suddenly you are "there."
Object oriented programming has been around for quite awhile now. I remember in the early 80's my brother asking if I had taken a look at Smalltalk yet. He seemed quite taken with the language and what it was about. I toyed with the turtle and got some inkling of objects and inheritance, but I really couldn't see that much would ever happen in the real world with Alan Kay's brainchild.
Years later C++ would begin to move into the mainstream. Not replacing Cobol and C but just establishing its own place in the landscape. OO methodologies
began to abound as more and more people crossed the line. But the big push hadn't even happened yet, Oak hadn't even dropped the acorn that became Java.
Today, with the wildfire popularity of Java among developers, with its entry into the enterprise not only assured but an established fact, with its continued maturing and fleshing out, it is Java that is carrying the banner of object oriented programing to the dwindling herd of procedural programmers.
Of course, in the time between Kay's conceptualization of objects, GUIs and cut-and-paste, and where we are today, it has not always been clear that this was the kind of stuff that would have profound, far-reaching impact on the way we look at software and design, the way we look at the tasks to be done and how we plan to do them.
To many of the brightest and the best, at least to many outside of the Learning Research Group at Xerox Palo Alto Research Center during the 70's and 80's, bubble memory was much more likely to be the next big thing. And so it is with some trepidation that I hereby formally and officially predict that we are today awash in the first tides of a sea change that will once again change everything.
But keep in mind, my dweebs, that my track record as a Karmac for Computing is something less than perfect. It was in the fall of 1978 that I told Sam Skaggs, then president of Skaggs-Albertsons superstores, the first marriage of drug and grocery emporiums, that scanning technology would never work in a grocery store.
And in 1994 I predicted OS/2 would win the desktop from Windows. So don't bet the digital dirtfarm on this just yet. Your narrator is guessing, just as every other pundit who looks out past the breakers for first signs of the swell that will become the next big wave.
My hunch is this: free/open source software will emerge as the only sensible choice. Feel the tremors in the Northwest? This one could be killer. There has been much debate over which term ("free software" or "open source") is the best choice, the most descriptive, and the truest to its philosophical roots. I am not going to go there. I will compromise by using both terms interchangeably.
But please note that the word free in "free software" applies to a state of being, not to its price. It is about freedom. Also note that the hottest software product in the world today, Linux, qualifies as free software under this definition, whether you download it for free from the internet or pay anywhere from $1.99 to $99.99 for specific distributions.
Linux is the only non-Windows operating system in the world that is gaining market share. How hot is it? It's almost impossible these days to keep up with articles in the press about Linux. A mailing list dedicated to Linux News recently had to split into three separate lists in order to handle the load. Linus Torvalds, its creator, is on the cover of the August issue of Forbes.
Every major computer trade publication is showering it with attention. Oracle, Ingres, and Informix have just announced they will be porting their database products to Linux. Caldera has just announced (and has available for free download today) a Netware server for Linux. And that's just the news from the past two weeks. Linux has cache, bebe.
The roots of Linux-mania began in the early 80's when Richard Stallman founded the GNU Project. Stallman had worked at MIT during the 70's and witnessed the destructive (in terms of group productivity and effort) nature of restrictive licensing of proprietary software. He wanted to create a free, modern operating system that could be used by everyone.
In the GNU Manifesto (1983), he explained why he must write GNU: "I consider that the golden rule requires that if I like a program I must share it with other people who like it. Software sellers want to divide the users and conquer them, making each user agree not to share with others.
I refuse to break solidarity with other users in this way. I cannot in good conscience sign a nondisclosure agreement or a software license agreement.
For years I worked within the Artificial Intelligence Lab to resist such tendencies and other inhospitalities, but eventually they had gone too far: I could not remain in an institution where such things are done for me against my will.
So that I can continue to use computers without dishonor, I have decided to put together a sufficient body of free software so that I will be able to get along without any software that is not free.
I have resigned from the AI lab to deny MIT any legal excuse to prevent me from giving GNU away."
By the time (almost ten years later) Linus Torvalds had a good working Linux kernel available, the GNU project had most of the non-kernel essentials ready. It was a marriage made in free/open source software heaven, and Linus converted the original Linux license to the GPL (GNU's General Public License).
After all, it seemed the obvious choice to the young college student who had wanted to create a free version of Unix that everyone could use. Not only is Linus a true code wizard, he is delightfully perfect for his role today as poster boy of the free/open source movement.
Every interview, every public appearance, each bit of history about him and Linux unearthed reveals a warm, wise, friendly, candid and particularly unpretentious personality. How else could someone whose views are so diametrically opposed to those of Bill Gates and the money mongers end up on the cover of Forbes? But Linux is not the only success story in the world of free/open source.
Netscape rocked the commercial world earlier this year when it announced it would free the source code for its browser and make it available for download to
anyone who wanted it. Netscape now claims that the browser has been improved as much over the past couple of months as it would have in 2.5 years in its closed source environment.
FreeBSD, a rival for Linux in the UNIX like, free/open source sector, has its own fanatical users and supporters. Just this past week it shattered an existing world record for total bytes transferred from an FTP site in a single day. CRL Network Services, host of the popular Walnut Creek CD-ROM ftp site, announced on July 30th that they had moved over 400 gig of files on July 28, 1998. The previous mark of about 350 gig had been set by Microsoft during the Win95 launch period.
Oh, one other thing. The FreeBSD record was set on a single 200Mhz Pentium box. The Microsoft record was set using 40 separate servers. Results like those are probably the driving force behind the emerging model. The performance just blows away what Windows is able to deliver in their closed, sealed, NDA protected, shoot you if you see it source code, proprietary model.
Eric S. Raymond, keeper of the tome on internetese called "The Jargon File" and author on the must read essay "The Cathedral and The Bazaar," talks about the success he had with FETCHMAIL using the Bazaar model of development. Lots of eyes on the code: bugs are found more quickly, enhancements made more quickly, design becomes more normalized.
But Linus is the candle for the moth. Leo LaPorte had him as a guest on his ZDTV show the night that Win98 was launched. I caught him in chat on the way out and asked him how SMP was looking for the next release. He said it looked very good.
It seems he is always this accessible, and that is part of his magic and part of the reason for the success of Linux and shift in thinking about software development. For open software to not only flourish but become the norm, at least for those essential bits, like operating systems, that everyone needs to run, there must be huge successes to attract the rest of the crowd.
Linux and FreeBSD are two of those attractions. Linus is the advantage that Linux holds over FreeBSD, not in a technical sense, but in a human sense. To get a sense of what Linus is like, it's interesting to follow his exchange of USENET messages with Andy Tanenbaum, the creator of Minix.
Linus began his 386 experience with Minix and began to extend it to create Linux. He and Andy exchanged a series of messages in comp.os.minix over the issues of microkernel architecture, truly free software, and the relative merits of Minix and Linux.
It began with a post by Tanenbaum which said in part:
"MINIX is a microkernel-based system. The file system and memory management are separate processes, running outside the kernel. The I/O drivers are also separate processes (in the kernel, but only because the brain-dead nature of the Intel CPUs makes that difficult to do otherwise).
LINUX is a monolithic style system. This is a giant step back into the 1970s. That is like taking an existing, working C program and rewriting it in BASIC. To me, writing a monolithic system in 1991 is a truly poor idea."
To which Linus replied:
"True, Linux is monolithic, and I agree that microkernels are nicer. With a less argumentative subject, I'd probably have agreed with most of what you said. From a theoretical (and aesthetical) standpoint Linux loses. If the GNU kernel had been ready last spring, I'd not have bothered to even start my project: the fact is that it wasn't and still isn't. Linux wins heavily on points of being available now.
>>MINIX is a microkernel-based system. >>LINUX is a monolithic style system.
If this was the only criterion for the "goodness" of a kernel, you'd be right. What you don't mention is that minix doesn't do the micro-kernel thing very well, and has problems with real multitasking (in the kernel). If I had made an OS that had problems with a multithreading filesystem, I wouldn't be so fast to condemn others: in fact, I'd do my damndest to make others forget about the fiasco."
Notice what is missing from the post? Even though his pet project, the fledgling Linux, has been slapped around pretty hard by the man who created its predecessor, Linus did not fall into the trap of name calling and hysterics that too often goes hand-in-glove with online debate.
Notice what is present in the post? Concession of valid points made by Tanenbaum. Factual assertions that represent Linux quite nicely, thank you very much. And even for this well behaved defense, Linus closed with this:
"PS. I apologize for sometimes sounding too harsh: minix is nice enough if you have nothing else. Amoeba might be nice if you have 5-10 spare 386's lying around, but I certainly don't. I don't usually get into flames, but I'm touchy when it comes to Linux :)"
For all his dweebness, Linus is a people person. He is likable. He is brilliant. He is passionate about Linux but not to the point of resorting to bashing its detractors or alternatives to it. Earlier I mentioned an ongoing debate among proponents of the terms "free software" and "open source software." That is really symptomatic of a deeper argument over what type of licensing free/open source software should have.
There is the GNU GPL that Linux uses, and there is the BSD model. Listen to Linus the diplomat walk that tightrope (while still making his preference known) in an interview with Linux Focus's Manuel Martinez:
"I'd like to point out that I don't think that there is anything fundamentally superior in the GPL as compared to the BSD license, for example.
But the GPL is what _I_ want to program with, because unlike the BSD license it guarantees that anybody who works on the project in the future will also contribute their changes back to the community. And when I do programming in my free time and for my own enjoyment, I really want to have that kind of protection: knowing that when I improve a program those improvements will continue to be available to me and others in future versions of the program.
Other people have other goals, and sometimes the BSD style licenses are better for those goals. I personally tend to prefer the GPL, but that really doesn't mean that the GPL is any way inherently superior - it depends on what you want the license to do.."
His views on the Evil Empire? Strong, perhaps, but certainly not inflammatory or angry. In his words, from the same interview:
"I can certainly understand the "David vs Goliath" setup, but no, I don't personally share it all that much. I can't say that I like MicroSoft: I think they make rather bad operating systems - Windows NT is just more of the same - but while I dislike their operating systems and abhor their tactics in the marketplace I at the same time don't really care all that much about them.
I'm simply too content doing what I _want_ to do to really have a very negative attitude towards MicroSoft. They make bad products - so what? I don't need to care, because I happily don't have to use them, and writing my own alternative has been a very gratifying experience in many ways. Not only have I learnt a lot doing it, but I've met thousands of people that I really like while developing Linux - some of them in person, most of them through the internet."
Three potentially disasterous discussions on red button issues: Linux versus Minix, the GNU GPL license versus that of BSD, and Linux versus Windows. In each he makes his points politely but with utter candor.
One last example. There is finally an official Linux logo. It is the cute, fat and friendly Penguin you often see on Linux sites. There was heated debate among the Linuxites on the choice of the logo. Many wanted something other than a cute, fat penguin. Something more aggressive or sleek, perhaps.
Linus calmed these waters at the release of Linux 2.0 by saying:
"Some people have told me they don't think a fat penguin really embodies the grace of Linux, which just tells me they have never seen an angry penguin charging at them in excess of 100mph. They'd be a lot more careful about what they say if they had."
He is completely believable, obviously passionate about the project, and possessed of a contagious good humor. Linux could have no better leader from a technical point of view, and it couldn't have a better poster boy either. Its success more than anything else is pulling the rest of the world's mindset towards the notion of free/open source software.
Nicholas Petreley raised the issue of open source software recently in his forum at InfoWorld Electric. It triggered a huge number of responses about the phenomenum. There may even be an Open Source magazine in the works. I credit my rethinking on this software dynamic to the reading I did there. I believe it is what finally made me realize that a paradigm shift has already occurred. That we are no longer discussing a possibility, but simply what is.
The conclusion to the Forbes article behind the Linus cover calls for the Department of Justice to take note of the success of Linux in growing market share and to call of the investigation of Microsoft as unregulated monopoly. While I consider that a lame conclusion, the DOJ should be interested in enforcing antitrust law whether Linux is flourishing or not, I can't help but wonder if there's not some truth to the inspiration for that thinking. That it won't be government intervention or regulation that busts up Microsoft, but a revolution in our thinking about software.
The Dweebspeak Primer, http://www.pjprimer.com/
Copyright ® 1998 by Ron Jenkins. This work is provided on an "as is" basis. The author provides no warranty whatsoever, either express or implied, regarding the work, including warranties with respect to its merchantability or fitness for any particular purpose.
Corrections and suggestions are welcomed by the author. He can be reached by electronic mail at rjenkins@unicom.net.
This document came about as a result of a client's problem and my solution. I have since seen this question asked a zillion times on USENET right up there with "Why can't Linux see all my (insert your >64MB number here,) of RAM?"
One of my clients had a rather classical old-style Unix host to dumb terminal setup, connected through multiple serial termservers.
They also had a PC on every desk, also connecting through a "dumb" serial connection.
The problem was that they needed to administer the host, as well as run many other programs on the host that required a GUI. To accomplish this, they utilized a couple of Unix workstations.
Obviously this was unacceptable, as they had everyone fighting for time on the workstations.
The version of Unix they were running, had no CLI other than a network telnet session or the aforementioned serial setup, only administration through their proprietary interface running on top of X.
A quick investigation showed an X server running on the host, but not being utilized. A previous consultant from the company they purchased the two systems from had suggested X Terminals as a solution, which by coincidence, they just happened to have handy.
They never did tell me what his quote was, but rumor has it was staggering. (Look the price of an X Terminal sometime and you'll see what I mean.)
Enter Linux. First, I did away with the serial connections on the PC's and got them on a switched 10 base T network.
Next, I setup a couple of 486/100's as file servers and proxy hosts, using ip_masq and Samba. These machine then connected to the external WAN over a 10 base 2 bus. All the suits had quota'd storage, could e-mail and memo the begeezus out of each other, surf the "net, and were happy as clams.
One word - POLITICS.
To convince the suits (the ones with the money) to let me use Linux to solve the problem for the programmers and administrators (the ones who actually do the work to produce the money), I had to impress them first.
While they don't understand diddly squat about the technical side of the business, they do understand I gave them e-mail, file services, intranet, and Internet access for just the cost of my time, since they had the 486's setting in a closet collecting dust.
Now I had the go-ahead for the X solution I proposed, which was 2 more 486's also already on site, also not being used, upgraded to SCSI-3 Ultra Wide Disks, and honked up the RAM, to serve as X proxies, for reasons I can't go into. This interposes an additional barrier between the Xhost and the clients. You shouldn't need this, so I'm going to pretend everything behind the 486's does not exist.
Just to make it really fun, I was also asked to include the web design department on this subnet, who were all on Mac's and Power PC's.
After creating a 10 base T subnet with the 486's and the clients wired up and TCP/IP configured on all the clients, it was time to show 'em some magic.
From this point forward, the 486 will be referred to as the "X host", and any Windows 95/98/NT/Mac/PPC machine will be referred to as "the client".
On the X host, create a user account for each of the desired clients.
Acquire X server software for the clients.
I am a freeware fanatic, so I chose to use MI/X, available from http://tnt.microimages.com/www/html/freestuf/mix/, or my mirror, ftp.brokewing.com/pub/mix/.
An additional factor that led me to choose the MI/X package, is that it runs on all three platforms.
Install the MI/X software
Note for Windows clients - either install the program in it's own place like C:\mix, or if you put it in Program Files, create a shortcut directly to $BASEDIR\TNTSTART.EXE startmix (note the space) for some reason, on the 95 machines you may get a not enough memory message when you try to run it if you don't.
Acquire Telnet software for the clients.
In my case they were already setup for telnet, from the previous serial thing.
All Windows clients should already have telnet, the Mac's may or may not.
If not, NCSA produces a telnet client that runs on the Mac platform.
You should be ready to go. I am sure that this whole thing could be done more elegantly, but here's what I did:
For the bourne shell:
DISPLAY=<the IP of the client machine>:0.0
For example, DISPLAY=192.0.0.3:0.0
Now you need to tell the Xhost to use this Environment Variable for all subsequent programs.
The command to accomplish this is:
export DISPLAY
For the csh:
setenv DISPLAY <client IP as above>
You should now be able to run any X application you want on the Xhost and have it display on your client machine.
In the telnet window, to launch an xterm, type:
xterm &
After the xterm comes up in the MI/X window, you can close the telnet session.
That's all there is to it!
As your website grows in size, so will the number of people that visit your site. Now most of these people are just like you and me in the sense that they want to go to your site, click a button, and get exactly what information they were looking for. To serve these kinds of users a bit better, the Internet community responded with the ``Site Search''. A way to search a single website for the information you are looking for. As a system administrator, I have been asked to provide search engines for people to use on their websites so that their clients can get to their information as fast as possible.
Now the trick to most search engines (Internet wide included) is that they index and search entire sites. So for instance, you are looking for used cars. You decide to look for an early 90s model Nissan Truck. You get on the web, and go to AltaVista. If you do a search for ``used Nissan truck'', you will most likely come up with a few pages that have listings of cars. Now the pain comes when you go to that link and see that 400K HTML file with text listings of used trucks. You have to either go line by line until you find your choice, or like most people, find it on your page using your browser's find command.
Now wouldn't it be nice if you could just search for your used truck and get the results you are looking for in one fail swoop?
A recent search CGI that I designed for a company called Resource Spectrum (http://www.spectrumm.com/) is what precipitated DocSearch. Resource Spectrum needed a solution similar to my truck analogy. They are a placement agency for high skilled jobs that needed another alternative to posting their job listing to newsgroups. What was proposed was a searchable Internet listing of the jobs on their new website.
Now as the job listing came to us, it was in a word document that had been exported to HTML. As I searched (no pun intended) long and hard for something that I could use, nothing turned up. All of the search engines I found only searched sites, not single documents.
This is where the idea for DocSearch came from.
I needed a simple, clean way to search that single HTML document so users could get the information they needed quickly and easily.
I got out the old Perl Reference and spent a few afternoons working out a solution to this problem. After a few updates, you see in front of you DocSearch 1.0.4. You can grab the latest version at ftp://ftp.inetinc.net/pub/docsearch/docsearch.tar.gz.
Let's go through the code here so we can see how this works. First before we really get into this though, you need to make sure you have the CGI Library (cgi-lib.pl) installed. If you do not, you can download it from http://www.bio.cam.ac.uk/cgi-lib/. This is simply a Perl library that contains several useful functions for CGIs. Place it in your cgi-bin directory and make it world readable and executable. (chmod a+rx cgi-lib.pl)
Now you can start to configure DocSearch. First off, there are a few constants that need to be set. They are in reference to the characteristics of the document you are searching. For instance...
# The Document you want to search. $doc = "/path/to/my/list.html";Set this to the absolute path of the document you are searching.
# Document Title. The text to go inside the <title></title> HTML tags. $htmltitle = "Nifty Search Results";Set this to what you want the results page title to be.
# Optional Back link. If you don't want one, make the string null. # i.e. $backlink = ""; $backlink = "http://www.inetinc.net/some.html";If you want to provide a ``Go Back'' link, enter the URL of the file that we will be referencing.
# Record delimiter. The text which separates the records. $recdelim = " ";This part is one of the most important aspects of the search. The document you are searching must have something in between the "records" to delimit the html document. In English, you will need to place some HTML comment or something in between each possible result of the search. In my example, MS Word put the $nbsp; tag in between all of the records by default, so I just used that as a delimiter.
Next we ReadParse() our information from the HTML form that was used as a front end to our CGI. Then to simplify things later, we go ahead and set the variable $query to be the term we are searching for.
$query = $input{`term'};
This step can be repeated for each query item you would like to use to
narrow your search. If you want any of these items to be optional, just
add a line like this in your code.
if ($query eq "") {
$query = " ";
}
This will match relatively any record you search.
Now comes a very important step. We need to make sure that any meta characters are escaped. Perl's bind operator uses meta characters to modify and change search output. We want to make sure that any characters that are entered into the form are not going to change the output of our search in any way.
$query =~ s/([-+i.<>&|^%=])/\\\1/g;Boy does that look messy! That is basically just a Regular Expression to escape all of the meta characters. Basically this will change a + into a \+.
Now we need to move right along and open up our target document. When we do this, we will need to read the entire file into one variable. Then we will work from there.
open (SEARCH, "$doc"); undef $/; $text = <SEARCH>; close (SEARCH);The only thing you may not be familiar with is the undef $/; statement you see there. For our search to work correctly, we must undefine the Perl variable that separates the lines of our input file. The reason this is necessary is due to the fact that we must read the entire file into one variable. Unless this is undefined, only one line will be read.
Now we will start the output of the results page. It is good to customize it and make it appealing somehow to the user. This is free form HTML so all you HTML guys, go at it.
Now we will do the real searching job. Here is the meat of our search. You will notice there are two commented regular expressions in the search. If you want to not display any images or show any links, you should uncomment those lines.
@records = split(/$recdelim/,$text);We want to split up the file into an array of records. Each record is a valid search result, but is separate from the rest. This is where the record delimiter comes into play.
foreach $record (@records)
{
# $record =~ s/<a.*<\/a>//ig; # Do not print links inside this
# doc.
# $record =~ s/<img.*>//ig; # Do not display images inside this
# doc.
if ( $record =~ /$query/i ) {
print $record;
$matches++;
}
}
This basically prints out every $record that matches our search
criteria. Again you can change the number of search criterion you use by
changing that if statement to something like this.
if ( ($record =~ /$query/i) && ($record =~ /$anotheritem/) ) {
This will try to match both queries with $record and upon a
successful match, it will dump that $record to our results
page. Notice how we also increment a variable called $matches
every time a match is made. This is not as much as to tell the user how many
different records were found, but more of a count to tell us if no
matches were found so we can tell the user that no, the system is not
down, but in fact we did not match any records based upon that query.
Now that we are done searching and displaying the results of our search, we need to do a few administrative actions to ensure that we have fully completed our job.
First off, as I was mentioning before, we need to check for zero matches in our search and let the user know that we could not find anything to match his query.
if ($matches eq "0") {
$query =~ s/\\//g;
print << "End_Again";
<center>
<h2>Sorry! "$query" was not found!</h2><p>
</center>
End_Again
}
Notice that lovely Regular Expression. Now that we had to take all of
the trouble to escape those meta characters, we need to remove the
escape chars. This way when they see that their $query was
not found, they will not look at it and say ``But that is not what I
entered!'' Then we want to dump the HTML to disappoint the user.
The only two things left to do is end the HTML document cleanly and allow for the back link.
if ( $backlink ne "" ) {
print "<center>";
print "<h3><a href=\"$backlink\">Go
back</a></h3>";
print "</center>";
}
print << "End_Of_Footer";
</body>
</html>
End_Of_Footer
All done. Now you are happy because the user is happy. Not only have
you streamlined your website by allowing to search a single page, but you
have increased the user's utility by giving them the results they want.
The only result of this is more hits. By helping your user find the
information he needs, he will tell his friends about your site. And his
friends will tell their friends and so on. Putting the customer first
sometimes does work!

 Larry Ayers
Larry Ayers
David Bandel
Joe Barr
Jim Dennis
Michael J. Hammel
Bill Henning
Phil Hughes
Ron Jenkins
James M. Rogers
Shay Rojansky
Vincent Stemen
Martin Vermeer
Branden R. Williams
Thanks to all our authors, not just the ones above, but also those who wrote giving us their tips and tricks and making suggestions. Thanks also to our new mirror sites.
 The news this month and last was gathered by
Ellen Dahl. Amy Kukuk put the News Byte column together for me. Thanks to
them both for good and needed help.
The news this month and last was gathered by
Ellen Dahl. Amy Kukuk put the News Byte column together for me. Thanks to
them both for good and needed help.
Have fun!
Marjorie L. Richardson
Editor, Linux Gazette, gazette@ssc.com
Linux Gazette Issue 32, September 1998,
http://www.linuxgazette.com
This page written and maintained by the Editor of Linux Gazette,
gazette@ssc.com










 The Mailbag!
The Mailbag! Greetings From Jim Dennis
Greetings From Jim Dennis