| Zpět | Obsah | Další |
Minule jsme si ukázali přehled všech tříd Foundation Kitu, a stručně jsme probrali účel a základní využití většiny z nich. Nyní se soustředíme jen na ty nejčastěji využívané; zato se na ně podíváme podrobněji na konkrétních příkladech použití. Pro příklady použijeme Objective C, popsané v předchozích dílech našeho seriálu; Cocoa umožňuje stejně dobře i využití jazyka Java, ale Objective C je šikovnější.
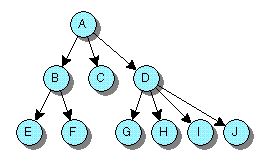
Pro ilustraci základního využití tříd NS(Mutable)Array si ukážeme (nikoli ideální) implementaci triviálního N-árního stromu, tj. datové struktury tohoto typu:
ve které má každý objekt libovolně mnoho 'následníků'. V C++ (ostatně, ani v Objective C bez beztypových kontejnerů) by to nebylo možné bez deklarovaní vlastní nové třídy; v Objective C s využitím beztypových kontejnerů Foundation Kitu je to snadné, a bohatě na to stačí samotná třída NSArray (přesněji řešeno, NSMutableArray, protože chceme aby strom byl dynamicky měnitelný).
Pro implementaci využijeme jednoduchého triku, umožněného právě beztypovostí kontejnerů: domluvíme se, že každý uzel stromu bude representován objektem třídy NS(Mutable)Array, s tím, že skutečný obsah uzlu bude vždy prvým objektem v poli. Ostatní objekty — budou-li takové — pak budou podřízené uzly. Použijeme-li tedy celkem přirozený zápis, využívající závorek pro representaci pole (takže prázdné pole bychom mohli vyjádřit výrazem "()", pole obsahující jediný objekt X by se dalo znázornit jako "(X)", pole obsahující objekty X a Y pak "(X,Y)"), mohli bychom celý strom z minulého obrázku zapsat jako
(A,(B,(E),(F)),(C),(D,(G),(H),(I),(J)))
Ukažme si nyní možnou implementaci základních služeb pro práci se stromy — pro jednoduchost to budou prosté "céčkové" funkce (jistě, to je tak trochu "neobjektové" řešení, a v praxi bychom to tak jistě nenaprogramovali — později se seznámíme s velmi pohodlným způsobem, jak v Objective C tento problém odstranit; prozatím však nechceme vykládat příliš mnoho věcí najednou, a proto zůstaneme u neobjektového rozhraní):
id newTree(id contents) { return [NSMutableArray arrayWithObject:contents]; }
Prvá funkce je naprosto triviální — vytvoří nový strom s jediným uzlem, obsahujícím zadaný objekt. Díky poloautomatickému garbage collectoru není zapotřebí žádná služba pro zrušení stromu: celá datová struktura bude zrušena automaticky, jakmile ji již nikdo nebude potřebovat. Základ stromu z minulého obrázku bychom tedy mohli připravit příkazemid ourTree=newTree(A);
za předpokladu (se kterým budeme pracovat i nadále), že objekty A-J, jež budou uloženy uvnitř stromu, již jsou pod odpovídajícími jmény k dispozici.
id contentsOf(id node) { return [node objectAtIndex:0]; }
NSArray *childsOf(id node) { return [node subarrayWithRange:NSMakeRange(1,[node count]-1)]; }
Tyto dvě služby vlastně ani nebudeme potřebovat; ukázali jsme si však jejich implementaci, neboť zajišťují zcela základní operace — získání objektu, uloženého v daném uzlu, a přístup k podřízeným uzlům pro hierarchické procházení stromem.
id addChildTo(id node,id contents) {
id child=newTree(contents);
[node addObject:child];
return child;
}
Služba addChild prostě přidá nový podřízený uzel se zadaným obsahem pod daný uzel (toto je triviální implementace; v praxi bychom ji implementovali trochu lépe, ukázka je na konci tohoto příkladu). Přitom rovnou vrátí nově přidaný uzel, takže jej ihned můžeme použít v dalším kódu. Ukažme si příkazy, jež by vytvořily kompletní strom z minulého obrázku:
id o=addChild(newTree,B);
addChild(o,E);
addChild(o,F);
addChild(newTree,C);
addChild(o=addChild(newTree,D),G);
addChild(o,H);
addChild(o,I);
addChild(o,J);
To je vlastně vše: výše uvedených osm řádků knihovního kódu by stačilo pro základní práci s datovými stromy: stačilo pouhých osm řádků, nebylo třeba vytvářet žádné nové třídy — něco podobného je možné jen v plně objektovém systému s dobře navrženými knihovnami! Přitom se vyplatí si uvědomit, že díky standardním službám Foundation Kitu jsme navíc úplně "zadarmo" dostali spoustu dalších možností:
Ukažme si pro zajímavost ještě možné implementace některých dalších služeb nad stromem. Prvou a nejjednodušší z nich by mohlo být posčítání všech objektů uvnitř stromu; pro procházení využijeme obecnou třídu NSEnumerator:
int countOf(id tree) {
int count=1; // jeden objekt je v tomto uzlu
NSEnumerator *en=[childsOf(tree) objectEnumerator];
while (tree=[en nextObject]) count+=countOf(tree);
return count;
}
O moc jednodušeji by to již skutečně nešlo. Samozřejmě, že namísto iterátoru (NSEnumerator) bychom mohli stejně snadno využít indexy; iterátor je však o něco pohodlnější, snižuje pravděpodobnost chyby, a ve složitějším kódu přináší další výhodu — dokud jej užíváme, je procházené pole "přidrženo" službou retain (viz garbage collector), takže není možné, aby nám někdo jiný sdílená data uvolnil dokud s nimi pracujeme. Při použití indexů bychom se o to museli postarat sami, iterátor to zajistí zcela automaticky.
O nic složitější nebude ani vyhledání zadaného objektu uvnitř stromu: následující funkce vrátí buď uzel, obsahující zadaný objekt, nebo hodnotu nil pokud ve stromě žádný takový uzel není:
id nodeWith(id tree,id contents) {
NSEnumerator *en=[childsOf(tree) objectEnumerator];
if ([contentsOf(tree) isEqual:contents]) return tree;
while (tree=[en nextObject])
if ((tree=nodeWith(tree,contents))!=nil) return tree;
return nil;
}
Nakonec si ukážeme slíbený trik, jak se vyhnout ošklivému neobjektovému rozhraní složenému z céčkových funkcí: nic není jednoduššího, prostě využijeme kategorie, a jejich pomocí doplníme odpovídající služby přímo do knihovní třídy NSMutableArray! Něco podobného by ve statickém jazyce typu C++ nepřipadalo v úvahu vůbec (ale není to, bohužel, vinou nedomyšleného návrhu firmy Sun, možné ani v plně dynamické Javě):
@interface NSMutableArray (DemoTreeServices)
+newTreeWithObject:contents; // vytvoří nový strom s jediným uzlem, obsahujícím objekt contents
-contents; // vrátí obsah tohoto uzlu
-(NSArray*)childs; // přímo podřízené uzly
-(int)numberOfNodes; // počet všech objektů ve stromě
-nodeContainingObject:contents; // vrátí uzel s daným obsahem, nebo nil, není-li ve stromě takový
-addChildWithObject:contents; // přidá poduzel s daným obsahem a vrátí jej. Je-li contents pole, přidá pro každý jeho objekt nový poduzel s daným obsahem (a vrátí nil)
-(void)addChildsWithObjects:(int)number:contents,...; // ditto, lze zadat více objektů
@end
Implementace je asi již zřejmá — většinu služeb naprogramujeme pro ukázku jen triviálně s využitím výše uvedených funkcí; službu addNode však předěláme tak, jak by asi vypadala v reálném systému — podívejte se na komentář v rozhraní, o pár řádků výš (první ukázková implementace funkce addChild byla příliš jednoduchá a nenabízela luxus, na který jsou uživatelé Foundation Kitu zvyklí):
@implementation NSMutableArray (DemoTreeServices)
+newTreeWithObject:contents {return newTree(contents);}
-contents {return contentsOf(self);}
-(NSArray*)childs {return childsOf(self);}
-(int)numberOfNodes {return countOf(self);}
-nodeContainingObject:contents {return nodeWith(self,contents);}
-addChildWithObject:contents {
if ([contents isKindOfClass:[NSArray class]]) {
NSEnumerator *en=[contents objectEnumerator];
while (contents=[en nextObject]) addChild(self,contents);
return nil;
} else return addChild(self,contents);
}
-(void)addChildsWithObjects:(int)number:contents,... {
addChildWithObject([NSArray arrayWithObjects:&contents count:number]);
}
@end
Povšimněte si toho, že nyní je tvorba nových uzlů ve stromě nesrovnatelně pohodlnější, ačkoli nás to stálo jen pár — a velmi jednoduchých — řádků zdrojového kódu navíc. Stojí za to uvést ukázku jak by nyní vypadalo vytvoření kompletního stromu z úvodního obrázku:
id ourTree=[NSMutableArray newTreeWithObject:A];
[[ourTree addChildWithObject:B] addChildsWithObjects:2:E,F];
[ourTree addChildWithObject:C];
[[ourTree addChildWithObject:D] addChildsWithObjects:4:G,H,I,J];
A to je vše! Nakonec jen malý kvíz pro pozorné čtenáře: na první pohled se zdá, že rozšíření funkce metody addChild snížilo flexibilitu datového typu, protože již není možné, aby obsahem uzlu bylo pole (objekt třídy NSArray). Je tomu skutečně tak?
Jako jednoduchoučkou ukázku služeb knihovní třídy NSSet si předvedeme funkci, jejímž argumentem je pole obsahující naprosto libovolnou skupinu objektů. Funkce vrátí jiné pole, jež bude obsahovat tytéž objekty, ale bez duplicit — každý objekt v něm bude uložen nanejvýš jednou.
Snad každý programátor s rozsáhlejšími zkušenostmi potvrdí, že obdobnou službu potřebujeme v praxi dost často. V klasických API se to většinou řeší tak, že ji pro každý případ programujeme znovu, protože v konkrétních případech — kde není zapotřebí plná obecnost funkce nad zcela libovolnými objekty — bývá její implementace mnohem snazší, obvykle zabere mezi pěti až dvaceti řádky kódu, podle konkrétní situace a sady omezení, jež v ní platí.
Zkuste hádat, kolik řádků zabere zcela obecná implementace bez jakýchkoli omezení v API Cocoa! Ano, skutečně — je to jeden řádek; jednodušeji by to už opravdu ani při nejlepší vůli nešlo:
NSArray *removeDups(NSArray *a) { return [[NSSet setWithArray:a] allObjects]; }
Příklad použití této služby by mohl vypadat třeba takto (funkci voláme přímo z ladicího programu gdb):
(gdb) po a
(a, b, a, xyz, xyz, (nested, array), a, b, a, xyz, xyz, (nested, array))
(gdb) po removeDups(a)
(xyz, b, a, (nested, array))
(gdb)
V našem příkladu pole obsahovalo jen textové řetězce a vnořená pole; stejně dobře by však funkce pracovala nad libovolnými objekty (včetně např. datových stromů z minulé kapitoly). Je také vhodné si uvědomit, že díky hashování je tato funkce velmi efektivní — pravděpodobně ne tolik, jako kdybychom ji napsali přímo a pilování jejího algoritmu věnovali hodně času, ale určitě mnohem, mnohem efektivnější než cokoli, co lze napsat byť za stonásobek těch asi deseti sekund, jež byly zapotřebí pro výše uvedenou implementaci!
Jako ilustraci služeb třídy NSCountedSet (a několika dalších) si pro změnu ukážeme kompletní program, který načte daný textový soubor, a provede jeho frekvenční analýzu. Kompletní zdrojový kód — bez zvláštních služeb pro vstup či výstup, ale s kompletní analýzou textu včetně třídění výsledků podle četnosti — jsem psal ani ne čtvrt hodiny, a stačilo k tomu třicet zdrojových řádků:
#import <Foundation/Foundation.h>
int cmpWithSet(id left,id right,NSCountedSet *freq) {
return [freq countForObject:right]-[freq countForObject:left];
}
int main (int argc, const char *argv[])
{
NSAutoreleasePool *pool=[[NSAutoreleasePool alloc] init];
NSString *fname=[NSString stringWithCString:argv[1]];
NSString *data=[NSString stringWithContentsOfFile:fname];
NSLog(@"Scanning \"%@\" (%d bytes)...",fname,[data length]);
if (!data) NSLog(@"Cannot properly open \"%@\"",fname);
else {
NSScanner *sc=[NSScanner scannerWithString:data];
NSCharacterSet *wordDelims=[NSCharacterSet characterSetWithCharactersInString:@" ,.?!;:\"\'/-()0123456789*#@\\\r\n"];
NSCountedSet *freq=[NSCountedSet set];
NSArray *a;
int q,i;
while (![sc isAtEnd]) {
NSAutoreleasePool *pool=[[NSAutoreleasePool alloc] init];
NSString *str;
[sc scanCharactersFromSet:wordDelims intoString:NULL]; // skip any delimiters
if ([sc scanUpToCharactersFromSet:wordDelims intoString:&str])
if ([str length]>3) [freq addObject:str];
[pool release];
}
NSLog(@"done, found %d words",[freq count]);
a=[[freq allObjects] sortedArrayUsingFunction:(int(*)(id,id,void*))cmpWithSet context:freq];
NSLog(@"sorted, first ten:");
if ((i=10)>[a count]) i=[a count];
for (q=0;q<i;q++)
NSLog(@"%@ (%d)",[a objectAtIndex:q],[freq countForObject:[a objectAtIndex:q]]);
}
[pool release];
exit(0); // insure the process exit status is 0
return 0; // ...and make main fit the ANSI spec.
}
Jistěže řada drobností by se dala vylepšit (např. minimální délka slova by měla být parametrizovatelná, a ne fixní 4, mělo by být možné zvolit kódování českých znaků na vstupu, pro výstup by se mělo využít lepší formátování, než triviální NSLog — jež, jak uvidíme níže, zobrazuje Unicode znaky dost nečitelným způsobem — apod.). Přesto je program již v této podobě velmi použitelný.
Ačkoli neuvádím přesný popis jednotlivých použitých služeb, mám za to, že by program měl být i tak dosti snadno srozumitelný — jelikož jména služeb Foundation Kitu jsou víceméně čitelná v obyčejné angličtině, neměl by být problém program pochopit pro kohokoli, kdo má alespoň základní zkušenosti s programováním, a rozumí anglicky. Přesto, pokud by bylo na implementaci cokoli nejasného, rád podám podrobnější vysvětlení, napíšete-li mi na adresu cocoa@ocs.cz.
Programátoři v C++ a jiných assemblerech, stejně jako na opačném konci palety jazyků uživatelé SmallTalku, patrně budou pochybovat o efektivitě takto napsaného programu. Proto jsem mu na zkoušku podstrčil text Bible, který má přes čtyři megabyty. Frekvenční analýza zabrala méně než půl minuty, třídění výsledků trvalo cca jednu sekundu — jak je dobře vidět z časových značek, jež služba NSLog automaticky používá:
Nov 15 05:00:52 Scanning "/Local/Users/ocs/Library/OpenUp/Bible_0/Cznwt.txb" (4325411 bytes)...
Nov 15 05:01:19 done, found 49413 words
Nov 15 05:01:20 sorted, first ten:
Nov 15 05:01:20 jeho (4912)
Nov 15 05:01:20 \U00afekl (3986)
Nov 15 05:01:20 jsem (3539)
Nov 15 05:01:20 jako (3468)
Nov 15 05:01:20 Jehova (3053)
Nov 15 05:01:20 kte\U00af\U00cc (2550)
Nov 15 05:01:20 jejich (2195)
Nov 15 05:01:20 kter\U02dd (2138)
Nov 15 05:01:20 bude (1873)
Nov 15 05:01:20 p\U00afed (1846)
| Zpět | Obsah | Další |
Copyright © Chip, O. Čada 2000-2003