Lamia Labed Jilani
Regional Institute for Research in
Computing and Telecommunications
Cite Montplaisir, Belvedere 1002 Tunisia
Tel: (216) 1 787 757,
Fax: (216) 1 787 827
Email:
lamia.labed@irsit.rnrt.tn
Rym Mili
School of Engineering and Computer Science
University of Texas at Dallas,
Richardson, TX 75028, USA
Tel: (972) 883-2091,
Fax: (972) 883-2349
Email:
rmili@utdallas.edu
Ali Mili
Department of Computer Science, University of Ottawa
Ottawa, Ont. K1N 6N5, Canada
Tel: (613) 562 5800 X 6714, Fax: (613) 562 5187
Email:
amili@csi.uottawa.ca
When one uses informal methods to retrieve a component that satisfies some requirements out of a software reuse library, one cannot distinguish between the retrieved components that do satisfy the requirements and those that merely approximate the requirements (i.e. almost satisfy them). On the other hand, if one uses formal retrieval methods based on precise specifications of components and queries and on formal matching criteria, then one can clearly distinguish between two retrieval methods: exact retrieval, which seeks to identify components that are proved to satisfy the requirements at hand; and approximate retrieval, which is content with components that do not necessarily satisfy but approximate the requirements at hand. In this paper we advocate the need to make the distinction between these two families of methods, and introduce a possible approach thereto.
Keywords: Component based software, software component storage and retrieval, software libraries, software reuse, formal specifications, information retrieval, measures of distance between specifications.
Workshop Goals: Learning; networking; assessing the pertinence of our work; advocating the need for scientifically based methods.
Working Groups: components based software, formal methods, reuse libraries.
Software reuse libraries are reporsitories where reusable software components are stored and retrieved. They play a crucial role in determining the success of a software reuse policy, because they have a profound impact on the practice of software reuse in an organization:
In light of the foregoing observations, one may think that formal methods of software components storage and retrieval are widely used in practice. Yet despite the abundance of such methods, and despite the wide range of cost vs quality that these methods provide [1, 2, 3, 4, 5, 6, 7], they are mostly ignored by industry, in favor of traditional, low-tech solutions that are inspired from information retrieval or from library science [8].
We submit the position that both kinds of methods are needed to do a satisfactory job in component storage and retrieval: traditional retrieval techniques are most useful in the early stages of the search process, when large chunks of the library can be excluded by simple keyword matches; mathematically based techniques are most effective in the later stages of the search process, when a great deal of pprecision is required to discriminate between several candidates which differ only slightly from each other.
One of the key differences between informal retrieval methods and formal retrieval methods is the ability to distinguish between exact retrieval and approximate retrieval. Because informal methods focus on matching component descriptions with user queries, they do not support the idea of correctness: a component may well match the query in all its detail but still fail to be correct (due to a mismatch between the library manager's interpretation of a feature, and the user's); also, a component may fail to match a query but still be correct with respect to the query (the component does satisfy a required feature, but the library manager neglected to record it). Hence, with informal retrieval methods, all retrievals are approximate retrievals: the decision of whether a component is correct (and can be used verbatim), is not correct but is close enough (and can be used after modification), or is not correct and costs too much to modify (and must be discarded) --this decision is taken after the retrieval operation, rather than as part of it.
We have investigated a formal method of component retrieval [3], based on formal specifications and program correctness, and have discussed in turn exact retrieval then approximate retrieval under this method. In this paper, we briefly introduce our main results on approximate retrieval.
In [9], Mili defines four measures of distance between specifications;
we review these measures in turn and see how they can be used to perform approximate
retrieval. Basically, for a given measure of distance, say ![]() , we
consider a reuse library L and a query K, and we seek to identify all the
components C of L that minimize the distance
, we
consider a reuse library L and a query K, and we seek to identify all the
components C of L that minimize the distance ![]() .
.
The first measure of distance is what we call functional consensus. The rationale for this measure can be summarized as follows:
Given a component C and a query K, we consider that C is close to K if C and K have plenty of information in common.Among all the components of the library, this measure will select that which has most information in common with the query.
Given two specifications C and K such that K refines C (i.e. all the requirements information of C is recorded in K). The refinement difference between K and C is the smallest functional increment that we must add to C to obtain K. The rationale of this measure is the following.
Given a component C and a query K, we consider that C is close to K if the amount of functionality of K that is not satisfied by C is small.Note that unlike all other measures of distance presented in this section, the measure of refinement difference is not symmetric.
Given two specifications K and C; the refinement distance between
K and C reflects all the functional information of K that is not
recorded in C and all the requirements information of C that is not
in K. We denote this measure by ![]() .
The rationale of this measure of distance is the following:
.
The rationale of this measure of distance is the following:
The refinement distance reflects two terms: the functional requirements of K that C does not satisfy; and the functional properties of C that K does not need. Ideally, we want to minimize both of these terms: we minimiize the first term in order to have fewer additional features to add to C; and we minimize the second term in order to have fewer irrelevant features of C to deal with when we are modifying C to satisfy K.
The rationale of functional distance is the following:
Given two specifications A and B. The distance between A and B is reflected by two features: the amount of requirements information that A have in common, which is reflected by the functional consensus of A and B (denoted byConsequently, we define the functional distance between A and B as the vector denoted by); and the amount of requirements information that sets them apart, which is reflected by
.
![]()
In order to illustrate how these distances can be used to perform approximate retrieval in a database of software components, we have considered the library of compilers that is presented in [3] and a user query K that no element of the library satisfies. Figure 1 gives a graphic representation of these compilers, where the nodes are ordered by means of the refinement relation.
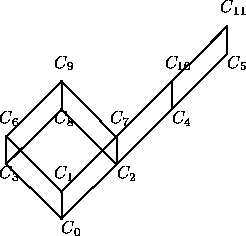
Figure 1: A Database of Pascal Compilers
For each measure of distance (say ![]() ), we consider all the entries
of the original database and compare them with respect to their distance
to specification K. Specifically, whenever component
), we consider all the entries
of the original database and compare them with respect to their distance
to specification K. Specifically, whenever component ![]() is
is ![]() -closer
to K than component
-closer
to K than component ![]() , we draw
, we draw ![]() higher than
higher than ![]() in the new graph;
also, whenever two components
in the new graph;
also, whenever two components ![]() and
and ![]() have the same distance to K
(i.e.
have the same distance to K
(i.e. ![]() ), we represent them at the same node
in the new graph. The graphs that we obtain
for functional consensus, refinement difference, refinement distance
and functional distance are given in figure 2.
On each graph, the specifications that minimize the measure of
distance (hence are prime candidates in an approximate retrieval) are those that
appear at the top of the graph.
), we represent them at the same node
in the new graph. The graphs that we obtain
for functional consensus, refinement difference, refinement distance
and functional distance are given in figure 2.
On each graph, the specifications that minimize the measure of
distance (hence are prime candidates in an approximate retrieval) are those that
appear at the top of the graph.
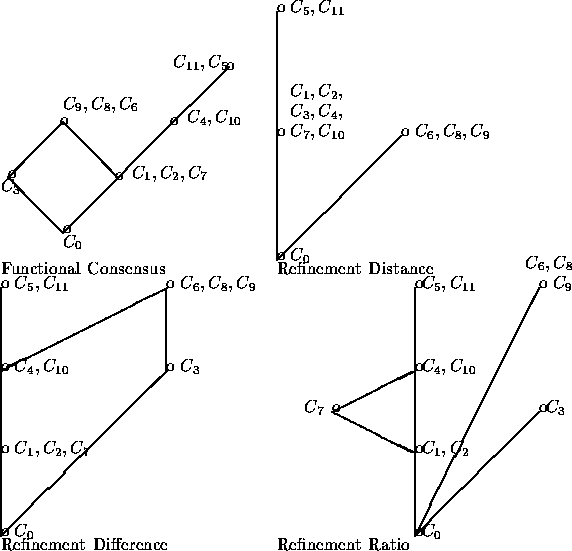
Figure 2: Graphs derived from Measures of Distance
Lamia Labed Jilani holds an Engineering degree in Computer Engineering from the University of Tunis II; she is a PhD candidate at the University of Tunis II and is a researcher with the Regional Institute for Research in Computing and Telecommunications in Tunis, Tunisia. Rym Mili holds a Doctorate in Computer Science from the University of Tunis and a PhD in Computer Science from the University of Ottawa; she is an Assistant Professor of Computer Science at the University of Texas at Dallas. Ali Mili holds a PhD from the University of Illinois and a Doctorat d'Etat from the University of Grenoble; he is Professor of Computer Science at the University of Ottawa.