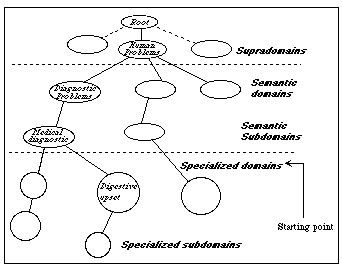
Figure 1: Example of a three-level domain structure
Rafael Capilla
Facultad de Informática
Universidad de Sevilla
Avda. Reina Mercedes s/n 41012 - Sevilla
Spain
Tel: +34 5 455.27.74
Fax: +34 5 455.27.61
Email:
rcapilla@cica.es
This paper outlines an attempt to improve problem-oriented systematic reuse methods. This work, which is part of my doctorate, consists of a model for reusing knowledge from different types of problems using domain analysis methods. The proposed model attempts to reuse the knowledge of analysis and design information from several types of problems grouped in several domains. It tries to improve systematic reuse so we can unify not only domain analysis methods but also classification methods.
Keywords: Knowledge Reuse, Domain Analysis, Domain Engineering, Systematic Reuse, Classification.
Workshop Goals: Systematize domain analysis methods. To define a methodology to reuse knowledge.
Working Groups: Domain Engineering Helps Manage Change - Hype, Myth, Wishful Thinking, or Reality ?, Rigorous Behavioral Specification as an Aid to Reuse, Domain Engineering tools, Object Technology, Architectures, and Domain Analysis: What's the Connection? Is there a connection?.
Although J. Neighbors introduced the concept of domain analysis, there is not yet a unique methodology of doing these tasks in a systematic way. Several authors have made different proposals [1], [2], [3] but they do not agree how this methodology should be carried out. The aim of this work is to improve domain analysis methods and provide guidelines in creating a systematic methodology [4] which can serve to reuse the knowledge of several kinds of problems (organized in several domains) and expressed in terms of analysis and design information.
So far software reuse has evolved from lower levels of abstraction (source code, [5]) to higher levels (specifications, design). Despite the intrinsic difficulty in reusing high level information, the general opinion is that design stays more or less stable, while code is usually very variable and dependent who writes it. This analysis and design information, according to Neighbors [6], provides the most powerful type for reuse.
To promote a large-scale reuse, [7], we should consider systematic reuse methods [8],[9]. Although components reuse is nearly the most common kind of reuse and at times does not turn out to be especially difficult, we should try to reuse sofware elements of higher abstraction levels, such as architectures, specifications and designs, because they are less constrained to future changes. Moreover from the design of a problem, it should always be possible to generate the functional elements of the problem and then the executable code that resolves it.
My interest is centered in the reuse of the designs of problems in a Data Flow Diagram (DFDs) form through a systematic method for domain analysis techniques and for knowledge reuse in general.
This plan focuses on a problem-oriented reuse (top-down), [3], in an effort to eliminate those aspects of reverse engineering of bottom-up processes, that is, independent of ready-made systems or applications. I consider that the root of the problem of domain analysis methods is trying not only a systematic method, but a problem-oriented one.
When reusing the knowledge of various types of problems expressed in terms of analysis, design and/or specification information, there are two fundamental challenges:
The problem of knowledge representation is that we do not have even formalisms to represent all existing knowledge, and much less so one which can represent the majority of cases. The proposed idea of representation consists of four parts:
The model should be organized into a structure of classes according to object-oriented programming. These classes will support the structures of design in a DFD form, as well as a hierarchic domain structure in which the different types of problems are grouped. If we want to reuse it, we have to classify the information beforehand so we can do an effective search of the knowledge from different types of problems when a new problem appears. I propose a structure of domains in three levels [4]:
Figure 1 showing an example of the proposed domain structure.
Figure 1: Example of a three-level domain structure
Specialization domains can be subdivided into subdomains of more specialized problems. For the moment, the third level (and eventually from the second), is the starting point from which we can reuse knowledge from the problems in a more or less effective way, because the knowledge of higher levels is not well defined and is more difficult to formalize.
Futhermore, we have additionally a series of general characteristics applied to problems in different domains as well as a meta-knowledge or higher level knowledge. These two elements help us to represent more knowledge from problems and to discriminate and find reusable design solutions to problems inside the same domain (intra-domain reuse), or in different domains (inter-domains reuse).
One of the objectives in obtaining a systematic method for reusing knowledge is to reduce the number of existing domain analysis techniques. Given that reuse is composed of two sides which are development for reuse and development with reuse, the life cycle model proposed is also two-fold:
a)- Domain engineering (development for reuse)
b)- Reuse engineering (development with reuse)
The part I call Reuse engineering is defined as: the process of reusing reusable components that have (or haven't) passed through a domain analysis process. Specific to our problem is the process of reusing stored knowledge which has passed through a previous process of domain analysis. It comprises the following steps:
In figure 2 we can see the global scheme of the whole process.
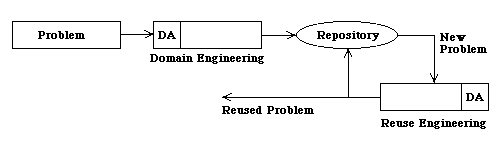
Figure 2: Global diagram of knowledge reuse
Domain and Reuse Engineering stores in the repository the extracted knowledge through domain analysis processes. We define domain analysis as ``the analysis of relevant information of the problems to generate a model of information or knowledge that can be reused to build applications''[4].
The meaning of the definition not only associates the term relevant information with objects and operations, but also includes another set of characteristics such as those mentioned in section 2.2. (general characteristics of problems and domains, meta-knowledge).
Finally, the fundamental steps we propose to do the domain analysis are:
These steps for the proposed method for the domain analysis (DA) are problem-oriented. As an additional feature, we can say that the domain classification method would be able to classify other kinds of reusable components, not only problems.
Some authors like Prieto-Díaz remark that DA is a difficult task for which there is no single methodology, and consequently there is not a unique and systematic methodology.
In the cited references [1], [2] and [3] we can find comparisons of several DA methods. We can see [2] differences among the methods, but there is a common base on which DA methods should be built. Recent DA methods like DARE and ODM are analyzed in references [10] and [11]. Maiden and Sutcliffe [12] [13] attempt to reuse by analogy, but they don't do an explicit DA process of the problem. In addition to DA, there are several forms of classification, like: enumerative, faceted classification [14], hierarchic, etc... .
My current work is aimed at attempting to improve DA methods inside a problem-oriented reuse, and to reduce the existing classification methods making DA processes more systematic by defining the most common stages.
Rafael Capilla is a graduated in Computer Science from the University of Seville (Spain). He worked for two years in a company specializing in communications and computers, and since 1991 to the present, has been employed at the Computing Center in the Faculty of Computer Science at the University of Seville. His work is related to network communications and Unix systems administration.
Also since 1993, he has been working in the field of Software Reuse as part of his Ph. D. research, specifically in the area of Domain Analysis and Domain Engineering. He also participated as a consultant in the European Esprit Orchestra project. His interest focuses to obtain more systematic methods which help reuse of the analysis and design knowledge of different types of problems.