This section describes mosmlyac, a simple parser generator which is closely based on camlyacc from the Caml Light implementation by Xavier Leroy; camlyacc in turn is based on Bob Corbett's public domain Berkeley yacc. This documentation is based on that in the Caml Light reference manual.
The mosmlyac command produces a parser from a context-free grammar specification with attached semantic actions, in the style of yacc. Assume the input file is grammar.grm; then executing
![]()
produces a file grammar.sml containing a Moscow ML unit with code for a parser and a file grammar.sig containing its interface.
The generated module defines one parsing function per entry point in the grammar. These functions have the same names as the entry points. Parsing functions take as arguments a lexical analyser (a function from lexer buffers to tokens) and a lexer buffer, and return the semantic attribute of the corresponding entry point. Lexical analyser functions are usually generated from a lexer specification by the mosmllex program. Lexer buffers are an abstract data type implemented in the library module Lexing. Tokens are values from the datatype token, defined in the interface file grammar.sig produced by mosmlyac.
Example uses of mosmlyac can be found in directories calc and lexyacc under mosml/examples.
A grammar definition has the following format:

Comments in the declarations and rules sections must be enclosed in C comment delimiters /* and */, whereas comments in the header and trailer sections must be enclosed in ML comment delimiters (* and *).
The header and the trailer sections consist of Moscow ML code which is copied into file grammar.sml. Both sections are optional. The header goes at the beginning of file grammar.sml, but after the token datatype declaration; it usually contains open declarations required by the semantic actions of the rules. The trailer goes at the end of file grammar.sml.
Declarations are given one per line. They all start with a % sign.
Declare the given symbols as tokens (terminal symbols). These symbols become constructors (without arguments) in the token datatype.
Declare the given symbols as tokens with an attached attribute of the given type. These symbols become constructors (with arguments of the given type) in the token datatype. The type part is an arbitrary Moscow ML type expression, but all type constructor names must be fully qualified (e.g. Unitname.typename) for all types except standard built-in types, even if the proper open declarations (e.g. open Unitname) were given in the header section. This is because the header is copied only to the .sml output file, not to the .sig output file, while the type part of a %token declaration is copied to both.
Declare the given symbol as entry point for the grammar. For each entry point, a parsing function with the same name is defined in the output file grammar.sml. Non-terminals that are not declared as entry points have no such parsing function. The start symbols must be given a type with the %type directive below.
Specify the type of the semantic attributes for the given symbols. Every non-terminal symbol must have the type of its semantic attribute declared this way. This ensures that the generated parser is type-safe. The type part may be an arbitrary Moscow ML type expression, but all type constructor names must be fully qualified (e.g. Unitname.typename) for all types except standard built-in types, even if the proper open declaration (e.g. open Unitname) were given in the header section. This is because the header is copied only to the .sml output file, not to the .sig output file, while the type part of a %token declaration is copied to both.
Declare the precedence and associativity of the given symbols. All symbols on the same line are given the same precedence. They have higher precedence than symbols declared in previous %left, %right or %nonassoc lines. They have lower precedence than symbols declared in subsequent %left, %right or %nonassoc lines. The symbols are declared to associate to the left (%left), to the right (%right), or to be non-associative (%nonassoc). The symbols are usually tokens, but can also be dummy nonterminals, for use with the %prec directive inside the rules.
The format of grammar rules is as usual:
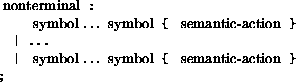
Each right-hand side consists of a (possibly empty) sequence of symbols, followed by a semantic action.
The directive `%prec symbol' may occur among the symbols in a rule right-hand side, to specify that the rule has the same precedence and associativity as the given symbol.
Semantic actions are arbitrary Moscow ML expressions, which are
evaluated to produce the semantic attribute attached to the defined
nonterminal. The semantic actions can access the semantic attributes
of the symbols in the right-hand side of the rule with the $
notation: $1 is the attribute of the first (leftmost) symbol,
$2 is the attribute of the second symbol, etc. An empty
semantic action evaluates to () : unit.
Actions occurring in the middle of rules are not supported. Error recovery is not implemented.
The following command-line options are recognized by mosmlyac:
Generate a description of the parsing tables and a report on conflicts resulting from ambiguities in the grammar. The description is put in file grammar.output.
Name the output files prefix.sml, prefix.sig, prefix.output, instead of using the default naming convention.
Lexical errors (e.g. illegal symbols) and syntax errors can be reported in an intelligible way by using the Location module from the Moscow ML library. It provides functions to print out fragments of a source text, using location information provided by the lexer and parser. See Location.sig for more information.