|
By John R. Haley, President
Viking Software Services, Inc.
One of the often-overlooked and underestimated elements of a document imaging project is the cost to lift data from the images. Systems engineers frequently respond to data entry requirements with automation-only solutions that fail to recognize the accuracy demands of most applications. We have all heard horror stories about lost images due to improper indexing and major errors due to inaccurate invoices or claim forms.
The off-the-shelf key entry component found in most document imaging systems is seldom up to the job. They lack the attention to data entry cultures and automation costs that are critical in high-volume, high-accuracy data entry operations. On-going labor costs for data entry are often the largest element of the operating costs. Unnecessary operating costs result from failure to provide state-of-the-art data entry methods and techniques. Controlling these costs can mean the difference between economic success or failure.
Data Entry Components
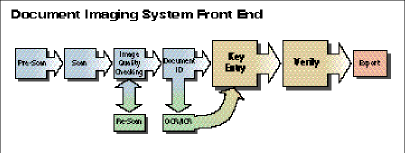
The figure on the following page shows how the data entry components relate to other front end components in a generalized document imaging system. Most data entry modules for image systems were designed by Windows programmers and are excellent for casual use. Nevertheless, they are inefficient for high-volume, high-speed data entry. For decades the national average for keyboard data entry has been about 12,000 keystrokes per hour. Anything less is unacceptable to organizations concerned about costs.
Many document imaging systems are designed to do most of the indexing and data entry by a "keyless" method using ICR (or OCR) engines for automatic character recognition. In well-controlled circumstances this technology will reduce key entry labor dramatically. However, in the real world with uncontrolled documents, recognition rates seldom approach advertised rates. Unrealized expectations and undetected errors cause big problems.
Data errors cause a variety of problems and raise the costs in several areas. The cost to recognize and detect errors is not trivial. Further costs are incurred correcting the data errors. The largest cost components are the hidden costs that affect other departments.
The earlier an error is detected, the cheaper it is to correct it.
Detecting data errors in programs often takes as much, or more, of the anal- ysis and programming efforts than the main logic. The earlier an error is de- tected, the cheaper it is to correct it. Fifty years ago it was common to key-verify punch cards. This technique is still one of the best methods for detecting errors. Re-key verifying selected data items, com- bined with programs that look for invalid data, can detect most data errors.
Correcting errors programmatically is least expensive. Doing it with a single keystroke when the data is initially keyed is the cheapest manual method. Conversely, it costs hundreds, or thousands, times more to create transactions to fix errors that remain undetected until later in the process. The hidden cost of errors can be very high. For example, customer service problems increase proportionately to the number of billing errors or wrong product shipped.
An entire specialty knowledge area has developed around designing and tuning character recognition applications. The state of the art is constantly improving, but it still requires very scarce technical resources to be successful.
Many ICR systems claim 95% to 99% data accuracy. This sounds great on the surface, but in fact may be unacceptably low. Ninety-five percent accuracy means 5% errors. A typical data input transaction consists of more than 60 characters. How many applications with an average of three errors on each transaction would be considered successful?
There are two classes of recognition errors: unrecognized characters--known as rejects--and erroneously recognized characters--referrred to as substitution errors. Rejects must be corrected. Substitutions must first be detected and then corrected.
Today's ICR/OCR systems have un- satisfactory error rates for most real-world documents. Data for computers must be very accurate. The true measure of the value of ICR must include the cost of error correction. This is highly application- dependent. Many ICR projects are highly successful, but others cost more than simply keying the data.
On the surface, reject re-entry seems simple and straight forward. An image of the rejected character is presented to the keyer who depresses the correct character key, prompting the program to move to the next reject character.
When the recognition engine cannot separate adjacent characters and treats them as single, unreadable characters, the operator must be able to quickly insert extra characters. Also, extraneous marks on the paper may appear as an additional unrecognized character which the operator must delete.
Keying data from images should be slightly faster than the national average of 12,000 keystrokes per hour for keying from paper.
The goal of
ICR/OCR is to
avoid key entry.
With some systems, reject re-entry keying rates may be only 5% to 10% as fast as full keying rates. One reason for the slower rate is the fact that keyers who are presented with only a single character at a time cannot build any rhythm. Smooth keying rhythm is essential to fast keying. Reject characters often occur together so the ability to simply re-key the entire field, or even the entire record, greatly speeds up reject re-entry rates. This is because the operator can often key the entire field faster than repairing several rejects.
By referring to the figure at the top of the following page, it is possible to see how two factors influence the cost to repair rejects:
* Accuracy of the recognition engine
* Reject re-entry speed.
The following figure shows the relationship of these factors to the cost, as compared to simply keying the data. If the recognition engine is only 90% accurate and the reject re-entry rate is only 10% as fast as full keying, it is just as cheap to key the data.
Conversely, increasing the recognition to 95% will make it very worthwhile. Increasing the reject re-entry rate also leads to substantial cost reductions.
Reject repair programs for high-volume applications must be well designed to be cost-effective. The value of recognition engines depends on many factors and it is highly application dependent.
When evaluating the cost of substitution errors, consider first the error detection component. Correcting substitutions is harder than rejects because the recognition engine finds the reject errors. The challenge is finding the substitution errors that fooled the recognition engine.
Some errors can be detected programmatically using spelling checkers, database look-ups, deduction from other data, balance calculations and semantic analysis.
There are also two manual error detection methods. Proof-reading (or sight verification) is the most common. It is not especially accurate because the mind has a way of fooling the eyes.
Re-key verify is the time-proven method of manual error detection. Over decades of use it has been proven to be 99.9% accurate. The cost is similar to the cost of keying the data. However, usually not all of the data has to be verified, which saves time. Data elements that can be programmatically validated, or whose accuracy is not important, do not need to be key-verified. Good data entry programs have this capability. Verifying only sample portions of the data is a statistical method used to detect problems with equipment and personnel.
Once the error has been detected, it must be corrected. Some systems allow the error detection program to mark substituted characters as rejected characters and send the data record and its image back through the reject re-entry process. Re-key verify programs should provide an efficient method for immediate error correction. Some are more efficient than others. Operating costs can run for the lifetime of the project and are much higher than the acquisition and implementation costs. The four principal cost elements are:
* maintainance costs
* data accuracy
* keying speed
* controls and auditing.
Re-key verify is the time-proven method of manual error detection.
Several questions nust be answered when evaluating maintenance costs: What are the annual maintenance fees for licensed software? What will it cost to maintain the hardware? How much will it cost to maintain and enhance products developed in-house? What will it cost to maintain the skill levels of in-house developers?
The importance of data accuracy topic has already been addressed in this white paper. The focus will now shift to data accuracy-related techniques and methods data entry software should offer. These features that will be found in good key-from-image programs.
Validation Features are very important and there are several to consider.
Character sieves. The first line of defense against keying errors is eliminating invalid keystrokes as they occur. Alpha characters should not be allowed in numeric fields and more sophisticated single character validations are required.
Field edits. As soon as a field is entered, it needs to be edited, or validated. A wide variety of edits are required, ranging from simple numeric range checks to database look-ups and computed values. There should also be a mechanism for easily adding custom edits that are unique to the application.
High-speed table look-ups. Comparing field values with database tables of acceptable values and other information is one of the most important types of field edits. Table look-up with substitution is a valuable keystroke saver that improves productivity. However, this process must be extremely rapid and efficient, never delaying the keyer. Table look-ups that disrupt keying rhythm may be counter-productive.
Computed values. The system must provide for flexible and fast field edits to compute values based on one or more data fields and database values.
Check digits. Many fields, such as account numbers, have a self-checking digit in the number that can be used to detect errors in the value.
Field duplication. The ability to duplicate data from values in previous fields and images reduces keystrokes.
Context-sensitive help. The system should provide on-line help to guide the keyer in the rules for entering data. Help messages should present information for the data field being keyed. It should require a minimum of keystrokes to request and terminate the help messages.
Optional and required fields. Some optional fields are seldom entered so keyers will be more productive if the default is to automatically skip them. The best systems have the ability to dynamically skip fields based on the data entered in previous fields.
Moving beyond validation features, re-key verify is a time-proven technique for improving data accuracy. Accuracy is much better when the keyer doing the verify step is not the one who originally entered the data. To be cost effective, this process must be very efficient.
Many factors influence keying speed. There is no single overriding factor, but rather a series of items that enable the keyer to reach maximum potential. Interestingly, studies have shown that the fastest keyers are also the most accurate. This means that these ergonomic factors are important even if you do not expect blinding speed from the keyers.
Rates of 12,000-20,000 key strokes per hour can only be achieved with well designed data entry systems that promote keying rhythm, and minimal hand movement. Techniques and methods for high-speed key entry are evidently not widely understood and appreciated. A new generation of analysts that has grown up with a mouse has no concept of what is involved in keying at 20,000 keystrokes per hour. Production data entry is very different from the casual data entry used with spreadsheets, databases and other transaction-oriented applications.
Rhythm is a very important factor in high-speed keying. Fast keyers look ahead. There is a discernable time lag between the eyes and the fingers. It is important to display the proper amount of the image. The fastest keyers traditionally have used the so-called "029 keypunch" keyboard layout with the numeric keys underneath the right hand. This allows alphanumeric characters to be keyed at the maximum rate without moving the hands from the home keys.
Cost to Correct Rejects
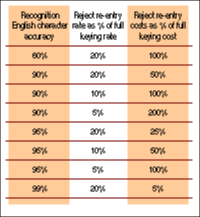
The table at right shows the labor cost to correct rejects compared to simply keying all of the data from scratch. Two factors influence reject re-entry costs: (1) accuracy rate of the recognition engine, and (2) speed at which rejects can be corrected.
The better the recognition accuracy, the fewer rejects to be corrected. Reject re-entry rate is the other factor.
Data entry systems use the ENTER key to complete data fields. It is a large key under the strong right hand. Windows uses the TAB key for this purpose. It is a small key located under the left hand. This use of the TAB key makes it unavailable for tabbing over optional fields. Statistics should be kept regarding the number of errors and who made them. This is useful both for evaluating the keyers and refining the system. It has often been said that if you can't measure it you can't manage it.
The traditional metric for data entry systems is keystrokes per hour. However, this may not be applicable for image data entry or reject re-entry. It is a good comparative measure for keyers doing the same work. A better metric may be error-free records per hour, or documents per hour. Documents per hour is better for evaluating changes to the system.
The data entry supervisor must be able to monitor and control work in the system. The system must in turn be auditable to ensure that all the work has been processed. There are several required features.
File/batch avigation allows users to view various images and data including previously entered work. Search mechanisms find records and images based on data contents. The ability to easily change keyed data and data from recognition engines provides necessary flexibility. Character insert/delete with both type-over and insert mode are also needed.
The costs required to develop the data entry component of document image systems vary widely. Look for systems that provide easy-to-use tools to create applications quickly. Beware of closed and proprietary technology that require extensive training.
Summary
Data entry often contributes the largest cost component to document imaging systems. Costs can be classified into four categories:
*data capture costs
*error detection costs
*error correction costs
*hidden costs.
Well-designed systems minimize these costs, but attention to detail and time-proven ergonomic techniques are essential. Keyless data entry technology is improving, but manual data entry and reject re-entry is going to be required for years to come. Organizations will not be well-served by glossing over this issue. Rather, they should be certain that the data capture components of their document imaging systems are well-suited to their requirements. Superior data entry modules are available as off the shelf products.
Viking Software offers ImagEntry which meets all the above requirements for keying data from images. *
Viking Software Services, Inc., 6804 South Canton Avenue, Tulsa, OK 74136-3419; Phone: 918-491-6144; Fax 918-494-2701; E-mail 71411,212@compuserve.com
John R. Haley is president and co-founder of Viking Software Services, Inc., a major supplier of data entry software products in the United States and other countries. He helped start the computer department at Continental Oil Co. (Conoco) and was an executive with one of the country's largest data entry service companies.
IW Special Supplement, March 1996
|

