
Egy rövid bevezetőt szeretnék közreadni,
hogy mire lehet pl. jó eddigi kínlódásunk. A minap történt velem:
Egyik ismerősöm adott egy winchestert,
hogy segítsek rajta, mert eltűnt róla minden. Ez majd egy éves
teljes számlázást, könyvelést meg hasonlókat tartalmazott. Első kérdésem
mentés (backup) mikor volt utoljára ? Hááát ..., szóval nincs ... Ez egy
40MB-os, régi winyedli volt, s kb. 4 MB nélkülözhetetlen DBase adatbázis
volt rajta. Hogy mi is a hibajelenség:
-
Egyik este lekapcsoltam a gépet másik nap meg be, s se kép – se hang.
Rövid kutakodás után kiderült, hogy a partíciós tábla, ill. a FAT
mindkettő teljes példánya "eltűnt". Ezek után egy átlag felhasználó
feladná, persze feltételezve, hogy eljutott odáig,
hogy mi a hiba. De az informatIQus próbál valamit tenni. (Remélem az előző
cikkek alapján nem kell magyaráznom, hogy FAT nélkül, lehetetlen kiolvasni
a winyedliről, hogy hol – mi volt, hisz a töredezett file-ok össze-vissza
vannak.) Visszatérnék arra, hogy eltűnt
a FAT, meg a partíciós tábla: Hogy tűnhet
el ??? Feltételezésem, ill. a tények:
-
Vagy valami program, vagy tényleg csak úgy "spontán eltűnt"
a partíciós tábla.
-
Ennek örömére egy Norton Utilities DiskDoctor-t engedett rá, ami ilyenkor
többet árt, mint használ. S látván, hogy nem lett jobb a helyzet, a winyedlit
kivette a 386-osból, majd egy ismerősénél
egy Pentiumba dugva, vizsgálták tovább.
Ekkor szerintem még fent volt a FAT a
winyedlin, csak a partíciós tábla hiányzott.
-
Majd a Pentiumos gépen auto-hard-disk-detect-tel a setup-ból beállították,
s egy újabb NDD-t engettek rá. Mivel az auto-HDD-detect NEM azt a cylinder-sáv-fej
kombinácót állította be az NDD feltételezve, hogy rossz helyen van a FAT
(a más beállítások miatt) LETÖRÖLTE a rossznak vélt FAT-ot, majd valami
össze-visszaságot írt fel.
-
Így elveszett a FAT, s annak reménye is, hogy visszaállíthatóak legyenek
a DBF állományok.
-
Ekkor jöttem én a képbe.
-
Gondoltam, ha már van egy file-kezelő objektumom
akkor használhatnánk is.
-
Csak valahogy vissza kellene állítani a DBF-eket.
-
Feltételezve, hogy a DBF nem sérült, s ezt bizonyították a DiskEditor-ral
történt vizsgálódásaim is: A root-entry, a többi könyvtár struktúra megtalálható,
s jó. Csak az a fránya FAT.
-
Tehát meg vannak a DBF-ek darabjai "csak"
megfelelő sorrendben össze kell fűzni.
-
Első próbálkozásom, hogy dátum szerinti sorrendben
fűzöm össze a DBF-rekordjait tartalmazó cluster-eket, csak a ciki
az, hogy a DBF-en belűl nem rendezetten
voltak.
-
Ezután jött a briliáns ötlet:
Tudjuk, hogy meg van a DBF minden cluster-e, csak a sorrend a kérdéses.
Készítsünk egy olyan rekurzív, backtack-es algoritmust mely létrehozza
a helyes összecsatolási sorrendet. De hogy ? Lássuk, hogyan helyezkedik
el a DBF állomány a winchester-en:
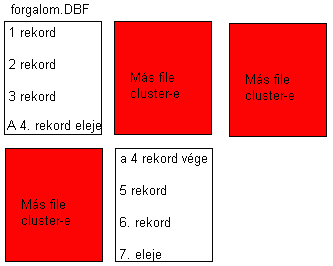
Láthatjuk, hogy egy cluster-be nem fér éppen annyi rekord, hogy tele
legyen, így az utolsó rekordnak csak az eleje van az X. cluster-ben, míg
egy másik cluster-ben (amit egyenlőre nem
ismerünk) van a rekord vége. Mivel a rekord mindig ugyanúgy épül fel kiszámíthatjuk,
egy mezőből, pl. a számla dátumából, hogy a cluster-en belűl, hol is kezdődik
az utolsó rekord.
Kitudjuk azt is számolni, hogy mennyi
byte van az X. cluster-ben és mivel ismerjük a rekord byte-ban mért
hosszát tudjuk mennyi byte kell a teljes rekordhoz. Olyan cluster-eket
keresünk, - igen helyes a többes szám mivel többet fogunk találni - , amelyeknek
az elején éppen a szükséges töredék hosszú rekord található. (Ezt hasonló
módon nézzük meg: a Y. az X. hez illeszkedő
cluster darab, töredék DBF rekordja utáni első rekordjának címe – 1 egyenlő
lesz az Y. cluster-ben a töredék rekord hosszávan.) Ha X. töredéke és Y.
elején a töredék byte hossza = egy rekord hosszával, akkor az a cluster
az előzőhöz illeszkedik.
DE persze nem biztos, hogy csak
az jó oda, hisz több hasonlóan jól illeszkedő cluster van. Ahogy fent említettm
sajnos nem járható út két cluster összeillesztésénél, - feltéve, hogy összeillőek
-, hogy az X. cluster dátumát hasonlítom össze az Y.-éval.
Ekkor az ötlet, hogy bízzuk a gépre az összeállítás sorrendjének kidolgozását,
egy rekurzív - back-track algoritmussal.
Mert tudjuk, hogy CSAK EGY helyes összeállítási sorrend létezik, akár
egy törött vázánál. Hisz, ha rossz helyre illesztjük az egyik darabot akkor
végül lesz olyan darab melyhez már nem találunk hozzá illeszthetőt.
Az algoritmus: Van egy rutinunk mely ellenőrzi
hogyha az X. cluster-hez, az Y-t illeszteném (csak akkor próbálja egyáltalán
ha illeszkedik hozzá, a rutin a több illeszkedő közül az egy helyeset keresi),
szóval ha X-hez Y-t illesztem akkor végigpróbálgatva az összes többit lesz
–e minden cluster-nek illeszkedő párja.
Ha nem akkor van másik illeszkedő,
sőt oda illő cluster is.
Ha igen akkor rutinunk megtalálta
az oda illő darabot, s folytathatja a Y. törött rekordjához illő Z passzoló
cluster-t. (Ha gondolkodunk lényegében csak egyszer fut le a rutin
de mivel a felépítgetés, annyi szintű
ahány cluster közül lehet választani marha nagy memória, ill. CPU igényű,
hisz sokáig tarthat. Igy nem ajánlatos sima DOS módban, hanem inkább védett
módban az ilyen algoritmust megírni.)
Első hallásra nehéz lehet megérteni a rutin
teljes mibenlétét, de olyan veszettül nehéz. Pár apróság azoknak,
akik megértették legalább a rutin alapjait.
-
Hogyan tudom meg, hogy az összeillesztett
rekord (X és Y cluster-ből), jó –e ?
Első lépés az összeillesztett rekordot
először is egy TDBFRekord típusú rekordba kell másolni, ami a DBF rekordjainak
mintájára van felépítve. Ha ennek a rekordnak a mezői helyesek, az-az a
dátum 199x-et tartalmaz, stb.
-
Az összeillesztés, hogy megy?
1, Move(Ptr(Seg(XCluster),Ofs(XCluster)+Clusterméret-töredékhossz)^
, DBFRec, töredékhossz);
2, Move(YCluster, Ptr(Seg(DBFRec), Ofs(DBFRec)+töredékhossz)^,
rekordméret-töredékhossz);
-
Az ellenőrzésre meg van egy ValideRecord():
Boolean függvény.
Konklúzió, tanácsok:
-
Ha valami rejtélyes módon nem tudsz boot-olni
gépedről kezd gondolkodni, mi is lehet az oka ? Vírus ? Esetleg valami
program letörölte a partíciós táblát ? Vagy netán WIn95-öt installáltál
? Vagy te törölhetted le nagy programozásban Int 13h-mal ?
-
Ha tudod a kezdeti félelmeidet legyőzve,
használd az eszed s ne vaktába össze-vissza csinálj mindent.
-
Ha minden a HDD-n lévő fontos dologról
van mentésed akkor legegyszerűbb egyet
formázni.
-
Ha volna mit lementeni, próbáld meg Norton Utilities DiskEditorral rendbe
hozni a partíciós táblát, vagy a boot-rekordot ha az a hibás. ÉS NE NDD-t
futtas, mert az általában csak tönkreteszi a FAT-ot, vagy a könyvtárstruktúrát
nagyobb sérülés után. (A fenti példa csak részint bizonyítja ezt, de már
sok esettel találkoztam amikor az NDD tette reménytelenné a visszaállítás
lehetőségét.) Ha nem vagy ismerős a DOS file-kezlésének
mélységeiben, keres szakembert (pl. eMail-ezz
nekünk, megpróbálunk segíteni.). Ha mindenképpen NDD-zni akarsz akkor meg,
minden alkalomnál amikor az NDD felkínálja készíts NDD Undo file-t.
-
A NU DiskEdit-ben van egy hiba javító lehetőség,
az úgyn. Advanced Recovery. Ez akkor jó ha teljesen ismeretlenek a partíciós
tábla adatai.
-
Mielőtt magad a DE-vel munkához látnál fog
papírt, cerzát, s mindig írd fel mit, hogyan változtattál. Olyan
dolgot NE csinálj amiben NEM vagy BIZTOS !
-
Jótanács: gyakrak speed-disk-el a HDD-det, pl. havonta egyszer (persze
lehet többször is: J ),
ill. egy ARJ-ben tárold a HDD-den a legfontosabb dolgokat. Ez azért előnyös,
mert ha egy ARJ-ben van és elszáll a FAT akkor az ARJ egy darabban
található (a speed-disk miatt) és ezt a FAT kézi feltöltésével visszanyerhetjük.
-
Persze az esetek 80%-ban marad a HDD-n olyan dolog ami nincs elmentve,
vagy régi a mentés, és akkor jöhet a kínlódás: pl. a fent említett módszer
ami meglehetősen sok türelmet, és jártasságot
igényel.
-
Vannak cégek akik a hibás HDD-kről való adatvisszanyeréssel
foglalkoznak (Ők, a fizikailag hibás, pl. leejtett, megégett, stb. HDD-kkel
is foglalkoznak, én csak a logikai hibákról írtam.). Szóval ezen cégek
visszanyerik nekünk adatainkat csak a kérdés, hogy mennyiért ?
Általában horribilis összegeket kérnek
a csak logikailag hibás HDD-kért is.
Ha meg fizikailag hibás a HDD akkor csak
egy BANK, stb. számára megfizethető, lévén, hogy speciális a technika mellyel
visszanyerik. (Ne írjon senki, nem mondok cégnevet.)
-
Tizedik pont, az eszmefuttatásból elég, jöjjön
a mai anyag ! De előtte remélem elrémítettelek annyira, hogy gyorsan készítesz
mentést a legfontosabbakról.
Handle-s file-kezelés
Ugorjunk a közepébe ! Mivel kezdjük a file-műveleteket
? File-nyitással ! Lássuk:
function TR4sFileDOS.OpenFile(Name: TASCIIZ; AccessMode:
Byte; var Handle: Word): Boolean;
function GetFirstFreeHandle: Word;
var i: Word;
begin
for i:=6 to 55 do
if Not IsUsedHandle[i] then
begin GetFirstFreeHandle:=i; Break; end;
end;
-
Ez a lokális rutin megkeresi az első szabad
handle-számot, amit handle-ként a későbbiekben visszaadhatunk.
var
FFDataBlock: PFindFileDataType;
NameS : String;
begin {first handle 0006h; AccessMode = FileMode}
if FindFirstFile(Name, AnyFile and
((Not Directory) and (Not VolumeID)))
-
S lőn csoda, feltalátuk a spanyolviaszt, hogy
keresünk file-t ? FindFile()-al. Ha nem találjuk a file-t, rögtön kiugrunk,
ha igen, továbblépünk.
then begin
NameS:=ConvertASCIIZToString(Name);
NameS:=UCaseString(UTrim(NameS)); FFDataBlock:=DTA;
if NameS[2] = ':' then Delete(NameS,
1, 2);
repeat
Delete(NameS, Length(NameS),
1);
until NameS[Length(NameS)]
= '\';
if Length(NameS) > 2 then
Delete(NameS, Length(NameS), 1);
NameS:=Slasher(NameS) + FFDataBlock^.FileName;
-
Idáig azt tettük meg, hogy a rutinnak megadott Name: TASCIIZ-t NameS: String-gé
konvertáltuk. Mivel a megadott Name tartalmazhat joker karaktert így a
FindFirstFile() által szolgáltatott megfelelő
file nevét kell az útvonal végére biggyesztenünk.
Az UnSlasher() rutin az útvonal végéről
leszedi a \ (slash) karaktert, míg
a Slasher() pedig rak az útvonal string
végére egy \-t ha nincs még ott.
repeat
Delete(NameS, Length(NameS), 1);
until NameS[Length(NameS)] <> #0;
Handle:=GetFirstFreeHandle;
-
A Handle egy cím szerint visszaadott érték,
melynek most a fenti rutin számolja ki eredményét. Értéke az első üres
handle.
Handles[Handle].Path:=NameS;
Handles[Handle].Entry:=AEntry;
-
A handle-höz tartozó file-bejegyzés száma.
Handles[Handle].Position:=0;
-
A handle aktuális file-pozíciója.
Handles[Handle].OwnerDIR:=FFDataBlock^.OwnerDIRStartClus;
-
S a file-nevét tartalmazó könyvtár kezdő cluster-ének
számát is elmentjük.
IsUsedHandle[Handle]:=True;
OpenFile:=True;
-
A file-t megnyitottá, s használttá tesszük.
end
else
begin
Handle:=0;
OpenFile:=False;
-
Ez a sikertelen file-nyitás eredménye.
end;
end;
Hogy ne a levegőbe beszéljek elmondom –
igaz pár számmal régebben már elmondtam -, hogy a handle-s file-kezelés
részint azért jobb, mert nekünk csak a megnyitott file sorszámával kell
dolgoznunk, s DOS tárolja a megnyitott file-hoz tartozó információkat.
Mivel saját file-kezelést írunk ezért most mi tároljuk a file-handle-höz
tartozó információkat, egy rekord-tömbben.
{TR4sFileDOS = object}
private
Handles : Array[6..55] of THandle;
end
type
PHandle = ^THandle;
THandle = record
Path : String[80];
Entry : TDirectoryEntry;
Position: Longint;
PosZero : Boolean;
OwnerDIR: Word;
end;
Nos láthatjuk, hogy 6..55-ig 50 szabad handle van. (0-5-ig DOS által
foglalt, s mi is alkalmazkodunk ehhez.) A THandle rekord meg mindent tartalmaz
ami kellhet.
Lássuk a file-lezérását:
function TR4sFileDOS.CloseFile(Handle: Word): Boolean;
begin
if IsUsedHandle[Handle] then
begin
IsUsedHandle[Handle]:=False;
FillChar(Handles[Handle], SizeOf(Handles[Handle]),
0);
CloseFile:=True;
end else begin
Error:=R4sFDOS_InvalidHandle; CloseFile:=False; end;
end;
Bármely megnyitott file lezárható.Viszont ha rossz handle-számot adunk
meg, és az épp nem megnyitott file-hoz tartozik akkor hibát kell jeleznünk.
Lássuk a handle-ös file-olvasást. Remélem nem leszek nagyon érthetetlen:
function TR4sFileDOS.ReadFromFile(Handle: Word; var ByteToRead:
Word; var Buf; BufSize: Word): Boolean;
var
{... fölösleges a változóneveket itt az újságban is leírni}
begin
if IsUsedHandle[Handle] then
begin
-
Áhá: már megint előjött egy ellenőrzés: hogy
jó file-handle-t adtunk –e meg ? Ha igen folytathatjuk:
ErrProc:=False;
if BufSize < 4096 then NeedLocalBuf:=True
else NeedLocalBuf:=False;
-
Megállapítjuk, hogy kell –e a rutinnak magának létrehozni lokális buffer-t
?
(Ha 5 byte-ot akarunk csak beolvasni akkor is kell legalább egy 4 KB-s
buffer.
Viszont ha 4 KB-nál nagyobbat akarunk beolvasni akkor nem kell lokális
buffer, hiszen a rutinnak megadott buffer használhatjuk átmeneti célokra
a rutinban is.
Hogy kell –e buffer a NeedLoaclBuf: Boolean tárolja.)
if BufSize < ByteToRead then begin ByteToRead:=BufSize;
ErrProc:=True; end;
-
Ha kisebb a kintről megadott buffer, mint
amennyi byte-ot kell beolvasni, akkor hibát kell jelezni, hisz nem lesz
hova beolvasni.
if NeedLocalBuf then
begin
New(LocalBuf);
FillChar(LocalBuf^, SizeOf(LocalBuf^), 0);
ToBuf:=LocalBuf;
end
-
No tessék ha kell, akkor itt á létrehozzuk
a lokális buffer-t.
else begin
FillChar(Buf, BufSize, 0);
ToBuf:=@Buf;
end;
-
Ha nem kell akkor csak a ToBuf: Pointer-nek adjuk a kinti buffer címét,
amivel elérjük, hogy biztosan a ToBuf : Pointer jó buffer címet tartalmaz.
(Vagy a kintiét, vagy a belsőt, de lehet használni.)
MustRead:=ByteToRead; WasPosZero:=False;
-
A MustRead-ben eltároljuk a beolvasandó byte-ok számát, s kezdeti változó
inicializálást végzünk.
if (Handles[Handle].Position <> 0) or Handles[Handle].PosZero
then
begin
if Handles[Handle].PosZero then
begin
Handles[Handle].PosZero:=False;
WasPosZero:=True;
end;
PosDiv:=(Handles[Handle].Position + 1) div (BootInf.Byte_Sector
* BootInf.Sector_Cluster);
PosMod:=(Handles[Handle].Position + 1) mod (BootInf.Byte_Sector
* BootInf.Sector_Cluster);
-
Ez egy fontos momentum, a PosDiv, ill. PosMod kiszámítása, hogy mennyi
szektorral beljebb kezdődik a kiolvasandó
adat, ill. az adott szektor hányadik byte-jától, ha az aktuális file-pozíció
nem osztható maradék nélkül a cluster/byte-tal ill.
end else begin PosDiv:=0; PosMod:=0; end;
{PosDiv, and PosMod are Cluster "orianteted" variables}
MaxCluster:=(Handles[Handle].Entry.FileSize div (BootInf.Byte_Sector
* BootInf.Sector_Cluster));
if Handles[Handle].Entry.FileSize mod (BootInf.Byte_Sector
* BootInf.Sector_Cluster) <> 0 then Inc(MaxCluster);
-
A MaxCluster változó megadja, hogy maximum mennyi cluster szükséges a file
eltárolásához. (Megjegyzem, most ahogy ezt nézem nem lesz szükség rá a
későbbiekben.)
Cluster:=Handles[Handle].Entry.ClusterNumber;
-
A kezdő cluster ahol a file kezdődik, a THandle
információs rekordban található.
if PosDiv <> 0 then
for i:=Handles[Handle].Entry.ClusterNumber to Handles[Handle].Entry.ClusterNumber+PosDiv-1
do
Cluster:=GetIndexFromFAT(FAT, Cluster);
-
Mivel a kiolvasandó adat nem biztosan a file
elején kezdődik (Pos<>0) így el kell ugrálnunk arra a cluster-re ahol
a kiolvasandó adat van. Hisz a cluster a file első cluster-e, és a file
nem folytonosan helyezkedik, így nem adhatunk a cluster-hez pl. X-et. Hanem
a FAT-on keresztül el kell ugrálni az X-dik cluster-re.
S itt kezdődik maga a rutin mely kiolvassa
az adatokat a FAT segítségével:
OK:=False; Res:=0;
repeat
ClusToRead:=0;
StartCluster:=Cluster;
repeat
Inc(ClusToRead);
if GetIndexFromFAT(FAT, Cluster) >= Cluster12_EOF
then Break;
if Longint(ByteToRead) <= Longint(Longint(ClusToRead
+ Res) *
Longint(BootInf.Byte_Sector)
* Longint(BootInf.Sector_Cluster) ) then Break;
NotINC:=False;
if GetIndexFromFAT(FAT, Cluster) = Cluster
+ 1 then Cluster:=GetIndexFromFAT(FAT, Cluster)
else NotINC:=True;
until (GetIndexFromFAT(FAT, Cluster) <> Cluster
+ 1);
-
Ennek a ciklusnak az a lényege, hogy megnézi, a beolvasandó adatból mennyi
helyezkedik el egymás utáni cluster-en hisz, pl. ha 64 KB-os darabban akarunk
file-t kiolvasni akkor szükséges, hogy ne egy darab cluster-t olvassunk
majd ugorjunk a következőre, és csak azután
olvassunk hanem: megnézem mennyi cluster helyezkedik el egymás után fizikailag
a lemezen, s egyszerre olvasom be gyorsan az összes egymásutáni X db cluster-t.
Ez gyorsít az olvasáson.
-
Hogy teszi ezt ez a ciklus ?
Három fő vizsgálat van:
1, elértük –e a file végét a FAT szerint
az-az a FAT megfelelő indexén $(F)FFF van –e ?
2, az annyiadik cluster-nél tartunk amennyit
max. be kell olvasni –e ?
3, a file következő darabja a FAT X. indexén
lévő következő index, (ez a file következő cluster-ének
címe) tehát a FAT x. indexén lévő index egyenlő –e x+1-gyel. Ha igen akkor
a file x. és x+1. cluster-e egymás után van fizikailag. (És így majd egy
szuszra beolvashatjuk.)
TempW:=GetIndexFromFAT(FAT, Cluster);
if ((TempW >= Cluster12_EOF) or (TempW <> Cluster
+ 1)) and (Not NotINC)
then Inc(ClusToRead)
else NotINC:=False;
-
Ez egy vizsgálat, hogy file-vége (EOF) miatt léptünk –e ki, ha igen akkor
növeljük eggyel a beolvasandó cluster-ek számát, he nem a NotInc = False.
Res:=Res + ClusToRead;
-
A Res változó megadja az eddig bolvasott cluster-ek számát, ebből
tudja meg majd a legkülső repeat-until, hogy ki lehet lépni –s a ciklusból
mert elértük –e a bolvasandó byte-ok számat.
ReadnLogigalSector(ConvertClusterNumberToLogicalSector(StartCluster),
ClusToRead, ToBuf);
-
ÉS TESSÉK: bolvassuk egy szuszra a cluster-eket a fenti ToBuf: Pointer
által definiált területre. (Nyílván ha nem folytonosan vannak a cluster-ek
akkor itt csak egy cluster-t olvasunk be.)
ToBuf:=Ptr(Seg(ToBuf^), Ofs(ToBuf^) + Word(ClusToRead * BootInf.Byte_Sector
* BootInf.Sector_Cluster));
-
Beállítjuk a ToBuf: Pointer Offset-jét, ha lesz még cluster amit be kell
olvasni akkor a memóriában az jó helyre kerüljön.
Cluster:=GetIndexFromFAT(FAT, Cluster);
-
A következő cluster-re ugrunk, a FAT segítségével.
until Longint(ByteToRead) <= Longint( Longint(Res) *
Longint(BootInf.Byte_Sector) * Longint(BootInf.Sector_Cluster)
);
-
S amint mondottam ez a kűlső repeat-until
addig pörög míg be nem olvastuk a megfelelő számú byte-ot.
ByteToRead:=Res * Word(BootInf.Byte_Sector * BootInf.Sector_Cluster);
if ByteToRead > MustRead then ByteToRead:=MustRead;
-
A visszaadott beolvasott byte-ok számának meghatározása.
if PosMod <> 0 then
if NeedLocalBuf then
BringDecedXByte(LocalBuf^, Seg(LocalBuf^), Ofs(LocalBuf^),
Word(PosMod), SizeOf(LocalBuf^))
else BringDecedXByte(Buf, Seg(Buf), Ofs(Buf), Word(PosMod),
BufSize);
-
Ha a szektornak nem az elejéről kezdtük el
a beolvasást akkor megfelelően a Buffer tartalmán annyival előrébb kell
hozni.
if NeedLocalBuf then begin Move(LocalBuf^, Buf, ByteToRead);
Dispose(LocalBuf); end;
-
Ha volt lokális buffer akkor annak tartalmát
a külső buffer-be másoljuk.
if (Handles[Handle].Position = 0) and (Not Handles[Handle].PosZero)
then Handles[Handle].PosZero:=True;
if (Handles[Handle].Position = 0) and (Not WasPosZero)
then Handles[Handle].Position:=ByteToRead - 1
else Handles[Handle].Position:=Handles[Handle].Position
+ ByteToRead;
-
Az aktuális file-pozíció beállítása.
if ErrProc then ReadFromFile:=False else ReadFromFile:=True;
-
A függvény Boolean visszatérési értékének beállítása: True ha teljesen
sikeres volt a beolvasás.
end else
begin FillChar(Buf, ByteToRead, 0); ByteToRead:=0; ReadFromFile:=False;
end;
-
Ez az ELSE ág pedig arra vonatkozik, ha rossz handle-t adtunk meg.
end;
Nos ennyi lett volna maga a beolvasó rutin, nem olyan ördöngös, de azért
nem mondom, hogy könnyű volt mikor
lassan két éve írtam.
Lássuk a file-ban történő seek-elést.
3 féle seek-elés van:
-
00h – a file elejétől történő seek-elés.
-
01h – a mostanihoz képest a seek-elés (+/-)
-
02h – a file végéhez képest. (így abból kivonódik)
function TR4sFileDOS.SeekFile(Handle: Word; SeekType:
Byte; var Pos: Longint): Boolean;
begin
if IsUsedHandle[Handle] then
case SeekType of
$00: begin Handles[Handle].Position:=Pos; SeekFile:=True;
end;
$01: begin Handles[Handle].Position:=Handles[Handle].Position
+ Pos; SeekFile:=True; end;
$02: begin Handles[Handle].Position:=Handles[Handle].Entry.FileSize
- Abs(Pos); SeekFile:=True; end;
else begin Handles[Handle].Position:=Pos;
SeekFile:=True; end;
end else begin Pos:=0; SeekFile:=False;
end;
end;
Ez a rutin pedig az aktuális file-pozíciót kérdezi le:
function TR4sFileDOS.GetFilePos(Handle: Word): Longint;
begin
if IsUsedHandle[Handle] then GetFilePos:=Handles[Handle].Position
else GetFilePos:=$FFFFFFFF;
end;
Nos a Tippek – Trükkök rovat mai száma zárul. S ha minden igaz a DOS
file-kezelését is lezárom. (Hacsak olvasó kérdések tömkelege nem érkezik.)
Úgy gondolom elég aprólékosan sikerül e témán áthaladnunk, s elég sok forráskódot
is közzé tettem. Így most is felteszem a mai
cikk forráskódját, ill. a :\PC-XUSER.18\TT\R4sFDOS\ könyvtárban található
ZIP egy terjeszthető változat az R4sFDOS-ról, és a gyors FDD-olvasóról
az: R4sQuickFloppy-ról.
Bárkinek bármi kérdése intézze azt az alábbi eMail címre.
Bérczi László


