
Múltkori számunkban nem volt programtervezés rovat, s ezek szerint nem
is hiányoltátok annyira, hogy billentyűt
ragadjatok s írjatok nekem. Kérem aki rendszeres olvasója ezen rovatnak
eresszen el egy eMail a PC-XUSER@freemail.c3.hu-ra
s ígérem előbb olvassa el a következő programtervezés
cikket, mint bárki más.
Nos utoljára a léptetéses ciklust tárgyalgattuk
most a rutinok használatát, jelentőségét vesszük nagyítónk alá.
Elmélet
Mire jó a rutin, mikor használjuk ?
-
Vegyük először is a rutin definícióját: egy
programból bizonyos szempontok alapján elkülönített forráskód részlet,
melynek nevet adunk s ezzel a névvel hivatkozunk rá a későbbiekben.
-
Miért különítünk el bizonyos részeket-, miért bontjuk részekre a programot
?
Ennek több oka van:
-
A programot - elvileg - úgy kell megírni,
hogy adott egy nagy probléma. Ezt rész problémákra bontjuk, amelyek már
külön egységként kezelhetőek. Tehát finomítjuk a problémát. A rész problémákat
most külön - külön vesszük nagyítónk alá, s megpróbáljuk mindig az egyiket
megoldani. Egy részprobléma megoldása hasonlóan történik: ezt is annyi
részproblémára bontjuk, ami már megegyezik a programozási nyelv alaputasításaival.
(amíg le nem írható if then, for, … alap egységekkel). Ezt a folyamatot
lépésenkénti finomításnak nevezik. A program részegységeinek elkülönítésére
– is – szolgálnak a rutinok. Minden főbb problémát
és annak megvalósítását, ha szükséges külön rutinba tehetjük.
-
Persze nem csak a program felépítésénél használhatjuk
előnyösen, hanem általában vannak olyan feladatok – művelet sorozatok,
amit többször is használunk egy program megírása során.
Ilyenek az adatok beolvasását és ellenőrzését végző programrészek melyeket
érdemes egy rutinba foglalni, hogy ezek után csak a rutint meghívva egy
sorral elvégezhessük a beolvasást, megkímélve magunkat a beolvasó algoritmus
sokszori begépelésétől. (s persze a programunk is rövidebb lesz
jó pár byte-tal.)
-
A 2. Pontból adódóan a rutinoknak mindig olyan nevet kell (saját jól felfogott
érdekünkben) adni, mely utal az általa végrehajtott tevékenység sorozatra.
Most hogy jól körül írtuk miért használjuk, akkor lépjünk a tettek mezejére,
s vegyünk egy ismerős példát (ezt a példát
én is főiskolán hallottam, ahol előadáson sokan alszanak), nos:
Íme egy reggeli készülődés számítástechnikus
által megfogalmazott stuktogrammja:
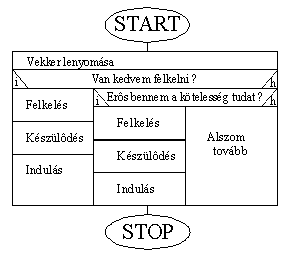
Nos ezt a programot kellene optimalizálnunk
méghozzá úgy, hogy a kétszer előforduló kódrészeket egy rutinba
foglaljuk. A rutinokat stuktogrammal az alábbi módon jelöljük:
Bővebben:

-
Hogy szép szakszavakat használjunk a rutinokat ezentúl szubrutinnak nevezzük,
hisz a logikából következik, hogy ez az egész program egy alrutinja.
-
Amint látjuk a megszokott START részben adjuk meg a rutin nevét,
ezzel fogunk a későbbiekben hivatkozni rá.
Így a feladatunk leegyszerűsödött, s így fog
kinézni:
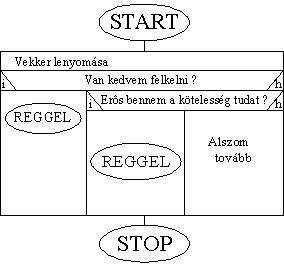
Magának a REGGEL rutinnak meg itt található a kifejtése:
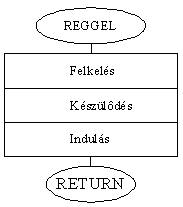
Nos remélem e példa megfogott mindenkit, most inkább gyakorlatibb vizekre
evezzünk.
Tegyük fel billentyűzetről kell beolvasni
bizonyos változókat. Ahhoz, hogy ezt megtegyük el kell készíteni egy beolvasó
rutint. A beolvasó rutin saját – lokális változóiba olvassa be az adatokat
(lokális változó = csak a rutin
kezdetétől annak végéig használható változó. A rutin meghívásával foglalódik
le számára hely a memóriában, s a rutinból történő kilépéskor megszűnik
létezni.). Az adatokat vissza kell adni a meghívó kódrészlet
számára, vagy onnan kell átvenni adatokat amivel a rutin dolgozik. Tehát
a rutinnak létre kell hozni valamilyen adat
– változó csere lehetőséget, hiszen NEM adhatunk meg globális változókat
(Az egész program minden része által elérhető változót mert azzal csak
mi gabalyodnánk meg. Elfogadott tány, hogy minden rutin, s maga a főprogram
is csak lokális változókkal dolgozik.) az adatcserére. Az egyik
helyen így, a másik helyen meg úgy kellene használni a globális változót,
s csak bénázhatnánk vele, hogy kinullázzuk, meg minden. Így az lesz a legtisztább,
ha a fent említettek szerint csak lokális változókkal dolgozunk.
Lássuk a példát a rutinban használt változókra,
s az őt meghívő kód által elért lokális változókat. Felhívnám a figyelmet,
hogy egy egyszerű példát veszünk csak mely adatot ad át a rutinnak,
de vissza nem kér – nem kap semmit.
Adjuk át a rutinnak A és B egész típusú változót. A rutin kiszámítja
ezeknek a számtani közepét:
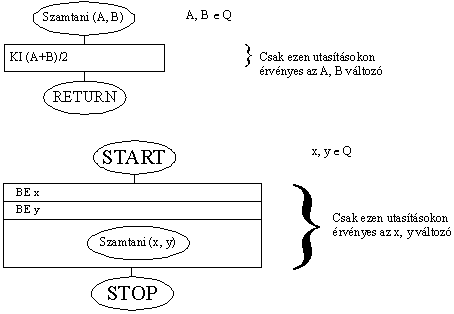
Láthatjuk, a főprogramban deklaráltunk
egy x, y valós változót. Majd ezeknek értéket olvastunk be. Az x,
és y változó által definiált értékeket adjuk át paraméterként a Szamtani
közepet számító rutinnak. Ez a rutin az értékeket A és B nevű
változókban kapja meg. Így ő belűl
már A és B-vel tud számolni. Ez az A és B változó reprezentálja a kívülről
kapott értékeket melyek jelen esetben az x és y változóban vannak. Mivel
most csak értéket adtunk át meghívhatnánk a Szamtani() rutint úgy is, hogy
a paramétere két konkrét szám: Szamtani(2,4) így a képernyőre
(2+4)/2 az-az 3-at írna ki. Az x, y változókra csak a szám beolvasás miatt
volt szükség.
Azért hangsúlyozom ezt ennyire ki, mert a későbbiekben
másképp is használjuk a paraméterátadást mégpedig úgy, hogy nem csak a
rutinnak adunk paramétert, hanem ugyan azon változón keresztül vissza is
várunk kiszámított értéket.
Mielőtt a dolgok elébe szaladnánk,
lássuk a szabványosított stuktogramm beli definíciót a paraméter átadásra.
-
A szubrutin meghívásakor megadjuk, hogy a hívó helyéről
mely változókban tárolt értékeket kívánjuk átadni magának a rutinnak. Ezeket
a változókat aktuális paramétereknek nevezzük.
-
A szubrutin deklarálásakor hasonló módon meg kell adnunk, hogy milyen adatokat
akarunk feldolgozni, s ezen adatokat prezentáló változóneveket a rutin
fejrészében kell deklarálni a zárójelen belül. Nyilván itt is paraméternek
nevezzük az ilyen változókat, de formális paraméternek.
-
Nyilván FONTOS: hogy az aktuális (a hívó által átadott) paraméternek mind
a sorrendje (balról-jobbra) és mind a típusa megegyezzen a formális (a
szubrutin) paraméterével.
| Aktuális (hívó) |
|
Formális (szubrutin) |
| X |
ó |
A |
| Y |
ó |
B |
Most, hogy a definíciót megbeszéltük lássuk a szubrutin fajtáit felhasználásuktól
függően.
Két különböző módon használhatjuk a szubrutinokat:
-
Az egyik, hogy átadunk neki bizonyos adatokat és azokkal olyan műveletet
végez mely semmilyen hatással nincs az őt
meghívó kódrészletre. Ezt a szubrutint eljárásnak (procedure) nevezzük.
-
A másik, amikor - a matematikai példához hasonlóan - van egy rutinunk
ennek adato(ka)t adunk át paraméteren és EGY az-az 1 visszaadott értéke
van. Tehát matematikai szempontból ez egy: egy vagy több változós függvény
(function). A függvény lefutása, kiértékelődése:
a meghívás után - általában - a megadott paramétereken műveletet
végez, s ezt visszaadja egy konkrét értékként. Így a függvény leírásával
akár egy konkrét számra hivatkozhatunk, beépíthetjük akár egy feltételbe,
vagy a kiírásba közvetlenül.
Láttuk az eljárás stuktogrammját, de függvényét még nem. Megoldandó probléma,
hogy hogyan és hol jelezzük a visszaadott értéket. Íme:
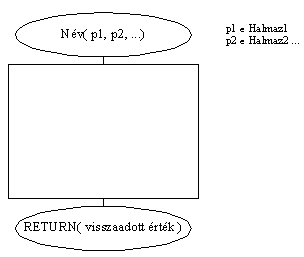
Nyílván való, hogy a visszaadott érték típusának meg kell egyeznie
azzal a típussal, ahova a függvényt behelyettesítjük. Tehát ahol karakteres
típust várunk el, oda nem helyettesíthetünk be numerikus értéket visszaadó
függvényt.
Gyakorlati rész
Mivel eddig csak a stuktogrammokról, meg egyéb elméleti témákról volt
szó, most evezzünk a megvalósítás vizére s lássuk, hogyan történik mindez
Pascal ill. C++ nyelvben:
-
Vegyük a Pascal-t előbb, hisz ez a
könnyebb:
A fent elmondottak szerint az eljárást procedure-ának, a függvényt function-nek
nevezhetjük. Először lássuk egy program
képletes felépítését:
procedure JoKisNeveLegyen( parameter1 : tipus; parameter2: tipus;
…)
begin
utasítások …
end;
function EzEgyProba( parameter1 : tipus; …): visszatérési_tipus;
begin
utasítások …
EzEgyProba:= visszatérési érték. {így adunk visszatérési
értéket a függvénynek!}
end;
BEGIN {a főprogram itt kezdődik}
END.
Nos általánosságokban így kell felépíteni, lássuk a konkrét megadást:
function beolvas_karaktert(szoveg: string): Char;
var c: Char;
begin
Write(szoveg); ReadLn(c);
beolvas_karaktert:=c;
end;
procedure Kiir(szoveg1, szoveg2: String; karakter: Char);
begin
WriteLn(szoveg1, ’ ’, karakter);
WriteLn(szoveg2, ’ ’, karakter);
end;
var
s1, s2: String;
c : Char;
BEGIN {a főprogram itt kezdődik}
s1:=’Kérem a beolvasandó karaktert: ’;
c:=beolvas_karaktert(s1);
s1:=’Ezt a karaktert éppen most olvastuk be: ’;
s2:=’Ezt a karaktert éppen most írtuk ki: ’;
Kiir(s1, s2, c);
END.
Mit csinál a program ?
-
Először beolvas egy karaktert függvénnyel.
Ez a függvény a szöveget amit kiír a beolvasás előtt
paraméterben kapja meg. Majd e függvény visszatérési értéke a beolvasott
karakter lesz.
-
A következő eljárás a megadott szövegek
mögé írja ki kétszer a beolvasott karaktert.
A fenti programot jelentősen lehet
egyszerűsíteni, így tegyük meg:
function beolvas_karaktert(szoveg: string): Char;
var c: Char;
begin
Write(szoveg); ReadLn(c);
beolvas_karaktert:=c;
end;
procedure Kiir(szoveg1, szoveg2: String; karakter: Char);
begin
WriteLn(szoveg1, ’ ’, karakter);
WriteLn(szoveg2, ’ ’, karakter);
end;
BEGIN {a főprogram itt kezdődik}
Kiir(’Ezt a karaktert éppen most olvastuk be: ’,
'Ezt a karaktert éppen most írtuk ki: ’,
beolvas_karaktert(’Kérem a beolvasandó karaktert: ’));
END.
Nos lőn csoda nem is volt szüksége
a főprogramnak változókra. Hisz ahogy
fent elmondottam, ilyen érték szerinti paraméterátadásnál közvetlen konstansként
is megadhatjuk a paramétert. A kiírandó karaktert, amit az eljárásnak adunk
át nem szükséges külön változóba másolni, hanem a karakter beolvasó függvényt
közvetlenül elhelyezhetjük az eljárás paramétereként, hisz annak visszatérési
értéke akár egy konkrét szám helyettesítődik
oda be.
A Pascal-os megvalósítás után lássuk a C gyönyöreit:
#include<stdio.h>
#include<conio.h>
void main()
{
void JoKisNeveLegyen(int, int, char);
char beolvas_karakter();
clrscr(); // kepernyotorles
char c;
c=beolvas_karakter();
JoKisNeveLegyen(1, 2, c);
}
char beolvas_karakter()
{
char tempc;
printf("\nKérek be egy karaktert: ");
tempc=getche();
return(tempc);
}
void JoKisNeveLegyen(int szam1, int szam2, char karakter)
{
printf("\nA beolvasott karakter: %c", karakter);
printf("\nAz első szám: %d", szam1);
printf("\nA második szám: %d", szam2);
}
Nos magyarázkodjunk egy kicsit:
-
Az #include-okra nyílván szükség van, hisz ezen header file-ok tartalmazzák
a printf() (kiíró), getch() (karakter-bolvasó) rutinok prototípusait.
-
A void szócska lehet, hogy nem ismerős,
igaz már szó volt az abC cikkekben róla:
A C nyelvben alapértelmezés szerint minden rutin függvény szerkezetű.
Követve a matematikai analógiát. Hogyha épp’ eljárást akarunk deklarálni
akkor közöljük a fordítóval, hogy sorry de ennek a függvénynek nincs visszatérési
értéke. Ezt a függvény visszatérési értékének típusa helyére biggyesztett
VOID szócskával érhetjük el.
-
Azt is meg kell említenem, hogy a szubrutinoknak a prototípusát valahol
deklarálni kell. A prototípus nem mást jelent, mint leírni a szubrutin
nevét és felsorolni a formális paraméter lista elemeinek típusát (elég
csak a típust). Ha a főprogramban helyezzük
el a prototípus deklarációt nyílván a főprogramra
lesz lokális a meghívható szubrutin. Máshonnan nem érhetjük el. Ha szükség
lenne a globalitásra, akkor rakjuk a főprogram
elé, minden block-on ( { } ) kívül.
-
Megírjuk a főprogramot – ami használja
a szubrutinokat.
-
Ezek után nincs más dolgunk, mint a szubrutinok kifejtése. Ezt, pl. a főprogram
után tegyük meg.
FONTOS, hogy a prototípussal hasonlóan definiáljuk a paraméterlistát
(a típusok megegyezzenek), s most már a paramétereket megnevező
változók neveit is megadjuk.
FONTOS: ellentétben a prototípus megadásával nem kell a szubrutin fejlécét
; (pontosveszővel) lezárni.
-
Itt C-ben a függvénynek a visszatérési értékét – a stuktogrammhoz hasonlóan
– a RETURN kulcsszóval adhatjuk vissza.
Ahogy a Pascal-ban is lehetett egyszerűsíteni,
így a C-ben is lássuk a forráskódot:
#include<stdio.h>
#include<conio.h>
void main()
{
void JoKisNeveLegyen(int, int, char);
char beolvas_karakter();
clrscr(); // kepernyotorles
JoKisNeveLegyen(1, 2, beolvas_karakter());
}
char beolvas_karakter()
{
printf("\nKérek be egy karaktert: ");
return(getche());
}
void JoKisNeveLegyen(int szam1, int szam2, char karakter)
{
printf("\nA beolvasott karakter: %c", karakter);
printf("\nAz első szám: %d", szam1);
printf("\nA második szám: %d", szam2);
}
Ahogy a forráskód mutatja itt még egyszerűbb
dolgunk volt, mint Pascal-ban hisz ugyanúgy a függvény behelyettesíthető
bárhova, de a függvény visszatérési értékét megadhatjuk közvetlenül a RETURN(
)-be ágyazott újabb függvénnyel mely a billentyűt
olvassa be ( getche() ). Pascal-ban külön segédváltozóra volt szükség,
hogy visszaadhassuk a beolvasott karaktert.
(Persze ha Pascal-ban lenne (vagy készítenénk) egy olyan függvényt,
melynek visszatérési értéke a beolvasott karakter, akkor a fenti beolvas_karaktert()
függvény visszatérési értékét egy közvetlen egyenlőséggel
megadhatnánk.
Beolvas_karaktert:=ReadChar; (ahol readchar egy általunk készített
másik függvény).)
Nos ennyi mára, aki érdeklődőbb
(vagy nem értett valamit) elereszthet egy eMailt a PC-XUSER@freemail.c3.hu-ra.
Bérczi László


