





Heute lernen Sie die Datenbankarchitektur des JBuilder kennen, die JDBC-Architektur sowie die Datenbankkomponenten-Hierarchie. Sie lernen Klassen und Schnittstellen kennen, die die Grundlagen für diese Architekturen bilden, und Sie sehen, was die einzelnen zu bieten haben. Insbesondere werden die folgenden Themen angesprochen:
Bevor Sie die Datenbankarchitektur von JBuilder kennenlernen, sollten Sie einen Überblick über die Datenbankterminologie erhalten, ebenso wie einige Informationen über verschiedene Datenbankmodelle und -typen. Dieser Abschnitt dient als Einführung für die Leser, die noch nicht viel mit Datenbanken gearbeitet haben, und als Auffrischung für diejenigen, die schon lange nicht mehr mit Datenbanken gearbeitet haben. (Wenn Sie jeden Tag mit Datenbankentwicklung zu tun haben, können Sie diesen Abschnitt überblättern.)
Heute werden Sie mit Datenbankterminologie überschwemmt, deshalb wollen wir zunächst bestimmen, wie diese Begriffe in diesem Buch verwendet werden. Einige der Begriffe sind für JBuilder spezifisch, bei anderen handelt es sich um allgemeine Begriffe. Tabelle 1.41 bietet einen Überblick und eine kurze Erklärung.
Tabelle 14.1: Datenbankbegriffe
Mit diesen Begriffsdefinitionen wollen wir jetzt verschiedene Datenbanktypen und Datenbankmodelle betrachten.
Es gibt viele Anwendungen, die Datenbanken verwenden, aber welches Daten
Die meisten der heute verwendeten Datenbanken sind relationale Datenbanken. Eine relationale Datenbank legt Informationen in logischen Tabellen ab, die sich aus Zeilen und Spalten zusammensetzen. Die Tabellen haben gemeinsame Spalten haben, die die Information aus einer Tabelle mit der einer anderen verknüpfen. Angenommen, Sie haben gerade ein Fotogeschäft eröffnet und Sie haben eine Tabelle mit Informationn über einen Kunden und eine Tabelle mit Informationen über Rechnungen. Nach dem ersten Monat könnten die beiden Tabellen etwa aussehen wie in Tabelle 14.2 und 14.3 gezeigt.
Sicher haben Sie das Prinzip erkannt. Diese beiden Tabellen werden über das Feld ID verknüpft, und hier handelt es sich um ein Beispiel einer Eins-zu-Viele-Beziehung. Mit anderen Worten, für jeden Datensatz in der Kunden-Tabelle können viele Datensätze in der Rechnungen-Tabelle existieren.
Anders als eine relationale Datenbank legt eine Datenbank mit flachen Dateien alle ihre Informationen in einem Datensatz ab. In dem obigen Beispiel beispielsweise gäbe es keine Kundentabelle, und die Rechnungstabelle würde für jeden Datensatz den Namen und die Adresse des Kunden beinhalten. Das ist natürlich eine enorme Platzverschwendung, weil die Information redundant ist. Aus diesem Grund werden heute hauptsächlich relationale Datenbanken eingesetzt.
Neben den beiden grundlegenden Datenbankmodellen gibt es auch noch verschiedene Datenbanktypen, die Sie einsetzen können. Auch hier hängt die Entscheidung davon ab, welche Art Anwendung Sie entwickeln und wie sie eingesetzt werden soll.
Eine Standalone-Datenbank legt ihre Dateien in dem lokalen Dateisystem ab und das Programm, das darauf zugreift, befindet sich ebenfalls auf derselben Maschine. Dieser Datenbanktyp kann für Java-Programme geeignet sein, die für den Einbenutzer-Zugriff vorgesehen sind. Das bedeutet, nur eine Person (diejenige, die die lokale Maschine benutzt) greift auf die Daten zu. Das ist das einfachste Szenario, weil Sie sich keine Gedanken um Mehrbenutzerzugriff (Nebenläufigkeit), Netzwerkverkehr oder Client/Server-Aspekte kümmern müssen. Wenn Sie beispielsweise ein Programm schreiben wollen, das Ihre persönlichen Ausgaben verwaltet und nicht vorhaben, diese Information jemandem anderen zur Verfügung zu stellen, ist eine Standalone-Datenbananwendung für Ihre Bedürfnisse geeignet.
Eine Datenbank mit gemeinsam genutzten Dateien ist eine verteilte Form einer Datenbank, die mehreren Anwendern Zugriff auf dieselben Dateien bietet. Im allgemeinen haben die Anwender ein Programm für den Zugriff auf die Tabellen auf ihrer lokalen Maschine im Netzwerk, und die Datenbank wird auf einer zentralen Maschine vorgehalten. Um welche Art Netzwerk es sich handelt, ist unwesentlich, weil die lokale Maschine auf die Datenbank als gemeinsam genutzte Datei im Netzwerk zugreift. Wenn ein Anwender auf die Datei zugreift, wird diese gesperrt, bis der Anwender die Abfrage, Aktualisierung oder eine andere Verarbeitung abgeschlossen hat. Jeder Anwender muß also warten, bis er Zugriff auf die Datei erhält, diese Lösung ist also nur geeignet, wenn nicht viele Anwender auf die Tabellen der Datenbank zugreifen.
Eine Client/Server-Datenbank (auch als Two-Tier-System bezeichnet) wurde so optimiert, daß sie viele gleichzeitige Anfragen verarbeiten kann. Ein Teil der Verarbeitung erfolgt auf der lokalen Maschine (Client), ein Teil auf der zentralen Maschine (Server). Dabei kann zwar immer noch nur jeweils ein Zugriff auf die Datei erfolgen, aber der Client kann etwas anderes tun, während der Server die Anfrage bearbeitet (via SQL-Abfragen oder gespeicherte Prozeduren). Andere Clients können ihre Anforderungen in Warteschlangen einreihen und werden nicht aufgrund gesperrter Tabellen abgewiesen.
Wieviel Verarbeitung passiert auf dem Client, wieviel auf dem Server? Das ist ein Balanceakt, der detaillierte Planung erforderlich macht, wobei die Anzahl der potentiellen Benutzer, der Netzwerkverkehr, die Anforderungstypen und ihre Häufigkeit sowie andere Aspekte berücksichtigt werden müssen. Außerdem ist für Client/Server-Systeme ein Protokoll erforderlich, wie etwa TCP/IP, wodurch zusätzliche Konfigurationen und administrative Aufgaben anfallen. Client/Server ist zwar in der Regel eine aufwendigere Lösung, aber wenn es viele gleichzeitige Anwender gibt, ist sie wahrscheinlich am besten für Sie geeignet.
Multi-Tier-Systeme sind Client/Server-Systeme, die die Verarbeitung noch weiter aufsplitten, wozu sie manchmal eine Zwischenschicht einführen, die sogenannten »Middleware«, die zusätzliche Verarbeitungen vornimmt und die Last vom Server abzieht. Dadurch kann der Server mehr Anforderungen verarbeiten, und die Kapazität und der Durchsatz steigen. Die Middleware ist in der Regel multithreaded, um mehrere gleichzeitige Anfragen verarbeiten zu können, und sie kann so konfiguriert werden, daß Anfragen für verschiedene Datenbanken verarbeitet werden.
JDBC eröffnet uns eine ganz neue Welt in der Client/Server-Technologie. Wenn Sie dachten, die Client/Server-Konfiguration auf dem lokalen Netzwerk war anspruchsvoll, können Sie jetzt mit Clients und Servern arbeiten, die meilenweit voneinander entfernt sind, und Sie müssen auch den Verkehr auf dem Internet berücksichtigen!
Wie ODBC basiert auch JDBC auf dem X/Open SQL CLI (Call Level Interface), aber im Gegensatz zu ODBC handelt es sich bei JDBC um ein Java-API, das plattformunabhängig und herstellerneutral ist. Das JDBC-API verwendet SQL SQL (Structured Query Language) für den Datenzugriff über das Internet und kann somit auf fast alle Daten zugreifen, die Ihre Anwendung braucht. JDBC ist ebenfalls objektorientiert und deshalb einfacher zu lernen und zu implementieren. Und schließlich unterstützt JDBC Client/Server- und Multi-Tier-Systeme.
Applets haben den Sprung ins Internet geschafft, und so wie es Sicherheitsprobleme bei Applets gibt, gibt es sie beim Datenbankzugriff über das Internet. In diesem Abschnitt erfahren Sie etwas über die Prozesse, die Aspekte und einige der Sicherheitsprobleme, die mit JDBC gelöst werden können.
Wenn Sie ein Applet mit Zugriff auf eine Datenbank über das Internet entwickeln, gibt es einige offensichtliche Sicherheitsprobleme. Wie Sie in der 1. Woche gelernt haben, sind Java-Applets zahlreichen Einschränkungen unterworfen, vom Zugriff auf die Festplatte des Clients bis hin zu Netzwerkverbindungen zu anderen als dem eigenen Server. Häufig sind die Daten der wichtigste Besitz eines Unternehmens, wenn man also den Datenbankzugriff über das Internet in Betracht zieht, dann potenzieren sich die Sicherheitsprobleme. Wie kann JDBC diese Probleme lösen?
JDBC erlaubt keinen unzuverlässigen (d.h. über das Internet heruntergeladenen) JDBC-fähigen Applets, auf die Daten einer lokalen Datenbank zuzugreifen. Das JDBC-Applet kann nur eine Verbindung zu einer Datenbank einrichten, die sich auf dem Server befindet, von dem es geladen wurde. Wenn das Applet jedoch durch die Java-VM als zuverlässig eingestuft wird (etwa durch Verwendung eines codierten Paßworts, oder wenn der Client davon ausgeht, daß Applets von einer bestimmten Site als sicher betrachtet werden können), wird das Applet wie eine Anwendung behandelt, was die Sicherheit betrifft.
Java-Anwendungen werden auch für andere Aufgaben als den Einsatz im Internet verwendet. Es gibt immer mehr Firmen-Intranets und -Extranets, und der Zugriff, den JDBC bietet, ist mit eine Ursache für ihre schnelle Verbreitung.
Aufgrund der Firewall-Technologie ist die Sicherheit bei Java-Anwendungen kein großes Thema. Anwendungen, die lokal geladen werden, werden als zuverlässig betrachtet. Eine andere Lösung ist die Verwendung eines Multi-Tier-Systems, wo die Middleware für die Sicherheit und den Zugriff verantwortlich ist, und als Sicherheitsgarant zwischen Client und Server steht. Wie Sie gleich sehen werden, unterstützt JDBC alle diese Sicherheits-Strategien.
JDBC unterstützt unter anderem Informix, InterBase, MS SQL Server, Oracle, Paradox, Sybase und xBase. Diese Unterstützung wird durch vier Arten der Verbindung realisiert:
Die beiden letzten Protokoll-Lösungen werden von JavaSoft als die bevorzugte Weise des Datenbankzugriffs mit JDBC empfohlen.
Es gibt noch zwei Arten von Verbindungen, die erwähnt werden sollen, RMI und CORBA.
RMI steht für Remote Method Invocation und ist eine Methode, wie eine Java-Client-Anwendung direkt Methoden für ein Java-Objekt auf einem entfernt gelegenen Server ausführen kann. Mit Hilfe der Serialisierung und Deserialisierung zum Speichern und Wiederherstellen des Objektstatus erlaubt dieses Modell eine reine Java-Lösung für den Datenbankzugriff, weil die RMI-Klassen Teil des JDK sind.
CORBA steht für Common Object Request Broker Architecture und ist ein Standard der Object Management Group. Dieser Standard definiert die IDL (Interface Definition Language), die ein »Abkommen« zwischen Client- und Server-Implementierung aushandelt. JavaSoft arbeitet gerade an einem IDL-Compiler.
Um zu verstehen, wie JDBC funktioniert, wollen wir die Schnittstellen und Klassen betrachten, aus denen es sich zusammensetzt, die alle im Paket java.sql enthalten sind. (Vergessen Sie nicht, dieses Paket in Ihren Code zu importieren, wenn Sie diese Klassen verwenden.) Das Laden von Daten mit Hilfe von JDBC basiert auf vier sehr einfachen Schritten.
Der erste Schritt wird normalerweise automatisch vom DriverManager ausgeführt, den wir als nächstes betrachten.
Die Klasse DriverManager enthält zahlreiche Methoden zur Verwaltung, Registrierung und Deregistrierung von Treibern. Größtenteils brauchen Sie jedoch nur die Methode getConnection() aufzurufen, dann lädt der DriverManager automatisch den geeigneten Treiber für die Datenbank. Tabelle 14.4 bietet einen Überblick über die wichtigsten Methoden dieser Klasse.
Tabelle 14.4: Methoden der Klasse DriverManager
Entfernt den angegebenen Treiber aus der Liste der registrierten Treiber |
|
Gibt eine Verbindung zu der Datenbank an der im String-Argument spezifizierten URL zurück |
|
getConnection(String, Properties) |
Gibt eine Verbindung zu der an der URL befindlichen Datenbank zurück wobei die Information im Properties-Argument spezifiziert wird |
Gibt eine Verbindung zu der an der URL (erster String) befindlichen Datenbank zurück und nimmt eine Anmeldung mit dem angegebenen Login und Paßwort (die beiden nächsten String-Argumente) vor. |
|
Die Methoden registerDriver() und deregisterDriver() erlauben der aufrufenden Klasse, Treiber in die Treiberliste des Klassen-Loaders einzutragen oder daraus zu entfernen. getDrivers() gibt eine Liste aller Treiber zurück.
Die überladene getConnection()-Methode bietet Ihnen mehrere Möglichkeiten, die Verbindung einzurichten. Alle drei benötigen eine URL. Für Datenbanken kann sich die URL-Syntax von dem unterscheiden, was Sie gewöhnt sind. Das grundsätzliche Format sieht wie folgt aus:
protokoll:unterprotokoll:untername
Die gebräuchlichsten Protokolle sind http: und ftp:, und die Unternamen sehen normalerweise aus wie //www.microsoft.com/ oder //www.javasoft.com/. Bei der Verwendung von JDBC ist das protokoll jdbc:, das unterprotokoll stellt einen bestimmten Datenbankmechanismus dar, und der Untername ist die Information, die für die Verbindung zu der Datenbank benötigt wird (inklusive Port). Hier einige typische JDBC-URLs:
jdbc:odbc:mydata
jdbc:odbc:mydata;UID=mylogin;PWD=mypasswd
jdbc:dbprot://testsite:321/mytables/mydata
Das erste Beispiel zeigt, wie eine Verbindung zu der Datenbank mydata eingerichtet wird, wozu über das odbc-Unterprotokoll die JDBC-ODBC-Bridge verwendet wird. Das zweite Beispiel zeigt dieselbe Verbindung mit ODBC-Login (UID) und Paßwort (PWD). Das dritte Beispiel zeigt, wie ein Datenbank-Unterprotokoll (dbprot:) verwendet wird, um sich auf Port :321 auf der Web-Seite testsite anzumelden, wobei sich die Datenbank mydata im Verzeichnis mytables befindet.
Um die Methode getConnection() zu verwenden, weisen Sie einfach einer String-Variablen die entsprechende URL zu und rufen damit die Methode auf.
String myURL = ("jdbc:dbprot://testsite:321/mytables/mydata");
getConnection(myURL, "myUID", "myPWD");
Nachdem Sie eine erfolgreiche Verbindung eingerichtet haben, wird ein Connection-Objekt zurückgegeben. Hier eine Codezeile, die zeigt, wie das realisiert wird:
Connection dbConn = DriverManager.getConnection
("jdbc:odbc:dbname", "mylogin", "mypasswd");
Als nächstes betrachten wir die Connection-Schnittstelle.
Eine Klasse, die die Schnittstelle java.sql.Connection implementiert, kann Methoden zum Sperren von Tabellen, zum Commit und Rollback von Änderungen und zum Schließen von Verbindungen überschreiben. Außerdem bietet sie Methoden zur Vorbereitung bestimmter Aufrufe und Anweisungen. Tabelle 14.5 bietet einen Überblick über einige der wichtigsten Methoden der Schnittstelle.
Tabelle 14.5: Die Methoden der Schnittstelle java.sql.Connection
Bietet eine Möglichkeit, die Connection sofort zu schließen und die JDBC-Ressourcen freizugeben. |
|
Aktualisiert die Tabelle mit allen Änderungen, die seit dem letzten Commit/Rollback vorgenommen wurden, und gibt die Connection-Sperren für die Datenbank frei. |
|
Gibt einen Booleschen Wert zurück: true, wenn AutoCommit aktiviert ist, false, wenn es deaktiviert ist. |
|
Gibt ein DatabaseMetaData-Objekt zurück, das Informationen über die Tabellen, die gespeicherten Prozeduren und die unterstützte SQL-Grammatik für die aktuelle Connection-Datenbank enthält. |
|
Gibt einen Booleschen Wert zurück: true, wenn die Connection geschlossen ist, false, wenn sie geöffnet ist. |
|
Gibt ein neues CallableStatement-Objekt mit optionalen OUT- oder INOUT-Parametern zurück. Das String-Argument ist eine SQL-Anweisung. |
|
Gibt ein neues PreparedStatement-Objekt zurück, das eine vorkompilierte einfache SQL-Anweisung oder eine mit IN-Parametern. Das String-Argument ist eine SQL-Anweisung. |
|
Verwirft alle Änderungen, die seit dem letzten Commit/Rollback in der Tabelle vorgenommen wurden; alle Connection-Sperren werden freigegeben. |
|
Setzt das Boolesche Argument auf true, um AutoCommit zu aktivieren, auf false, um es zu deaktivieren. |
Die Klasse, die die Statement-Schnittstelle implementiert, kann Methoden überschreiben, die Ihnen ermöglichen, unterschiedliche SQL-Anweisung zu verwalten und auszuführen. Tabelle 14.6 bietet einen Überblick über die gebräuchlichsten Methoden.
Tabelle 14.6: Die Methoden der Schnittstelle java.sql.Statement
Es gibt noch viele andere Methoden in der Statement-Schnittstelle. Weitere Informationen entnehmen Sie bitte der Online-Hilfe.
Neben der Statement-Schnittstelle gibt es noch zwei weitere Schnittstellen, die hier erwähnt werden sollen. Die Schnittstelle CallableStatement erbt von der Schnittstelle PreparedStatement, die wiederum von der Statement-Schnittstelle erbt. Auf jeder Ebene werden zusätzliche abstrakte Methoden für den jeweiligen SQL-Anweisungstyp bereitgestellt.
Die Schnittstelle PreparedStatement wird verwendet, wenn Sie eine einfache SQL-Anweisung vorkompilieren wollen, um sie mehrere Male auszuführen, oder wenn die SQL-Anweisung IN-Parameter hat und vorkompiliert werden muß. Das ist eine effizientere Weise, die Anweisung auszuführen.
Die Schnittstelle CallableStatement ist in der Regel eine vorkompilierte gespeicherte Prozedur, die von gespeicherten Datenbankprozeduren mit OUT- oder INOUT-Parametern verwendet werden muß.
Hier folgt ein typischer Codeabschnitt für die Abfrage von myTable:
Connection dbConn = DriverManager.getConnection
("jdbc:odbc:dbname", "mylogin", "mypasswd");
Statement sqlStmt = dbConn.createStatement();
ResultSet rSet = sqlStmt.executeQuery
("SELECT xInt, yString FROM myTable");
Dieses Beispiel verwendet die Connection-Instanz dbConn und erzeugt die Statement-Instanz sqlStmt. Mit sqlStmt führt es die SQL-Abfrage unter Verwendung der Methode executeQuery() von Statement aus und gibt die ResultSet-Instanz rSet zurück. Die abstract-Klasse von ResultSet ist der letzte Teil der JDBC-Architektur, den Sie als nächsten kennenlernen werden.
Die Implementierung der Methoden der abstrakten Klasse java.sql.ResultSet steuern den Zugriff auf die Zeilenergebnisse aus einer vorgegebenen SQL-Anweisung. Durch diese Klasse erhalten Sie Zugriff auf die Ergebnisse all Ihrer Abfragen. Tabelle 14.7 zeigt einige der wichtigsten Methoden dieser Schnittstelle.
Tabelle 14.7: abstract-Methoden von java.sql.ResultSet abstract
Es gibt zwei getXxxx()-Methoden für jeden Java-Typ; eine, die einen Spaltenindex verwendet, und eine, die einen Spaltennamen verwendet. Um beispielsweise ein String-Objekt aus der zweite Spalte der aktuellen Zeile zu ermitteln, schreiben Sie folgendes:
Damit erhalten Sie den Wert dieses Feldes als Java-String-Objekt zurück. Um einen Zeichen-Wert aus der Spalte Gender zu ermitteln, würden Sie folgendes schreiben:
Die Methode findColumn() gbit die Spaltennummer für einen Spaltennamen zurück.
Der Cursor in einer ResultSet wird unmittelbar vor der ersten Zeile positioniert, wenn das ResultSet erzeugt wird. Um den Cursor durch das ResultSet zu bewegen, rufen Sie die Methode next() auf. Bevor Sie versuchen, die Daten in die Zeile einzulesen, sollten Sie den Rückgabewert von next() auswerten, um festzustellen, ob Sie auf einer gültigen Zeile gelandet sind, oder ob es keine weiteren gültigen Zeilen gibt. Der folgende Code kombiniert die oben gezeigten Codeausschnitte mit Hilfe einer while-Schleife, die das ResultSet rSet durchläuft:
Connection dbConn = DriverManager.getConnection
("jdbc:odbc:dbname", "mylogin", "mypasswd");
Statement sqlStmt = dbConn.createStatement();
ResultSet rSet = sqlStmt.executeQuery
("SELECT xInt, yString FROM myTable");
while (rSet.next()) {
int xIntVal = getInt("xInt");
String yStrVal = getString("yStr");
}
Die Methode getMetaData() gibt ein ResultSetMetaData-Objekt zurück, das Informationen über das ResultSet enthält, etwa die Anzahl der Spalten. Außerdem gibt sie Informationen über einzelne Spalten (Felder) zurück, etwa den Namen, den Titel, die maximale Breite, die Datentypen, die Genauigkeit (Dezimalstellen), die Skalierung (Dezimalpunkte) und anderes. Eine vollständige Liste aller Methoden der Klasse ResultSetMetaData, die Informationen über das ResultSetMetaData-Objekt zurückgeben, finden Sie in der Online-Hilfe.
Einfach ausgedrückt, es gibt Datentypen, die spezifisch für SQL sind, und die auf Java-Datentypen abgebildet werden müssen, wenn Sie erwarten, daß Java sie verarbeitet. Diese Umwandlung kann in drei Kategorien eingeteilt werden:
Es gibt Tabelle in der Online-Hilfe, die die Konvertierungen in beide Richtungen genau beschreiben (von SQL in Java und von Java in SQL).
Die Datentypen DECIMAL und NUMERIC müssen unter Verwendung einer speziellen Klasse konvertiert werden, weil die absolute Genauigkeit eingehalten werden muß. Vor JDBC gab es keine Datentypen für das, was benötigt wurde. Das JDBC-API enthält die Klasse java.sql.Numeric, die Ihnen ermöglicht, die SQL-Werte DECIMAL und NUMERIC in Java umzuwandeln.
Das SQL-DATE besteht aus Tag, Monat und Jahr, TIME aus Stunden, Minuten und Sekunden. TIMESTAMP kombiniert DATE und TIME und führt ein Feld für die Nanosekunden ein. Weil java.util.Date keine 1:1-Entsprechung mit diesen SQL-Typen bietet, wurde die Klasse java.sql.Date definiert, die die SQL-Werte DATE und TIME verarbeitet, während java.sql.Timestamp so definiert ist, daß es SQL-TIMESTAMP verarbeitet.
Basierend auf den früheren Beispielen finden Sie im folgenden ein vollständiges Listing, wo eine typische JDBC-Verbindung eingerichtet, eine Datenbank abgefragt, Ergebnisse aus einem ResultSet ermittelt und die Daten ausgedruckt werden. Das Programm in Listing 14.1 ist zwar nicht direkt ausführbar (es sei denn, Sie haben die Tabelle myTable mit den entsprechenden Daten vorliegen), aber es soll Ihnen zeigen, wie ein Programm aussieht, das das JDBC-API verwendet.
Listing 14.1: QueryMyTable.java
1: import java.net.URL;
2: import java.sql.*;
3:
4: public class QueryMyTable {
5:
6: public static void main(String args[]) {
7:
8: try {
9:
10: // Verbindung zur Datenbank einrichten
11: String theUrl = "jdbc:odbc:dbname";
12: Connection dbConn = DriverManager.getConnection
13: (theUrl, "mylogin", "mypasswd");
14:
15: // SELECT-Anweisung ausführen
16: Statement sqlStmt = dbConn.createStatement();
17: ResultSet rSet = sqlStmt.executeQuery
18: ("SELECT xInt, yString FROM myTable");
19:
20: // Ergebniszeilen durchlaufen und die ermittelten
21: // Werte ausgeben
22: System.out.println("Return results");
23: while (rSet.next()) {
24: int xIntVal = rSet.getInt("xInt");
25: String yStrVal = rSet.getString("yStr");
26: System.out.print("xIntVal = " + xIntVal);
27: System.out.print("yStrVal = " + yStrVal);
28: System.out.print("/n");
29: }
30:
31: sqlStmt.close();
32: dbConn.close();
33: }
34:
35: catch (Exception e) {
36: System.out.println("EXCEPTION: " + e.getMessage());
37: }
38:
39: }
40:
41: }
In JBuilder geht der DataBroker-Zugriff für den Datenzugriff und die Aktualisierung von JDBC-Datenquellen in drei Phasen vor:
Mögliche Konflikte bei der Bearbeitung werden automatisch behandelt. Dieser Ansatz, der in der DataBroker-Architektur implementiert ist, ermöglicht Ihnen einen Datenzugriff auf sehr hoher Ebene, wozu Sie Drag&Drop-Komponenten nutzen und mit den JBCL-Komponenten Ihrer Benutzeroberfläche verbinden können.
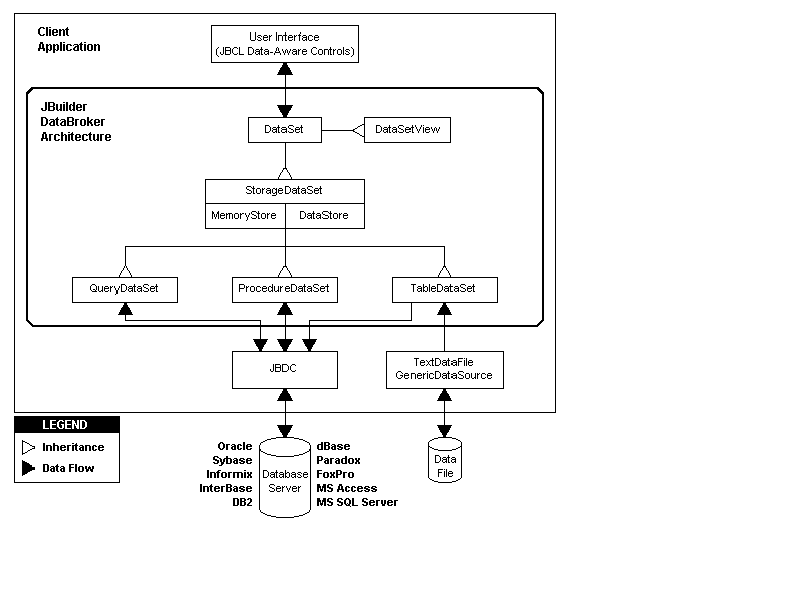
Abbildung 14.1: Die DataBroker-Architektur von JBuilder
Die Klassen DataSet und StorageDataSet sind abstrakt, während DataSetView, QueryDataSet, ProcedureDataSet, TableDataSet und TextDataFile Komponenten auf der Datenzugriff-Registerkarte der Komponentenpalette sind. Abbildung 14.2 zeigt die Datenzugriff-Registerkarte.

Abbildung 14.2: Die Datenzugriff-Registerkarte in der Komponentenpalette
Für die Registry-Einstellungen ist für einen Java-JDBC-Treiber keine spezielle Installation erforderlich. Dadurch können Anwendungen, die mit dem DataBroker erzeugt werden, als Anwendung oder als Applet ausgeführt werden.
Der DataBroker nimmt die Typabbildung mit Hilfe von Variant-Typen vor. Variant ist eine Klasse, die statische int-Bezeichner hat, die die unterstützten Datentypen auflisten. Größtenteils erfolgt die Zuordnung von JDBC-Typen zu Variant-Typen 1:1. Sie ist in der JBCL-Referenz dokumentiert.
Alle DataBroker-Ausnahmeklassen für die Fehlerbehandlung sind entweder DataSetException oder eine Unterklasse davon. DataBroker-Ausnahmen können andere Aunahmetypen auffangen (wie etwa IOException und SQLException).
Jetzt betrachten wir die einzelnen Klassen und Komponenten, die Sie zum Erzeugen von Datenbankanwendungen in JBuilder brauchen.
DataSet ist eine abstrakte Klasse. Sie stellt alle Methoden zur Navigation, für den Datenzugriff und die Aktualisierung von DataSets bereit. Außerdem unterstützt sie Master-Detail-Beziehungen, Sortieren und Filtern. Datenbezogene JBCL-Steuerelemente haben eine DataSet-Eigenschaft, die sie auf eine beliebige von DataSet abgeleitete Komponente setzen können, wie etwa DataSetView, QueryDataSet, ProcedureDataSet, and TableDataSet.
StorageDataSet ist eine abstrakte Klasse, die das Speichern von DataSet-Daten und die Bereitstellung von Indizes erlaubt. Sie stellt Methoden zum Hinzufügen, Löschen, Änderung und Verschieben von Daten bereit. Außerdem werden hier Aktualisierungen, Einfügungen und Löschvorgänge automatisch aufgezeichnet.
DataSetView stellt einen Cursor mit Sortierung und Filtermöglichkeit bereit, indem die StorageDataSet-Eigenschaft entsprechend gesetzt wird. Sie können diese Komponente auch verwenden, um mehrere DataSetView-Komponenten zu einem neuen DataSet zusammenzusetzen, indem Sie ihre StorageDataSet-Eigenschaften ändern.
QueryDataSet ist eine JDBC-spezifische Unterklasse von DataSet, die einen JDBC-Datenprovider verwaltet, der in der Query-Eigenschaft (eine SQL-Anweisung) angegeben ist.
ProcedureDataSet (nur C/S) ist ebenfalls eine JDBC-spezifische Unterklasse von DataSet, die einen JDBC-Datenprovider verwaltet, der in der Procedure-Eigenschaft (eine gespeicherte Prozedur) angegeben ist.
Ein QueryResolver steuert, wie Aktualisierungen erfolgen und wie Konflikte aufgelöst werden. Dazu wird die Resolver-Eigenschaft Ihrer DataSet-Komponente auf Ihre QueryResolver-Komponente gesetzt.
TableDataSet ist eine DataSet-Komponente ohne eingebauten Provider, sie kann aber ihre Änderungen zurück in eine Datenquelle schreiben.
Das DataModule ist ein nicht-visueller Container für Komponenten wie etwa DataSet oder Database und steht in der Object Gallery (Datei | Neu) zur Verfügung. Auch andere Container können Datenzugriff-Komponenten enthalten, wie etwa Frames oder Applets, aber es ist besser, sie in einem DataModule abzulegen. Dadurch können Sie eine von Ihren Benutzeroberflächen-Komponenten separate Anwendungslogik bereitstellen. Wenn Sie die folgende Codezeile als Schablone für die Verwendung von DataModule in Ihrem Code verwenden:
DataModule myDMod = DataModule.getDataModule();
dann können Sie auf das soeben erzeugte DataModule-Objekt in anderen Frames oder Applets zugreifen, so daß Sie seine Komponenten als Gruppe wiederverwenden können.
Mehrere DataSet-Komponenten (wie etwa QueryDataSets und ProcedureDataSets) können dieselbe Database gemeinsam nutzen, indem sie ihre Database-Eigenschaften entsprechend setzen. Die Database-Eigenschaft Connection spezifiziert die URL, den Login-Namen, das Paßwort sowie optional einen JDBC-Treiber.
DataSet-Komponenten können Daten aus einer beliebigen JDBC-Datenquelle entgegennehmen. Die Database-Eigenschaft gibt an, für welche Connection die Abfrage erfolgen soll. Die Query-Eigenschaft ist ein String, der die SQL-Anweisung darstellt. Die ParameterRow-Eigenschaft ermöglicht, optionale Abfrageparameter anzugeben. Das executeOnOpen-Ereignis bewirkt, daß QueryDataSet die Abfrage beim ersten Öffnen ausführt, das sinnvoll ist, wenn echte Daten zur Entwurfszeit angezeigt werden sollen. Die Eigenschaft AsynchronousExecution bewirkt, daß die DataSet-Zeilen in einem eigenen Thread ermittelt werden, so daß ein Zugriff auf die Daten möglich ist, während QueryDataSet Zeilen aus der Connection lädt.
Die QueryDataSet-Komponente kann auf dreierlei Weise eingesetzt werden, um Daten zu laden:
Dynamisches Laden von Detail-Gruppen: Die MasterLinkDescriptor-Eigenschaft eines DataSet enthält eine FetchAsNeeded-Eigenschaft. Wenn diese Eigenschaft für ein QueryDataSet gesetztwird, wird die Detail-Abfrage ausgeführt, wenn zum ersten Mal eine neue Master-Zeile angetroffen wird.
Nachdem Daten in ein DataSet geladen wurden, kann man sich darin bewegen. Diese Navigation kann relativ sein (nächster, vorhergehender, erster oder letzter Datensatz). Es kann entweder mit Hilfe der Methode goToRow() positioniert werden, oder es kann mit locate() oder lookup() nach einem Wert gesucht werden. Wenn das DataSet mit einem datenbezogenen Steuerelement der Benutzeroberfläche verbunden ist, verwaltet dieses Steuerelement die aktuelle Zeile im DataSet. Wenn das nicht gewünscht ist, verwenden Sie statt dessen ein DataSetView, das einen unabhängigen Cursor, eine Zeilensortierung und eine Filterung ermöglicht.
DataSet bietet außerdem Methoden zum Hinzufügen, Löschen und Aktualisieren von Zeilen im DataSet. Das Einfügen einer neuen Zeile in ein nicht sortiertes DataSet erfolgt am Ende dieses DataSets. Wenn das DataSet sortiert ist, wird die Zeile an der korrekten Position eingefügt. Außerdem gibt es die Methode getStatus(), die eine Bitmaske mit Statusinformationen zurückgibt. Die Biteinstellungen sind in der Klasse RowStatus definiert.
Jedes DataSet kann eine eigene Spaltensortierung aufweisen, die in der Sort-Eigenschaft festgelegt wird. Der SortDescriptor spezifiziert auch Sortierungen ohne Berücksichtung der Groß-/Kleinschreibung und absteigende Reihenfolgen, die durch Indizes verwaltet werden. Indizes werden durch Aufruf von freeAllIndexes() (definiert in der Klasse StorageDataSet) freigegeben. Das Filtern wird durch Definition des RowFilter-Ereignisses der DataSet-Komponente bewerkstelligt. Wenn ein RowFilter-Ereignishandler parametrisiert ist, kann das DataSet gezwungen werden, den Filter durch Aufruf der Methode recalc() neu zu berechnen.
Diese Unterstützung wird aktiviert durch Setzen der MasterLink-Eigenschaft des Detail-DataSet, wodurch Spaltenwerte aus dem Master-DataSet mit dem Detail-DataSet verbunden werden. Beim Durchlaufen des Masters werden die Details mit übereinstimmenden Spaltenwerten angezeigt. Eine Master-Zeile kann nicht gelöscht werden, und eine Master-Link-Spalte kann nicht verändert werden, wenn ihr Detail-Zeilen zugeordnet sind. Ein Master-DataSet kann mehrere zugeordnete Detail-DataSet-Komponenten haben, und ein Detail-DataSet kann Master für ein anderes Detail-DataSet sein.
Es gibt zwei Ansätze für die Verwendung der Master-Detail-Funktionalität in QueryDataSet-Komponenten:
Die DataBroker-Architektur bietet eine umfangreiche Unterstützung zum Speichern von DataSet-Änderungen in einer JDBC-Datenquelle und zum Auflösen aller möglichen Konflikte. Die automatische Auflösung ruft die Methode saveChanges() (definiert in Database) für die DataSets (oder eine DataSet-Unterklasse) auf, so daß das Einfügen, Löschen oder Aktualisieren standardmäßig in einer einzigen Transaktion in der JDBC-Datenquelle erfolgt. Für eine angepaßte Auflösung wird die Resolver-Eigenschaft des DataSet verwendet. (Alle von StorageDataSet abgeleiteten DataSets besitzen diese Eigenschaft.) Sie können aber auch einen QueryResolver instantiieren, seine Eigenschaften und Ereignishandler setzen und dann die Resolver-Eigenschaft der DataSet-Komponente auf Ihre QueryResolver-Komponente setzen. Auf diese Weise können Sie steuern, wie Aktualisierungen vorgenommen werden und wie Konflikte aufgelöst werden.
Die Methode saveChanges() delegiert die Arbeit, Änderungen zu speichern, an eine Unterklasse, SQLResolutionManager. Hier folgt ein Codeabschnitt, der zeigt, wie die Methode saveChanges() arbeitet:
SQLResolutionManager resolutionManager = new SQLResolutionManager();
resolutionManager.setDatabase(this);
resolutionManager.setDoTransactions(true);
resolutionManager.savechanges(DataSets);
In diesem Abschnitt werden die datenbezogenen Steuerelemente mit je einer kurzen Beschreibung vorgestellt. Um diese Komponenten mit den entsprechenden Datenzugriffs-Komponenten zu verbinden, klicken Sie auf den Dropdown-Pfeil in der DataSet-Eigenschaft und wählen einfach eine der DataSet-Unterklassen-Komponenten, die Ihnen in der Liste angezeigt werden.
Wenn eine Tabellenspaltenüberschrift angeklickt wird, werden die Daten nach dieser Spalte in aufsteigender Reihenfolge sortiert. Wenn sie ein zweites Mal angeklickt wird, wird die Spalte in absteigender Reihenfolge sortiert. Die Tabelle benachrichtigt das DataSet, wenn sie die Spalten umsortiert, und diese Information wird von LocatorControl ausgewertet, welche Spalten gesucht werden sollen.
Wenn die DataSet-Eigenschaft eines StatusBar gesetzt wird, macht sie das StatusBar zu einem StatusListener des DataSet. Dann zeigt das StatusBar Informationen über die Navigation, die Berabeitung, den Fortschritt der Abfrageausführung sowie andere Statusmeldungen an.
Wenn die Dataset-Eigenschaft dieser Komponente gesetzt ist, können die Schaltflächen von NavigatorControl die Navigation steuern, Zeilen neu laden und speichern. Die Schaltflächen zum Neuladen und Speichern werden nur für QueryDataSet- und ProduceDataSet-Komponenten aktiviert.
Die Komponente LocatorControl hat DataSet- und ColumnName-Eigenschaften, um einen interaktiven Suchmechanismus an eine Spalte zu binden. Wenn die Spalte nicht angegeben ist, wird die erste Spalte im DataSet geladen. Wenn sie mit einem GridControl verbunden ist, wird die zuletzt betrachtete Spalte geladen. Für Spalten vom Typ String wird eine inkrementelle Suche unterstützt, wobei die Groß-/Kleinschreibung nicht berücksichtigt wird, wenn nur Kleinbuchstaben eingegeben werden.
Durch Setzen der DataSet-Eigenschaft dieser Komponente kann die PickListDescriptor-Eigenschaft von ColumnComponent verwendet werden, um die Auswahlliste zu füllen.
Heute haben Sie JDBC als Low-Level-Löstung für die Verbindung zu einer SQL-Datenbank kennengelernt, und Sie haben gesehen, daß Performance und Sicherheit zum Thema werden können, wenn Sie Ihre Java-Programme mit einem SQL-Host verbinden. Außerdem haben Sie das JDBC-API kennengelernt, sowie ein Beispiel, wie ein Java-Programm eine Verbindung zu einer SQL-Datenbank einrichten, diese Abfragen und die Ergebnisse zurückgeben könnte.
Sie haben die Datenzugriffs-Komponenten von JBuilder als High-Level-Lösung für die Verbindung mit SQL-Datenbanken und die Verwendung des JDBC-API kennengelernt. Die DataBroker-Architektur wurde vorgestellt. Außerdem wurden die datenbezogenen Komponenten kurz gezeigt.
Dies war jedoch nur eine kurze Einführung in die Möglichkeiten, die JDBC und die Datenzugriffskomponenten von JBuilder bieten.
F Kann JDBC neue Sicherheitsrisiken aufwerfen?
A JDBC wurde sorgfältig drauf ausgelegt, daß es demselben Sicherheitsmodell wie Java unterliegt. Ein neues Sicherheitsrisiko, das ein Problem darstellen könnte, kommt jedoch mit den BLOBs (Binary Large Objects). Der BLOB, in SQL auch als Datentyp LONG RAW realisiert, wird normalerweise genutzt, um binäre Daten zu speichern, unter anderem Grafik und Sound. Das könnte zu einer Sicherheitslücke zum Einschleusen von Viren oder fremdem Code in das Client-System führen.
F Mit Hilfe von ODBC kann ich eine SQL-Anweisung asynchron ausführen. Bietet Java etwas ähnliches?
A Java bietet noch etwas viel besseres: Multithreading. Der DriverManager kann mehrere Verbindungen zur Datenbank gleichzeitig einrichten, und jede dieser Verbindungen kann mehrere Anweisungen ausführen. So wie Animationen können Sie auch SQL-Anweisungen in ihre eigenen Threads einbetten.
Der Workshop bietet zwei Möglichkeiten, zu überprüfen, was Sie in diesem Kapitel gelernt haben. Der Quiz-Teil stellt Ihnen Fragen, die Ihnen helfen sollen, Ihr Verständnis für den vorgestellten Stoff zu vertiefen. Die Antworten auf die Fragen finden Sie in Anhang A. Der Übungen-Teil ermöglicht Ihnen, Erfahrungen in der Anwendung der Dinge zu sammeln, die Sie hier kennengelernt haben. Versuchen Sie, diese Dinge durchzuarbeiten, bevor Sie mit der nächsten Lektion weitermachen.
Experimentieren Sie anhand von Listing 14.1 mit einer eigenen Tabelle und greifen Sie über eine SQL-Abfrage auf verschiedene Datenzeilen zu und geben Sie diese aus.
