![[View INPRISE Home Page]](/file/31678/ENTER9_2.bin/prog_8/JBInfo/BOLUS.GIF) ![[View Product List]](/file/31678/ENTER9_2.bin/prog_8/JBInfo/PRODUCTS.GIF) ![[Search This Web Site]](/file/31678/ENTER9_2.bin/prog_8/JBInfo/SEARCH.GIF) ![[View Available Downloads]](/file/31678/ENTER9_2.bin/prog_8/JBInfo/downloads.gif) ![[Get Free INPRISE Membership]](/file/31678/ENTER9_2.bin/prog_8/JBInfo/membership.gif) ![[Enter Discussion Area]](/file/31678/ENTER9_2.bin/prog_8/JBInfo/newsgroups.gif) ![[Send Email To Webmaster]](/file/31678/ENTER9_2.bin/prog_8/JBInfo/FEEDBACK.GIF) |
||
|

JBuilder
INPRISE
Programs |
 DataExpress Technology Overview by Steven Shaughnessy
TABLE OF CONTENTS
The advantages of this approach can be summarized as follows. The DataExpress approach is one of the most practical approaches for developing thin client/server-oriented applications on the Internet across a broad variety of data sources. The JDBC API.
According to JavaSoft's web site, JDBC has been endorsed by leading database, connectivity, and tools vendors, including Oracle, Sybase, Informix, Interbase and DB2. Several vendors have announced availability and future products plan for JDBC drivers. Existing ODBC drivers can be utilized via the JDBC-ODBC bridge provided by JavaSoft. Using the JDBC-ODBC bridge is not an ideal solution because it requires the installation of ODBC drivers and registry entries. ODBC drivers are also implemented natively which—compromises cross-platform support and applet security.
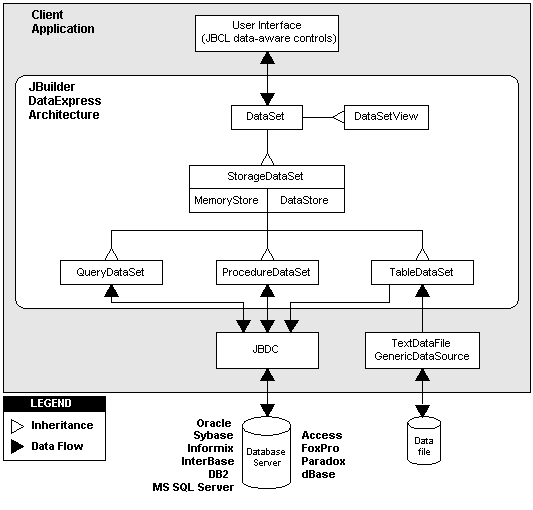
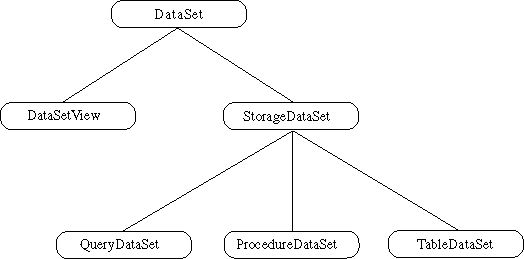
The DataSet class hierarchy is the centerpiece of the DataExpress architecture. The DataSet class hierarchy is not a set of implementable interfaces. DataSets provide a rich level of functionality and semantics for data access and update. If interfaces existed for these APIs, the implementor would have the burden of supporting the rich functionality and semantics of the DataSet APIs. The intent of the DataExpress architecture is to provide a powerful, performant, and tested set of components that are ready for use and customization. Customization is achieved by property settings, event handlers, and implementation of smaller, more focused interfaces such as Resolver and DataFile (both discussed later).
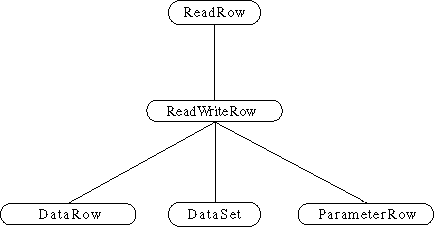
The DataSet class hierarchy is not a set of implementable interfaces. DataSets provide a rich level of functionality and semantics for data access and update. If interfaces existed for these APIs, the implementor would have the burden of supporting the rich functionality and semantics of the DataSet APIs. The leaf nodes of this class hierarchy are instantiable components. DataSet and StorageDataSet are abstract classes. DataSet. An abstract class. A large amount of the public API for all DataSets is surfaced in this class. All navigation, data access, and update APIs for a DataSet are surfaced in this class. Support for master detail relationships, row ordering, and row filtering are surfaced in this class. All of our data, aware JBCL controls have a DataSet property. This means a GridControl can have its DataSet property set to the various extensions of DataSet: DataSetView, QueryDataSet, ProcedureDataSet, and TableDataSet. StorageDataSet. An abstract class. The StorageDataSet manages the storage of DataSet data,indexes used to maintain varying views of the data and persistent Column state. The current release provides efficient in-memory storage for data. The architecture also lends itself to plugging in persistent DataStores as well. All structural APIs (add/delete/change/move column) are surfaced in this class. Since StorageDataSets manage the data, it is where all row updates, inserts, and deletes are automatically recorded. Since all changes to the StorageDataSet are tracked, we know exactly what needs to be done to save (resolve) these changes back to the data source during a resolution operation. DataSetView. This component can be used to provide independent navigation (a cursor) with a row ordering and filtering different than that used by the base DataSet. To use this, component DataSetView has a StorageDataSet property that must be set. This component can also be used when multiple controls need to dynamically switch to a new DataSet. The controls can all be wired to the same DataSetView. To force them all to view a new DataSet, the DataSetView StorageDataSet property can be changed. QueryDataSet. This is a JDBC-specific DataSet. It manages a JDBC provider of data. The data to be provided is specified in a query property. The query property is a SQL statement. ProcedureDataSet. This is a JDBC-specific DataSet. It manages a JDBC provider of data. The data to be provided is provided with a procedure property. The procedure property is a stored procedure. TableDataSet. This is a generic DataSet component without anya built-in provider mechanism. Even though it has no default provider, it can be used to resolve its changes back to a data source. TableDataSets Columns and data can be added through DataSet methods or by importing data with a DataFile component like TextDataFile. 1.2 The Column component. A StorageDataSet can contain one or more Column components. A Column describes data type, meta data, and several persistent properties (constraints, defaults, etc.) for a column in a DataSet. Unlike Delphi Field components, data values are notcannot be retrieved from a Column object. Instead, field values are retrieved through DataSet and Read/ReadWriteRow methods. The reason for this difference is that DataExpress DataSets allow for multiple views (via DataSetView) with separate cursors of the same StorageDataSet. Columns can also be marked persistent. Since several properties can be set on a Column, including display/edit masks, constraints, defaults and validation events, it is useful to persist Columns for a DataSet. This is most easily done interactively. Columns can be added and marked persistent in the JBuilder visual component tree, simply by editing any of their properties. Another valuable use of Columns is to persist meta data for QueryDataSets and ProcedureDataSets. When providing data for a QueryDataSet, meta data discovery is performed. The needed meta data is usually very basic: Table name, column names, column data type, unique row identifiers, precision, and scale. If for some reason the driver cannot provide this information, or retrieval of this information is slow, the meta data can be specified in a persistent Column. 1.3 The DataModule. This is similar to the Delphi DataModule. The DataModule is a nonvisual container for components. It is especially well-suited to containing collections of related DataExpress components (i.e. DataSets and Database components). Although the DataModule is not visible at runtime, it is visible and designable in the JBuilder VCD component tree. Although other containers like Frames and Applets can contain database-related components, it is generally a much better practice to centralize related database components into a DataModule. This allows the developer to separate business rules and application logic from components that are largely used for visual presentation (i.e. Frames and data-aware controls). The DataModule also allows for easier reuse of the components it contains. This is because a DataModule can be reused by multiple Frames or Applets. The best way to create a DataModule is to use the DataModule Wizard in JBuilder (File|New). This will create the basic skeleton of a DataModule. There are two ways to reference a DataModule inside another Frame or Applet. The easiest way is to add a statement in your visual container that creates a new instance of your DataModule: MyDataModule myDataModule = new MyDataModule(); The drawback to this is that there is that this instance is not easily referenced by other visual containers. The solution to this problem is to call a static method in your DataModule that instantiates the DataModule for the first caller and returns this same instance to any successive callers: MyDataModule myDataModule = MyDataModule.getDataModule(); You don't have to implement the getDataModule method yourself; the DataModule Wizard does this for you. 1.4 The Database component. This is a JDBC-specific component that manages a JDBC connection. QueryDataSets and ProcedureDataSets have a Database property. Multiple DataSets can share the same Database. The Database Connection property specifies the JDBC connection url, user name, password, and optional JDBC driver(s). The JDBC connection url is the JDBC method for specifying the location of a JDBC data provider (i.e. SQL server). It can actually contain all the information for making a successful connection, including user name and password. 1.5 Descriptor properties. There are several property names that end in "Descriptor." For better readability, the property inspector does not show "Descriptor" in the property name, but the generated code does. These are simple containers for groups of related properties that usually have customized property editors. SortDescriptor (sortkeys, caseInsensitive, descending) and QueryDescriptor (database, query, paramRow, executeOnOpen, asynchronousExecution) are examples of this practice. 1.6 Row classes. Though not shown in the hierarchy diagram above, the DataSet class actually derives from some row classes. The row hierarchy looks like this:
ReadRow. This is an abstract class that provides read access to a row of data. There are getters for the data types supported by JDBC standard. Data values can be accessed by ordinal or by name. There is also a method for copying one row to another. ReadWriteRow. This is an abstract class extension of ReadRow that provides read and write access to a row of data. There are getters and setters for the data types supported by the JDBC standard. There is also a method for setting default values and applying constraints. DataRow. This is a class that can be instantiated. Its constructors require at least a DataSet. The associated DataSet defines the number and type of columns. The DataRow has one row of storage that can be set and fetched. A DataRow can be scoped. A scoped DataRow is constructed by using the constructor that has a DataSet and String array argument. The String array is an array of Column names in the DataSet. A DataRow will only allow setting and fetching of the Columns it is scoped to. A scoped DataRow is useful for locate and lookup operations. The locate mechanism will only search on the columns specified in the scoped list of columns. DataSet. This is the same abstract class discussed in the DataSet hierarchy. As an extension of ReadWriteRow, the row of data being accessed by the ReadWrite methods is the current row that the DataSet is positioned to. So if you navigate to the 5th row and do a get operation, the values returned will be whatever is at the 5th row. ParameterRow. This is a class that can be instantiated. It contains one row of storage. Unlike DataRow, it gets its columns from add/setColumns() methods. It is used for parametized queries and procedures. The reason that DataRow cannot be used for query/procedure parameters is that there may be multiple parameters for the same column. An example of this would be a where clause that compared a column value to a start-and-end parameter. In this case, two parameter columns are needed for one data column. The Row classes are used extensively in the DataExpress APIs. The ReadRow and ReadWriteRow are used much like interfaces that indicate what the usage intent is. By using a class hierarchy, implementation is shared and there is a slight performance advantage of not using interfaces. The Row classes provide access to column values by ordinal and column name. Specifying columns by name is a more robust and readable way to write your code. Accessing columns by name is not quite as quick as by ordinal, but it is still quite fast if the number of columns in your DataSet is 20 or less, due to some patentedproprietary high-speed name/ordinal matching algorithms. It is also a good practice to use the same Strings for all access to the same column. This saves memory and is easier to type in if there are many references to the same column. Variant class. This class is unique to the Borland JBCL and is used to map JDBC type system into its internal type system. There is a mapping of JDBC types to Variant types. A Variant object can store any of the Variant Types. The DataExpress architecture makes extensive use of Variant for internal purposes. Although Variant is surfaced in some of the public methods of DataExpress components, most applications don't have to use Variants. There is an extra step to using a Variant because a Variant must be allocated before a public method can be called with it. Variants can be useful when you want to pass arbitrary data values across API layers. Variant also supports two null states: Variant.ASSIGNED_NULL and Variant.UNASSIGNED_NULL. This differentiation is useful if a DataSet is resolved back to a JDBC connection. If a value is Variant.UNASSIGNED_NULL, new rows will be inserted without specifying the values for the columns that are set to Variant.UNASSIGNED_NULL. This causes many servers to fill in default values for these columns. If the value for a column is Variant.ASSIGNED_NULL, then new rows will be inserted specifying that the values of these columns should be set to null. If a row is added without setting column values, they automatically get stored to the DataSet as Variant.UNASSIGNED_NULL 2. Providing data from JDBC data sources. 3. Navigating and editing data in a DataSet. 6. Resolving a DataSet back to a JDBC data source.
6.1 Automatic resolution. The simplest scenario is to call the saveChanges method of the Database component with one or more DataSets. Any component that extends from the DataSet component can be saved to a Database, regardless of whether it initially came from that Database. The saveChanges method will cause all of the inserts/deletes/updates made to the DataSet to be saved to the JDBC data source. By default all DataSets passed into saveChanges are saved in a single transaction. There is a Database.saveChanges() method with a boolean "doTransactions" parameter that can be set to false. Setting doTransactions to false causes no start/commit/rollback operations to be performed as the dataSets are saved. If there are multiple DataSets being saved and they are part of a master detail relationship established with the DataSet.MasterLink property, there is special logic that orders the saving of changes across the related DataSets. The ordering for DataSets in a master detail relationship is as follows: deletes, updates, then inserts. For deletes and updates, detail DataSets are processed first. For inserts, master DataSets are processed first. Errors can occur while saving changes. Common ones will be violation of server integrity constraints and resolution conflicts. A resolution conflict can happen from deleting a row that is already deleted, or updating a row that has been updated by another user. The default handling of these errors is to position the DataSet to the offending row (if it's not deleted) and display the error encountered with a message dialog. Although DataExpress has extensive built-in support for saving changes back to a JDBC data source, there are several ways in which an application can customize this process. A good portion of the DataExpress mechanism is generic and could be used for saving changes back to non-JDBC data sources. 6.2 Custom Resolution The first level of customization can be achieved by customizing a DataSet's Resolver. Any DataSet that descends from StorageDataSet has a Resolver property. If this is not set, a QueryResolver component is used by default. An application can instantiate a QueryResolver, set properties and event handlers on the QueryResolver, and then set this as the Resolver property for a StorageDataSet. QueryResolver has an UpdateMode property. This can be used to control the level of optimistic concurrency used when updating rows. There are three settings: 1) ALL_COLUMNS. If any column values have changed since a row was fetched, the update will fail. This is the default property setting. 2) KEY_COLUMNS. If any of the key columns have been updated since a row was fetched, the update will fail. 3) CHANGED_COLUMNS: If any key columns or any of the columns changed in the updated row have changed since a row was fetched, the update will fail. There are also ResolverListener events on a QueryResolver that can be wired. These allow the application to receive separate before, after, and error events for insert, delete, and update operations. The default behavior is to abort resolution and the transaction in process if there are any errors. This behavior can be overridden by wiring the error handlers of the QueryResolver component. Errors can be ignored, skipped, retried, or cause the whole resolution to be aborted. All of the error cases receive the DataSet being resolved as an argument. If this DataSet is wired to a visual control, it can be used to navigate the DataSet to the row that has a problem, using the DataSet goToRow(ReadRow row) method. The DataSet refetchRow() method is handy when errors are encountered for an updated row. When Executed for a QueryDataSet, this method will reexecute a query just to fetch the current contents of the row. This can also be used at any time to freshen the contents of a row. In our first release, we only provide a QueryResolver component. Developers or third parties can implement the SQLResolver interface to provide specialized resolver components. Although the Database component has a saveChanges() method to resolve one or more DataSets, it doesn't actually do any of the work. It delegates to a class called SQLResolutionManager. Here is a code snippet that illustrates what the Database component actually does for saveChanges:
SQLResolutionManager resolutionManager = new SQLResolutionManager(); Some developers may find it useful to instantiate SQLResolutionManager themselves to set the DoTransactions property or to set the DefaultResolver (this is used when the StorageDataSet property is not set). In the future, we may provide transaction events wired to the SQLResolutionManager. In the meantime, inheritance could be used to override start/commit/rollback methods of SQLResolutionManager. If this is still not enough control, an application can ask a StorageDataSet for three different DataSetViews: 1) StorageDataSet.getInsertedRows() shows all the inserted rows. 2) StorageDataSet.getDeletedRows() that shows all the deleted rows. 3) StorageDataSet.getUpdatedRows that shows all the updated rows. For updated rows, there is also a method on StorageDataSet to retrieve the original row contents. The original row is handy for performing searched updates against a SQL server. 6.4 JDBC meta data usage. There are several kinds of JDBC meta data that is used by the DataExpress provider and resolver mechanisms. This meta data is usually discovered automatically when the query is run. Here are some of the more important types of JDBC meta data automatically discovered by DataSet providers: 1) StorageDataSet.TableName property. If JDBC ResultSetMetaData does not provide this, the query string will be analyzed to discover the name. If the name cannot be discerned from the query string, it can be set directly on the StorageDataSet. 2) Column.ColumnName and Column.ColumnLabel. If labels are not supplied, they are set to the column name. 3) Column.RowId property is discovered using JDBC meta data APIs. It is set for one or more columns that uniquely identify a row. For Oracle, this is typically an Oracle row id. For other servers, this is a unique key (i.e. primary key). 4) Column.Searchable property determines whether a column can be included in a where clause. 5) Column.Scale and Column.Precision properties for numeric and String data types. For Strings, the precision is used as a validity constraint to prevent values longer than precision from being posted. The automatic discovery of meta data overrides settings that may have been already set by an application or component designer. Some forms of meta data can be expensive to derive (i.e. the Column.RowId property). For these reasons, there is a StorageDataSet.MetaDataUpdate property that can be used to prevent automatic discovery and update of meta data related properties. Currently, there are two settings: MetaDataUpdate.ALL and MetaDataUpdate.NONE. If MetatDataUpdate.NONE is selected, Column.RowId/Precision/Scale/Searchable, and StorageDataSet.TableName/SchemaName properties are not set on persistent Columns. 6.5 Secondary resolutions. Once a DataSet has been resolved, it can be resolved again if new changes are made. The old resolved changes will not be resolved in the successive resolutions unless they are changed again. This can be a problematic process because the state of a DataSet becomes more and more inconsistent as successive resolutions are performed. It may be better to refresh the DataSet (reexecute the query) after each save.
Java and all Java-based marks are trademarks or registered trademarks of Sun Microsystems, Inc. in the United States and other countries. Borland International, Inc. is independent of Sun Microsystems, Inc. |
|
| Back To Top Home Page |
||