Introduzione
La costruzione di funzioni hash è stata sempre finalizzata a consentire lÆaccesso "istantaneo" ai dati memorizzati, spesso però le tecniche utilizzate hanno svantaggi quali lo spreco di spazio, a causa delle locazioni inutilizzate, oppure la gestione complessa delle collisioni. Per questo motivo, nei casi in cui sia noto a priori lÆinsieme delle chiavi, si è pensato di costruire funzioni hash perfette, cioè prive di collisioni, o hash perfette minimali che utilizzano tutte le locazioni.
In particolare possiamo pensare a come funziona una funzione hash classica:
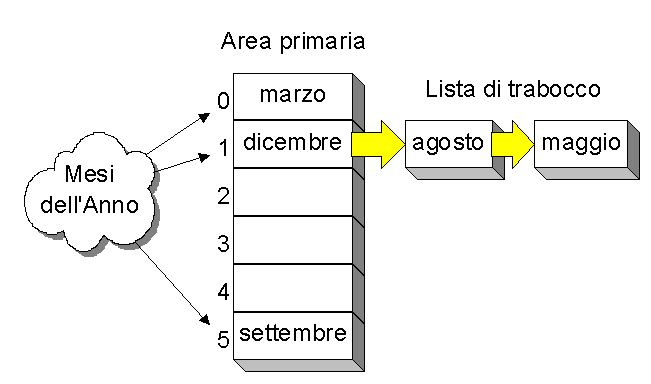
Dato un insieme di chiavi (nel nostro caso il nome dei dodici mesi dellÆanno) una funzione hash mappa una chiave in una determinata posizione dellÆarea primaria in modo deterministico (cioè una certa chiave K finirà sempre nello stessa posizione Hash(K) ). EÆ chiaro che può succedere che due chiavi K e Y abbiano lo stesso valore di hashing cioè che sia Hash(K) = Hash(Y) in questo caso si avrà una "collisione". Un modo semplice di gestire le collisioni è lÆutilizzo delle liste di trabocco come è mostrato in figura: le chiavi "dicembre", "agosto" e "maggio" hanno uno stesso valore di hash. In letteratura sono svariate le varianti degli algoritmi di hash che cercano di migliorare la gestione delle collisioni visto che da questo dipendono le performance.
Le funzioni hash perfette possono essere raggruppate in :
LÆuso di queste tecniche di hashing è ristretto solamente al caso in cui il set di chiavi è statico e noto a priori ma ugualmente sarebbero molteplici le applicazioni pronte a beneficiare di una tale classe di funzioni. In particolare oltre agli archivi memorizzati su supporti read-only, come per esempio i CD-ROM, anche i compilatori di linguaggi potrebbero utilizzare funzioni hash perfette allo scopo di velocizzare le ricerche nelle tabelle dei nomi, oppure gli interpreti PROLOG, in cui la velocità di accesso allÆelenco dei predicati è sempre un problema cruciale.
In questo articolo si analizzerà un algoritmo proposto da Czech e altri [] che utilizzando importanti nozioni della teoria dei grafi permette di generare funzioni hash OPMPHF!
Descrizione dellÆalgoritmo
Viene indicato con U lÆuniverso delle chiavi (stringhe di caratteri appartenenti ad un certo alfabeto); con N=|U| (leggi cardinalità di U) il numero di chiavi dellÆuniverso; con S Í U lÆinsieme delle chiavi considerate nel problema; con n=|S| il numero di chiavi in S; con m il numero di slot nella tabella hash T; con T la tabella hash con slot numerati da 0,...,(m-1). Inoltre risulta m=n poiché si considerano funzioni hash perfette minimali (MPHF).
LÆalgoritmo proposto cerca una funzione del tipo:
h(k)=(g(f1(k))+g(f2(k)) mod m
con h: S ® T biiettiva; e con:
f1,f2: S ®
[0,..,n-1], g: [0,..,n-1] ®
[0,..,m-1]
dove n è un parametro.
LÆalgoritmo è probabilistico e utilizza la generazione casuale di grafi. Infatti, la ricerca di funzioni OPMPHF h, è equivalente alla soluzione del seguente problema sui grafi.
Dato un grafo non orientato G = (V,E) dove V è lÆinsieme dei Vertici ed E lÆinsieme degli archi con |V| = n, |E| = m, trovare una funzione g: V ® [0,..,m-1] tale che la funzione h: E ® [0,..,m-1] con h(e=(u,v)) = (g(u)+g(v)) mod m sia biiettiva.
In parole più semplici si sta cercando di assegnare un valore a ciascun vertice in modo tale che, per ogni arco e (rappresentato come coppia ordinata (u,v) con u Î V e v Î V), la somma dei valori associati ai vertici agli estremi, modulo il numero degli archi, sia un numero unico in [0,..,m-1].

In particolare la chiave k rappresenta un arco del grafo che si sta costruendo i cui estremi sono rappresentato dallÆarco (u,v)=(f1(k),f2(k)) infatti le funzioni f1 e f2 hanno il compito di mappare una chiave in un vertice. Applicando le funzioni f1 e f2 a tutte le chiavi dellÆinsieme si costruisce un grafo a partire da un insieme di vertici isolati.