Základní jednotkou pro zpřístupňování dat v C++ Builderu
je rodina objektů datových množin. Naše aplikace používá datové množiny
pro veškerý přístup k databázím. Obecně objekt datové množiny reprezentuje
určitou tabulku obsaženou v databázi, nebo reprezentuje dotaz nebo uloženou
proceduru, které zpřístupňují databázi. Všechny objekty datových množin,
které používáme v našich databázových aplikacích, jsou odvozeny od TDataSet
a tedy od TDataSet dědí datové položky, vlastnosti, události a metody.
Abychom mohli používat libovolný objekt datové množiny, musíme pochopit
sdílenou funkčnost poskytnutou TDataSet.
Na následujícím obrázku je uvedena hierarchie všech komponent
datových množin.
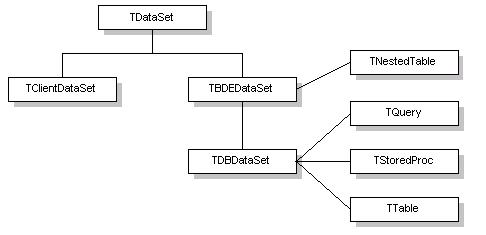 TDataSet je předek všech objektů datových množin,
které můžeme používat ve svých aplikacích. Definuje množinu datových položek,
vlastností, událostí a metod sdílených všemi objekty datových množin. TDataSet
je virtuální datová množina, což znamená, že většina jejich vlastností
a metod je virtuálních nebo čirých. Tyto virtuální metody mohou být přepsány
(a obvykle jsou) ve svých potomcích, ale v každém z nich mohou být implementovány
jinak. Čirá virtuální metoda je deklarována bez aktuální implementace.
Deklarace je prototyp, který popisuje metodu (a její parametry a návratový
typ), která musí být implementována ve všech potomcích.
TDataSet je předek všech objektů datových množin,
které můžeme používat ve svých aplikacích. Definuje množinu datových položek,
vlastností, událostí a metod sdílených všemi objekty datových množin. TDataSet
je virtuální datová množina, což znamená, že většina jejich vlastností
a metod je virtuálních nebo čirých. Tyto virtuální metody mohou být přepsány
(a obvykle jsou) ve svých potomcích, ale v každém z nich mohou být implementovány
jinak. Čirá virtuální metoda je deklarována bez aktuální implementace.
Deklarace je prototyp, který popisuje metodu (a její parametry a návratový
typ), která musí být implementována ve všech potomcích.
Protože TDataSet obsahuje čiré virtuální metody,
nemůže být v našich aplikacích použita přímo. Musíme vytvářet instance
potomků TDataSet jako je
TTable,
TQuery,
TStoredProc
a TClientDataSet a použít je ve své aplikaci nebo odvodit svou vlastní
třídu datové množiny od TDataSet nebo jeho potomků a zapsat implementaci
všech jejich abstraktních metod.
TDataSet definuje vše, co je společné pro všechny
objekty datových množin. Např. TDataSet definuje základní strukturu
všech datových množin: pole komponent TField, které odpovídají sloupcům
v jedné nebo více databázových tabulkách a vyhledávací nebo počitatelné
položky poskytnuté naši aplikaci.
V této kapitole se seznámíme s funkčností TDataSet,
kterou dědí objekty datových množin používané v našich aplikacích. Tuto
sdílenou funkčnost musíme pochopit, abychom mohli používat libovolné objekty
datových množin. Je popsána v těchto bodech:
Typy datových množin
K pochopení společné koncepce pro všechny objekty datových
množin a jako přípravu pro vývoj svých vlastních přizpůsobených datových
množin, které používají BDE, je zapotřebí se seznámit s touto kapitolou.
K vývoji tradičních dvou vrstvových databázových aplikací
typu Klient/server používajících BDE se musíme také seznámit s BDE. Úvod
do TBDEDataSet a TDBDataSet a seznámení s BDE bude uvedeno
později. V této kapitole jsou popsány sdílené služby nejčastěji používaných
komponent datových množin TQuery, TStoredProc a TTable.
S některými verzemi C++ Builderu můžeme vyvíjet více
vrstvové databázové aplikace používající distribuované datové množiny.
S prací klientských datových množin ve více vrstvových aplikacích se seznámíme
později.
Otevírání a uzavírání
datových množin
Abychom mohli číst nebo zapisovat data tabulky (nebo dotazu),
aplikace musí nejprve otevřít datovou množinu. Datovou množinu lze otevřít
dvěmi způsoby. Nastavíme vlastnost Active datové množiny na true
a to při návrhu v Inspektoru objektů nebo kódem za běhu. Např.
CustTable->Active = true;
Druhou množností je volání metody Open pro datovou
množinu za běhu:
CustQuery->Open();
Obdobně, datovou množinu můžeme také uzavřít dvěmi způsoby.
Vlastnost
Active datové množiny nastavíme na false a to při
návrhu v Inspektoru objektů nebo kódem za běhu. Např.
CustQuery->Active = false;
Druhou možností je volání metody Close pro datovou
množinu za běhu:
CustTable->Close();
Datovou množinu musíme uzavřít abychom mohli změnit jisté
její vlastnosti (např. TableName komponenty TTable). Za běhu
můžeme také chtít uzavřít datovou množinu z jistých důvodů specifických
pro naši aplikaci.
Zjišťování
a nastavování stavu datové množiny
Stav nebo režim datové množiny určuje co lze provádět s jejími
daty. Např. když datová množina je uzavřena, pak její stav je dsInactive,
což znamená, že není možno nic provádět s jejími daty. Za běhu, můžeme
testovat vlastnost datové množiny State (je určená pouze pro čtení)
k zjištění jejího současného stavu. Následující tabulka uvádí možné hodnoty
vlastnosti
State a co tyto stavy znamenají:
| Hodnota |
Význam |
| dsInactive |
Uzavřená datová množina. Její data jsou nedostupná. |
| dsBrowse |
Otevřená datová množina. Její data můžeme prohlížet,
ale ne měnit. Je to implicitní stav otevřené datové množiny. |
| dsEdit |
Otevřená datová množina. Současný řádek může být modifikován. |
| dsInsert |
Otevřená datová množina. Je vkládán nebo přidáván nový
řádek. |
| dsSetKey |
Pouze pro TTable nebo TClientDataSet. Otevřená
datová množina. Umožňuje nastavovat hodnoty rozsahu a klíče použité v operacích
rozsahu a GotoKey. |
| dsCalcFields |
Otevřená datová množina. Indikuje, že množina je pod
řízením události
OnCalcFields. Zabraňuje změnám položek, které nejsou
počitatelné. |
| dsCurValue |
Pouze pro interní použití. |
| dsNewValue |
Pouze pro interní použití. |
| dsOldValue |
Pouze pro interní použití. |
| dsFilter |
Otevřená datová množina. Indikuje, že množina je řízena
operací filtru. Filtrovaná množina dat může být prohlížena a žádná data
nemohou být změněna. |
Když aplikace otevře datovou množinu, pak je implicitně
uvedena do stavu
dsBrowse. Stav datové množiny se mění podle toho
jak aplikace zpracovává data. Otevřenou datovou množinu převedeme z jednoho
stavu do jiného, kódem naší aplikace nebo vestavěným chováním datových
komponent. Pro převedení datové množiny do stavu dsEdit, dsBrowse,
dsInsert
nebo dsSetKey voláme metodu odpovídající jménu stavu. Např. následující
kód uvádí CustTable do stavu dsInsert, akceptuje vstup uživatele
jako nový záznam a zapisuje nový záznam do databáze:
CustTable->Insert(); // uvádí datovou množinu
do stavu dsInsert
AddressPromptDialog->ShowModal();
if (AddressPromptDialog->ModalResult == mrOK)
CustTable->Post(); // při úspěchu
přechod do stavu dsBrowse
else
CustTable->Cancel(); // přechod do
stavu dsBrowse
Tento příklad také ukazuje, že stav datové množiny se
automaticky změní na dsBrowse, když metoda Post úspěšně zapíše
záznam do databáze (při chybě Post se stav datové množiny nemění)
nebo když je volána metoda Cancel.
Některé stavy nemohou být nastavovány přímo. Např. k
uvedení datové množiny do stavu dsInactive, nastavíme její vlastnost
Active
na false nebo voláme metodu Close datové množiny. Následující
příkazy jsou ekvivalentní:
CustTable->Active = false;
CustTable->Close();
Zbývající stavy (dsCalcField, dsCurValue,
dsNewValue,
dsOldValue
a dsFilter) nemohou být nastavovány naší aplikací. Do těchto stavů
datová množina přejde automaticky, když je to nutné. Např. stav
dsCalcField
je nastaven, když je generována událost OnCalcField. Když událost
OnCalcField
skončí, pak datová množina se vrátí do předchozího stavu.
Poznámka: Když se změní stav datové množiny,
pak je generována událost OnStateChange pro všechny komponenty datových
zdrojů přiřazených k datové množině.
V následujících bodech je provedeno seznámení s těmito
stavy, jak a kdy jsou stavy nastaveny, jaké jsou vztahy mezi jednotlivými
stavy a kde najdeme potřebné informace. Jsou zde uvedeny tyto body:
Deaktivování datové množiny
Datová množina je neaktivní, když je uzavřena. Nemůžeme přistupovat
k záznamům v uzavřené datové množině. Při návrhu, datová množina je uzavřena,
dokud nenastavíme její vlastnost Active na true. Za běhu
je datová množina uzavřena dokud ji aplikace neotevře voláním metody Open
nebo nastavením vlastnosti Active na true. Když otevřeme
neaktivní datovou množinu, pak její stav se automaticky změní na dsBrowse.
K udělání datové množiny neaktivní voláme její metodu
Close.
Můžeme zapsat obsluhy událostí OnBeforeClose a OnAfterClose,
které reagují na metodu Close pro datovou množinu. Např. pokud datová
množina je ve stavu dsEdit nebo dsInsert a aplikace volá
Close,
pak se aplikace může dotázat uživatele, zda změny zapsat nebo zrušit a
to před uzavřením datové množiny (v obsluze události OnBeforeClose):
void __fastcall TForm1::VerifyBeforeClose(TDataSet
*DataSet)
{
if (DataSet->State ==
dsEdit || DataSet->State == dsInsert)
{
TMsgDlgButtons
btns;
btns <<
mbYes << mbNo;
if (MessageDlg("Post
changes before closing?",mtConfirmation,btns,0)==mrYes)
DataSet->Post();
else
DataSet->Cancel();
}
}
Prohlížení datové množiny
Když aplikace otevře datovou množinu, pak datová množina
automaticky přejde do stavu dsBrowse. Tento stav umožňuje prohlížet
záznamy v datové množině, ale neumožňuje jejich editaci nebo vkládání nových
záznamů. Ze stavu dsBrowse můžeme přejít do všech ostatních stavů.
Např. voláním metody Insert nebo Append pro datovou množinu
změníme její stav z dsBrowse na dsInsert (pokud to ostatní
vlastnosti datové množiny umožňují). Volání SetKey uvádí datovou
množinu do stavu dsSetKey.
Dvě metody přiřazené ke všem datovým množinám, mohou
vrátit datovou množinu do stavu dsBrowse. Cancel ukončuje
současnou editační, vkládací nebo vyhledávací úlohu a vždy vrací datovou
množinu do stavu dsBrowse.
Post
se pokusí zapsat změny do
databáze a v případě úspěchu také vrací datovou množinu do stavu dsBrowse.
Při neúspěchu se současný stav datové množiny nemění.
Umožnění editace datové množiny
Datová množina musí být ve stavu dsEdit, aby aplikace
mohla modifikovat její záznamy. V našem kódu můžeme použít metodu Edit
k uvedení datové množiny do stavu dsEdit, pokud vlastnost
CanModify
(určená pouze pro čtení) datové množiny je true. Vlastnost
CanModify
je true, pokud k databázi spojené s datovou množinou máme čtecí
a zápisová privilegia.
Některé datové ovladače na formuláři v naši aplikaci
mohou automaticky uvést datovou množinu do stavu dsEdit, pokud:
-
vlastnost ReadOnly ovladače je false (implicitně),
-
vlastnost AutoEdit datového zdroje pro ovladač je
true
a
-
vlastnost CanModify datové množiny je true.
Důležité: Pro komponentu TTable, pokud vlastnost
ReadOnly
je true, pak CanModify je false, což zabraňuje editaci
záznamů. Podobně pro komponentu TQuery, pokud vlastnost RequestLive
je false, pak CanModify je false.
Poznámka: I když datová množina je ve stavu
dsEdit,
pak pro SQL databáze, editace záznamů nemusí být úspěšná, pokud uživatel
naší aplikace nemá potřebná přístupová privilegia.
Datovou množinu můžeme vrátit ze stavu dsEdit
do stavu dsBrowse v kódu voláním metod Cancel, Post
nebo Delete. Cancel zruší editaci současné položky nebo záznamu.
Post
se pokusí zapsat modifikovaný záznam do datové množiny a v případě úspěchu
vrací datovou množinu do stavu dsBrowse (při neúspěchu se stav nemění).
Delete
se pokusí odstranit současný záznam z datové množiny a v případě úspěchu
vrací datovou množinu do stavu dsBrowse (v případě neúspěchu datová
množina zůstává ve stavu dsEdit).
Datové ovladače pro které editace je povolena, automaticky
volají Post, když uživatel provede libovolnou akci, která mění současný
záznam (přesun na jiný záznam) nebo která způsobí, že ovladač ztrácí zaostření
(přesun na jiný ovladač na formuláři).
Umožnění vkládání nových
záznamů
Datová množina musí být ve stavu dsInsert, aby aplikace
mohla k ní přidat nový záznam. V našem kódu můžeme použít metodu Insert
nebo Append k uvedení datové množiny do stavu dsInsert, pokud
vlastnost určená pouze pro čtení CanModify datové množiny je false.
Pro stav dsInsert platí vše, co je výše uvedeno pro stav dsEdit.
Umožnění prohledávání
datových množin
Libovolnou datovou množinu můžeme prohledávat pomocí metod
Locate
a Lookup. Komponenty TTable poskytují další metody (GotoKey
a FindKey), která umožňují vyhledávat záznamy na základě indexu
tabulky. Pro použití těchto metod pro komponentu tabulky, komponenta musí
být ve stavu dsSetKey. Stav dsSetKey je aplikovatelný pouze
na komponenty TTable. Datovou množinu uvedeme do stavu dsSetKey
za běhu voláním metody SetKey. Metody GotoKey, GotoNearest,
FindKey
a FindNearest ukončující současné hledání vracejí datovou množinu
do stavu dsBrowse po dokončení vyhledávání.
Můžeme zobrazit a editovat podmnožinu dat pro libovolnou
datovou množinu pomocí filtrů. Komponenta TTable také podporuje
další způsob přístupu k podmnožině záznamů, nazvaný rozsah. K vytvoření
a aplikování rozsahu na tabulku, tabulka musí být ve stavu dsSetKey.
Počitatelné položky
C++ Builder uvádí datovou množinu do režimu dsCalcFields,
když aplikace volá obsluhu události OnCalcFields datové množiny.
Tento stav zabraňuje modifikacím nebo přidávání záznamů do datové množiny,
mimo modifikace počitatelných položek modifikovaných obsluhou. Všechny
ostatní modifikace jsou zakázány, protože OnCalcFields používá hodnoty
ostatních položek k odvození hodnot počitatelných položek. Změny na těchto
ostatních položkách by mohli znehodnotit hodnoty přiřazené počitatelným
položkám. Když obsluha
OnCalcFields skončí, pak datová množina se
vrátí do stavu dsBrowse.
Filtrování záznamů
Když aplikace volá obsluhu události OnFilterRecord
datové množiny, pak C++ Builder uvádí datovou množinu do stavu dsFilter.
Tento stav zabraňuje modifikacím nebo přidávání záznamů do datové množiny
během procesu filtrování a tedy filtr nemůže být znehodnocen. Po dokončení
obsluhy OnFilterRecord, se datová množina vrací do stavu dsBrowse.
Aktualizování záznamů
Když provádíme operace odložených aktualizací, pak C++ Builder
může uvést datovou množinu dočasně do stavu dsNewValue, dsOldValue
nebo dsCurValue. Tyto stavy indikují, že odpovídající vlastnosti
položkových komponent (NewValue,
OldValue a CurValue)
mohou být zpřístupněny a to obvykle v obsluze události
OnUpdateError.
Naše aplikace nemůže vidět nebo nastavovat tyto stavy.
Procházení datovými množinami
Každá aktivní datová množina má kurzor (ukazatel na současný
řádek v datové množině). Současný řádek v datové množině je ten, jehož
hodnoty mohou být zpracovány metodami editace, vkládání a rušení a ten
jehož hodnoty položek jsou právě zobrazeny v jednotlivých položkových datových
ovladačích na formuláři, jako je např. TDBEdit, TDBLabel
nebo TDBMemo.
Současný řádek můžeme změnit přesunem kurzoru k ukazování
na jiný řádek. Následující tabulka uvádí metody, které můžeme použít v
kódu aplikace k přesunu na jiný záznam:
| Metoda |
Popis |
| First |
Přesouvá kurzor k ukazování na první řádek v datové množině. |
| Last |
Přesouvá kurzor k ukazování na poslední řádek v datové
množině. |
| Next |
Přesouvá kurzor k ukazování na následující řádek v datové
množině. |
| Prior |
Přesouvá kurzor k ukazování na předchozí řádek v datové
množině. |
| MoveBy |
Přesouvá kurzor o specifikovaný počet řádků dopředu nebo
zpět v datové množině. |
Vizuální datový ovladač TDBNavigator zaobaluje
tyto metody jako tlačítka, která uživatel může stisknout k pohybu po záznamech
za běhu aplikace.
Mimo těchto metod, další tabulka popisuje dvě logické
vlastnosti datové množiny, které poskytují užitečné informace při procházení
záznamy datové množiny:
| Vlastnost |
Popis |
| Bof |
true pokud kurzor je na prvním řádku v datové
množině; false v opačném případě |
| Eof |
true pokud kurzor je na posledním řádku v datové
množině; false v opačném případě |
V této části jsou uvedeny ještě tyto body:
Používání metod
First a Last
Metoda First přesouvá kurzor na první řádek v datové
množině a nastavuje vlastnost Bof na true. Pokud kurzor je
již na prvním řádku datové množiny, pak First nic nedělá. Např.
následující kód přesouvá kurzor na první záznam v CustTable:
CustTable->First();
Metoda Last přesouvá kurzor na poslední řádek
v datové množině a nastavuje vlastnost Eof na true. Pokud
kurzor je již na posledním řádku datové množiny, pak Last nic nedělá.
Např. následující kód přesouvá kurzor na poslední záznam v CustTable:
CustTable->Last();
Poznámka: I když mohou být různé důvody pro
přechod na první nebo poslední řádek v datové množině bez intervence uživatele,
můžeme povolit uživateli přechod ze záznamu na záznam pomocí komponenty
TDBNavigator.
Tato komponenta obsahuje tlačítka, která umožňují uživateli přesun na první
nebo poslední řádek aktivní datové množiny. Událost
OnClick těchto
tlačítek volá metody First nebo Last datové množiny.
Používání metod
Next a Prior
Metoda Next přesouvá kurzor dopředu o jeden řádek
v datové množině a nastavuje Bof na false, pokud datová množina
není prázdná. Pokud kurzor je již na posledním řádku datové množiny, pak
volání Next nic nedělá. Např. následující kód přesouvá kurzor na
následující záznam v CustTable:
CustTable->Next();
Metoda Prior přesouvá kurzor zpět o jeden řádek
v datové množině a nastavuje Eof na false, pokud datová množina
není prázdná. Pokud kurzor je již na prvním řádku datové množiny, pak volání
Prior
nic nedělá. Např. následující kód přesouvá kurzor na předcházející záznam
v CustTable:
CustTable->Prior();
Požívání metody MoveBy
MoveBy umožňuje specifikovat o kolik řádků dopředu
nebo dozadu přesunout kurzor v datové množině. Přesun je relativní k současnému
záznamu v době, kdy MoveBy je voláno. MoveBy také nastavuje
vlastnosti
Bof a Eof datové množiny podle skutečného stavu.
Tato metoda přebírá celočíselný parametr určující o kolik řádků se přesouváme.
Kladná čísla indikují směr dopředu a záporná přesun zpět.
MoveBy vrací počet řádků o který byl proveden
přesun. Pokud se pokusíme provést přesun o více řádků než kolik jich je
k začátku nebo konci datové množiny, pak počet řádků vrácený MoveBy
se liší od počtu řádků požadovaného přesunu. Přesun končí při dosažení
prvního nebo posledního řádku v datové množině. Následující kód přesouvá
kurzor o dva záznamy zpět v CustTable:
CustTable->MoveBy(-2);
Poznámka: Pokud používáme MoveBy ve
své aplikaci a pracujeme ve víceuživatelském databázovém prostředí, nesmíme
zapomenout, že databáze se mění. Záznam, který byl o pět záznamů zpět může
být nyní o čtyři, šest nebo neznámý počet záznamů zpět, protože několik
uživatelů může současně přistupovat k databázi a měnit její data.
Používání vlastností Eof a
Bof
Běhové vlastnosti (určené pouze pro čtení) Eof (End
of file) a Bof (Begin of file) jsou užitečné pro procházení datovou
množinou, obzvláště když chceme procházet všemi záznamy v datové množině.
Když Eof je true, pak kurzor je na posledním
řádku v datové množině. Eof je true, pokud aplikace otevře
prázdnou datovou množinu, volá metodu Last datové množiny, volá
metodu Next datové množiny a metoda je neúspěšná neboť kurzor je
na posledním řádku datové množiny nebo volá SetRange na prázdný
rozsah nebo datovou množinu. Eof je v ostatních případech nastaveno
na false.
Eof je často testováno v podmínkách cyklů k řízení
procesu iterace všemi záznamy v databázi. Pokud otevřeme datovou množinu
obsahující záznamy (nebo voláme First), pak Eof je false.
K procházení záznamy datové množiny vytvoříme cyklus, který je ukončen,
když Eof je true. Uvnitř cyklu voláme Next pro každý
záznam v datové množině. Eof je false dokud Next nepřejde
na poslední záznam. Následující příklad kódu ukazuje jeden způsob procházení
záznamy datové množiny nazvané CustTable:
CustTable->DisableControls();
try
{
CustTable->First();
// přechod na první záznam
while (!CustTable->Eof) // cyklus
dokud Eof není true
(
// Zpracování každého
záznamu
...
CustTable->Next();
// když jsme na posledním
záznamu, pak Eof je true; jinak je false
}
}
__finally
{
CustTable->EnableControls();
}
Tip: Tento příklad také ukazuje jak zakázat
a povolit vizuální datové ovladače spojené s datovou množinou. Pokud vizuální
datové ovladače během procházení datovou množinou zakážeme, pak proces
iterace je urychlen, neboť C++ Builder nemusí aktualizovat obsah těchto
ovladačů při změně aktuálního záznamu. Po dokončení iterace, ovladače opět
povolíme, aby obsahovaly hodnoty pro nový současný řádek. Povšimněte si,
že povolení ovladačů je vloženo do klauzule __finally příkazu try
... __finally. Tím zajistíme, že i když výjimka ukončí cyklus předčasně,
ovladače nezůstanou zakázané.
Bof je true, když kurzor je na prvním řádku
datové množiny.
Bof je nastaveno na true, když aplikace otevře
datovou množinu, volá metodu First datové množiny, volá metodu Prior
datové množiny když kurzor je na jejím prvním řádku nebo volá SetRange
na prázdný rozsah nebo datovou množinu. V ostatních případech je Bof
nastaveno na false.
Podobně jako Eof i Bof může být použito
v podmínkách cyklů při řízení iteračního zpracování záznamů v datové množině.
Ukazuje to následující kód:
CustTable->DisableControls(); // urychlení
zpracování
try
{
while (!CustTable->Bof)
// cyklus dokud Bof je true
(
// zpracování každého
záznamu
...
CustTable->Prior();
}
}
catch (...)
{
CustTable->EnableControls();
throw;
}
CustTable->EnableControls();
Označování a návrat na záznamy
Mimo přesunu ze záznamu na záznam v datové množině, je často
také užitečné označit jisté místo v datové množině, abychom se na ně mohli
rychle vrátit, když je potřeba. TDataSet a jeho potomci implementují
službu záložek, která umožňuje označit záznamy a později se na ně vracet.
Služba záložek se skládá z vlastnosti Bookmark a pěti metod pro
práci se záložkami.
Vlastnost Bookmark indikuje, která záložka z mnoha
záložek v naši aplikaci je aktuální. Bookmark je řetězec, který
identifikuje aktuální záložku. Kdykoliv můžeme předat další záložku, která
se stává aktuální záložkou.
TDataSet implementuje virtuální metody záložek.
I když tyto metody zajišťují, že libovolný objekt odvozený od TDataSet
vrací při volání metody záložky hodnotu, vrácená hodnota je implicitní
a neurčuje současné místo. Potomci TDataSet, jako je TBDEDataSet,
reimplementují metody záložek k návratu rozumných hodnot podle následujícího
seznamu:
-
BookmarkValid - pro určení zda specifikovaná záložka
je použitelná.
-
CompareBookmarks - test, zda dvě záložky jsou stejné.
-
GetBookmark - alokování záložky pro současnou pozici
v datové množině.
-
GotoBookmark - návrat na záložku dříve vytvořenou
GetBookmark.
-
FreeBookmark - uvolnění záložky dříve vytvořené GetBookmark.
Pro vytvoření záložky v naši aplikaci musíme deklarovat proměnnou
typu TBookmark, pak volat GetBookmark k alokování místa pro
proměnnou a nastavení její hodnoty na jisté místo v datové množině. Proměnná
TBookmark
je ukazatel (void *).
Před voláním GotoBookmark k přesunu na specifikovaný
záznam, můžeme volat BookmarkValid k určení zda záložka ukazuje
na záznam.
BookmarkValid vrací true, pokud specifikovaná
záložka na záznam ukazuje. V TDataSet,
BookmarkValid vždy
vrací false (indikace, že záložka není přípustná). Potomci
TDataSet
metodu reimplementují k poskytnutí smysluplné návratové hodnoty.
Můžeme také volat CompareBookmarks k zjištění
zda se chceme přesunout na jinou (ne současnou) záložku. TDataSet::CompareBookmarks
vždy vrací 0 (indikace, že záložky jsou identické). Potomci TDataSet
tuto metodu reimplementují k návratu smysluplné hodnoty.
Když záložku předáme GotoBookmark, pak kurzor
datové množiny je přesunut na místo specifikované v záložce. TDataSet::GotoBookmark
je čirá abstraktní metoda. Potomci TDataSet ji smysluplně reimplementují.
FreeBookmark uvolňuje paměť alokovanou pro specifikovanou
záložku, když již není zapotřebí. FreeBookmark můžeme také volat
před opětovným použitím existující záložky.
Následující kód ukazuje jedno z možných použití záložky:
void DoSomething (const TTable *Tbl)
{
TBookmark Bookmark=Tbl->GetBookmark();//Alokování
paměti a přiřazení hodnoty
Tbl->DisableControls(); // Vypnutí
zobrazování hodnot v datových ovladačích
try
{
Tbl->First(); // Přechod
na první záznam v tabulce
while (!Tbl->Eof) // Procházení
všemi záznamy tabulky
{
// Naše zpracování
záznamů
...
Tbl->Next();
}
}
__finally
{
Tbl->GotoBookmark(Bookmark);
Tbl->EnableControls();
// Zapnutí zobrazování hodnot v datových ovladačích
Tbl->FreeBookmark(Bookmark);
// Dealokace paměti pro záložku
throw;
}
}
Před procházením záznamy jsou ovladače zakázány. Pokud
v průběhu procházení záznamy vznikne chyba, pak klauzule __finally
zajistí, že ovladače jsou povoleny a záložka uvolněna a to i při předčasném
ukončení cyklu.
Prohledávání datové množiny
V libovolné datové množině můžeme hledat určitý záznam pomocí
obecných prohledávacích metod Locate a Lookup. Tyto metody
umožňují hledání v libovolném typu sloupce v libovolné datové množině.
Budou popsány v těchto bodech:
Používání Locate
Locate přesouvá kurzor na první řádek odpovídající
specifikovaným vyhledávacím kritériím. V nejjednodušším tvaru, předáme
Locate
jméno prohledávaného sloupce, hledanou hodnotu a příznaky voleb určující
zda při hledání rozlišovat velikost písmen nebo zda používat částečné vyhledávání.
Např. následující kód přesouvá kurzor na první řádek, kde hodnota ve sloupci
Company
je Professional Divers, Ltd.:
TLocateOptions SearchOptions;
SearchOptions.Clear();
SearchOptions << loPartialKey;
bool LocateSuccess=CustTable->Locate("Company","Professional
Divers, Ltd.",
SearchOptions);
Jestliže Locate nalezne vyhovující záznam, pak
tento záznam se stane současným a Locate vrací true. Není-li
vyhovující záznam nalezen, pak Locate vrací false a současný
záznam se nemění.
Locate můžeme použít i pro hledání ve více sloupcích
a můžeme specifikovat více hodnot pro hledání. Hledané hodnoty jsou variantami
(datový typ umožňující používání libovolného datového typu), což umožňuje
specifikovat ve vyhledávacích kritériích různé datové typy. Při specifikaci
více sloupců ve vyhledávacím řetězci, oddělujeme jednotlivé prvky v řetězci
středníky. Protože vyhledávané hodnoty jsou variantami, pak při předávání
více hodnot musíme jako parametr předat pole typu variant (např. hodnoty
vrácené metodou Lookup) nebo musíme vytvořit pole variant pomocí
funkce VarArrayOf.
Následující kód ukazuje hledání ve více sloupcích pomocí
více vyhledávaných hodnot a použití vyhledávání typu částečného klíče:
TLocateOptions Opts;
Opts.Clear();
Opts << loPartialKey;
Variant locvalues[2];
locvalues[0] = Variant("Sight Diver");
locvalues[1] = Variant("P");
CustTable->Locate("Company;Contact", VarArrayOf(locvalues,
1), Opts);
Locate používá nejrychlejší možnou metodu k lokalizaci
hledaného záznamu. Pokud prohledávaný sloupec je indexován a index je kompatibilní
s námi určenou volbou hledání, pak Locate použije index.
Používání Lookup
Lookup hledá první řádek, který vyhovuje specifikovaným
vyhledávacím kritériím. Při nalezení řádku, jsou provedena přepočítání
všech počitatelných položek a vyhledávacích položek přiřazených k datové
množině a potom metoda vrátí jednu nebo více položek z nalezeného řádku.
Lookup
nepřesouvá kurzor na nalezený řádek, pouze z něj vrací hodnoty.
V nejjednodušší formě, předáme Lookup jméno prohledávaného
sloupce, hledanou hodnotu a vracenou položku nebo položky. Např. následující
kód hledá první řádek v CustTable, kde ve sloupci Company
je hodnota Professional Divers, Ltd. a vrací jméno podniku, kontaktní
osobu a telefonní číslo:
Variant LookupResults = CustTable->Lookup("Company",
"Professional Divers, Ltd", "Company;Contact;Phone");
Lookup vrací hodnoty specifikovaných položek z
prvního vyhovujícího záznamu. Hodnoty jsou vraceny jako varianty. Jestliže
je požadováno vracení více hodnot, pak Lookup vrací pole typu Variant.
Pokud žádný záznam nevyhovuje, pak Lookup vrací prázdnou variantu.
Více informací o polích variant naleznete v nápovědě.
Lookup také umožňuje hledání ve více sloupcích
a specifikovat více hodnot pro hledání. Ve specifikaci řetězců obsahujících
více sloupců nebo výsledkových položek, oddělujeme jednotlivé položky středníky.
Protože hledané hodnoty jsou variantami, pak při předávání více hodnot,
musíme předat jako parametr pole typu Variant (např. vrácené hodnoty
z metody Lookup) nebo musíme vytvořit pole variant pomocí funkce
VarArrayOf.
Následující kód ukazuje hledání ve více sloupcích:
Variant LookupResults;
Variant locvalues[2];
Variant v;
locvalues[0] = Variant("Sight Diver");
locvalues[1] = Variant("Kato Paphos");
LookupResults = CustTable->Lookup("Company;City",
VarArrayOf(locvalues, 1),
"Company;Addr1;Addr2;State;Zip");
// výsledek vložíme do globálního seznamu
řetězců (vytvořeného někde jinde)
pFieldValues->Clear();
for (int i = 0; i < 5; i++) // Lookup
požadoval 5 položek
{
v = LookupResults.GetElement(i);
if (v.IsNull())
pFieldValues->Add("");
else
pFieldValues->Add(v);
}
Lookup používá nejrychlejší možnou metodu k nalezení
vyhovujícího záznamu. Jestliže prohledávané sloupce jsou indexovány, pak
Lookup
index použije.
Zobrazování
a editace podmnožiny dat pomocí filtrů
Aplikaci často zajímá pouze podmnožina záznamů v datové množině.
Např. nás mohou zajímat pouze záznamy obsahující jistou množinu hodnot
položek. V těchto případech můžeme použít filtry k omezení přístupu aplikace
k podmnožině všech záznamů v datové množině.
Filtr specifikuje podmínku, kterou záznam musí splňovat,
aby byl zobrazen. Podmínka filtru může být zadána ve vlastnosti Filter
datové množiny nebo zakódována v její obsluze události OnFilteredRecord.
Podmínky filtru jsou založeny na hodnotách v několika specifikovaných položkách
v datové množině a to bez ohledu na to, zda tyto položky jsou indexovány.
Např. k zobrazení pouze těch záznamů, které se týkají Kalifornie,
můžeme použít filtr, kde budeme ve sloupci State požadovat hodnotu
"CA".
Poznámka: Filtry jsou aplikovány na všechny
záznamy získané z datové množiny. Když chceme filtrovat velké množství
dat, pak je výhodnější použít k omezení získaných záznamů dotaz nebo nastavit
rozsah pro indexovanou tabulku.
V této sekci jsou uvedeny následující body:
Povolení a zakazování filtrování
Povolování filtrování datové množiny je tříkrokový proces:
-
Vytvoříme filtr.
-
Nastavíme volby filtru
pro testování založeném na řetězcích (je-li potřeba).
-
Nastavíme vlastnost Filtered na true.
Když je filtrování povoleno, pak aplikace získává pouze ty
záznamy, které splňují filtrovací kriteria. Filtrování je vždy dočasný
proces. Můžeme jej vypnout nastavením vlastnosti Filtered na false.
Vytvoření filtru
Jsou dva způsoby vytváření filtrů pro datovou množinu:
Specifikujeme
podmínku ve vlastnosti Filter
Hlavní výhodou vytváření filtrů pomocí vlastnosti Filter
je to, že naše aplikace může vytvářet, měnit a aplikovat filtr dynamicky
(např. v závislosti na vstupu uživatele). Hlavní nevýhodou je to, že filtrovací
podmínka musí být vyjádřena jako jednoduchý textový řetězec, nemůže používat
konstrukce větvení a cyklů a nemůže testovat nebo porovnávat své hodnoty
s hodnotami, které nejsou v datové množině.
Výhodou události OnFilterRecord je to, že filtr
může být složitý a proměnný, může být vytvořen více řádky kódu používající
větvení a cykly a může testovat hodnoty datové množiny s hodnotami mimo
datovou množinu (např. textem v editačním ovladači). Nevýhodou je to, že
filtr je vytvořen během návrhu a nemůže být modifikován v závislosti na
vstupu uživatele. Můžeme ale vytvořit několik obsluh událostí a přepínat
se mezi nimi.
K vytvoření filtru pomocí vlastnosti Filter, nastavíme
hodnotu této vlastnosti na řetězec obsahující filtrovací podmínku. Např.
následující příkaz vytváří filtr, který testuje položku State datové
množiny na hodnotu pro stát Kalifornie:
Dataset1->Filter = "State = 'CA'";
Můžeme také dodat hodnotu pro Filter na základě
textu zadaného v ovladači. Např. následující příkaz přiřazuje vlastnosti
Filter
text z editačního ovladače:
Dataset1->Filter = Edit1->Text;
Řetězec můžeme také vytvořit z pevného textu a dat zadaných
uživatelem v ovladači:
Dataset1->Filter = AnsiString("State = '")
+ Edit1->Text + "'";
Po specifikaci hodnoty pro Filter, aplikujeme
filtr na datovou množinu nastavením vlastnosti Filtered na true.
Můžeme porovnávat hodnoty položek s konstantami a používat následující
operátory: < > >= <= = <> AND NOT OR. Pomocí kombinace
těchto operátorů, můžeme vytvářet složitější filtry. Např. následující
podmínka používá operátor
AND:
(Custno > 1400) AND (Custno < 1500);
Poznámka: Při zapnutém filtrování, editace
záznamů může způsobit, že záznam přestává splňovat podmínku filtru. Tento
záznam tedy již není dále získáván z datové množiny. Pokud toto nastane,
pak současným záznamem se stane další záznam splňující podmínku filtru.
Zápis
obsluhy události OnFilterRecord
Filtr pro datovou množinu může být také obsluha události
OnFilterRecord
generovaná
pro každý záznam získaný z datové množiny. Jádrem každé obsluhy filtru
je test, který určuje zda záznam bude zařazen mezi ty, které jsou viditelné
aplikací.
K indikaci, zda záznam splňuje podmínku filtru, naše
obsluha filtru musí nastavit parametr Accept na true k akceptování
záznamu, nebo na false k odmítnutí záznamu. Např. následující filtr
propouští pouze ty záznamy, kde položka State má hodnotu "CA".
void __fastcall TForm1::Table1FilterRecord(TDataSet
*DataSet; bool &Accept)
{
Accept = DataSet->FieldByName["State"]->AsString
== "CA";
}
Když filtrování je povoleno, pak událost OnFilterRecord
je generována pro každý získaný záznam. Obsluha události testuje každý
záznam a pouze ty, které splňují podmínku filtru jsou propouštěny. Protože
událost OnFilterRecord je generována pro každý záznam v datové množině,
musíme se snažit, aby kód obsluhy byl co nejkratší aby nebyla snížena výkonnost
aplikace.
Můžeme kódovat několik obsluh událostí filtrů a přepínat
se mezi nimi za běhu. K přepnutí na jinou obsluhu události za běhu, přiřadíme
novou obsluhu události vlastnosti OnFilterRecord datové množiny.
Např. následující příkaz přepne OnFilterRecord na obsluhu události
nazvanou
NewYorkFilter:
DataSet1->OnFilterRecord = NewYorkFilter;
Refresh;
Nastavování
voleb filtru
Vlastnost FilterOptions umožňuje specifikovat
zda se bude provádět úplné porovnávání řetězců a zda se bude rozlišovat
při porovnávání velikost písmen. FilterOptions je množina, která
může být prázdná (implicitně) nebo může obsahovat jednu nebo obě z následujících
hodnot:
| Hodnota |
Význam |
| foCaseInsensitive |
Při porovnávání řetězců je ignorována velikost písmen. |
| foPartialCompare |
Částečné porovnávání řetězců (řetězec končící hvězdičkou). |
Např. následující příkaz nastavuje filtr, který ignoruje
velikost písmen při porovnávání hodnot v položce State:
TFilterOptions FilterOptions;
FilterOptions.Clear();
FilterOptions << foCaseInsensitive;
Table1->FilterOptions = FilterOptions;
Table1->Filter = "State = 'CA'";
Procházení záznamy
ve filtrované datové množině
Jsou čtyři metody datových množin, které umožňují procházet
záznamy ve filtrované datové množině. Tyto metody jsou popsány v následující
tabulce.
| Metoda |
Činnost |
| FindFirst |
Přesun na první záznam v datové množině, který splňuje
zadaná filtrovací kritéria. Hledání vždy začíná prvním záznamem v nefiltrované
datové množině. |
| FindLast |
Přesun na poslední záznam v datové množině, který splňuje
zadaná filtrovací kritéria. |
| FindNext |
Přesun na následující záznam v datové množině, který
splňuje zadaná filtrovací kritéria. |
| FindPrior |
Přesun na předchozí záznam v datové množině, který splňuje
zadaná filtrovací kritéria. |
Např. následující příkaz nalezne první vyhovující záznam
v datové množině:
DataSet1->FindFirst();
Pokud máme nastavenu vlastnost Filter nebo vytvořenou
obsluhu události OnFilterRecord pro naši datovou množinu, pak tyto
metody přemístí kurzor na specifikovaný záznam a to bez ohledu na to, zda
filtrování je povoleno. Když voláme tyto metody a filtrování není povoleno,
pak filtrování je dočasně povoleno, kurzor umístěn na odpovídající záznam
a filtrování je zakázáno.
Poznámka: Jestliže vlastnost Filter
není nastavena a není vytvořena obsluha události OnFilterRecord,
pak tyto metody pracují stejně jako metody
First,
Last, Next
a Prior.
Všechny tyto metody umístí kurzor na vyhovující záznam
(pokud existuje) a vracejí true. Pokud vyhovující záznam neexistuje,
pak pozice kurzoru se nemění a metoda vrací false. Např. pokud kurzor
je na posledním vyhovujícím záznamu v datové množině a voláme FindNext,
pak metoda vrací false a současný záznam se nemění.
Modifikování dat
Můžeme používat následující metody datové množiny pro vkládání,
aktualizaci a rušení dat:
| Metoda |
Popis |
| Edit |
Uvádí datovou množinu do stavu dsEdit, pokud již
není ve stavu
dsEdit nebo dsInsert. |
| Append |
Zapisuje nezapsaná data, přesouvá kurzor na konec datové
množiny a převádí datovou množinu do stavu dsInsert. |
| Insert |
Zapisuje nezapsaná data a převádí datovou množinu do
stavu dsInsert. |
| Post |
Pokusí se zapsat nový nebo změněný záznam do databáze.
V případě úspěchu vrací datovou množinu do stavu dsBrowse, jinak
se stav nemění. |
| Cancel |
Ukončuje současnou operaci a vrací datovou množinu do
stavu dsBrowse. |
| Delete |
Ruší současný záznam a převádí datovou množinu do stavu
dsBrowse. |
Tyto metody jsou podrobněji popsány v následujících bodech:
Editace záznamů
Aby aplikace mohla modifikovat záznamy, musí být datová množina
ve stavu
dsEdit. V našem kódu můžeme použít metodu Edit k
uvedení datové množiny do stavu dsEdit, pokud vlastnost CanModify
datové množiny je true. CanModify je true, pokud k
tabulce spojené s datovou množinou máme čtecí a zápisová privilegia. Jak
jsme se již dozvěděli, datová množina při splnění jistých podmínek může
do stavu dsEdit přejít automaticky.
Po uvedení datové množiny do stavu dsEdit uživatel
může modifikovat hodnoty položek současného záznamu, které jsou zobrazeny
v datových ovladačích na formuláři. Datové ovladače pro které je automaticky
povolená editace, volají Post, když uživatel provede nějakou akci
měnící současný záznam (přesun na jiný záznam). Pokud náš formulář obsahuje
navigační komponentu, pak uživatel může zrušit provedené změny stisknutím
tlačítka Cancel navigátora. Tím přejde datová množina do stavu dsBrowse.
V kódu musíme zapsat nebo zrušit provedené změny voláním
příslušných metod. Změny zapisujeme voláním Post a rušíme je voláním
Cancel.
Edit
a Post jsou často používány společně. Např.
Table1->Edit();
Table1->FieldValues["CustNo"] = 1234;
Table1->Post();
V předchozím příkladě, první řádek kódu uvádí datovou
množinu do stavu
dsEdit. Další řádek kódu přiřazuje číslo 1234 položce
CustNo
současného záznamu. Poslední řádek zapisuje (odešle) modifikovaný záznam
do databáze.
Poznámka: Pokud vlastnost CachedUpdates
datové množiny je
true, pak odesílané modifikace jsou zapsány do
dočasné vyrovnávací paměti. K jejich zápisu do databáze voláme metodu ApplyUpdates
datové množiny.
Přidávání nových záznamů
Dříve než aplikace může k datové množině přidat další záznam,
musíme ji uvést do stavu dsInsert. Pro uvedení datové množiny do
stavu dsInsert voláme v kódu metodu Insert nebo Append,
pokud vlastnost
CanModify datové množiny je nastavena na true.
CanModify
je true, pokud k databázi spojené s datovou množinou máme čtecí
a zápisová privilegia. Datová množina při splnění určitých podmínek může
být do stavu dsInsert převedena automaticky.
Po uvedení datové množiny do stavu dsInsert, uživatel
nebo aplikace může zadávat hodnoty do položek nového záznamu. Mimo místa
uložení není rozdíl mezi metodami Insert a Append. Insert
používáme pro vložení nového řádku před současný záznam a Append
pro vložení nového řádku za poslední záznam datové množiny.
Datové ovladače, pro které je povoleno vkládání, automaticky
volají
Post, když uživatel provede nějakou akci, která mění současný
záznam (přesun na jiný záznam). Jinak musíme volat Post ve svém
kódu. Post zapisuje nový záznam do databáze nebo při CachedUpdates
nastaveným na true, do dočasné vyrovnávací paměti (pro zápis do
databáze je nutno ještě volat ApplyUpdates).
Insert otevírá nový prázdný záznam před současným
záznamem a tento prázdný záznam se stává současným záznamem a tedy hodnoty
položek tohoto záznamu mohou být zadávány uživatelem nebo kódem naší aplikace.
Když aplikace volá Post (nebo ApplyUpdates
při povolených odložených aktualizacích), nově vkládaný záznam je zapsán
do databáze jedním z těchto způsobů:
-
Pro indexované tabulky Paradoxu nebo dBASE, záznam je vložen
do datové množiny na základě jejího indexu.
-
Pro neindexované tabulky, záznam je vložen do datové množiny
na její současnou pozici.
-
Pro SQL databáze, fyzické umístění vkládaného záznamu je
implementačně závislé. Pokud tabulka je indexována, pak index je aktualizován
informacemi nového záznamu.
Append otevírá nový prázdný záznam na konci datové
množiny. Jinak je činnost stejná jako při Insert (při zápisu do
neindexované tabulky je záznam vložen na konec datové množiny).
Rušení záznamů
Aby aplikace mohla zrušit záznam, musí být datová množina
aktivní. Delete ruší aktivní záznam v datové množině a převádí ji
do stavu dsBrowse. Záznam, který následuje za zrušeným záznamem
se stává současným záznamem. Pokud jsou povoleny odložené aktualizace,
pak zrušený záznam je pouze odstraněn z dočasné vyrovnávací paměti, dokud
nevoláme ApplyUpdates.
Pokud na svém formuláři používáme navigační komponentu,
pak uživatel může zrušit současný záznam stisknutím tlačítka Delete
navigátora. V kódu musíme explicitně volat k odstranění současného záznamu
metodu Delete.
Odesílání dat do databáze
Metoda Post centralizuje v aplikacích C++ Builderu
interakce s databázovou tabulkou. Post zapisuje změny současného
záznamu do databáze, ale chování se liší v závislosti na stavu datové množiny:
-
Ve stavu dsEdit, zapisuje modifikovaný záznam do databáze
(nebo vyrovnávací paměti při povolené odložené aktualizaci).
-
Ve stavu dsInsert, zapisuje nový záznam do databáze
(nebo do vyrovnávací paměti při povolené odložené aktualizaci).
-
Ve stavu dsSetKey, vrací datovou množinu do stavu
dsBrowse.
Odeslání může být prováděno explicitně nebo implicitně jako
část jiné procedury. Když aplikace přesouvá současný záznam, pak Post
je voláno implicitně. Volání metod First, Next, Prior
a Last provádí
Post, pokud datová množina je ve stavu dsEdit
nebo dsInsert. Metody
Append a Insert také implicitně
odesílají všechna nevyřízená data.
Poznámka: Metoda Close nevolá Post
implicitně. Použijeme obsluhu události BeforeClose k odeslání všech
nevyřízených aktualizací.
Zrušení změn
Aplikace může zrušit změny provedené na současném záznamu,
pokud ještě nebyly zapsány pomocí Post. Např. pokud datová množina
je ve stavu
dsEdit a uživatel změnil data jedné nebo více položek,
pak aplikace se může vrátit k původním hodnotám záznamu voláním metody
Cancel
datové množiny. Volání Cancel vždy vrací datovou množinu do stavu
dsBrowse.
Pokud na formuláři máme umístěnu navigační komponentu, pak můžeme pro zrušení
změn připojené datové množiny stisknout tlačítko
Cancel této komponenty.
Modifikace celých záznamů
Všechny datové ovladače na formuláři mimo mřížky a navigační
komponenty poskytují přístup k jednotlivým položkám v záznamu. V kódu ale
můžeme používat následující metody, které pracují s celými záznamy a to
za předpokladu, že struktura databázových tabulek připojené datové množiny
je stabilní a nemění se.
| Metoda |
Popis |
| AppendRecord([pole hodnot]) |
Předává záznam se specifikovanými hodnotami sloupců na
konec tabulky. Provádí implicitně Post. |
| InsertRecord([pole hodnot]) |
Vkládá specifikované hodnoty jako záznam před současnou
pozici kurzoru tabulky. Provádí implicitně Post. |
| SetFields([pole hodnot]) |
Nastavuje hodnoty specifikovaných položek (odpovídá přiřazení
hodnot do TFields). Aplikace musí provést explicitně Post. |
Tyto metody přebírají pole hodnot TVarRec jako
parametr, kde každá hodnota odpovídá sloupci v připojené datové množině.
K vyplnění těchto polí použijeme makro ARRAYOFCONST. Hodnoty mohou být
konstanty, proměnné nebo NULL. Pokud počet hodnot v parametru je menší
než počet sloupců v datové množině, pak zbývajícím sloupcům je přiřazeno
NULL.
Pro neindexované datové množiny, AppendRecord
přidává záznam na konec datové množiny a InsertRecord vkládá záznam
před současný záznam. Pro indexované tabulky, obě metody umisťují záznam
do tabulky na základě indexu. V obou případech metody přemístí kurzor na
vložený záznam.
SetFields přiřazuje hodnoty specifikované v poli
parametrů do položek v datové množině. Pro použití SetFields, aplikace
musí nejprve volat Edit k uvedení datové množiny do stavu dsEdit.
Aplikování změn na současný záznam pak provedeme Post.
Jestliže použijeme SetFields k modifikaci některých,
ale ne všech položek v existujícím záznamu, pak můžeme předat hodnotu NULL
pro položky, které nechceme měnit. Pokud nepředáme dostatek hodnot pro
všechny položky v záznamu, pak SetFields přiřadí hodnoty NULL pro
zbývající položky (tyto NULL přepíší existující hodnoty v těchto položkách).
Např. předpokládejme, že v databázi je tabulka COUNTRY
se sloupci Name,
Capital,
Continent, Area a
Population.
Pokud komponenta TTable nazvaná CountryTable je spojená s
touto tabulkou, pak následující příkaz vloží záznam do tabulky COUNTRY:
CountryTable->InsertRecord(ARRAYOFCONST(("Japan",
"Tokyo", "Asia")));
Tento příkaz neobsahuje hodnoty pro sloupce Area
a Population a jsou tedy do nich vloženy hodnoty NULL. Tabulka je
indexována podle sloupce
Name a příkaz tedy vloží záznam na místo
na základě abecedního umístění "Japan". K aktualizaci záznamu, aplikace
může použít tento kód:
TLocateOptions SearchOptions;
SearchOptions.Clear();
SearchOptions << loCaseInsensitive;
if (CountryTable->Locate("Name", "Japan",
SearchOptions))
{
CountryTable->Edit();
CountryTable->SetFields(ARRAYOFCONST(
((void *)NULL, (void
*)NULL, (void *)NULL, 344567, 164700000)));
CountryTable->Post();
}
Tento kód přiřazuje hodnoty položek Area a Population
a potom je odesílá do databáze. Tři ukazatelé na NULL drží místo pro první
tři sloupce k zabránění změně jejího obsahu (musíme provést přetypování
na void *).
Varování: Pokud použijeme NULL bez přetypování,
pak položku nastavíme na prázdnou hodnotu.
Používání událostí datových
množin
Datové množiny mají několik událostí, které umožňují aplikaci
provádět kontroly, výpočty součtů a další úlohy. Tyto události jsou uvedeny
v následující tabulce:
| Událost |
Popis |
| BeforeOpen, AfterOpen |
Je generována před/po otevření datové množiny. |
| BeforeClose, AfterClose |
Je generována před/po uzavření datové množiny. |
| BeforeInsert, AfterInsert |
Je generována před/po uvedení datové množiny do stavu
dsInsert. |
| BeforeEdit, AfterEdit |
Je generována před/po uvedení datové množiny do stavu
dsEdit. |
| BeforePost, AfterPost |
Je generována před/po odeslání změn. |
| BeforeCancel, AfterCancel |
Je generována před/po zrušení provedených změn. |
| BeforeDelete, AfterDelete |
Je generována před/po zrušení záznamu. |
| OnNewRecord |
Je generována při vytvoření nového záznamu; používá se
k nastavení implicitních hodnot. |
| OnCalcFields |
Je generována, když počitatelné položky jsou počítány. |
Pro zrušení provádění metod, jako je např. Open
nebo Insert, voláme funkci Abort v některé metodě Before...
(BeforeOpen,
BeforeInsert apod.). Např. následující kód vyžaduje
potvrzení uživatele před zrušením záznamu.
void __fastcall TForm1::TableBeforeDelete
(TDataSet *Dataset)
{
if (MessageBox(0, "Delete This Record?",
"CONFIRM", MB_YESNO) != IDYES)
Abort();
}
Použití OnCalcFields
Událost OnCalcFields je používána k nastavování hodnot
počitatelných položek. Vlastnost AutoCalcFields určuje zda je generována
událost
OnCalcFields. Jestliže hodnota této vlastnosti je true,
pak
OnCalcFields je generována když:
-
Datová množina je otevřena.
-
Přesuneme zaostření z jedné datové komponenty na jinou nebo
z jednoho sloupce na jiný v datovém ovladači mřížky a při modifikaci současného
záznamu.
-
Získání záznamu z databáze.
OnCalcFields je vždy generována při změně hodnoty
některé nepočitatelné položky a to bez ohledu na nastavení AutoCalcFields.
Varování: Jelikož OnCalcFields je volána
velmi často, je vhodné, aby obsluha této události byla krátká. Pokud AutoCalcFields
je true, pak OnCalcFields by neměla provádět akce modifikující
datovou množinu neboť to může vést k rekurzi (pokud OnCalcFields
volá Post, pak je generována
OnCalcFields). Když AutoCalcFields
je false, pak OnCalcFields je generována pouze při volání
Post.
Při provádění OnCalcFields je datová množina ve
stavu dsCalcFields a nemohou být tedy měněny hodnoty jiných než
počitatelných položek. Po dokončení OnCalcFields se datová množina
vrátí do stavu dsBrowse.
-
Další aplikace, kterou vytvoříme, bude zobrazovat informace o našich podmořských
přátelích a umožní ukládat tyto informace do textového souboru. Aplikace
bude používat již vytvořený databázový soubor BIOLIFE.DB. Ukážeme si v
ní použití komponent TDBGrid, TDBText, TDBImage, TDataSource,
TTable
a TDBMemo, procházení daty pomocí mřížky, extrakci dat z datového
ovladače a zápis do textového souboru.
Začneme vývoj nové aplikace. Na formulář umístíme komponentu panel,
jejíž výšku nastavíme asi 72 bobů a zarovnáme ji se spodním okrajem formuláře
(Align nastavíme na alBottom). Na formulář přidáme další
panel, který tentokrát bude zabírat levou polovinu zbývající části formuláře.
Do spodní části tohoto panelu přidáme komponentu TDBText (použijeme
červené písmo, tučné a kurzívou velikosti 14) a na jeho zbývající plochu
komponentu DBImage. Na zbývající plochu formuláře umístíme komponentu
TDBMemo.
Data z databáze budeme získávat komponentou TTable. Umístíme ji
na formulář a nastavíme u ní vlastnost DatabaseName na BCDEMOS,
vlastnost TableName na BIOLIFE a vlastnost
Active
na true. Dále je nutno na formulář umístit komponentu
TDataSource
a nastavíme u ní vlastnost DataSet na Table1. Na panel umístěný
u spodního okraje formuláře na pravém okraji nad sebe dvě tlačítka BitBtn.
Spodní bude mít nastavenu vlastnost Kind na bkClose (bude
sloužit k ukončení aplikace) a horní bude mít tuto vlastnost nastavenu
na bkCustom (bude sloužit k zápisu dat z ovladače do souboru; jeho
text změníme na Save a vložíme na něj vhodný obrázek). Zbytek plochy
spodního panelu zaplníme komponentou TDBGrid (její výsku nastavíme
tak, aby mimo hlavičky zde byl zobrazen pouze jeden řádek).
Vlastnosti DataSource u komponent TDBGrid, TDBText,
TDBImage
a TDBMemo nastavíme na DataSource1 a vlastnosti
DataField
u TDBText na Common_Name, u TDBImage na Graphic
a u TDBMemo na Notes. Nyní již aplikaci můžeme přeložit a
spustit. Rolováním mřížky procházíme záznamy tabulky. Mřížka obsahuje zbytečné
sloupce. Později si ukážeme jak je nezobrazovat a jak umožnit definovat
způsob zobrazení.
-
Zatím jsme se nezabývali ukládáním dat z ovladače do souboru. Na formulář
umístíme komponentu TSaveDialog a nastavíme u ní vlastnosti DefaultExt
na .txt, FileName na Fish.txt a Filter na Textový
soubor (*.txt). Obsluha stisknutí tlačítka Save bude tvořena
příkazy:
FILE *outfile;
char buff[100];
sprintf(buff, "Save Info For: %s", DBText1->Field->AsString.c_str());
SaveDialog1->Title = buff;
if (SaveDialog1->Execute()){
outfile = fopen(SaveDialog1->FileName.c_str(),
"wt");
if (outfile) {
fprintf(outfile, "Facts
on the %s\n\n",
(LPSTR)DBText1->Field->AsString.c_str());
for (int i=0; i < DBGrid1->FieldCount;
i++)
fprintf(outfile,
"%s: %s\n",
(LPSTR)DBGrid1->Fields[i]->FieldName.c_str(),
(LPSTR)DBGrid1->Fields[i]->AsString.c_str());
fprintf(outfile, "\n%s\n",
(LPSTR)DBMemo1->Text.c_str());
}
fclose(outfile);
}
Tato obsluha zapíše do textového souboru informace o současné rybě.
Podívejte se, jak se tyto informace získávají a zapisují. Tím je vývoj
aplikace ukončen. Další příklady budou uvedeny v následující kapitole.
   |
6. Seznámení s datovými množinami
|