Databázové aplikace umožňují uživateli pracovat s informacemi
které jsou uloženy v databázích. Databáze poskytuje informacím strukturu
a umožňuje jejich sdílení mezi různými aplikacemi. C++ Builder poskytuje
podporu pro relační databázové aplikace. Relační databáze organizují informace
do tabulek, které obsahují řádky (záznamy) a sloupce (položky). S těmito
tabulkami můžeme manipulovat jednoduchými operacemi známými jako relační
počet.
Když navrhujeme databázové aplikace, pak musíme vědět
jak jsou data strukturována. Na základě této struktury, můžeme navrhnout
uživatelské rozhraní k zobrazení dat pro uživatele a k umožnění uživateli
zadávat nové informace nebo modifikovat existující data.
Úvod do návrhu databázových aplikací bude uveden v těchto
bodech:
Používání databází
Komponenty na stránce Data Access Palety komponent
umožňují naší aplikaci číst z a zapisovat do databáze. Tyto komponenty
používají Borland Database Engine (BDE) pro zpřístupnění databázových informací,
které dělá dostupnými v datových ovladačích v našem uživatelském rozhraní.
V závislosti na naši verzi C++ Builderu, BDE obsahuje
ovladače pro různé typy databází. I když všechny typy databází obsahují
tabulky s uloženými informacemi, různé typy podporují další služby jako:
Můžeme se připojit k různým typům databází, a to v závislosti
na instalovaných ovladačích v BDE. Všechny verze C++ Builderu zahrnují
ovladače pro lokální databáze. Dále některé verze používají ovladače instalované
s SQL Links pro komunikaci se vzdálenými databázovými servery. Volba typu
databáze závisí na několika faktorech. Naše data mohou být také uložena
v již existujících databázích. Pokud vytváříme tabulky pro informace používané
naší aplikací, pak je vhodné zodpovědět si následující otázky:
-
Kolik dat budou tabulky obsahovat?
-
Kolik uživatelů bude tyto tabulky sdílet?
-
Jaký typ výkonnosti (rychlost) požadujeme od databáze?
Lokální databáze sídlí na našem lokálním disku nebo
lokální oblasti sítě. Má příslušné API pro zpřístupňování dat. Často jsou
určeny pro jediný systém. Když jsou sdíleny několika uživateli, pak používají
uzamykací mechanismus založený na souborech. Z tohoto důvodu tyto databáze
také nazýváme databáze založené na souborech.
Lokální databáze mohou být rychlejší než vzdálené databázové
servery, protože často sídlí na stejném systému jako databázové aplikace.
Protože jsou založeny na souborech, lokální databáze jsou více omezeny
než vzdálené databázové servery v množství dat, která mohou uložit. Tedy
při rozhodování, zda použít lokální databázi, musíme odhadnout kolik dat
tabulka bude obsahovat.
Aplikace, které používají lokální databáze se nazývají
jedno
vrstvové aplikace, protože aplikace a databáze sdílí jeden souborový
systém. Příklady lokálních databází jsou Paradox, dBASE, FoxPro a Access.
Vzdálené databázové servery obvykle sídlí na vzdáleném
počítači. Používají Strucrured Query Language (SQL) pro umožnění klientům
přistupovat k datům. Z tohoto důvodu se také nazývají SQL servery.
Jiné jméno je Remote Database Management System (RDBMS). Mimo společných
příkazů, tvořících základ SQL, některé vzdálené databázové servery podporují
unikátní "dialekty" SQL.
Vzdálené databázové servery jsou určeny pro současný
přístup několika uživatelů. Místo uzamykacího systému založeného na souborech,
který je využíván lokálními databázemi, poskytují rafinovanější víceuživatelskou
podporu, založenou na transakcích.
Vzdálené databázové servery udržují více dat než lokální
databáze. Někdy data ze vzdálených databázových serverů nesídlí na jednom
počítači, ale jsou distribuované na několika serverech.
Aplikace, které používají vzdálené databázové servery
se také nazývají dvou vrstvové aplikace nebo více vrstvové aplikace,
protože aplikace a databáze operují na nezávislých systémech.
Příklady SQL serveru jsou Interbase, Oracle, Sybase,
Informix, Microsoft SQL server a DB2.
Databázová bezpečnost
Databáze často obsahují citlivé informace. Různé databáze
poskytují bezpečnostní schéma pro ochranu těchto informací. Některé databáze,
jako je Paradox nebo dBASE, pouze poskytují zabezpečení na úrovni tabulek
nebo položek. Když se uživatel pokusí přistupovat ke chráněné tabulce,
pak musí zadat heslo. Po autorizaci uživatele, pak uživatel vidí pouze
ty položky (sloupce), ke kterým má oprávnění.
Většina SQL serverů vyžaduje k použití databázového serveru
jméno uživatele a heslo. Po přihlášení uživatele k databázi, pak jméno
uživatele určuje, které tabulky může uživatel používat a jak je může používat.
Při vývoji databázové aplikace, musíme zvážit jaký typ
autorizace je požadován naším databázovým serverem. Pokud nechceme aby
uživatel musel zapisovat heslo, pak musíme použít databázi, která to nevyžaduje
nebo musíme předat jméno uživatele a heslo programově. Při programovém
předávání hesla je ale omezena bezpečnost dat.
Pokud požadujeme, aby uživatel musel zadávat heslo, pak
se musíme zamyslet, kdy je heslo požadováno. Pokud používáme lokální databáze
a chystáme se přejít na SQL server, pak se můžeme dotazovat na heslo před
přístupem k tabulce i když jej zatím nebudeme používat.
Pokud naše aplikace vyžaduje více hesel protože se musíme
přihlašovat k několikrát chráněnému systému nebo databázi, pak můžeme uživateli
poskytnout jedno hlavní heslo, které je použito pro přístup k tabulce chráněné
heslem chráněným systémem. Aplikace pak předává heslo programově, bez nutnosti
zadávání několika hesel uživatelem.
Ve více vrstvových aplikacích můžeme chtít použít jiný
bezpečnostní model. Můžeme použít MTS k řízení přístupu ke střední vrstvě
a střední vrstva pak může kompletně zpracovávat přihlašování k databázovým
serverům.
Transakce
Transakce je skupina akcí, které musí být všechny provedeny
úspěšně na jedné nebo několika tabulkách v databázi než se stanou trvalými.
Pokud některá akce ze skupiny je neúspěšná, pak všechny akce tvořící tuto
skupinu jsou zrušeny.
Transakce také chrání před důsledky hardwarových chyb,
které nastanou v průběhu databázového příkazu nebo množiny příkazů. Jsou
také základem řízení víceuživatelského souběžného přístupu na SQL serverech.
Když každý uživatel pracuje s databází pouze prostřednictvím transakcí,
pak příkazy jednoho uživatele nemohou narušit transakce jiného uživatele.
SQL server sleduje přicházející transakce a zajistí jejich úplné provedení
nebo úplné zrušení.
I když podpora transakcí nepatří do většiny lokálních
databází, ovladače BDE poskytují omezenou podporu transakcí pro tyto databáze.
Pro SQL servery a ODBC databáze, podpora transakcí je poskytnuta samotnou
databází. Ve více vrstvových aplikacích, můžeme vytvářet transakce, které
obsahují i jiné akce než pouze databázové operace nebo které se týkají
více databází.
Datový slovník
Bez ohledu na typ použité databáze, naše aplikace má přístup
k Datovému slovníku. Datový slovník poskytuje přizpůsobitelnou ukládací
oblast, nezávislou na naši aplikaci, kde můžeme vytvářet množiny rozšířených
atributů položek, které popisují obsah a vzhled dat.
Např. pokud často vyvíjíme finanční aplikace, můžeme
vytvořit řadu množin specializovaných atributů položek popisujících různé
zobrazovací formáty pro finanční položky. Když při návrhu vytváříme datové
množiny pro naši aplikaci, pak místo použití Inspektora objektů k nastavení
finančních položek v každé datové množině, můžeme přiřadit tyto položky
k množině rozšířených atributů položek v Datovém slovníku. Používání Datového
slovníku také zajišťuje konzistentnost vzhledu dat a to i různých vytvářených
aplikacích.
V prostředí klient/server, Datový slovník může být umístěn
na vzdáleném serveru pro sdílení informací. S vytvářením a používáním Datového
slovníku se seznámíme později.
Programovací rozhraní k Datovému slovníku je dostupné
v jednotce drintf (umístěné v adresáři lib). Rozhraní nabízí
následující metody:
| Metoda |
Použití |
| DictionaryActive |
Indikuje zda Datový slovník je aktivní. |
| DictionaryDeactivate |
Deaktivuje Datový slovník. |
| IsNullID |
Indikuje zda dané ID je NULL. |
| FindDatabaseID |
Vrací ID pro databázi danou její přezdívkou. |
| FindTableID |
Vrací ID pro tabulku ve specifikované databázi. |
| FindFieldID |
Vrací ID pro položku ve specifikované databázi. |
| FindAttrID |
Vrací ID pro pojmenovanou množinu atributů. |
| GetAttrName |
Vrací jméno množiny atributů dané jejím ID. |
| GetAttrNames |
Provádí zpětné volání pro každou množinu atributů ve
slovníku. |
| GetAttrID |
Vrací ID množiny atributů pro specifikovanou položku. |
| NewAttr |
Vytváří novou množinu atributů z položkové komponenty. |
| UpdateAttr |
Aktualizuje množinu atributů k nalezení vlastností položky. |
| CreateField |
Vytváří položkovou komponentu založenou na uložených
atributech. |
| UpdateField |
Mění vlastnosti položek na shodu se specifikovanou množinou
atributů. |
| AssociateAttr |
Přiřazuje množinu atributů s danou ID položky. |
| UnassociateAttr |
Odstraňuje množinu atributů přiřazenou pro ID položky. |
| GetControlClass |
Vrací řídící třídu pro specifikované ID atributu. |
| QualifyTableName |
Vrací plně kvalifikované jméno tabulky (kvalifikované
jménem uživatele). |
| QualifyTableNameByName |
Vrací plně kvalifikované jméno tabulky (kvalifikované
jménem uživatele). |
| HasConstraints |
Indikuje, zda datová množina má omezení ve slovníku. |
| UpdateConstraints |
Aktualizuje importovaná omezení datové množiny. |
| UpdateDataset |
Aktualizuje datovou množinu na současné nastavení a omezení
ve slovníku. |
Referenční
integrita, uložené procedury a spouštěče
Všechny relační databáze mají jisté služby, které obecně
umožňují aplikacím ukládat a manipulovat s daty. Dále databáze nabízejí
další služby specifické pro databázi, které jsou užitečné pro zajištění
vztahů mezi tabulkami v databázi. To zahrnuje:
-
Referenční integrita - poskytuje mechanismus k chránění
vztahu Master-detail. Když se uživatel pokusí zrušit položku v tabulce
Master, pak pravidla referenční integrity chrání záznamy Detail.
-
Uložené procedury - jsou množiny příkazů SQL, které
jsou pojmenované a uložené na SQL serveru. Uložené procedury obvykle provádějí
obecné databázové úlohy na serveru a vracejí množinu záznamů.
-
Spouštěče - jsou množiny příkazů SQL, které jsou automaticky
prováděny v reakci na jistý příkaz.
Vývojové prostředí
Databázové služby a nástroje C++ Builderu slouží k snadnému
návrhu, implementaci, vývoji a udržování databázových aplikací v různých
výpočetních prostředích. Některé databázové služby a nástroje, jako je
Průzkumník SQL (SQL Explorer), Monitor SQL, Vytvářeč SQL, Klientské datové
množiny, Moduly vzdálených dat a Poskytovací komponenty jsou specifické
pro verzi Client/Server C++ Builderu (Průzkumník databáze nahrazuje ve
verzi Professional Průzkumníka SQL). Ostatní nástroje, jako jsou standardní
databázové komponenty, BDE (Borland Database Engine) a samostatný Database
desktop (DBD) jsou poskytnuty ve všech verzích C++ Builderu.
Obecně verze Client/Server poskytuje vysokou integraci
nástrojů potřebných pro návrh, testování a vytváření dvouvrstvových a vícevrstvových
aplikací, které pracují s databázemi SQL na vzdálených serverech a databázích
dBASE, Paradox, MS Access a FoxPro (a to lokálně nebo síťově). Pomocí ovladačů
ODBC můžeme také přistupovat k dalším lokálním nebo vzdáleným databázím.
Verze Professional umožňuje budovat a testovat klientské
aplikace pro databáze dBASE, Paradox, Access a FoxPro a to opět lokálně
i síťově a pomocí ODBC lze přistupovat k dalším lokálním nebo vzdáleným
databázím.
Průzkumník SQL a Průzkumník databáze
Ve verzi Client/Server C++ Builderu, můžeme prohlížet
databáze a jejich tabulky s daty pomocí Průzkumníka SQL z IDE. Ve verzi
Professional C++ Builderu, můžeme použít Průzkumníka databáze. Obě verze
průzkumníka umožňují:
-
Prohlížet existující databázové tabulky a struktury. Pomocí
Průzkumníka SQL můžeme prohlížet a dotazovat se vzdálených SQL databází.
-
Vytvářet objekty SQL na vzdálených databázových serverech,
jako jsou uložené procedury (Průzkumníkem SQL). Můžeme také zobrazovat
textové objekty SQL na serveru.
-
V Průzkumníku SQL spouštět skript SQL.
-
Zaplňovat tabulky daty.
-
Vytvářet množinu rozšířených atributů položek v Datovém slovníku
pro pozdější získání a použití. Rozšířené atributy položek popisují jak
hodnoty sloupce jsou formátovány a zobrazeny.
-
Přiřadit rozšířené atributy položek k položkám v naší aplikaci.
-
Vytvářet a spravovat přezdívky BDE používané naší aplikací
pro připojení k databázi.
Více o Průzkumníku SQL a Průzkumníku databáze se dozvíme
později.
Vytvářeč SQL
Ve verzi Client/Server C++ Builderu můžeme používat Vytvářeč
SQL k vizuálnímu vytváření SQL pro dotazy. Vytvářeč SQL může být vyvolán
z místní nabídky komponenty Query. Vytvářeč SQL usnadňuje:
-
Vizuálně specifikovat příkazy SELECT.
-
Vytvářet vnořené výrazy.
-
Používat řetězcové konstanty.
-
Přímý zápis kódu SQL a prohlížení jeho zrcadlení ve vizuální
reprezentaci.
Vytvářečem SQL se více zabývat nebudeme.
Desktop databáze
Desktop databáze (DBD) můžeme použít k prohlížení a modifikaci
existujících tabulek Paradoxu a dBASE nebo k jejich vytváření a zaplňování,
vytváření indexů, definování referenční integrity a vytváření ověřovacích
pravidel pro ně. Můžeme také prohlížet a vytvářet přezdívky BDE.
DBD je samostatná utilita, která se spouští mimo IDE.
Více informací bude uvedeno v příští kapitole.
Datové moduly
Datové moduly značně zjednodušují přístup k datům v našich
aplikacích. Datové moduly nabízejí centralizované návrhové kontejnery pro
všechny naše komponenty datového přístupu, které umožňují modularizovat
náš kód a oddělovat logiku datového přístupu v naši aplikaci od logiky
uživatelského rozhraní na formulářích aplikace.
Po definici našich datových množin a jejich položek v
Datovém modulu, všechny formuláře které používají modul mají konzistentní
přístup k datovým množinám a položkám a to bez nutnosti jejich opětovného
vytváření pro každý formulář. Datové moduly mohou být uloženy v Zásobníku
objektů pro sdílení mezi vývojáři a aplikacemi.
Vzdálené datové moduly umožňují vytvářet Datové moduly
ActiveX, které jsou základem pro vytváření objektů automatizace OLE, které
mohou sloužit jako aplikační servery ve vícevrstvových databázových aplikacích.
Šablony komponent
Šablony komponent umožňují umístit jednu nebo více komponent
na formulář, nastavit jejich vlastnosti, zapsat pro ně obsluhy událostí
a potom uložit tuto skupinu komponent na Paletu komponent pro pozdější
opakované používání. Šablony komponent umožňují rychlé vytvoření uživatelského
rozhraní s implicitním chováním a jejich sdílení mezi aplikacemi.
Zásobník objektů
Zásobník objektů ukládá vazby na datové moduly, formuláře
a projekty pro opakované použití. Když vytváříme novou aplikaci, pak můžeme:
-
Kopírovat existující datové moduly, formuláře nebo projekty,
což zajistí, že naše kopie je úplně nezávislá na zásobníku.
-
Dědit existující datové moduly, formuláře a projekty, což
zajistí, že změny v propojených modulech, formulářích a projektech v zásobníku
se projeví i v naší aplikaci, když ji opětovně přeložíme.
-
Použít existující datové moduly, formuláře a projekty, což
zajistí, že změny které provedeme v modulu, formuláři nebo projektu jsou
dostupné pro použití v ostatních aplikacích.
Zásobník objektů podporuje týmový vývoj. Používá odkazový
mechanismus na Datové moduly, formuláře a projekty, které existují na síťovém
serveru nebo sdíleném počítači. Každý vývojář v naši organizaci může ukládat
objekty na sdílené místo a pak nastavovat odkazy Zásobníku objektů na místo
jejich uložení. Zásobník objektů také můžeme přizpůsobit volbou Tools
| Repository v IDE.
Vytváření vícevrstvových aplikací
Můžeme vytvářet vícevrstvové databázové aplikace a to
pomocí databázových komponent TClientDataSet, TMIDASConnection
(nebo
TRemoteServer) a TProvider. TClientDataSet umožňuje
vytvořit nezávislou datovou množinu databázového modulu přístupu k databázi,
která může získávat data z lokálních datových zdrojů, souborů a vzdálených
databázových serverů.
TClientDataSet můžeme použít k vytváření jednovrstvových
databázových aplikací, které nepoužívají BDE a komponentu TClientDataSet
můžeme použít v klientských aplikacích jako část vícevrstvové databázové
aplikace.
TMIDASConnection umožňuje vytvářet klientské aplikace,
které se připojují ke vzdáleným aplikačním serverům pomocí DCOM, Soketů
Windows nebo OLEEnterprise. Pokud používáme pouze DCOM, můžeme k těmto
účelům také použít TRemoteServer. TProvider umožňuje vytvářet
duální rozhraní mezi klientskou aplikací a aplikačním serverem (kde komponenta
TProvider sídlí) a tak klientská datová množina v klientské aplikaci
může komunikovat prostřednictvím poskytovatele nebo přímo s datovou množinou
na aplikačním serveru.
Architektura databáze
Databázové aplikace jsou budovány z prvků uživatelského rozhraní,
komponent které spravují databázi nebo databáze a komponent které reprezentují
data obsažená v tabulkách v těchto databázích (datových množinách). Architektura
naší databázové aplikace určuje jak tyto prvky používat. Izolováním komponent
databázového přístupu do Datových modulů, můžeme vyvíjet v naší databázové
aplikaci formuláře, které poskytují konzistentní uživatelské rozhraní.
Uložením vazeb na dobře navržené formuláře a Datové moduly do Zásobníku
objektů, dosáhneme toho, že my a ostatní vývojáři mohou budovat na existujících
základech místo začínání od ničeho v každém novém projektu. Sdílení formulářů
a Datových modulů také umožňuje standardizaci databázového přístupu a aplikačního
rozhraní.
Mnoho aspektů architektury naší databázové aplikace závisí
na typu používané databáze, počtu uživatelů, kteří budou sdílet databázové
informace a typu informací se kterými budeme pracovat.
Když zapisujeme aplikace, které používají informace nesdílené
několika uživateli, pak můžeme chtít použít lokální databáze v jednovrstvé
aplikaci. Toto řešení může mít výhodu v rychlosti (protože data jsou uložena
lokálně) a nevyžadují samostatný databázový server a počítačovou síť. Jsme
ale omezeni množstvím dat v tabulkách a počtem uživatelů, které naše aplikace
může podporovat.
Zápisem dvouvrstvé aplikace poskytneme víceuživatelskou
podporu a získáme možnost používat velké vzdálené databáze, které mohou
ukládat značně velké množství informací.
Když databázové informace obsahují komplikované vazby
mezi několika tabulkami nebo když se počet klientů zvětšuje, pak můžeme
chtít používat vícevrstvové aplikace. Vícevrstvové aplikace obsahují střední
vrstvu, která centralizuje logiku ovládání databázových interakcí. To umožňuje
různým klientským aplikacím používat stejná data se zajištěním konzistentní
datové logiky. To také zmenšuje klientské aplikace, protože část zpracování
je přesunuta do střední vrstvy (na jiném počítači). Tyto menší klientské
aplikace se snadněji instalují, konfigurují a udržují, protože neobsahují
připojení k databázím. Vícevrstvové aplikace mohou zvyšovat výkonnost rozložením
úloh zpracování dat na několik systémů.
Seznámením s uživatelským rozhraním
C++ Builder poskytuje řadu datových ovladačů pro vytváření
uživatelského rozhraní ve všech typech databázových aplikací. Datové ovladače
zobrazují data z položek v databázových záznamech a umožňují uživateli
editovat tato data a posílat změny zpět do databáze. Datové ovladače umisťujeme
na formulář a jsou tedy viditelné a přístupné pro uživatele.
Většina těchto ovladačů se podobá vzhledem a funkčností
standardním ovladačům Windows, které umisťujeme na formulář. Např. ovladač
TDBEdit
je datovou verzí standardního ovladače TEdit, který umožňuje prohlížet
a editovat textové řetězce. Další datové ovladače, jako je TDBNavigator
a TDBGrid mají vzhled a funkčnost, která potřebuje databázi. Např.
ovladač navigátora nezobrazuje ani needituje data, ale umožňuje uživateli
procházet záznamy databáze, přejít do editačního nebo vkládacího režimu,
rušit záznamy, odeslat změny do databáze a požadovat nové zobrazení dat.
TDBGrid
může zobrazit některé nebo všechny položky pro několik záznamů najednou
v tabulkovém formátu.
V následující tabulce je uveden přehled vizuálních datových
ovladačů, které jsou na stránce Data Controls Palety komponent:
| Komponenta |
Význam |
| TDBGrid |
Zobrazuje a edituje záznamy datové množiny v tabulkovém
formátu. |
| TDBNavigator |
Procházení záznamy datové množiny; umožňuje stavy Edit
a Insert; odeslání nových nebo modifikovaných záznamů; zrušení editačního
režimu; obnovení zobrazení. |
| TDBText |
Zobrazení položky jako popisu. |
| TDBEdit |
Zobrazení a editace položky v editačním ovladači. |
| TDBMemo |
Zobrazení a editace víceřádkového textu v rolovatelném
víceřádkovém editačním ovladači. |
| TDBImage |
Zobrazení a editace grafického obrázku nebo BLOB dat. |
| TDBListBox |
Zobrazení seznamu voleb pro zadávání do položek. |
| TDBComboBox |
Zobrazení editačního ovladače a rozbalovacího seznamu
voleb pro editaci a zadávání do položky. |
| TDBCheckBox |
Zobrazování a nastavování logické položky ve značce. |
| TDBRadioGroup |
Zobrazování a nastavování vzájemně vylučujících se voleb
pro položku ve skupině voličů. |
| TDBLookupListBox |
Zobrazení seznamu voleb odvozeného od položky v jiné
datové množině pro zadávání do položky. |
| TDBLookupComboBox |
Zobrazení editačního ovladače a rozbalovacího seznamu
voleb odvozeného od položky v jiné datové množině pro editaci a zadávání
do položky. |
| TDBRichEdit |
Zobrazení a editace víceřádkového formátovaného textu
nebo BLOB ve víceřádkovém rolovatelném editačním ovladači. |
| TDBCtrlGrid |
Zobrazování a editace záznamů v tabulkovém formátu, kde
každá buňka v mřížce obsahuje opakující se množinu datových komponent pro
jeden záznam (pouze verze Client/Server a Professional). |
| TDBChart |
Reprezentuje databázové informace v grafickém formátu. |
Datové ovladače získávají data z a zasílají data do komponenty
datového zdroje TDataSource. Komponenta datového zdroje slouží jako
propojení mezi uživatelským rozhraním a komponentou datové množiny reprezentující
databázovou tabulku, dotaz nebo uloženou proceduru. Několik datových ovladačů
na formuláři může sdílet jeden datový zdroj a zobrazení v těchto ovladačích
je synchronizováno s procházením v záznamech (v každém ovladači je zobrazena
hodnota odpovídající položky současného záznamu). Datové zdroje aplikace
obvykle umisťujeme do datového modulu (odděleně od datových ovladačů na
formuláři).
Každá komponenta datového zdroje v aplikaci je spojena
s jednou komponentou datové množiny. Komponenta datové množiny je vždy
odvozena od TDataSet. Pokud vytváříme tradičního dvouvrstvového
klienta, který používá BDE, pak naše aplikace používá komponenty TQuery,
TStoredProc
a TTable, které jsou všechny odvozeny od TDataSet. Při vytváření
vícevrstvové databázové aplikace, klientská část aplikace používá komponentu
TClientDataSet,
která je reprezentací datové množiny nezávislého modulu přístupu k databázi.
Můžeme také odvodit svou vlastní datovou množinu pro spolupráci s databázemi
dalších firem. Bez ohledu na typ komponenty datové množiny, vytváříme vždy
uživatelské rozhraní stejným způsobem. Následující obrázek ukazuje vzájemný
vztah komponent vytvářejících uživatelské rozhraní v naší databázové aplikaci
k datovým množinám, které získávají data a které zasílají aktualizace.
Datové ovladače usnadňují zápis aplikací zabstraktněním
chování databáze a dat uložených v databázi. Bez ohledu na to, zda zapisujeme
jedno, dvou nebo vícevrstvovou aplikace, pak můžeme izolovat její uživatelské
rozhraní od vrstvy databázového přístupu, jak ukazuje následující obrázek.
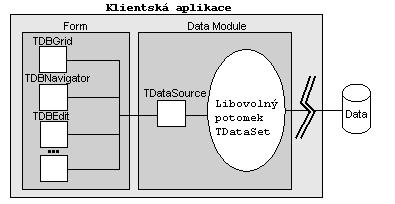 Formulář reprezentuje uživatelské rozhraní a obsahuje datové
ovladače a další prvky uživatelského rozhraní. Datové ovladače v uživatelském
rozhraní jsou připojeny k datovým množinám, které reprezentují informace
z tabulek v databázi. Datový zdroj (TDataSource) spojuje datové
ovladače s těmito datovými množinami. Izolováním datového zdroje a datové
množiny v Datovém modulu, dosáhneme toho, že při změně typu používané databáze
se formulář nezmění. Musí se změnit pouze datové množiny.
Formulář reprezentuje uživatelské rozhraní a obsahuje datové
ovladače a další prvky uživatelského rozhraní. Datové ovladače v uživatelském
rozhraní jsou připojeny k datovým množinám, které reprezentují informace
z tabulek v databázi. Datový zdroj (TDataSource) spojuje datové
ovladače s těmito datovými množinami. Izolováním datového zdroje a datové
množiny v Datovém modulu, dosáhneme toho, že při změně typu používané databáze
se formulář nezmění. Musí se změnit pouze datové množiny.
Když zapisujeme aplikace založené na BDE, pak snadno
přejdeme z jednovrstvé na dvouvrstvou aplikaci. Je nutno změnit pouze několik
vlastností datové množiny a můžeme se připojit místo k lokání databázi
přímo ke vzdálenému SQL serveru. Databázová aplikace založená na souborech
je snadno změněna na klienta ve vícevrstvové aplikaci, protože obě architektury
používají stejné komponenty datových množin. Z tohoto důvodu můžeme zapsat
aplikaci, která pracuje jako souborová aplikace i jako vícevrstvý klient.
Pokud plánujeme změnu použité architektury, pak mimo
izolace uživatelského rozhraní je vhodné izolovat i všechnu logiku, která
může sídlit v budoucnu ve střední vrstvě.
Následující tabulka uvádí přehled všech databázových komponent,
které jsou uvedeny na stránce Data Access Palety komponent.
| Komponenta |
Význam |
| TBatchMove |
Přesouvá data z jedné tabulky do jiné. |
| TClientDataSet |
Zaobaluje datovou množinu, která je nezávislá na BDE,
pro použití v jednovrstvových aplikacích a ve vícevrstvových aplikacích
na klientu. Pouze ve verzi Client/Server. |
| TDatabase |
Zaobaluje připojení klient/server k jedné databázi v
jednom sezení. |
| TDataSource |
Slouží jako propojení mezi ostatními komponentami datového
přístupu a vizuálními datovými komponentami. |
| TProvider |
Poskytuje duální rozhraní povolující ActiveX, které slouží
jako komunikační kanál mezi aplikačním serverem a klientskou aplikací ve
vícevrstvových aplikacích. Pouze ve verzi Client/Server. |
| TQuery |
Reprezentuje datovou množinu, která získává podmnožinu
sloupců a záznamů z jedné nebo více lokálních nebo vzdálených databázových
tabulek na základě dotazu SQL. |
| TMIDASConnection |
Připojuje klientskou aplikaci k aplikačnímu serveru ve
vícevrstvových aplikacích. Pouze ve verzi Client/Server. |
| TRemoteServer |
Připojuje klientskou aplikaci k aplikačnímu serveru ve
vícevrstvových aplikacích používajících pouze DCOM. Pouze ve verzi Client/Server. |
| TSession |
Reprezentuje jedno sezení ve vícevrstvových databázových
aplikacích. Každé sezení může mít více databázových připojení. |
| TStoredProc |
Reprezentuje datovou množinu, která získává jeden nebo
více záznamů z databázové tabulky na základě uložené procedury definované
pro databázový server. |
| TTable |
Reprezentuje datovou množinu, která získává všechny sloupce
a záznamy z databázové tabulky. |
| TUpdateSQL |
Reprezentuje příkazy SQL INSERT, UPDATE a DELETE, které
mohou být použity k aktualizaci výsledkové množiny některých dotazů. |
Mimo těchto přístupových a datových komponent, verze Client/Server
obsahuje na Paletě komponent stránku DecisionCube. Obsahuje šest
komponent, které umožňují provádět analýzu dat.
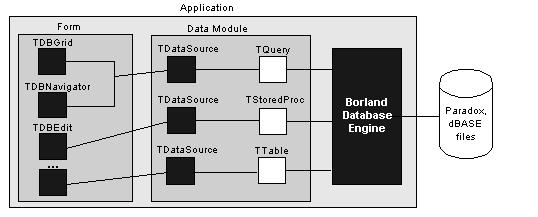
Architektura jednovrstvových BDE aplikací
V modelu jednovrstvové databáze, která používá BDE pro přístup
k Paradoxu a dBASE, aplikace obsahuje uživatelské rozhraní a spolupracující
BDE. C++ Builder má vždy podporu pro tento typ jednovrstvových databázových
aplikací. Následující obrázek ukazuje model architektury pro jednovrstvové
aplikace, které používají BDE:
 Mimo tohoto jednovrstvového modelu C++ Builder podporuje
jednovrstvový model nevyžadující DBE.
Mimo tohoto jednovrstvového modelu C++ Builder podporuje
jednovrstvový model nevyžadující DBE.
Architektura jednovrstvových aplikací
V modelu jednovrstvové databáze, aplikace obsahuje uživatelské
rozhraní. Používá komponentu TClientDataSet k vytvoření nezávislé
datové množiny modulu přístupu k databázi, která čte data z a zapisuje
data do souborů na disku bez požadavků na samostatný modul přístupu k databázi
nebo databázový server. Následující obrázek ukazuje model architektury
pro jednovrstvové aplikace, které používají klientské datové množiny:
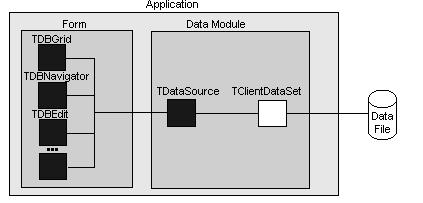 Dvě metody obsažené v TClientDataSet, LoadFromFile
a SaveToFile, umožňují klientské datové množině číst data přímo
ze souboru pro zobrazení a zápis dat z datových ovladačů přímo do souboru.
V tomto smyslu komponenta klientské datové množiny nahrazuje modul přístupu
k databázi. Struktura položek definovaná pro klientskou datovou množinu
určuje jak data jsou zapisována na a čtena z disku.
Dvě metody obsažené v TClientDataSet, LoadFromFile
a SaveToFile, umožňují klientské datové množině číst data přímo
ze souboru pro zobrazení a zápis dat z datových ovladačů přímo do souboru.
V tomto smyslu komponenta klientské datové množiny nahrazuje modul přístupu
k databázi. Struktura položek definovaná pro klientskou datovou množinu
určuje jak data jsou zapisována na a čtena z disku.
TClientDataSet se také používá (v poněkud jiném
významu) v klientské části vícevrstvových databázových aplikacích.
Dvouvrstvové databázové aplikace
V modelu dvouvrstvových databází, klientská aplikace poskytuje
uživatelské rozhraní k datům a spolupracuje přímo s lokálním nebo vzdáleným
databázovým serverem prostřednictvím BDE. Toto ukazuje následující obrázek:
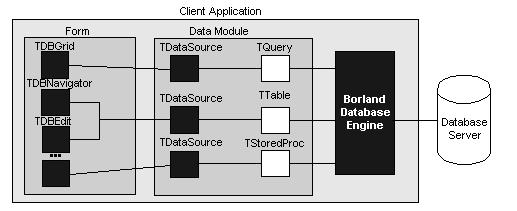 V tomto modelu, všechny aplikace jsou klienty databáze. Klient
získává informace z a zasílá na databázový server. Server může zpracovávat
požadavky od mnoha klientů současně, koordinací přístupu a aktualizací
dat.
V tomto modelu, všechny aplikace jsou klienty databáze. Klient
získává informace z a zasílá na databázový server. Server může zpracovávat
požadavky od mnoha klientů současně, koordinací přístupu a aktualizací
dat.
Dobře navržené dvouvrstvové aplikace snadno zobrazují
a editují data i v případě když aplikace pracuje se složeným datovým modelem.
Vývojář aplikace musí pochopit složení našeho datového modelu a pracuje
s maskou pro případného koncového uživatele naší aplikace.
Pokud máme verzi Professional C++ Builderu, pak investice
do vytváření databázových aplikací jsou chráněny, i když přejdeme na verzi
Client/Server C++ Builderu. C++ Builder zjednodušuje vývoj databázových
aplikací a také umožňuje přejít na vyšší implementaci klientská aplikace
- aplikační server, když je potřeba.
Vícevrstvové databázové aplikace
V modelu vícevrstvové databáze, aplikace je rozdělena do
částí, které sídlí na různých počítačích. Klientská aplikace poskytuje
uživatelské rozhraní k datům. Získává všechny datové požadavky a aktualizace
prostřednictvím aplikačního serveru. Aplikační server komunikuje přímo
se vzdáleným databázovým serverem. Obvykle v tomto modelu, klientská aplikace,
aplikační server a vzdálený databázový server jsou na různých počítačích.
To ukazuje následující obrázek:
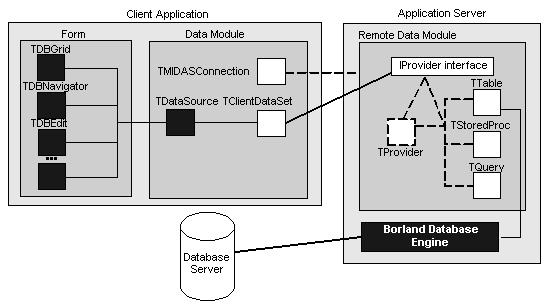 Můžeme použít C++ Builder k vytvoření klientské aplikace
i aplikačního serveru. Jak je ukázáno, klientská aplikace používá standardní
datové ovladače spojené prostřednictvím datového zdroje na jednu nebo více
komponent klientských datových množin pro zobrazování a editaci dat. Každá
klientská datová množina komunikuje se serverovou aplikací prostřednictvím
rozhraní IProvider, které je částí vzdáleného datového modulu aplikačního
serveru. Rozhraní
IProvider
je duální rozhraní ActiveX, které je
zřízeno aplikačním serverem, když klient poprvé použije komponentu TMIDASConnection
pro zřízení propojení na aplikační server.
Můžeme použít C++ Builder k vytvoření klientské aplikace
i aplikačního serveru. Jak je ukázáno, klientská aplikace používá standardní
datové ovladače spojené prostřednictvím datového zdroje na jednu nebo více
komponent klientských datových množin pro zobrazování a editaci dat. Každá
klientská datová množina komunikuje se serverovou aplikací prostřednictvím
rozhraní IProvider, které je částí vzdáleného datového modulu aplikačního
serveru. Rozhraní
IProvider
je duální rozhraní ActiveX, které je
zřízeno aplikačním serverem, když klient poprvé použije komponentu TMIDASConnection
pro zřízení propojení na aplikační server.
Aplikační server vytváří rozhraní IProvider jedním
ze dvou způsobů. Pokud aplikační server obsahuje jeden nebo více objektů
TProvider,
pak tyto objekty jsou vytvořeny při vytváření rozhraní
IProvider.
Pokud ne, pak aplikační server vytváří rozhraní IProvider automaticky.
V obou případech, všechny data jsou předávána mezi klientskou aplikací
a aplikačním serverem prostřednictvím rozhraní. Rozhraní získává data z
a zasílá aktualizace na normální komponenty datových množin C++ Builderu
a tyto komponenty komunikují s databázovým serverem prostřednictvím BDE.
Obecně, je několik klientských aplikací, které komunikují
s jedním aplikačním serverem ve vícevrstvovém modelu. Aplikační server
poskytuje bránu k našim databázím a pro všechny naše klientské aplikace
poskytuje databázové úkoly v centrálním místě.
Rozšíření databázové architektury C++ Builderu
Mimo všech těchto způsobů vytváření databázových aplikací,
model otevřené datové množiny umožňuje rozšířit architekturu přidáním požadovaných
možností. V rozšířeném modelu datových množin, určíme co požadujeme a odvodíme
uživatelskou komponentu datové množiny od TDataSet nebo některého
z jeho potomků. Odvozením uživatelské komponenty od TDataSet umožňuje
použít datové ovladače C++ Builderu k vytváření uživatelského rozhraní.
Např. jestliže chceme udržovat tenkou klientskou aplikaci,
pak ji můžeme vytvořit pomocí TClientDataSet, ale když se chceme
připojit k databázi DB2 bez použití BDE, pak musíme vytvořit uživatelskou
komponentu datové množiny. TDataSet definuje funkčnost společnou
pro všechny objekty datových množin. Můžeme zjistit, že existující objekty
datových množin, jako TClientDataSet nabízí další služby, které
chceme použít. V tomto případě můžeme odvodit uživatelskou komponentu datové
množiny od
TClientDataSet namísto od TDataSet. Tím zmenšíme
množství potřebného kódování.
Návrh uživatelského
rozhraní
Stránka Data Controls Palety komponent poskytuje datové
ovladače, které reprezentují data z položek v záznamech databáze a mohou
umožnit uživateli editovat a odesílat změny zpět do databáze. Pomocí těchto
datových ovladačů, můžeme budovat uživatelské rozhraní naší databázové
aplikace tak, že informace jsou viditelné a přístupné uživateli.
Datové ovladače přidáváme k uživatelskému rozhraní podle
typu zobrazovaných dat. Seznámíme se s nimi v těchto bodech:
Zobrazování jednoho záznamu
V mnoha aplikacích můžeme pouze požadovat poskytnutí informací
o jednom záznamu dat. Např. aplikace zadávání objednávek může zobrazovat
informace o jedné objednávce bez indikování jaké ostatní objednávky jsou
právě zadávány. Tuto informaci pravděpodobně získáme z jednoho záznamu
v datové množině objednávek.
Aplikace které zobrazují jeden záznam jsou obvykle snadno
čitelné a pochopitelné, protože všechny databázové informace jsou o jedné
věci (v předchozím příkladě o nějaké objednávce). Datové ovladače v těchto
uživatelských rozhraních reprezentují jednu položku ze záznamu datové množiny.
Stránka Data Controls Palety komponent poskytuje široký výběr ovladačů
k reprezentaci různých tříd položek.
Zobrazování více záznamů
Někdy požadujeme zobrazit mnoho záznamů ve stejném formuláři.
Např. aplikace může chtít zobrazit na jednom formuláři všechny objednávky
od jednoho zákazníka.
K zobrazení více záznamů, použijeme ovladač mřížky. Ovladač
mřížky poskytuje vícepoložkový více záznamový pohled na data, který může
dělat uživatelské rozhraní naší aplikaci komplexnější a efektivnější.
Můžeme požadovat návrh uživatelského rozhraní, které
zobrazuje jak položky z jednoho záznamu tak i mřížky reprezentující více
záznamů. Jsou dva modely, které těchto případech používáme:
-
Formuláře Master-detail. Můžeme prezentovat informace
jak z tabulky Master tak i tabulky Detail vložením ovladačů, které zobrazují
jednotlivé položky, tak i ovladače mřížky. Např. můžeme požadovat zobrazení
informací o jednom zákazníkovi s detailem mřížky, která zobrazuje objednávky
pro tohoto zákazníka.
-
Rozbalované formuláře. Na formulář, který zobrazuje
více záznamů, můžeme vložit ovladače jednotlivých položek, které zobrazují
detailní informace z právě vybraného záznamu. Tato možnost je obzvláště
užitečná když záznam obsahuje dlouhou poznámku nebo grafickou informaci.
Jak uživatel prochází záznamy mřížky, memo nebo grafika je aktualizována
k zobrazování hodnoty současného záznamu. Toto nastavení je velmi snadné.
Synchronizace mezi dvěmi zobrazeními je automatická: pokud ovladač mřížky
a memo nebo image sdílejí společný datový zdroj.
Poznámka: Obecně není vhodné kombinovat tyto dvě
možnosti na jednom formuláři. I když výsledek může být efektivní, je obvykle
obtížné pro uživatele pochopit vzájemné vztahy dat.
Analyzování dat
Některé databázové aplikace neprezentují databázové informace
přímo. Mohou analyzovat a sumarizovat informace z databáze a zobrazit souhrn
dat. Komponenta TDBChart na stránce
Data Controls Palety
komponent umožňuje prezentovat informace z databáze v grafickém formátu,
což umožňuje uživateli rychlé pochopení importovaných databázových informací.
Dále některé verze C++ Builderu obsahují stránku Decision
Cube na Paletě komponent. Obsahuje šest komponent, které provádějí
datovou analýzu na datech.
Pokud požadujeme vlastní komponentu, která zobrazuje
sumarizovaná data na základě různých seskupovacích kritérií, pak můžeme
použít agregační funkce s klientskou datovou množinou.
Výběr, která data
zobrazit
Často data, která chceme zpracovávat v naší databázové aplikaci
neodpovídají přesně datům v jedné databázové tabulce. Můžeme požadovat
pouze podmnožinu položek nebo podmnožinu záznamů v tabulce. Můžeme také
kombinovat informace z více tabulek do jednoho spojeného pohledu.
Data dostupná v naší databázové aplikaci jsou určována
volbami komponenty datové množiny. Vlastnosti a metody abstraktní datové
množiny databázové tabulky nerozlišují to, zda data jsou uloženy v databázové
tabulce nebo zda jsou odvozeny od jedné nebo více tabulek v databázi.
Naše aplikace může obsahovat více než jednu datovou množinu.
Každá datová množina reprezentuje logickou tabulku. Pomocí datových množin,
logika naší aplikace je složena z restrukturalizovaných fyzických tabulek
v naší databázi. Můžeme potřebovat změnit typ komponenty datové množiny
nebo způsob specifikace obsažených dat, ale zbytek našeho uživatelského
rozhraní může pokračovat v práci beze změny.
Můžeme používat tyto následující typy datových množin:
-
Komponenty tabulek: Tabulky odpovídají přímo připojeným
tabulkám v databázi. Můžeme určit, které položky zobrazovat (včetně přidávání
vyhledávacích a počitatelných položek) pomocí trvalých položkových komponent.
Můžeme omezit zobrazované záznamy pomocí rozsahu nebo filtru.
-
Komponenty dotazů: Dotazy poskytují obecnější mechanismus
pro specifikaci co má být obsaženo v datové množině. Můžeme kombinovat
data z více tabulek pomocí spojení a omezovat položky a záznamy na základě
nějakého kritéria uvedeného v příkazu SQL.
-
Uložené procedury: Uložené procedury jsou množinami
příkazů SQL, které jsou pojmenované a uložené na SQL serveru. Pokud náš
databázový server definuje vzdálené procedury, které vracejí datové množiny,
pak můžeme použít komponentu uložené procedury.
-
Klientské datové množiny: Klientské datové množiny
ukládají záznamy logické datové množiny do paměti. Mohou tedy obsahovat
pouze omezený počet záznamů. Umožňují vytvářet menší aplikace, protože
nevyžadují BDE. Klientské datové množiny jsou plněny daty dvěma způsoby:
z aplikačního serveru nebo dat uložených v souboru na disku.
-
Vnořené datové množiny: Vnořené datové množiny reprezentují
záznamy ve vnořené detailní množině Oracle8. C++ Builder neumožňuje vytvářet
tabulky s vnořenými položkami datových množin, ale umožňuje jejich editaci
a zobrazení. Vnořená datová množina získává svá data z komponenty položky
datové množiny.
-
Přizpůsobené datové množiny: Můžeme vytvářet své vlastní
přizpůsobené potomky TDataSet k reprezentaci dat, která vytváříme
nebo k nim přistupujeme v kódu.
Vytváření sestav
Pokud potřebujeme vytisknout databázové informace z datových
množin v naší aplikaci, pak můžeme použít komponenty sestav na stránce
QReport
Palety komponent. Pomocí těchto komponent můžeme vizuálně budovat proužkovou
sestavu k prezentaci a sumarizaci informací z našich databázových tabulek.
Můžeme přidávat sumarizace na hlavičky a patičky skupin k analýze dat na
základě seskupujících kritérií.
   |
1. Úvod do návrhu databázových
aplikací
|