21 Jun 1995 - Preliminary Information
[Note: a defective version of the June 21 code was posted between Midnight and 11:00 EDT on that date. Please replace it with the corrected version]
A World Wide Web has to deal with international character sets. Unfortunately, there are more characters in the World than can be easily handled in any simple one-byte encoding. Three solutions are available.
Unicode provides a two-byte character set that can handle all the Western languages and Chinese, Japanese, and Korean. This is the ultimate solution, but it is new and there are no good tools available.
There are a family of one-byte character sets that provide coverage for most languages. Since no single code can include the Western "Latin" alphabet and Hebrew, Arabic, and Cyrillic, the ISO proposed a set of 8859-x (where x=1...n) character sets covering each major alphabet group. The 8859-1 (also called "Latin 1") character set covers all the languages of Western Europe (and America, Australia, etc.). Starting with HTML 2.0, the Web standards hold that an HTML document is assumed to be in 8859-1 unless stated otherwise. The HTTP and some of the HTML <HEAD> area conventions may provide for the use of other 8859-x tables for other alphabets, though the Netscape Browser, for example, only supports 8859-1 and Japanese.
Since a complex document may include characters (including Math and other special symbols) from different 8859-x character sets, HTML has a notation for "Entities". An Entity reference begins with the "&" escape, then contains the character name, and ends in a semicolon. For example, it is becoming widely accepted that the copyright symbol © can be represented by the Entity reference "©".
From the beginning, SpHyDir read and created Entity references for the three special control characters "<", ">", and "&" (< > and &). The Entities were converted to the native character for easy display and editing. When HTML was generate, these characters were converted back to Entities.
Starting with the May 28th release, SpHyDir supported foreign language Entity names, but without any translation. The "&" character was simply converted to a Smiley Face dingbat character (so that the real "&" character could be treated as normal text in expressions like "PC Lube&Tune"). A user could create new Entity references by entering the Smiley Face character in the Text Edit Window (you can enter any character in the PC set by typing its decimal value on the keypad while holding down the Alt key. Since Smiley Face is 1, hold down Alt, type "1" on the numeric pad, and release Alt).
This made the entry of foreign characters possible, but not natural. The name of a landmark in the Stuttgart area had to be rendered with the Entity reference to the German sharp s (ß) as Schloßkirche (castle church)
The best approach would be to display foreign characters natively, just as SpHyDir translates the < > and & characters natively. After trying unsuccessfully to come up with some magic application that would solve the problem SpHyDir now caves in and handles the problem with the OS/2 standard Code Page Solution. Now Schloßkirche will display in its native format in the SpHyDir Workarea and in the Text Edit window, provided that you are using Code Page 850 or convert the supplied tables to work with some other Code Page.
The original PC character set is known today as Code Page 437. It is the default and is the set you get if you don't know enough to change it in CONFIG.SYS. The 437 set does not have all the characters in the "Latin 1" group. However, it does have the most important Western European characters. Although SpHyDir recommends and supplies tables for the improved Code Page 850 (along with instructions to change the CODEPAGE statement in CONFIG.SYS to make it the default), a user who insists on keeping the old 437 Code Page could change the supplied tables to support it.
SpHyDir ships files named ENTITIES.850, CHARIN.850, and CHAROUT.850. They should be copied to the root directory of the HTML library. ENTITIES.850 provides a mapping between the Entity names and the code assignments for the corresponding characters in the 850 Code Page. This is just a text file and it can be used as a model to produce an ENTITIES.437 if you insist on using the old defective 437 Code Page. It can also be changed to any other national use Code Page supported by OS/2. The other two files provide translate tables between the ISO 8859-1 encoding and the Code Page locations of the corresponding characters in the IBM numbered Code Page. This is a bit more tedious to edit, but it can be done.
SpHyDir doesn't do anything special about the keyboard. The assumption must be that a user has already selected a Code Page and Keyboard layout that allow the entry of characters to the ordinary editors and windows of the system. Rather than trying to duplicate (or worse to override) that support, SpHyDir simply provide a simple mechanism completely under the user's control to translate HTML entities into the standard operating system character support.
If a file is encoded in the ISO 8859-1 standard, the SpHyDir supplied translate tables will convert it to Code Page 850 as it is read in. This version of SpHyDir is biased to Entity notation, so when SpHyDir generates HTML it will use Entity notation for all characters that have values with defined Entity names. It will convert back to ISO 8859-1 only the characters that do not have Entity names. This version of SpHyDir will not display as native characters anything entered with the "numeric" entity notation. Only named characters will be translated for native display.
A new section of the SpHyDir document describes Code Pages in general and the ENTITIES definition file in particular.
Saw a request on the net for JPEG support. Added JPG and JPEG (case insensitive) to the list of extensions regarded as IMG file types. At this time, SpHyDir does not know how to find the size of JPEG files, so it does not add WIDTH and HEIGHT attributes as it does for GIF.
Discovered a user was still using TARGET. It was reported that if you drag the TARGET object from the toolbar (which was by the way blank now for some reason) and try to save the file, SpHyDir crashes. Well the TARGET object isn't supposed to be there, which is why the tool is blank. However, there really still was a TARGET tool under that blank face, and yes when you insisted on using it the HTML generation failed. This, however, also exposed a problem with the ToolChest, since SpHyDir would fail if the user created a tool with an unsupported type. Anyone who ran SpHyDir in the last few weeks has a TARGET tool in the ToolChest that won't go away until the TOOLDEF.TXT file is deleted from the root directory of the HTML Library. So HTML Generation is now protected against invalid object types.
Corrected a bug deleting Links. Added most remaining Netscape non-standard extensions.
Note: Netscape has this terrible idea to make BORDER an attribute of IMG taking a numeric value. This contrasts to the use of BORDER in TABLE which is just a Yes or No. SpHyDir II doesn't currently have the ability to distinguish valid ranges of values when the same attribute has different types of values in different tags. Reluctantly, BORDER is now defined as taking any type of value. So while it was possible previously to simply select BORDER from the Properties popup menu of a TABLE object and it would be set to the right thing, now when you select BORDER you will get a dialog box and you have to type in "Yes" and press OK.
SpHyDir has been struggling with the problem of Image Objects. The HTML 2.0 standard allows IMG tags to appear in the middle of sentences, headers, and captions. An IMG is regarded as a large letter. This is why the official ALIGN options for IMG (TOP, MIDDLE, BOTTOM) relate to how the image is aligned vertically with the characters immediately preceeding and following it.
That is not the way that most people want to treat large images. Netscape proposed two additional alignments (LEFT, RIGHT) that allow text to flow around the margin of an image, much as word processors handle inserted graphics. HTML 3.0 also includes these values for ALIGN, but for the most part it wants to use FIG.
A Figure is enclosed in the <FIG>..</FIG> tags. The FIG tag contains a SRC attribute that points to a graphic file, much as IMG. FIG has a number of extensions over IMG that might prove useful if any browser supported it. However, at this point no mainstream Web browser knows about FIG and all ignore it. Of course, they do not ignore the markup inside the FIG tag, just the tag itself.
The ordinary text content of the FIG tag is supposed to be displayed on non-graphic browsers as an alternative to the image:
<FIG SRC=monalisa.gif>
A famous painting of a woman smiling.
</FIG>
The IMG tag has an ALT attribute that contains alternate text for the same purpose. However, the FIG tag can contain much larger descriptions with paragraphs, lists, headings, and all other document elements. A major objective is to allow detailed description of diagrams for readers who are visually impaired and use text-to-speech browsers.
Currently, however, no major browser supports the FIG tag. Following standard practice, a browser ignores tags that it does not understand, but does not ignore their contents. This makes it difficult in the near term to use the FIG contents for its intended purpose since it will be displayed by graphic browsers like Netscape, Web Explorer, and Mosaic.
However, FIG appears to be a way out of the hole that SpHyDir in which SpHyDir has fallen. That hole was caused by the desire to have an Image Object. An Object is a nice big thing. You can drop GIF files on it. You can link to it easily. You can parameterize it with properties. The problem, of course, is that an object cannot occur between a couple of words, and since HTML 2.0 wants to regard the IMG tag as part of the ordinary paragraph text, this in the long run produced all sorts of problems.
The FIG is a much more suitable starting point for a Document Object. It stands along, like a paragraph. It even aligns LEFT, CENTER, RIGHT, and JUSTIFY like a paragraph. It cannot appear in the middle of a sentence or in a Heading.
Since FIG isn't currently supported by browsers, there has to be a migration strategy. As with "<CENTER><P ALIGN=CENTER>", the SpHyDir approach to HTML migration is to do the thing "every which way" it can be done so that every browser must precisely what is intended. Of course, there is no way to fake the advanced features that caused FIG to be invented in the first place. The browsers will just have to catch up. However, it is possible right now to generate a FIG that can replace standalone and text-wraparound images:<FIG SRC=monlisa.gif ALIGN=LEFT>
<IMG SRC=monalisa.gif ALIGN=LEFT ALT="A famous painting of a woman smiling">
</FIG>
An HTML 3.0 graphical browser will understand FIG, display the GIF file, and ignore the contents.
An HTML 2.0 graphical browser will not understand FIG and will ignore it. It will not ignore the contents, and so will process the IMG tag. Again the GIF file is displayed.
A non-graphical browser may or may not understand FIG, but in any case will ignore it because the browser doesn't display images. It will then look at the IMG tag and again decide not to display the GIF, but it will print the ALT text.
Although the GIF file appears in both the FIG and IMG tags, the two are mutually exclusive. One or the other will be processed, but not both. As to the ALIGN=LEFT, this is valid for a FIG in HTML3 and is a widely supported Netscape extension of IMG in HTML 2.
SpHyDir 1 did not deal with IMG tags that were embedded in the middle of a paragraph or Heading. SpHyDir II accomodated such IMG tags by creating another "dingbat" sequence in the text. The 0x08 character, which looks like a box with a hole, or roughly "[o]", is used to start and end an IMG reference. Between these two dingbats are the name of the GIF file, then optionally a blank and the alternate text.
However, in the first cut SpHyDir II continued to extract IMG tags from the start of a paragraph (or when they form a paragraph by themselves). They become IMG objects. Later on, SpHyDir II tries to decide if they should be merged back into the paragraph that follows them.
The intent is to change this. Images that are contained in a paragraph of their own, or that have ALIGN values LEFT or RIGHT will be extracted as before to for a separate object. However, the object will then be regenerated as a FIG+IMG construct as described above. This will allow the Image Object to begin to have Properties derived from the more powerful FIG tag, instead of limiting it to the current IMG Properties. Conversely, IMG tags that fall at the start of a paragraph containing other text, and that have ALIGN values of TOP, MIDDLE, or BOTTOM, will be treated as embedded images and will be represented by the 0x08 dingbat character sequence.
The Text Edit Window now allows drag and drop. Position the cursor or select a phrase of text. Now
Drag and Drop a GIF file anywhere on the Text Edit Window. This will generate an "embedded IMG". If no text is selected, the dingbat character and file name will be placed at the cursor position. If text is selected, then the selected text will become ALT alternate text within the dingbats.
Select some text. Hold down Ctrl-Shift and drop any file from the HTML library on the Text Edit Window. The previously selected text becomes a hypertext link to the file. Previously it was necessary to save the text, Link-Drop a file on the Paragraph Object in the workarea, and then select the text from the Hotword Selection window. Allowing links to be formed directly in the Text Edit window simplifies this process. Note that links created this way are saved only if the rest of the edited text is saved. Pressing the Cancel Button or closing the Text Edit window cancells the new Links as well.
Select text and drop a URL Object created by Web Explorer from the Workplace on the Text Edit Window. The selected text will be converted to a Link to the remote resource represented by the URL.
Do not select text. Leave the cursor at an insertion point in the paragraph (usually after a blank). Drop a URL Object created by WE on the Text Edit Window. The title of the remote resource is inserted at the point of the cursor and becomes a hotlink to the document itself.
Unfortunately, it is not possible to drop Link Manager list items on the Text Edit Window. To maintain the integrity of the data being edited, the Text Edit Window locks up the underlying Workarea until the edit completes. This also blocks the Link Manager from functioning. So links have to come from the WPS environment, or save the text and use the Link Manager as it has traditionally been used.
Extra blank spaces and lines after the <LI>, <TH>, and <TD> tags were removed. They were errors picked up by Netscape producing undesired results.
SpHyDir now declines to insert some of ending tags that nobody else bothers to generate. Tables generated too many </TH>, </TD>, and </TR> tags. It made the HTML ugly and hard to read.
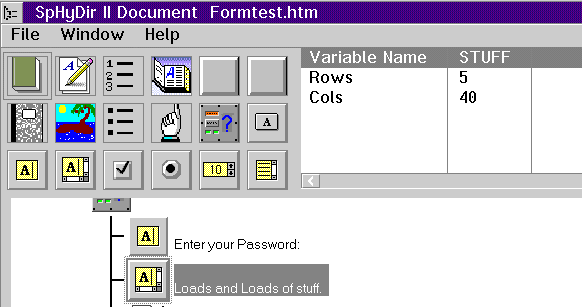
The temporary dialog for new Tables has been replaced by a more polished dialog box. Enter the number of rows and columns and select by a checkbox if they are to be labelled.
Select a Table Row Object. Click the Second Mouse Button. Select Create Another from the popup menu. A new row is created with the same number of label and cell objects as the previous row. [Adding a new column is harder and is left to a later date.]
When generating an Ordered or Unordered list, SpHyDir II has added an extra step because List Points no longer contain text. One might have to drop a new Point on the list, then go back and drop a new Paragraph on the Point. A shortcut is to popup the Second Mouse Button window for the previous Point and choose Create Another. This not only creates another Point object, but it also creates another Paragraph under it and opens the Text Edit window directly. More generally, Create Another populates the new Point with another object of the same type as the first object contained in the old point, so the trick works for Points of Images as well.
Forms bugs caused by rewrite: TYPE did not default to TEXT, NAME attribute generate twice, SUBMIT incorrectly genned as HIDDEN.
SpHyDir II now appears stable enough to remove some of the disclaimers. There are certain to be problems with the new HTML 3.0 tags that nobody is using, but more bugs have been fixed in the old code than seem to be problems with the new. SpHyDir II is now the "standard" distribution. Where the old code is mentioned, it is called "SpHyDir 1". The documentation has been updated.
A user had problems with the small characters. SpHyDir now remembers the WPS font that has been dropped on the Workpace, Properties Table, Edit Windows, and Link Manager. The Link manager window can now be widened.
Newer versions of the HTML standards pointed out a number of details about Entities. An ampersand is only regarded as a possible entity if it is followed by letters or numbers. The sequence "A & P" is legal. An entity doesn't require an ending ";" except to separate it from characters that could be part of the entity name. "A & P" is also valid. SpHyDir now recognizes these forms, though on output it always generates the full "A & P" in the output HTML.
After an initial false start, SpHyDir 1 support for Targets (the object corresponding to the HTML <A NAME=xxx> tag) became stalled. The problem is that HTML standards and use permitted the <A> tag to include text and Headings. Unfortunately, this might mean a construct of the form:<A NAME=FUZZY>the end of one topic.
<H2>Now for Something Completely Different</H2>
On a completely unrelated matter, </A>
This is perfectly legal HTML, but any attempt to make structural sense out of it is hopeless.
HTML 3.0 presented a much better idea. Labels can be assigned to headers or paragraphs with the ID attribute. This presents a Hypertext label whose location and purpose is unambiguous. Unfortunately, ID is not widely supported.
SpHyDir II takes its inspiration from the "Recommended" syntax of HTML 2 and 3. "Recommended" practice holds that an anchor should go inside a Header rather than including the header. This would produce<H2><A NAME="Python Introduction">
Now For Something Completely Different</A></H2>
One big advantage is that this syntax is effectively interchangeable with the preferred (but currently not widely supported) HTML 3 construct:<H2 ID="Python Introduction">
Now For Something Completely Different</H2>
Now a reasonable strategy appears. It eliminates ambiguity, gets rid of the Target object (which was cute but a problem), and provides for the sane migration from HTML 2 to 3. First, ambiguous structure is resolved by asserting that legacy HTML should have been following the Recommended practice. The <A NAME=xxx> tag is logically associated with the very next thing that follows it no matter where the </A> is located. The Name, however, becomes an attribute of the object that contains the next thing that follows the <A>.
"<A NAME=X>Fred. <H2>Mary" assigns the name X to the Paragraph or other text object containing "Fred". The name has nothing to do with the following Mary section.
"Fred.<A NAME=X><H2>Mary" - Assigns the name X to the Section associated with the Header for Mary. Although the <A> tag is "outside" and "before" the Header, nothing else comes between the tag and the start of the Header. The name applies to the first thing that follows the <A> tag, not the superficial location of the <A> tag itself.
"Fred.<H2><A NAME=X>Mary" - HTML 2.0 Recommended practice. SpHyDir will convert the previous case to this when generating new HTML. That is, SpHyDir will move the <A> tag inside the <H2> tag.
"Fred.<H2 ID=X>Mary" - Recommended HTML 3.0 practice. Unfortunately, many browsers don't support this yet. SpHyDir will recognize it and "backlevel it" to the previous case of Recommended HTML 2.0 practice. Later on, when the browsers catch up, this will become the syntax that SpHyDir will produce and SpHyDir will "upgrade" HTML 2 to 3.
The Target button has now been restored to the Link Manager window. This time it works. Pressing the target button displays all the target lables in the current document tree. They can be dragged and dropped onto Images and text to form hyperlinks as previous Link Manager entries were used. SpHyDir does not intend to extende the reach of the target button outside the current document. Rather, XSpO programs will be developed to identify targets in other documents or databases.
Although it is common practice to give short names to targets, HTML allows the ID/NAME value to be long and to have multiple words if it is quoted. Note that names are case sensitive. Using somewhat more descriptive names is helpful when a hypertext link must be selected from a long list of available labels.
CENTER and ALIGN=CENTER should be handled correctly in most cases. There is one area where problems can arise. When an IMG appears at the start of a paragraph, SpHyDir tries to break it out as a separate object. Objects are easier to change, since you can update properties with the table and can drop a new GIF file on the icon. Thus<P><IMG SRC=xxx ALIGN=MIDDLE>This is typical.</P>
is processed by SpHyDir to produce an Image Object and a Paragraph Object. The ALIGN=MIDDLE on the Image is the flag that warns SpHyDir to shuffle the image back "inside" the paragraph when HTML is generated.
This is even harder to code than it is to describe. It becomes impossible, however, when you add CENTER:<CENTER>
<P><IMG SRC=xxx ALIGN=MIDDLE>This is typical.</P>
</CENTER>
The problem is that CENTER is not an attribute of IMG tags. The "MIDDLE" value means to align the image vertically so that the text that follows is at the middle of the image. It has nothing to do with CENTER which is horizontal alignment. An IMG can have ALIGN values of TOP, MIDDLE, BOTTOM, and with extensions LEFT and RIGHT. However, the way to center an IMG is to put it inside a centered paragraph as above (Netscape) or below (HTML 3.0):<P ALIGN=CENTER><IMG SRC=xxx ALIGN=MIDDLE>This is typical.</P>
SpHyDir is left with three bad choices. One approach is to give up entirely on Image Objects. This reduces the drag and drop functionality of the system. A second approach is to allow Paragraphs to be "opened" to expose embedded images as objects. This would be a major revision of current use. So SpHyDir will try to salvage the current approach from the onslaught of new HTML features that make it more difficult.
Suppose you want to center two lines. One HTML 3.0 approach is to apply the center attribute to each separately:<P ALIGN=CENTER>Tastes Great!</P>
<P ALIGN=CENTER>Less Filling!</P>
This does the job, but if you change your mind it becomes necessary to uncenter each separately. The Netscape extension does the job:<CENTER>Tastes Great!<P>Less Filling!</CENTER>
but there are a number of technical semantic problems with the CENTER tag that make it unlikely to survive standarization. The HTML 3.0 view is to group the lines:<DIV CLASS=BUDLITE ALIGN=CENTER>
<P>Tastes Great!</P>
<P>Less Filling</P>
</DIV>
Alignment on a DIV applies to everything inside it. The best use of CLASS names in this context is unclear.
SpHyDir tries to migrate everything in the direction of the formal standard. To that purpose, SpHyDir introduces the Group Object which is logically associated with a DIV tag. The Insert - Structure - Group option of the Second Mouse Button popup will create an empy group. Alternately, Mark a range of objects and select Group from the popup to create a group containing all the marked objects (leaving them where they were).
However, the final use of Group and DIV is not clear. The standard provides little direction, and there is no body of use on the Net to point to the right direction. Clearly the current SpHyDir casual approach to Section Objects should be formalized by creating <DIV CLASS=xxx> markups. However, if a document spans multiple files in a tree, how does one determine the CLASS names (VOLUME, CHAPTER, SECTION, SUBSECTION, APPENDIX, etc). It should also be possible to convert a Group object into a Section Object (by adding a Title) or demote a Section to a plain group. What other transformations are needed?
SpHyDir II supports most of the HTML 3.0 and Netscape extended functions. Anything missing will be added quickly. This code is Beta because a large amount of core logic had to be ripped up and reorganized. There has not been enough time to test everything.
For the next few weeks, before using this code make an archive copy of the original file. Check carefully for any individual element that might have been dropped out of the document because of a bug. Please report problems back to the author.
Rewriting the documentation is one of the tasks ahead. As a result, SpHyDir II Beta is available only by FTP from pclt.cis.yale.edu in the sphydir subdirectory of /pub. Source will temporarily be unavailable to Professional uses, though the key that enables Professional features on SpHyDir 1 continues to work on II.
An HTML tag has attributes. SpHyDir II document objects have properties. There is largely a one to one correspondence between attributes and properties.
HTML 3.0 adds a ton of attributes to previously fairly simple tags. Even the <P> tag can now become<P ID="HomeTown" ALIGN=CENTER CLEAR=ALL>
SpHyDir II needs a way to display and change all these new properties for each object.
The Properties Table is modelled after similiar windows in Visual Basic and Delphi. Since PM doesn't exactly have the same kind of controls, SpHyDir settles for a Container (the same type of object as an open WPS folder or the Workarea) set to Details View. There are two columns in the table, a property description and a value.

It seemed to be confusing to list all the properties that every object might have, so the table lists only those with a significant value. However, if you point to the whitespace of the table (below the last entry) and click the second mouse button, a popup menu will list all the properties known to be valid for this type of object. During the Beta period, SpHyDir may be a bit fuzzy about this selection and may include a few properties that belong to a larger class of objects of which the current object is a particular case. For example, the properties of all the forms objects are jumbled together and need to be sorted out.
The value column of the table can be directly edited. Since this is a container, changing the value this way uses the same technique for renaming a file in WPS. Hold down Alt and click on the old value. A box appears around the old value and it can be edited. Clicking elsewhere in the table completes the process and saves the new value. As with WPS file renaming, this interface is not ideal.
Since the value column may be narrow and awkward, an alternative strategy is to doubleclick the property. This pops up a box with a bit more room to change the old value, and some edit rules that are a bit nicer to use.
If a property has a list of possible values, the list can be displayed by clicking on the property with the second mouse button. The possible values popup as a menu. SpHyDir II does not feel strongly that it really knows the absolutely correct list of possible values. First, the HTML 3.0 standard changes a lot. Secondly, the same attribute name can have different possible values in different contexts. So the user is free to type in values that are not in the list. Its just that the second mouse button popup menu cannot be used to set other values.
It is a restriction for the near term that the values "Yes" and "No" may not be used for any property other than a logical switch. So don't try to title a section "No" cause that won't work. Switches correspond to attributes whose presence signals a option, such as "COMPACT" in a list. Setting a logical switch to "No" is eventually going to delete it from the properties table, because "No" is the default setting for a switches and corresponds to the attribute not being present in the tag.
A few properties are changed implicitly by the dropping things on an object. For example, dropping a GIF file on the Document object changes the Background property and produces Netscape/HTML3 backgrounds. The Title of the Document or of a Section appears both as a property and as the caption of the Workarea Object. It can be edited by doubleclicking the Section object.
The HEAD tags are now parsed. Along with the attributes of the BODY tag, they generate attributes of the document. Support is provided for BASE, ISINDEX, LINK (REV=HOME,TOC,INDEX, GLOSSARY, HELP, BOOKMARK), and the BODY Netscape attributes for background and color control. META attributes will be added if anyone can send me a list.
<BLOCKQUOTE>
What, Me Worry?
<CREDIT>Alfred E. Newman
</BLOCKQUOTE>
This construct should be properly supported. At this time, SpHyDir accepts both BLOCKQUOTE and BQ but it currently generates BLOCKQUOTE to the output file. Although BQ is recommended, it is not supported by all current browsers, while BLOCKQUOTE is universal. It has been observed that <CREDIT> is not supported by WE.
The sequence:<UL>Some text.
<LI>One.
<LI>Two.
</UL>
is upgraded so that the isloated text is rendered as<LH>Some text.</LH>
List header text is displayed as the caption of the List Object and can be changed by doubleclicking the object.
Similarly, the construct<Table>Some text.
<TR> etc.
is upgraded to<CAPTION>Some text.</CAPTION>
In general, SpHyDir II will put ending tags in all output even when the tags can be legally omitted. In general, SpHyDir will put all text in some block, with <P>...</P> as the default. In the previous case the <P> is not appropriate because <CAPTION> (and <CREDIT>,<LH>, and a few other such things) are themselves the block container and are not allowed to contain other blocks.
SpHyDir 1 tried to promote all IMG references to objects. There is a certain simplicity when this can be done, because you can drop a GIF file on an IMG object to set the file association. However, SpHyDir 1 was therefore unable to place IMG references in a Heading or in the middle of a sentence. An IMG can now appear in the previously usupported places. In this context, the IMG is treated as "honorary text". A dingbat (corresponding to the PC character for the value 8) appears before and after the embedded image. Between the dingbats, the first word is the name of the GIF file and the remaining text is treated as ALT text.
There is currently no nice support for creating new embedded images. It will be added by the end of the beta period. For now, you can always type this stuff in manually. In the Text editor window, position the insert where you want the image to go. Hold down Alt, press the "8" key on the numeric pad, and release the Alt key. The dingbat appears. Type the name of the file in the ususal HTML format, say "../icons/face.gif". Type alternate text if you choose. End by repeating the Alt trick to create a second dingbat. (This can also be used to enter other unsupported tags and markup).
No attempt has or will be made to do HTML 3.0 Math markup. No support is provided for the horizontal tab <TAB> tag.
FIG has not been attempted this week. It should not be hard, but needs a bit of study to get it just right.
It is not clear just how many of the proposed new forms of character emphasis should be supported. <DFN>, <Q>, <LANG>, <AU>, <PERSON>, <ACRYONYM>, <INS>, <DEL>, <BIG>, and <SMALL> seem to be stretching things a bit. It is not clear that all of them will actually survive the standardization process, expecially since few browsers do anything particularly meaningful with the HTML 2.0 character formatting tags that already exist.
Most of the attributes in the HTML 3.0 standard are supported. A bunch of Netscape stuff was added, but a few more things are needed before the end of the Beta. To know what is supported, select an object of the appropriate type, then click the second mouse button on the whitespace of the Properties Table. If the attribute doesn't show up in the list, its not supported. Write me about it.
A major feature of HTML 3.0 is tables. They allow information to be layed out in columns. The rows and columns may have labels. Each cell of the table contains any type of document element (paragraphs, images, buttons, etc). Architecturally, a table is a two dimensional version of an Unordered List.
Viewed as HTML, Tables involve a large number of confusing tags. They are hard to edit by hand. SpHyDir allows you to construct specialized tables, but it will automate the process of building simple N by M tables. Even if you want something special, like a heading that spans two columns, it may be easier to let SpHyDir start by generating the normal table and then change or delete the automatically generated entries that you don't need.
When you use the Table Object, a dialog box pops up. During the Beta it is a bit cheezy. You can abort the dialog, leave a bare Table object, and add elements yourself (or you will if all the elements are available in some toolbar). Alternately, specify the number of rows and columns and choose whether lables are to be generated or not for each.
A simple 2x3 table might look like:
CL0 CL1 CL2 CL3
RL1 X11 X12 X13
RL2 X21 X22 X23
Where CL# are the column labels, RL# are the row labels, and X## are the cells. HTML is going to ravel this out row by row. The nasty part is getting the tags right. If SpHyDir II is asked to construct this table, it will produce a Table Object containing three Row Objects. The first Row Object contains the four Label Objects for the columns. The second and third Row Objects contain one Label Object (the row label) and three Cell objects. Initially, all are empty.
TABLE
ROW
LABEL (CL0)
LABEL (CL1)
LABEL (CL2)
LABEL (CL3)
ROW
LABEL (RL1)
CELL (X11)
CELL (X12)
CELL (X13)
ROW
LABEL (RL1)
CELL (X11)
CELL (X12)
CELL (X13)
The table is then filled in by dropping Paragraph Objects (or Image or any other document) on each Label and Cell object to provide contents for that label or cell. The twelve objects that need to be assigned contents are all at the third level of the tree (under the three Row Objects that are in turn under the one Table Object). It is fairly easy to see what needs to be done.
During the Beta period, SpHyDir II may not support all the defined table attributes. VALIGN, COLSPEC, ROWSPEC need some study. Currently SpHyDir doesn't have tools to create new Rows or cells. This is by design. It is the intent of the design that the table be expanded by selecting an exising object, clicking the second mouse button, and then choosing Create Another from the menu popup. If SpHyDir can dope out the table, it would then be able (after asking for your intention) to create all of the objects needed for another column or row. However this is not currently available.
After learning more about HTML details, it became clear that SpHyDir 1 had made a big mistake. List Points should not contain text. Semantically, a proper list is of the form:
<UL>
<LI><P>First point.</P></LI>
<LI><P>Second point.<P></LI>
</UL>
Nobody ever actually codes a list this way, so it is easy to miss. In HTML 2.0, the <LI> and <P> tags have no attributes, so they appear to be redundant. Then along comes HTML 3.0. Now proper construction of the list is "Recommended", and any tool that plans to read in HTML had better understand this implied structure because <LI> and <P> tags now have meaningful attributes. The SpHyDir 1 view that a List Point object contained the text of the implied paragraph has now become unworkable.
When SpHyDir II reads a document with lists, it creates a second level of tree indentation. The List object contains Point objects, and each Point object now contains paragraphs and stuff. You can no longer doubleclick a Point to get the Text Edit window.
Since the opportunity presented itself, a Point in a definition list has as one of its properties the term from the <DT> clause. This can be changed with the Properties Table.
This mess had to get cleared up before it was possible to do tables. A Table looks like a List. The Points of the Table are Rows which are themselves like a nested List. The Labels and Cells act like points. If this thing was going to be added, then the original List Points had to get cleared up.
This produces a generalization about Things that contain Stuff. In addition to the obvious Things (the Document, Section objects, and the three types of Lists) there are ten other Things that contain other objects: Points, Table Cells, ADDRESS, BLOCKQUOTE, DIV, FIG, FN, NOTE, BANNER, and CENTER. It did not seem to make sense to structurally distinguish DIV and BANNER (a few months ago they were merged in an earlier version of the HTML proposal). CENTER is an obsolete construct that has not been cleanly replaced. Points, Cells, Address, and BlockQuote seem to need their own objects. The rest SpHyDir II will try to collect under the category of a GROUP object. The icon for a group is a brightly colored Folder. It is an objective that Group become an option of the second mouse button popup menu for the workarea when items are marked. Choosing Group will create a new Group item and place all the marked objects in the group. The collection can then be assigned properties by assigning the property to the Group that contains in. In particular, this is the preferred way to center a collection of things.
There may be a transition during the Beta period for anyone using the previous SpHyDir 1 haphazard approach to <CENTER>. In a few weeks, SpHyDir will have dug itself out of the hole. Lacking any Group object, SpHyDir 1 assigned a Centered attribute to every object between <CENTER> and </CENTER>. The new thinking holds that if you chose to center a collection of objects, then the objects must collectively form a group with common properties. So SpHyDir will create the group for you and will use both new <DIV ALIGN=CENTER> and old <CENTER> syntax. Currently, however, CENTER may not work right.
There were two key decisions in SpHyDir II. The first was to completely reorganize key areas in order to make them ready for Object Oriented technology. The second was the choice to stick with existing Rexx and not use Object Rexx quite yet.
SpHyDir uses the services of VX-Rexx to store information. The Workarea that the user sees is a VX-Rexx container in Tree-Name view. What the user doesn't see is that the records in that container contain all the text and attributes.
SpHyDir 1 was designed around the HTML 2.0 standard. Since it was slowly moving toward formal adoption, it seemed that any design that handled 2.0 would be good enough to last for years. Then the Netscape folks captured a big share of the market and pushed the 3.0 features to the front. This added a whole bunch of attributes that would break the SpHyDir 1 design for storing information. One solution would be to build real Object Rexx classes and store the information there.
Instead, SpHyDir II ripped out a lot of ugly, bug prone logic and created a simpler (though possibly slightly less efficient) general purpose data store within the existing VX-Rexx support. Internal control structures were generalized by more agressive use of Stem variables.
SpHyDir 1 processed HTML input and generated HTML output from large SELECT/WHEN blocks. SpHyDir breaks this logic into a mass of small subroutines. The subroutine names are registered in stem tables indexed by the tag name, the attribute name, or the object type.
Rexx doesn't make it easy to initialize large syntax tables. Some tables are handled by simply listing all possible words in a character string. Rexx has some very nice WORDxxx functions that make it easy to manipulate such strings.
However, such wholesale changes will produce bugs when an isolated piece of the old code is missed during the update. A few routines handle most of the logic for creating new objects. However, initial debugging discovered that the New button in the Text Edit window was a special case that created a new paragraph without drag-and-drop or menus. That logic had to be updated also. The Beta period should identify any other special cases that slipped through the cracks.
IBM release Web Explorer Beta (5/25) Friday. It creates URL-file objects that can be dragged from WE to a disk directory to save interesting Web locations in WPS. You can drag these URL objects from WPS and drop them on SpHyDir objects to create Links, just as you previously dropped Link Manager URLs and XSpOs.
A ToolChest Window has been added. The ToolChest is a container that is intended to provide an extension or alternative to the current Toolbar. Currently, however, the ToolChest simply duplicates a subset of the Toolbar objects (though it adds descriptive captions missing from the Toolbar).
In HTML, an "entity" is a special character represented by a name preceeded by "&" and ending in ";". Because they have special significance to the syntax, "<", ">", and "&" must be represented in HTML documents as "<", ">", and "&". SpHyDir previously supported only these three entities, based on the incorrect assumption that all the other entities existed only to support ISO accented characters that would be better displayed using the international character set. However, ISO editing got put off, and a more careful examination of HTML 3.0 entities shows that they will include ISO, Greek, math, dingbats, and many other characters not found in any single code page. To allow simple editing of the "&" character, SpHyDir has to change the introducer to some funny character. Therefore, as HTML is parsed in an the leading "&" is converted to the 0x01 ("smiley face") PC character and it is converted back to "&" on output. There is no explict GUI support for entities, but as with any funny character you can enter it from the keyboard. To get a copyright symbol © hold down ALT, press the 1 key on the numeric pad, then release ALT (now you have a smiley face) then type the name "copy" and a trailing ";". Funny characters can be deleted or edited just like any other character.
Although it doesn't solve the entire problem, SpHyDir now has limited support for putting an image in a Section title. It allows one image to appear in front of the title. Worse, except for the H1 at the start of the document, you cannot create this construction with normal SpHyDir drag and drop but instead have to (ick) edit the HTML file with a plain text editor. Clearly there is room for improvement. In HTML terms, the construct looks like the following (from the PCLT home page):
<H1 >
<IMG SRC="exitsign.gif" ALIGN=MIDDLE WIDTH="218" HEIGHT="171">
Welcome to PC Lube and Tune </H1>
The <IMG> tag has to come after the <Hn> and it must have an ALIGN value (MIDDLE generally looks best). To put an image in front of the H1 tag in the document, drag the Image Object from the toolbar and drop it on the Document Object. The Image Object will be created just before the first Section object. Now drop a GIF file on the Image Object and set its ALIGN attribute to MIDDLE (or TOP or BOTTOM).
Once the Image is set up, it will be read in by SpHyDir and regenerated properly. So the worst case it to manually set it up once.
When SpHyDir was first created, some objectives were announced in the documentation. Subsequent developments have show some of these claims to be ill advised. It seems appropriate to provide users with advance warning of a change in direction. The term "SpHyDir II" is now being introduced to reflect some new ground rules that will be required to make further progress.
The biggest mistake was to promise that SpHyDir would generate HTML that would pass through a validator. Effectively, that ties it to HTML 2.0 syntax (for which there are standards) at a time when eveyone is moving rapidly to HTML 3.0 or "Netscape" extensions long before rigourous validation is possible. SpHyDir users, or at least the more vocal of them, want the extensions now.
There seems to be no limit on the number of structures that HTML can include, nor the number of attributes that will be added to HTML tags. There is no room at the top of the screen in the Toolbar or entry fields for everthing that the new language features support. If the number of features grows much larger, than simple icons will not be enough to remember what's what. Furthermore, users are asking for specialized features that may require user customization.
At the same time, HTML remains a poorly specified language. Important syntax changes occur from one version to the next. There are some differences between the "human" explanation of what is going on and the formal syntax descriptions. But the most important feature is that there is an enormous amount of invalid HTML on the Web that is accomodated because the mistakes don't prevent the browsers from displaying the correct image to users, and the final image is the only thing than seems to count. Worse, the standards documents explicitly mention common invalid constructions and urge browsers to accomodate them.
When people are first learning C, it is a common mistake to code
if (a=5) ...
when the correct statement is
if (a==5) ...
Yet no matter how common the error is, nobody would expect a C compiler to accomodate the user and automatically "correct" the program. Yet Web tools are expected, perhaps even required, to accomodate HTML syntax violations. Yet SpHyDir cannot advance to support more complicated syntax without some rigour.
Sphydir has to resolve a conflict between two goals:
<UL>
<LI>To support the common use of ordinary people.
<LI><P>To encourage "recommended" practice</P></LI>
</UL>
HTML has levels of conformance. "HTML.Recommended" holds that text should be contained in a block (P, PRE, BQ) instead of standing alone. The "<LI>text" construction is thus not "Recommended" but is widely used. There is an important difference between the human explanation of what is going on here and the semantic difference.
Books and articles on the "Complete Moron's Guide to HTML" will divide tags into those that create paragraphs breaks (P, H1..H6, CENTER, UL, OL, DL, LI, HR, etc.) and those that don't (B, I, A, IMG). BR creates a line break but not a paragraph break, though <BR><BR> might be hard to distinuish visably on most browsers. The non-rigourous explanation would be that <LI><P> seems redundant because <LI> itself generates the necessary break.
HTML is rigourously defined in a document called the "DTD". The DTD defines a %block as a P, UL, OL, DL, PRE, BQ, FORM, etc. At the Recommended level, a UL contains LI structures, and an LI contains %blocks. At the Recommended level, ordinary text is not supposed to be in the document BODY or in a list or list element. It is only supposed to appear as the contents of a P, PRE, BQ, header, etc. The DTD identifies "<LI>text" as not Recommended, but it doesn't specify what to do about it.
The DTD allows some ending tags to be omitted. The effect of a previous tag ends when a new tag is encountered that cannot be contained within the current structure. Thus "<LI> [stuff] <LI>" implies "<LI> [stuff] </LI><LI>" because one list item cannot occur within the previous list item.
Having said this, there is not one shred of usable standard to transform tolerated HTML into Recommended HTML.
<LI>Speak softly and carry a big stick</LI>
<LI><P>Speak softly and carry a big stick</P></LI>
Once the leading <P> is added, the ending </P> can be deduced because the </LI> cannot be inside the paragraph. However, no amount of DTD will every explain why the free text in the list item should have been turned into a paragraph in the first place. This is reasonable, because the reader could argue that BLOCKQUOTE is a justifiable alternative to the P tag in the case of this particular famous phrase.
SpHyDir can only accomplish its original objective if its HTML parsing is heuristic. A parse that is driven simply by syntax tables will not be quite enough. This means that SpHyDir will keep, though it ought to clean up, its current logic in the Read_HTML and Parse_Block routines.
At the same time, SpHyDir won't really work as an object oriented environment unless users can create their own objects. Sometimes people want to support new or experimental tags. Sometimes an author uses the same special construction in all documents. There have been requests, for example, for a document toolbar object of the form:
<P><A HREF= ><IMG SRC= ></A>...<A HREF= ><IMG SRC= ></A></P>
One can imagine creating this with an XSpO (an external Rexx
program dropped onto the Workarea), but it would then lose its identity. HTML 3.0 provides the solution with the CLASS attribute.
<P CLASS="TOOLBAR">
<A HREF= ><IMG SRC= ></A>...
<A HREF= ><IMG SRC= ></A>
</P>
CLASS allows most block tags to be assigned a user specified category name. CLASS definitions are intended to be hierarchical and there is some implication in the standard of one class being derived from another with inheritance.
SpHyDir can also make object distinctions based on the value of other attributes in the tag. For example, the current code distinguishes between <BR>, which is treated as part of paragraph text, and <BR CLEAR=ALL> which is treated as an document object like <HR>.
The proposal, then, is to allow new SpHyDir objects to be defined externally. The new objects would appear in the ToolChest Container window (maybe in the menu popup if it can be changed dynamically). New objects would be recognized as the HTML is read in by a new Tag name, the presence of an attribute or a special value assigned to an attribute on an existing tag, or a CLASS attribute specification. This is not designed to allow SpHyDir to assign user defined objects to raw HTML from external sources. The only claim is that SpHyDir should be able to read back HTML that it had previously written and recognize and redisplay extended constructions.
Simple user objects could be defined based on the fundamental attributes that SpHyDir currently potentially assigns to each object (an icon, caption, text content, name, variable name, variable value, etc.). Objects could also be define that contain other objects from a certain set of types. In its simplest version, this will be used to create "macros". For example, a SECTION-like object could be created named CHAPTER. It would be managed like an ordinary SECTION, but it would generate something more complicated:
<DIV CLASS="CHAPTER" CLEAR="ALL">
<HR SIZE=6>
<H1 ALIGN="CENTER">This is the ordinary Section title</H1>
[ordinary section contents]
</DIV>
The second time through, SpHyDir II will recognize its own construction by the DIV tag with the CHAPTER class. It will match up the </DIV> ender to determine the scope. It then has to suck up and discard the boilerplate tags (the HR SIZE=6 in this case). Although there is a HR object in the SpHyDir vocabulary, this particular HR is part of the formal expansion of a CHAPTER object and should not generate a separate object. Except in the HTML that it generates, the CHAPTER object would then behave in every way as if it were the existing SECTION object.
Now comes the trickey part. Programmers should instantly recognize that, in object oriented lingo, this example creates the CHAPTER class as a subclass of the SECTION class inheriting SECTION's methods (mostly the way to edit titles and its behavior as a container) but overriding a few methods (HTML parsing and generation). It seems likely that many new objects will have behavior exactly modelled on Paragraph, Section, or Image objects. SpHyDir might add a few new built-in objects on which new things can be constructed. However, full implementation of the concept will require that everything be rewitten in Object Rexx, and that will be disruptive enough to be put off until it is unavoidable.
SpHyDir has not dependencies on other programs, through it is distributed with a few utilities (GBM, RCS) that have proven useful. However, the new release of GOSERVE (2.30) is getting too slick to ignore. Since GOSERVE uses Rexx, and SpHyDir is written in Rexx, a closer relationship should be worked out between the two programs.
Currently, when SpHyDir wants to test a document, it calls Web Explorer or Netscape with its local file name. However, hyperlinks from this first document will not work if they are designed for another server and have fully qualified URL's or if the document contains a BASE statement with the production server's name. This made support for BASE a long requested but seemingly impossible objective.
Any machine running SpHyDir can probably run GOSERVE in the background. GOSERVE can be told to serve documents out of the HTMLLIB directory tree. The final trick is to override the name of the production server machine with a pointer to the local loopback IP address. This can be accomplished by adding an entry in the \TCPIP\ETC\HOSTS file with values like:
127.0.0.1 sphydir
127.0.0.1 pclt.cis.yale.edu
If TCP/IP is set to check the HOSTS file first, then with this entry any URL for "http://pclt.cis.yale.edu/pclt/sphydir/status.htm" will be redirected to the GOSERVE running on the local machine, which will then fetch pclt/sphydir/status.htm out of the HTMLLIB directory. BASE will then work, and all the URL's that point back to PCLT work. Of course, to FTP files to the real PCLT server I need to use a different alias for that machine (or temporarily change the HOSTS file).
GOSERVE also provides an environment to test FORMS and CGI-like programming. Some days it seems like an HTML form displayed on the Web Explorer window would be a more flexible way to choose options and configure SpHyDir or document objects than popup VX-Rexx windows.
In any event, future releases of SpHyDir may move toward almost requiring that GOSERVE and either Web Explorer or seamless Netscape be running.
Document Objects now have a popup menu. Click the second mouse button to display Open, Settings, Insert, Create Another, Mark, Delete, etc. Insert provides a quick way to add a new Paragraph, Image, Point, or List without going to the Toolbar. You can also Insert a Horizontal Rule for which there is no tool (though you have been able to generate it with ALT-H for quite some time). Create Another creates a second object like the current object (say another paragraph or point). Mark duplicates the old Alt-L. Delete duplicates the old Ctrl-D. Currently you can only Open the contents of the object (duplicates current DoubleClick function). Settings is under construction.
SpHyDir now refreshes the title of a subdocument as it reads the parent file in. Thus if you change the title of a subdocument, the pointer to it will be changed the next time that the parent (or the entire tree) is processed.
The File-Test (F5) operation now dynamically communicates to running copies of popular browsers. SpHyDir first generates a temporary copy of the document in TEMPDOC.HTM in the HTMLLIB root directory. In previous releases it then started Web Explorer to view the document. Now this is the last alternative. Before launching a new WE, SpHyDir now tries two things:
SpHyDir first attempts to establish a DDE link with a running copy of Netscape. For this to be useful, Netscape should be running in seamless WINOS2 mode. SpHyDir passes Netscape a request to display the Tempdoc file.
If Netscape is not found, then SpHyDir looks through the windows on the screen for a running version of Web Explorer. If one is found and it is already viewing an older version of TEMPDOC, then SpHyDir sends it a F5 to refresh the document. If it is running and viewing something else, SpHyDir enters the name and path of TEMPDOC in its entry area and sends an Enter key.
Netscape has known problems running seamless on OS/2. Fortunately, the most serious issues involve user interaction with the menus. By controlling Netscape from SpHyDir, interaction is minimized. However, the code to control both Netscape and WE is new and may require some fine tuning.
The design of a <BR> object finally became clear when a user reported by EMail that he was having trouble with Netscape extensions. Normally, an Image either appears by itself or is aligned with a single line of text. The Netscape ALIGN=LEFT (which SpHyDir has "supported" from the start) causes multiple lines of text to flow through the space left to the right of the image. Unfortunately, this option doesn't just flow text. it also "sucks up" any following images. The Netscapism for breaking this pattern and starting the next line under the image is to add a <BR CLEAR="ALL"> tag.
I have previously noted the need for a <BR> object to separate buttons in a form. The problem ws to distinguish when reading in the HTML a <BR> acting as an object from a <BR> in the middle of a paragraph that acts instead like a character or as a CR/LF pair. Although SpHyDir has tried to avoid non-standard HTML, it seems very compact to declare that <BR CLEAR="ALL"> would be recognized as the Object and plain <BR> as the character.
Browsers should ignore attributes they don't understand. The only problem occurs if you try to validate HTML that contains Netscape extensions with a validator looking for HTML 2.0. If you don't want <BR CLEAR="ALL">, then don't create the object. Incidentally, to create such a tag, position at the next object and press Alt-B. The BR Object will be positioned in front of the currently selected object. For the most part, the BR and HR objects are very similar. Neither has a specific icon at the moment.
Backup of HTML files has been a serious issue. First, SpHyDir cannot be subject to terribly aggressive testing between weekly releases. If a syntax error occurs, SpHyDir can abort in the middle of writing a file. If SpHyDir encounters HTML that it doesn't recognize, information can be lost. The previous strategy of saving the old copy of the file in the BACKUP directory addressed only part of the problem. SpHyDir now introduces the heavy artillery.
For other text files, the most powerful free software system is the RCS version control package from Unix. When fully exploited, it allows several people to check out and work on files in a shared library. It remembers changes to the file and who made the changes. It is possible to reconstruct older versions of the data if something goes wrong.
Use of RCS is optional. If it is not used, SpHyDir continues to make a copy of the previous version of the file in the BACKUP subdirectory.
For each original data file, RCS builds a control file that keeps a copy of its current contents and the information needed to recover any previous versions. The first version is "1.1" and each time the file is changed a new version number is generated.
By default, RCS will archive f:\pclt\sphydir\status.htm in a control file named f:\pclt\sphydir\RCS\status.htmv. That is, it stores files in the RCS subdirectory of the path where the data file is found, and it adds the suffix character "v" to the file type.
Some future version of SpHyDir may maintain enough variables for a document to allow individual decisions about what to manage under RCS. Currently, however, if you use RCS at all you have to use it as the backup for the entire library. SpHyDir is triggered to use it if there is an RCS subdirectory under the HTMLLIB root. On my machine, "f:\pclt" is the the HTMLIB for PCLT articles, so SpHyDir looks for "f:\pclt\RCS" to decide to use RCS, for all of the documents in all of the directories under f:\pclt.
Unexpectedly, RCS will not create the needed subdirectory automatically, and it will not quite work correctly if the subdirectory doesn't exist. A future version of SpHyDir may fix this, once I develop more confidence about the best arrangement. For now, manually create RCS subdirectories throughout your HTMLLIB tree if you intend to use this facility. If you forget, RCS will create the control file in the same directory as the data file and you can create the RCS subdirectory and move the file to it later on. This is not a problem on HPFS volumes, but it could present an issue on FAT directories where "HTMV" might get truncated to "HTM". RCS backup is probably not a good idea for SpHyDir users with only FAT directories.
Before generating new HTML, SpHyDir backs up the previous version of a file by issuing the command:
ci -xv -l -m"backup" -t-"backup" xxxx.htm(l)
This runs CI.EXE (Check In) of the RCS version control system. The -m and -t parameters provide dummy log messages so the program does not prompt for a description of changes or of the file. The -l parameter checks the file back out immediately (so that it remains in the library and can be rewritten). The -xv adds a "v" letter on the end of the file type (htmv or htmlv) to provide the file type of the RCS control file.
SpHyDir does not check the PATH for a copy of the RCS executables. It tries to use RCS based on the existence of a directory in HTMLLIB. It is the user's responsibility to install RCS on the OS/2 system before using this facility. Unzip the RCS567PC.ZIP distribution file and copy the contents of the BIN32 subdirectory to a library in your PATH. RCS is now available on the same FTP file servers as SpHyDir itself.
SpHyDir is using RCS to provide a super safe backup, not to do true version control. There is no provision to check out locked files, or to check in and unlock a final version. However, the user can build real version control outside SpHyDir by issuing RCS commands before or after running SpHyDir to provide real parameters and version numbers.
RCS is a serious system with some heavy duty manuals. SpHyDir's only direction function is to call CI.EXE to generate the backup. Comparing different versions of a file, or recovering old versions from the backup, requires direct use of the other RCS commands. RTFM. If RCS appears to be too complicated, feel free to continue to use the old SpHyDir BACKUP.
Use of RCS was requested in E-mail by a user several weeks ago. Initially it seemed like a really bad idea. The problem is that RCS and all the other version control systems have this view of tracking changes by line. Since SpHyDir only puts a CR/LF line break at the end of paragraphs, it appears to have really, really long lines. Change one word, and RCS regards the entire paragraph as changed. Flowing the text into 80 character lines would not make much difference, because any change in one section will flow changes onto all the subsequent lines of the paragraph. However, there are no better version control mechanisms, and after some consideration the long lines do not appear to be unworkable.
Before reporting any bugs, please realize that the version being "checked in" to RCS is not the version on the screen. What is being checked in is the old version on disk from before the current edit session. So if you read a file in, make a ton of changes, press F2 to save it, and look at the Console window, do not be surprised it it reads:
F:\PCLT\sphydir\RCS/STATUS.HTMv <-- F:\PCLT\sphydir\STATUS.HTM
file is unchanged; reverting to previous revision 1.3
It is not saying that there are no changes in the current version, just that there were no changes in the old version that you are just about to replace.
RCS is a Unix utility that has been ported to the OS/2 environment using the EMX package. EMX is a version of the GNU development tools and the GCC complier. These tools are normally found in the /unix subdirectory of the OS/2 files at ftp.cdrom.com and ftp-os2.nmsu.edu. The minimum files needed are the EXM runtime DLL library (emxrt.zip) and the RCS distribution (rcs567pc.zip). They will also be added to the SpHyDir FTP directory.
This facility is currently more "experimental" than the rest of SpHyDir, so its output is not captured. The CI command writes to "standard output" and VX-Rexx captures that file and displays it in the VX-Rexx Console window. If the service seems to work well, this output will be supressed in a future release. Meanwhile, the Console window will have to be manually closed when SpHyDir ends.
Copyright 1995 PCLT -- SpHyDir Web Document Manager -- H. Gilbert
May be distributed with SpHyDir program
This document generated by SpHyDir, another fine product of PC Lube and Tune.