



DiscWorld
Aaron Timbrell probes into the software directory
It's quite a large DiscWorld this month, which reflects the size of the software directory. As per usual we have the latest PD releases and the latest RISC OS games. Also this issue we are giving away a free copy of Sleuth, the OCR package.
Sleuth
Sleuth is an OCR (Optical Character Recognition) package for RISC OS. To put it simply what Sleuth does is "read" a scanned paper document and convert this into ASCII text that can be edited or reformatted in a word processor or DTP package. This can be much much quicker that reading a document by hand and typing it in yourself.
How Sleuth works
This is a brief description of the way Sleuth works.
Training
Before it can recognise letters the OCR program must be taught their shapes. The main problems are that there is a lot of variation for each letter because of different fonts, sizes and of course various defects introduced by the printing and scanning processes. The training program for Sleuth (not supplied) incorporates a sophisticated algorithm which starts with an outline font and mimics the processes of printing, faxing and scanning to make many examples of each letter. The training program uses about 400,000 examples in all. Each of these shapes is converted into a list of numbers (a "feature vector") which represents the important aspects of the shape. As each feature vector uses about 100 bytes it would require about 40Mb to store this information directly so it is "summarised" in a special way.
Finding lines of text
The first thing Sleuth does is find all the black shapes in the image. Some large and very small shapes are weeded out at this stage.
Next Sleuth estimates the skew in the image and removes it. It does not rotate the shapes (which would introduce further distortion) but moves them so that lines are horizontal and gutters (the space between columns) are vertical. Then the shapes are gradually merged together to form lines. Care is taken to avoid jumping over graphics and gutters or joining dropped capitals onto a line. Lines are then grouped into blocks and the blocks ordered.
The program finds and orders the lines before reading them. This means that it can start outputting text fairly quickly. However, since it knows nothing about the identities of the shapes at this stage, it does sometimes make mistakes that could be cured if more information was available to it. Later versions of Sleuth improve accuracy here, but that does mean losing the ability to edit while OCRing.
Character recognition
During reading shapes are extracted from the image, converted into feature vectors and compared with information about known shapes acquired during training. The result is a shortlist of possible letters, with scores representing how close the matches are, and also information about the style (bold/italic/serif) of the letter.
Although character recognition is at the heart of any OCR program it is only one part of a complex system. Letters are often joined to their neighbours, and sometimes split into two or more parts, so these problems must be dealt with before character recognition can take place. Some characters (eg p,P,c and C) can only be identified once the scale and position is known from the rest of the line. Others (eg I,l,1,e and c) can often only be correctly identified by using information about the likely identities of other shapes in the same word.
Reading a line of text
A shortlist of possibilities is obtained for each shape in the line and the best recognised letters used to find the baseline and scale of the text and so remove letters from the shortlists if they have the wrong size or position. Next word breaks are found and each word is visited in turn. If letters can be chosen from the shortlists so the word spellchecks without any letters being poorly recognised the word is done. Here's how the word "excellent" from a low quality scan might look like at this stage. There are no split or joined letters, but the correct interpretation is far from obvious.

If the word is not recognised at the first attempt it is examined more closely. Suspicious parts are identified, and these are cut into smaller pieces at likely places. Then the program considers various ways in which the pieces can be put together to make new possibilities for the shapes in the word. Each time a new set of pieces is combined to make a shape, the shape must be recognised. This process can be slow, and is the main reason why the program takes longer on poor quality images. Here is part of a word which has been cut into pieces:
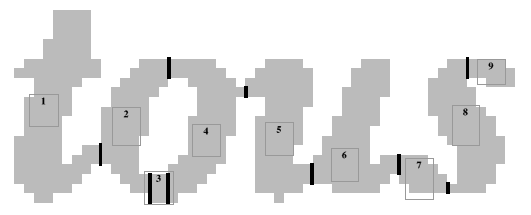
The black lines represent where the cuts would be made by the program to try and find the letters in the image.
The pieces in this shape would probably be combined so that 1 was on its own as a 't', 2 and 3 would be combined to make a reasonable 'c', then 4 would be added to make the 'o', 4 and 5 could make an italic 'n', 5 and 6 both make bad i's, but together make a good 'u', it is possible that 6, 7 and 8 could make a bad 'w', but that would be discarded for 7, 8 and 9 to be combined to make the 's'.
Paragraphs
The program checks for paragraph breaks after reading each line. Sometimes it has to read a couple of lines of the next paragraph before it can be sure there is a break, which is why you may (for example) see it is reading line 4 when it outputs the first one-line paragraph. When a paragraph break is detected, the text size, line spacing, justification are estimated and the program tries to find the main style (bold/italic/serif) of the paragraph and then find any words which do not fit this style. It does not try to identify style changes within words.
Finally the paragraph text and formatting information are sent to the text editor where you can then change them.
The complete DiscWorld line up
Files
Support materials for Brian Pickards file transfer series.
FreeCiv
The complete RISC OS version of FreeCiv.
Games
All the games from this issues games world column all ported by Peter Naulls.
Mustek
Samples images and two videos from the Mustek DV3000.
PD
All the latest PD, shareware and freeware releases from the PD column.
PowerBase
The latest version of Derek Haslams Database application.
Sleuth1
The complete version of Sleuth the OCR package.
Sleuth3
A demonstration version of Sleuth3.
Tanx
The latest version of Neil Whites game as discussed in his article.
ToolBox
The latest 26/32 bit neutral system components, required if you want to run a lot of new software releases on 26bit machines (ie. anything that isn't an Iyonix).
Aaron Timbrell