



Sleuth
Dave Wilcox gets out his magnifying glass
Sleuth is an OCR package which has been around for some time in one shape or form. It is written by Graham Jones and was initially sold by Beebug. I am pleased to say it has recently been salvaged by Dave Holden in the form of APDL/ProAction, I say pleased because I believe this is currently THE OCR package for the Acorn environment. The package supplied for review was version 3.07, however APDL are intending to maintain and improve Sleuth based upon customer feedback, which is very good news indeed for Sleuth users.
The program now comes on a CD and is accompanied by a copy of Sleuth2 and some example files. Sleuth2 is included for speed reasons. In certain circumstances it is considerably quicker than version 3.
On the disc is an installer which enables you to put a copy of the software onto your hard drive after entry of identification details.
Prior to use it is advisable to read the accompanying manual and to go through the configuration to make the program suitable for your needs. This initial action can save you considerable time in the editing stages later on.
With the software installed I am reviewing using a 287Mhz StrongARM machine with RISC-OS4.02 and 64Mb of RAM. The scanner is a SCSI Epson GT5000 with the appropriate TWAIN driver from Dave Pilling.
As with any software different people find different ways of best achieving their desired results, I have saturation tested this product by scanning and OCR'ing to date the first two volumes of the Archive magazine, hopefully for inclusion on the Archive CD next year. As a result of this I have found the best way for me to achieve my desired results, however there are always tweaks which can be done which are overlooked, so the old adage applies - "Read the flippin' manual...." I will take you through 'My Way' and then describe other features of the package, hopefully this will give a good overview of the potential available here.
I did it my way.....
The program works by OCR'ing a sprite from a scan. So bearing in mind the Archive book is A5, it is possible to scan two pages to A4. I started off this way but eventually decided that manipulating the sprite and then OCR'ing was fairly time consuming. I got into the routine of scanning by article, one A5 page at a time. This may seem more time consuming but by the time the editing has been carried out and you get into a routine it is not too bad. The other problem is that the text is in two columns with occasional graphics, so each page has to be classed as unique, and consequently needs setting for each scan.
First things first - configuration of the package. I needed the resultant text output to be suitable for dropping into TechWriter. This deals with paragraphs slightly different from the likes of impression in that only one
The next step is to scan your page in preview mode. The main reason for this is to ensure that the page is as near as possible set square. Sleuth is capable of dealing with up to two degrees of skew on a page, I am sure I have probably gotten away with slightly more than this, but work to two degrees maximum. Once your preview page is loaded to screen you need to tell Sleuth where the text zones are. These zones work very much like multi column text in your DTP package and display the flow of the text within the document. Each zone is a rectangular box which is dragged to enclose your desired section of text, each zone is tweakable by corner or side to achieve the optimum settings. When multi zones are drawn the bottom right of the first is linked to the top left of the next and so on to show the overall flow of the resulting text. Once you are happy with the page selection you need to consider the type of zone you have set. The default selected zone is a red box, unselected zones go grey. A zone can be set to be ignored, it shows as red with a cross, a single column zone - green, and a table zone - blue.
An ignore zone is useful to stop Sleuth trying to read text within graphics or the like. The single column option is useful for wide spaced text or sections with a lot of white space as in program code, the option forces the zone to be treated as a single column of text. As I say, for program coding this again cuts down considerably on the editing phase. The table zone will enclose the code deemed to be a table in quotes and comma separate each item. I have found that these usually require considerable search and replace to get right in the editing phase, but it is still quicker than having to sit and type in the table.
Once you are happy with the zones select 'Scan and OCR' from the menu and away you go, the page is scanned, and the program goes straight into the OCR phase. The manual states that a percentage accuracy under 95% is not acceptable and should be redone. I have found this not to be so, the percentage is altered by unknown words, i.e. not in the inbuilt dictionary or user dictionary, this can be a considerable amount dependant upon topic, and a quick click on the word invariably shows it is correct. There are the usual error areas which I think have to be expected due to the design of letters and numbers, i.e. 0,O, i,I,l,L,1 etc.... Sometimes you will also get a consistent pattern for certain characters which you eventually get to recognise without effort, an example common in my usage has been question mark, full stop (?.) instead of the numeral two (2). A lot of this can be due to scanning resolution. You will be surprised if you scan a page at the highest available resolution and look for print marks and smears and the like, there are loads that the eye normally ignores or doesn't see.
Once you have gone through the editing you simply save the resultant file out to disc. Here you have three options, text, RTF, or native OCR format. I have only used text output to date, but have played with the RTF which seems to carry the basic styling over quite well.
Well thats how I use the program to obtain my text, then as each page comes out I simply join the text in StrongED and save each article ready to compile in TechWriter, each article being a separate chapter. Graphics are simply scanned as graphics and dropped into the text at or near the original point.
Loading and Configuration
Once installed to hard drive a double click on the application will install it to the right of the iconbar with its own icon, from here we have the main iconbar menu
The only option I am really interested in here is the preferences, I think the others are fairly self explanatory.
Preferences
This window has two versions, output and input as can be seen below
Output Preferences
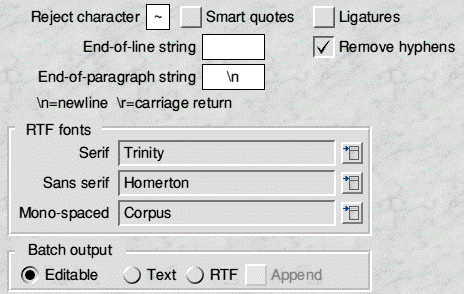
Here you can see my configuration, the end-of-line string is one space (obviously invisible) and the end-of-paragraph is one newline (\n) and the remove hyphens radio button is selected. The reject character can be set to anything you like, usually an unused or rarely used character, if Sleuth comes across something it doesn't recognise it will replace it with this character. Smart quotes enables the recognition of smart quotes, and the ligatures enables recognition of the characters '�' and '�'. As can be seen it is also possible to do batch processing of sprites (upto 75). With batch processing it is possible to set up a zones template and use the same zones on each page, nice when possible, otherwise it is a simple one column zone.
Input Preferences
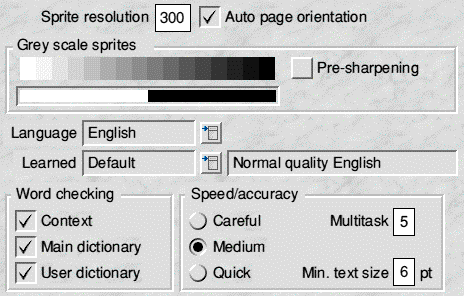
As you can see input options are also fairly concise. If you are using the TWAIN driver the resolution is taken from the settings within TWAIN. The greyscale enables the conversion of greyscale sprites to monotone, this is required as Sleuth works on black text on a white background. There are four languages known to Sleuth - German, English, French and Dutch. the learned files are the same but with FAX and Numerical as additions. The other settings are the defaults and are fairly self explanatory.
Once configured and the icon clicked upon, the main window opens. A little bit insignificant really.
Main Window
from here we have the main business menu:Main Menu
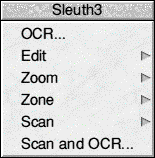
Here you can see the main options for working. Your first action will be scan, as I have said this links in with the TWAIN driver and will allow you to select your scanner and the usual settings and options for it. I always go for the preview option first, I have found by use that this will cut down on wasted scanning and OCR'ing. Once your preview screen is loaded:

You can see that I am working on the two left hand columns. It is necessary to set the zones for these columns, in this case just normal default zones.

As you can just make out the left column is deselected and is shown in grey, the right column is selected and is in red and the yellow line shows the frame flow, as you would expect. Going back to the main menu over this window you now need to click on 'Scan and OCR'. Again the TWAIN driver will take over and it will be necessary to click on scan here also. The program starts to scan and then translate the picture
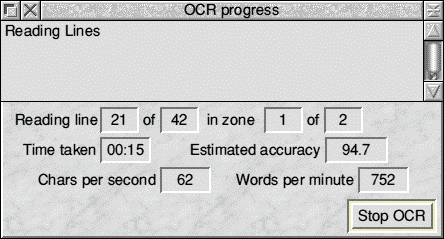
As it progresses it tries to display information to keep you up to date with what is going on, as you can see quite thorough really. Once finished you will have two windows presented to you.
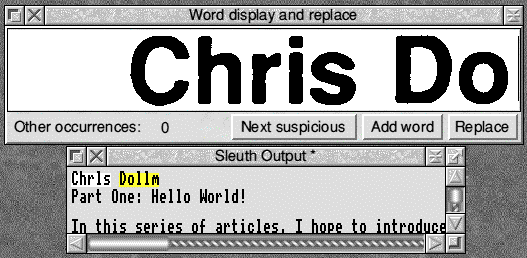
The top window shows the actual text of the scan and the bottom window shows the translation, in this case the text size for the subheading causes a minor problem, the 'i' in Chris is mistaken for an 'l' (ell) and the 'm' is mistaken for 'in', very easy to rectify though. As you progress the screen moves through the text bringing up the next error. If there are multiple occurrences of a misspelt word all can be replaced at the same time by clicking replace. The word can also be added to the user dictionary for future use. From experience be careful what you put in here as the word or character could be deemed to be correct in the wrong circumstances.

As you can see from this section most of the spelling queries are in fact correct and simply need clicking on as in order. Eventually the frame above shows the edited text. This can now be saved as your operational text file. Very nice........

Conclusion
I think with this it is very easy to fall into the trap of thinking 'blimey thats not a very good result' all those errors etc... But try timing yourself to type in a chunk of text and then try to OCR the same text and compare the results, I know which I prefer. If you have a lot to do your speed and accuracy will also improve as you go. I have to say I do like this program and the added bonus is it saves me having to use a PC to do the job, okay it costs a bit, but in the Acorn World I think we have become accustomed to having to pay for the luxury of using our chosen environment.
Product details
| Product: | Sleuth OCR |
| Supplier: | APDL |
| Price: | Sleuth 3 £49 (add £2 for overseas postage) |
| Sleuth 2 £29 (add £2 for overseas postage) | |
| Upgrade from Sleuth 2 to Sleuth 3 £25 (add £2 for overseas postage) | |
| Address: | APDL, 39 Knighton Park Road, Sydenham, London, SE26 5RN |
| Tel: | 0208 778 2659 |
| WWW: | www.apdl.co.uk |
| E-mail: | info@apdl.co.uk |
David Wilcox