



Great awk
Gavin Wraith introduces the often-overlooked awk programming language.
Awk is named after its creators, Alfred V. Aho, Peter J. Weinberger and Brian W. Kernighan, who designed it, in 1977, initially as a text processing tool. In 1985 it was extended to a more or less complete programming language, and was distributed with Unix System V Release 3.1. Since then there have been a number of developments, most notably the POSIX-compliant GNU implementation, gawk, by the FSF (Free Software Foundation), and Michael Brennan's mawk, which is the version provided on this CD-ROM (see below for installation instructions).
Of the two, Mawk is smaller and faster; whereas gawk works by constructing and then interpreting a parse-tree of the program, mawk works (like Java) by compiling the program into bytecodes for a virtual machine, and then running the virtual machine. This makes it appropriate as a basis for an awk compiler.
Installation

Copy the application mawk from the CD-ROM to somewhere on your hard disc, or run it straight from the archive. Double-clicking on the mawk application icon on your hard disc will put two icons on the icon bar (!RunAwk and !ShowAwk - see screen shot), and will create a new file type (&187) called awk.
Why use awk?
Suppose you were to have a text file called Food_bill containing, say, the following:
Breakfast Milk 0.50 Bread 0.70 Croissants 1.20 Marmalade 1.00 Lunch Wine 3.85 Pate 1.50 Baguette 1.05 Salad 1.10 Dinner Rice 1.30 Chicken 3.80 Vegetables 2.00 Cheesecake 1.85 That is all.
Would your text editor be clever enough to work out what you spent on lunch? Granted, this is a simple example, more easily done in the head or with paper and pencil, but imagine a bill with thousands of items. You could load the file into a spreadsheet, and then add up the appropriate cells. It would be harder work, but feasible, to write a Basic program to do the job.
The right tool for the job, however, is awk. To explain why, I'll show you how to write an awk program to calculate the lunch cost in the example above.
Using your favourite text editor (Edit, StrongED, Zap or whatever) create a text file containing the lines:
# Lunch cost /Lunch/, /Dinner/ { x += $2 } END { print "Lunch cost ",x }Save this somewhere as a file called Lunch_cost, with file type awk (&187).
If you can't be bothered to do this, I have in best Blue Peter tradition one that I prepared earlier, and also a copy of the input file Food_bill.
Double-click on Lunch_Cost's icon. This will produce a message to the effect that Lunch_Cost is now the 'current awk program'.
Drag the text file Food_bill onto the !Runawk icon on the icon bar. You should get a taskwindow displaying the answer:
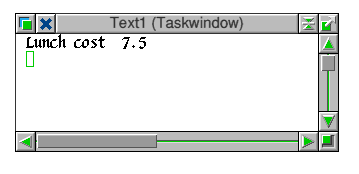
In general, double-clicking on a file of type awk will make it the current awk program. Dragging a file onto the !RunAwk icon will run the current awk program using the file as input. The output will be displayed in a Taskwindow, from which it can be saved in the usual way.
Pattern-action statements
To see how it all works, let us look at the awk program Lunch_Cost in more detail. The first line is a comment. The # symbol is exactly analogous to REM in Basic. All the text from # to the end of the line is ignored by awk. The next two lines are pattern-action statements. The 'pattern' is the part before the braces (curly brackets), and the 'action' is the part inside the braces. Pattern-action statements have the general form:
<pattern> { <action> }
So the second line has the pattern /Lunch/,/Dinner/ and the third line has the pattern END. Patterns can be thought of as tests which are applied to each line of text in turn. The /Lunch/,/Dinner/ pattern switches on as soon as a line containing the word Lunch is encountered and switches off as soon as a line containing the word Dinner is encountered. The END pattern switches on only after all the input has been read in; there is also a corresponding BEGIN pattern which only holds before any input has been read in.
The action { x += $2 } can be read as 'increase the value in the variable x by the numerical value of the second word in the line'. Note that variables do not have to be declared, or given an initial value. By default, the initial value of a numeric variable is 0.
The variables $1, $2, ... $n hold the values (either as strings or numbers) of the first, second, ... nth words in the line. The variable $0 holds the value of the whole line.
The action { print "Lunch cost ",x } is self-explanatory, I hope.
All statements of an awk program, disregarding comments, must either be pattern-action statements, or function definitions (see the next example). It is permissible to omit either the pattern part or the action part - but not both - in a pattern-action statement. If the pattern part is omitted, the action is applied to all lines of input. If the action is omitted it is taken to be { print $0 }.
So, in the minimal case, a very short awk program could be the single symbol 1, the pattern that is always true. This awk program simply has the effect of outputting the input text, but it does do something useful, because it strips out control codes other than newlines; useful for transforming MS-DOS-type text files into Unix/RISC OS-type text files. The equally short awk program, 0, outputs nothing.
Example 2
Here is another very short awk program, to demonstrate the use of functions and of associative arrays. Arguments in round brackets, like f(x), indicate that f() is a function. Arguments in square brackets, like f[x], indicate that f[] is an array. Its effect is to strip out duplicate lines from a text and it, too is included on the CD-ROM.
# no duplicate lines
{ if (!again[$0]++) line[++count] = $0 }
END { display(line,count) }
function display(l,c ,i)
{ for (i = 1; i <= c; i++ ) print l[i] }
The first line is, once again, a comment. The second and third lines are pattern-action statements; there is no pattern specified in the second line, so awk applies the action to all input lines, while the third only applies after all the input has been read. The remaining two lines define a function called display(). Line four declares the function, with two formal parameters, l and c, and a local variable i. Line five gives the body of the function inside braces - I'll come to this in a moment.
The action in line two is an if statement. The condition (in brackets) is the expression
!again[$0]++. There's a lot packed into that small fragment of code, so let's take it step by step.
The ! symbol is the negation operator, broadly equivalent to NOT in Basic. It turns 0 to 1 and all non-zero values to 0 - an if statement treats 0 as false and all other values as true.
We have an array called again[], indexed by the text of the lines being read in, represented by $0. Because the array is indexed by text rather than by numbers, it's called an associative array. If you've only used Basic or C before, and have never come across associative arrays, you'll need to pause for a moment to get to grips with the concept.
Traditional arrays, familiar to anyone who's done any Basic programming, are indexed by numbers. If I write array[6], you'll know that I mean the sixth element of the array (or seventh, if I'm starting from zero). Associative arrays, also known as hashes, work differently - they're basically a set of key/value pairs, so if I write array["cat"] I mean the value associated with the key 'cat'. I'll go into more detail about how they're used later. For the moment, all you need to know is that the array again[] is a set of numerical values, indexed by keys which are the text of the individual lines in the file.
Finally, the ++ postfix operator indicates that after the value of again[$0] has been evaluated, its value should be increased by 1. The first time that a particular line of text is read in, the variable again[$0] will be undefined and so treated as 0, and every time it is read in subsequently it will have a positive integer value.
Putting all of these together, you can see that the if statement will only be executed if the value of the array again[$0] is zero (because the condition is negated), and that this will only happen the first time a line is encountered in a file. Therefore, the line of code:
line[++count] = $0
will only be executed the first time that a particular line of text is read in. This statement defines a (non-associative) array line[] of strings, indexed by a numeric variable count which is augmented by 1 (by the prefix ++) before it is evaluated. The effect is that line[n] is the nth different line of text to be read in.
When all the input text has been read in, the variable count holds the number of elements in the array line[], and the function display() is called with arguments line[] and count.
The last two lines define the function, the body of which is a standard for loop. The syntax is precisely that of C, and probably requires no further comment.
Using arrays
From the preceding example, you will note that arrays in awk are very different from arrays in traditional languages like Basic or Fortran. There are no DIM statements needed to declare them. Their sizes are not fixed; if you need more components, you just go ahead and use them. More fundamentally, arrays in awk can be indexed by strings as well as by numbers. The elements of such an array have no preferred ordering. You can iterate over arrays with statements of the form:
for (x in f) { ... }
you can test for the existence of array components with statements of the form:
if (x in f) { ... }
and you can delete array components with statements like:
delete f[x]
Further reading
On the Internet:
- The awk Usenet group comp.lang.awk.
- comp.lang.awk's Frequently Asked Questions at http://www.faqs.org/faqs/computer-lang/awk/faq/, which contains a great deal of useful information.
- If you use StrongED you might be interested in http://www.wraith.u-net.com/awkfy.html, and on the same site there's some comment on the educational virtues of awk.
Three books deserve special mention:
- The AWK Programming Language by Aho, Kernighan and Weinberger, published by Addison-Wesley (ISBN 0-201-07981-X) This book, like Kernighan and Ritchie's The C Programming Language, is a classic. It is both a tutorial, packed with illuminating and surprising examples, and a reference work. It is a bit out of date concerning POSIX standards, but it is a very good read, with no flab.
- Effective AWK Programming by Arnold Robbins, published by SSC (http://www.ssc.com/) is also freely available in the form of web pages as The GNU AWK User's Guide (also here).
- sed & awk by Dale Dougherty and Arnold Robbins, published by O'Reilly (ASBN 1-56592-225-5). Covering not just awk itself but also its stream-editing cousin sed, this is a typical O'Reilly book, technical but readable, co-written by the maintainer of gawk, and with the engraving of an animal (the slender loris) on the cover. O'Reilly has released The sed & awk Pocket Reference (a smaller companion reference book) this month, but I haven't seen it available in the UK yet.
Summary
I have described how to use awk programs from the RISC OS desktop, and have given two small examples to give a taste of awk as a programming language. In later articles I will look at some of the issues involved in adapting software, originally developed for a command-line environment like Unix, to a graphical user interface like RISC OS. That brings us to how awk programs interact with files and the operating system, and to RISC OS-specific extensions. I will show how to use awk for small databases, using other software, such as GnuPlot, Easiwriter and web browsers, as display engines.
Gavin Wraith (gavin@wraith.u-net.com)


