



Using Powerbase — Part 6
by Derek Haslam
This month's article is more of a miscellany than previous ones. As promised in Article 5 we will begin by looking further into the use of script commands. This is followed by a trick for making a CSV file generate a working database from scratch. Finally a method is described of making the !MusicBase database developed in Articles 1, 2 and 3 add up the times for the tracks on each record.
The latest version of Powerbase, PB915SH, has some bug-fixes (one of which is quite important) and a few new minor features and you should upgrade your copy. Also present is the documentation, brought up to date and presented in HTML format for easy reading along with this article, as well as Impression, Ovation Pro and PDF formats.
More scripting
For this example we will use the !Elements database from EXAMP. How can we create a group of text-files which includes data about all 103 chemical elements with the elements divided up according to the contents of the Group (GP) field, i.e. Group 1 elements in their own file, likewise Group 2 elements and so on? There are two approaches to this problem:
- Include in the script a !QUERY command for each group.
- Use a loop to read the required search formulae from a list.
!SCRIPT [QUIET]
(QUIET is shown in square brackets because it is optional. If omitted Powerbase asks for confirmation before executing the script. If you use the QUIET option to bypass the confirmation message leave the square brackets out.) The next line selects the fields to include in the report by means of a !SELECTION command. We want the Name, Symbol, Atomic number and Group and we may specify these in two ways:
- By placing the tags of the fields in a comma-separated list:
!SELECTION NAME,SYM,Z,GP
- By highlighting the fields with ADJUST, saving the resulting selection as a file in the PrintRes directory (which is the default location) then simply using the filename as a parameter to the !SELECTION command, e.g. if the file is called Fields The command will be:
!SELECTION Fields
!DESTINATION File
Now for the !QUERY commands. The first of these (to report on Group 1 elements) is:
!QUERY GP=1
This should be followed by 10 similar lines in which GP is matched with 2,3,4,5,6,7,0,T,A,L. Finally, we tidy up by clearing the field selection and restoring the default print options:
!SELECTION
!PRINTOPTS
[!SCRIPT END]
Save the script under a suitable name then open the !Elements database and drop the file on the record window. After 11 brief bursts of hourglass activity the database's PrintJobs directory will be found to contain 11 text files named according to the search formulae. Loading them into an editor will confirm that each does indeed contain the elements specified, the Group field having been included in the selection to make this easy to see. We can refine this script in several ways, but first we'll look at the second method of creating these 11 files: the use of a loop.
Start by deleting the files from PrintJobs. If the directory has been closed you can easily do this by going to Print=>Show jobs done=>Print jobs from the main menu and choosing Delete all. Also delete all the !QUERY lines from the previous script.
Looping in a Powerbase script is accomplished by placing the commands to be repeated between !LOOP and !ENDLOOP commands like this:
!LOOP
!QUERY...
!ENDLOOP
But what is the parameter for !QUERY and how does the loop "know" when to terminate? Each time around the loop we want to read a search formula from a list and this is done by following !QUERY with the word READ Note that READ is a parameter, not a command, and therefore has no initial "!". We still haven't told the !QUERY command what it is to read from and this involves the script command !DATA, the syntax of which is:
!DATA GP=1,GP=2,GP=3...etc.
One important point: the !DATA line must come before the !LOOP command so be sure to insert it there. Dropping this much shorter script file onto the record window produces exactly the same set of text files as the first script. The loop terminates automatically when the !DATA list is exhausted. (There are other ways of terminating loops and the reader who is especially interested in this command is referred to the chapter on Script files in the manual.)
Now for a few refinements. The entries on the GP field are constrained by a validation table and the second column of the table contains expanded names for the groups. (Place the caret in the field and click on Table to display the validation table.) We can make the reports include these expanded names instead of single numerals and letters by placing !EXPAND ON in either of the scripts. In the first script it must come before any of the !QUERY lines; in the second it must come before the loop is entered. Secondly, we can choose our own filenames for the saved reports instead of accepting the defaults. To make a !QUERY command use a supplied filename the name is placed before the search formula and separated from it by a backslash. For instance, if you wanted the report for Group 1 to be called AlkMetals and that for Group 7 to be called Halogens the corresponding !QUERY commands (in the first script) would be:
!QUERY AlkMetals\GP=1
!QUERY Halogens\GP=7
This assumes you want the files saved in PrintJobs, but you may save the files elsewhere by supplying a full pathname instead of just a leaf-name.
The second script can also be made to save under user-defined filenames by having the !QUERY command READ those also, i.e. the command inside the loop becomes:
!QUERY READ\READ
which will cause a filename to be read and then a search formula each time the loop is executed. The filenames must appear in the !DATA line in the correct places, each name being followed by a comma and then the search formula associated with it. The only disadvantage of this approach is that you will have to provide some sort of name for every report.
Now here's an interesting variant of the above exercise. Delete the line !DESTINATION File so that the destination defaults to Window. (If there's any doubt about this, replace the line with !DESTINATION Window.) If you run the scripts again you will see each report in turn appear in a window, but no files are saved. You know that you can save a window report from the menu which opens when you click MENU over the report window. How can we do this from a script? It can be done by following each !QUERY command with a !SAVE command. Thus:
!QUERY GP=7
!SAVE
Why would you want to do this? Well, window reports can use colour, can be sorted, can be used for rapid retrieval of the records listed (by double-clicking). Moreover, when saved in PrintJobs they can be subsequently reloaded with all these features retained provided they are loaded by choosing them from the Print=>Show jobs done=>Print jobs submenu.
By this time you've probably guessed that any parameter to a script command can be replaced by the word READ and the real parameter supplied in a !DATA statement. This can be rather useful. Suppose a script makes a field selection, sets up print options, and executes a query - all from files, e.g.
!SELECTION Fields!PRINTOPTS Options
!QUERY Report (where "Report" is the name of a saved Query file in PrintRes).
This could be rewritten as:
!DATA Fields,Options,Report
!SELECTION READ
!PRINTOPTS READ
!QUERY READ
The script could then be made to use a different set of filenames as parameters by merely changing the !DATA line.
A nice final touch to these scripts is to make the PrintJobs directory open automatically when the reports are finished. This can be done by adding the line:
!OBEY Filer_OpenDir <Dbase$Dir>.PrintJobs
The !OBEY command can execute lines which might appear in an Obey file. e.g. you could delete a file with !OBEY Delete <filename>. Script files are capable of far more operations than those covered here and in Article 5, but since the area of greatest use is generating reports the discussion has been limited to that.
Databases from CSV files
While you have !Elements loaded try the following:
- From the main menu choose Export CSV file=>Options, which opens the CSV options window:
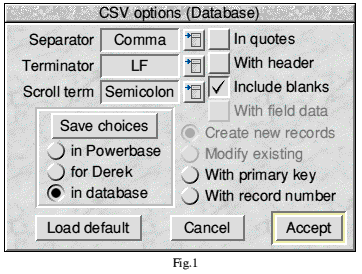
- Select the option buttons In quotes, With header and With field data.
- Select a number of fields (the selection used in the script exercises will do nicely), choose Export CSV file=>Export, enter a search formula if you wish and drag the file icon to a directory window.
- Now close !Elements (without quitting Powerbase) and drop your saved CSV file onto the iconbar icon. The CSV import window opens.
- Click Import, then the default action button on the following message window.
How is it done? Load the CSV file into your editor and look at the first line. This is a "header" line preceding any actual record data. CSV files with headers are quite common; we used one in Article 5 when preparing a file to mail-merge with EasiWriter. Usually, though, the header merely identifies the fields to which the data belongs. If you hadn't selected the With field data button you would have produced a CSV file with just the field tags in the header line but instead you have a header containing much more information. Let's examine it in detail.
There are several segments separated by commas. Each segment is in quotes and has four parts separated from each other by the "|" character. These are, respectively:
- A number specifying the type of field. 2, for instance, indicates an uppercase field. For further information examine the file !Powerbase.Resources.ValStrings. Information on the fieldtypes and type numbers for any open database can be found by choosing Utilities=>Database details=>Field data from the iconbar menu.
- A number specifying the maximum field length.
- The field descriptor
- The field tag
!MusicBase revisited
This database is on the CD in the zip file MUSIC. If you experiment with the last column of the scrollable list field you will find that no checking is performed to ensure that what you enter is a valid time in minutes and seconds and whatever character you enter to separate minutes from seconds remains unchanged when you type Return. Fig.3 illustrates this lack of validation and reformatting:
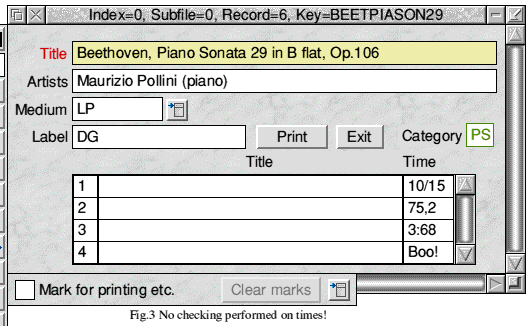
The problem is that the whole scrollable list is treated as a single field (admittedly with some rather special properties) and there is no provision for making individual columns acquire the characteristics of other types of field such as Time, Data, Uppercase etc. We can, however, get around these problems by means of a User function. User functions were discussed in Article 4 and you may recall that they are associated with two types of Computed field: Calculated and Composite. Nothing was said about attaching a user function to a scrollable list and, indeed, you can't do it! There is, however, no reason why a user function which serves a Computed field should not also stick its nose into the doings of another field - such as a scrollable list. That's what we're going to do here. A new field of Composite type will be added to the database to hold the sum of the times for the individual tracks and the user function associated with this field will also take care of the validation and formatting of times in the scrollable list's final column.
Before we go any further there's an important preliminary. When you enter data into a field which is validated as a time, Powerbase assumes the first number to be hours. If, for instance, you entered 5 into a Time field and immediately typed Return, your entry would be reformatted as 05:00:00. If your entry had a second numeric part it would be interpreted as minutes, e.g. 5/12 would be reformatted as 05:12:00. Only if you typed another non-numeral and a third numeric part would non-zero seconds appear, e.g. 5,12,8 would be reformatted as 05:12:08. For the times in MusicBase we want the first number entered to be interpreted as seconds, and the next as minutes. This can be achieved by means of a configuration option called TimeFirst. Use your editor to examine the file !Powerbase.Resources.Config and you will find, towards the end of the file, the line TimeFirst H where H means "hours". This determines the default behaviour as described above. Replacing H by S changes the interpretation to what we require in the present case. The next entry in Config is FullTime YES, which means that times are always formatted to include all of hours, minutes and seconds. By changing YES to NO any time less than one hour will be displayed as minutes and seconds only. Rather than changing Powerbase's own Config file it is best to give MusicBase a "private" file containing just the lines:
TimeFirst S
FullTime NO
saving it as Config inside !MusicBase.
The next step is to rebuild MusicBase with an additional field to hold the total time. The general procedure was covered in Article 3 when we added the Category field, but it's worth stating again:
- Choose Utilities=>Rebuild database from the iconbar menu.
- Drag the file icon to a suitable directory window. If you want to call the new database MusicBase you must use a different directory from that which contains the old database.
- Add the new field, which must be of Composite type and have a length of at least 8 characters to allow for total timings of an hour or more..
- Choose Quit design from the main menu.
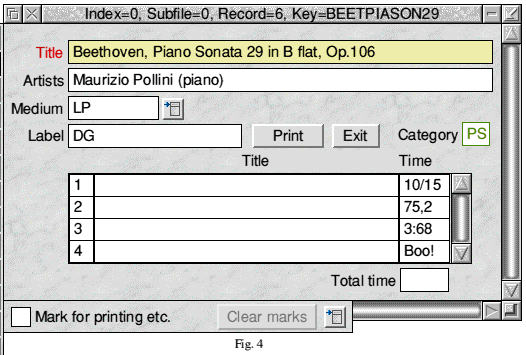
If you now place the caret anywhere in the Time column of the scrollable list and type Return, you should find that all the times in the list reformat to mm:ss and the total appears in the new field. That is, if the times are valid. Try entering things like 1/63 and 70,15 and see what happens.
If you are familiar with Basic programming you might like to examine ADDTIMES to see how the effect is achieved. The function makes use of several of Powerbase's own functions and procedures, notably FNcheck_time which checks that the minutes and seconds entered fall within the permitted range and then formats the string using the correct separator, FNseconds which converts such a time string to seconds, and FNtime which does the opposite. It will work no matter how many rows the scrollable list contains.
In conclusion
This mini-series is now approaching its end. The next article will probably be the last and will deal with the various choices which are available to determine how Powerbase works, and also how non-standard features may be added. If any readers feel that there are areas which haven't been covered and should be, please email me by clicking on my name below. I will either answer by email or, if there is sufficient material, incorporate the replies in a further article.