



The RISCWorld MakeHTML program
Aaron Timbrell explains the RISCWorld MakeHTML program
Editing RISC World is a very enjoyable job. However what isn't enjoyable is the grind of making the HTML files from the articles sent in by authors. I receive articles in a number of formats, including Impression, Ovation, TechWriter and plain text. Taking each article apart by hand and converting it to HTML is very time consuming, I know, RISC World was done that way when I started editing it. By coincidence Dave Holden was having a similar problem converting printed manuals to HTML format. While we were chatting about this the answer presented itself, automatic HTML converters.
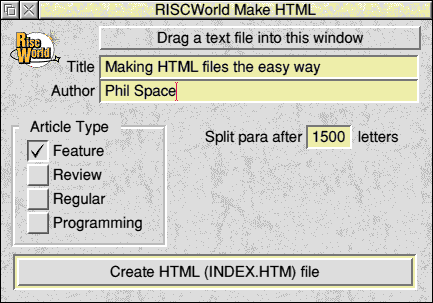
The MakeHTML program in its current state
Automatic Conversion
Although we both had a similar problem, the solutions we decided to adopt were slightly different. Dave Holden's problem was taking complete manuals, sometimes with hundreds of pages, and making HTML versions of them. The articles I was dealing with were much shorter. So I decided that since about half the articles I get sent were in plain text format I would work from that point of view. Articles arriving in formats other than plain text could easily be converted to text before being processed by the program.
Since all RISC World articles have basically the same layout, header and footer I decided to store these as stand alone files inside the application. Also since I am generating HTML to a fixed template I didn't go to the trouble of making the application configurable. With this in mind I started work.
Conversion problems
A quick mock up program was produced, this processed a text file to produce simple a simple HTML file using the following process:
- Load the text file to be converted
- Load a default HTML header from a directory inside the application
- Scan through the text file adding Parapgraph (<P>) tags
- Add a default HTML footer (loaded from a directory inside the application)
- Save the resulting HTML file
Of course the result didn't work as intended. The questions is why? The answer is quite simple. When I make an HTML file from a text file I apply a series of rules to produce the finished result. What I needed to do was to work out what rules I used, and then to write a program that did exactly the same.
Constructing rules
To make matters easier I decided that the first rules to be written would be those that covered each single character in the original text. Each character would need to be scanned and some would need to be replaced by strings. For example, a number of programming articles contain either the greater than (>) or less than (<) symbols. However in HTML these are used to contain the "mark-up" commands. So the program needs to replace these with the correct HTML versions, which are of course > and <
So I wrote a subroutine that could be pointed to a block of text and would scan each character one at a time using a set of rules. If the character being read had no rules attached to it then it would be copied directly from the original text file to the new HTML file. If however the character had some rules attached (as in the case of <) then the rule would be applied and the "correct" HTML would be inserted in the new file instead.
Having done this another problem presented itself. Although the program would scan a text file written by me and produce the correct result, when I tried it on some older articles submitted by authors it fell over and generated rubbish. Strangely enough on examining the text files I found out that even though a text file is just alphanumeric characters there is still a lot of potential for people to construct them differently. As a simple example when writing a text file for RISC World I don't underline headers as I know they will be larger when converted to HTML. However many people do so you could end up with the following in the converted HTML
This is the header
------------------
Which means the offending underlining has to be removed. Since the purpose of the exercise was to automate the process the program had to understand these underlines and ignore them. I then discovered that some people use equals signs for underlines and had to build rules for these as well.
Another problem concerns carriage returns. Often when writing a text file its easy to insert carriage returns before the end of lines to keep the line lengths down, so the program needs to be aware of this. Just hunting for carriage returns in the text makes a real mess, so instead the program needs to look for full stops followed by a carriage return, or in the case of one author a full stop, then a space, then a carriage return!
This results in a better HTML file. However not all sentences end with a full stop, they might end with a question mark for example. So I had to build in more rules to detect the ends of paragraphs. After a few days work the resulting program worked correctly for 90% of the articles I was sent. So as far as I am concerned its finished enough to be used, and of course shown to RISC World readers.
The final rules
Shown below are a simplified version of the process the program uses to scan a text file. Since the whole thing is written in BASIC it's very easy to take apart so that you can see the rules for individual characters.
- Load the text file to be converted
- Load a default HTML header
- Start at the beginning of the text file
- Find the first end of sentence followed by a carriage return
- IF the length of the text up to the first carriage return is greater than 40 THEN
- Examine this to see if its a heading
- IF this starts with a numeric character THEN it is probably part of a list so treat it as a short paragraph
- IF this starts with a Tab or a Bullet point THEN it is probably part of a list so treat it as a short paragraph
- IF we have not processed this text THEN turn it into a heading reading each character in turn and applying rules to it as required.
- ELSE
- This must be a paragraph
- Examine each character in turn to apply any required rules until end of paragraph is reached
- Move to the next character after the carriage return we found in step 4
- REPEAT UNTIL we have read all the text file
- Add a default HTML footer (loaded from a directory inside the application)
- Save the resulting HTML file
These are roughly the rules used by the program. A copy of the !MakeHTML program is in the software directory on this CD. Feel free to take it apart and see how it works, or indeed to improve it. The copy here has a couple of errors/ommisions in its rules for each character, I know what they are but haven't bothered fixing them as yet. It would be quite easy to alter the program to generate different HTML based on what you need, so feel free to have a fiddle with it. If anyone does improve it I wouldn't mind having a copy! Oh and if anyone bothers fixing the silly bug relating to full stops let me know as well!
Next time
Next issue I will be handing this column over to Dave Holden who will explain his programs. Unlike mine, which just deals with raw text files, his programs can convert both Ovation and Impression documents into HTML and can be easy altered to cope with different styles in the original document.
Aaron Timbrell