1.ユニシス特許に抵触しないGIF画像のデコード
1.ユニシス特許に抵触しないGIF画像のデコード
![]()
(2000/03/31初版)
(2000/04/01改訂)
(2000/04/02改訂)
(2000/04/05改訂)
| そもそも何が問題なのか? | ||||||||||||||
| 最近、GIFのライセンス問題が再び世間を混乱の渦に巻き込んでいる。初めて騒がれるようになったのは記憶が正しければ1995年の事だったと思うが、このところの騒ぎの大きさと言ったら当時の比ではあるまい。 一体何があったのだろうか? ちなみに、このときの騒動をご存じ無い方もかなりの割合でいらっしゃるのでは無いかと思う。それもそのはず、当時のユニシス側の対応としては、商用のソフトウェアにのみライセンス料を要求し、フリーソフトにはそれを課さないと言う方針だったからである。従って企業側には頭の痛い問題に違いはなかっただろうが、個人でフリーソフトを出している人間にとっては、あくまで対岸の火事でしか無かったわけである。故に、広く一般に騒がれることもなく、ライセンス問題はいったん収束するかにも見えた。 しかし、今後のフリーソフト界の発展及び活性化を願う身としては、現在の状況が決して良いものだとは思えない。特許の利用に対してライセンス料を支払う事は当然の義務ではあるのだが、そのやり方や対象の選択に対してユニシスに強い不信感を抱いているのは、何も私だけではあるまい。ただし、だからと言ってGIFフォーマットを利用しないことによって、この問題を解決しようという態度がベストだとも思えない。はっきり言わせてもらうが、それは非常に後ろ向きなやり方である。クリエイターたる者、常に新たな可能性を模索し続けなければなるまい。無いなら作る、壊れたら直す、使えないのなら何とかする・・・のが我々開発系の人間の責務では無かろうか?従って、今回もユニシスの要求に対し素直に従う事も無ければ、GIFの利用を止めるような事もしない。あくまで法に則った上で、GIFを利用する道を模索する。道は一本では無いのだ。 お世辞にも将来性の期待される画像フォーマットとは言い難いGIFではあるが、まだまだ現役であり今後も様々な場面で利用されることは多いはずである。それがフリーソフトにおいて使用できないと言うのでは、PC業界全体で見ても大きなマイナスになるとしか考えられない。そもそもGIFというフォーマットは米CompuServeにおいて、ライセンスフリーを謳い文句に策定されたフォーマットである。ライセンスフリー故に大きく広まり、発展を遂げてきた。それを後から湧いて出てきた特許によって根こそぎ強奪するようなやり方がまかり通ってしまうのは、サブマリン特許が認められてしまうアメリカならではの事情ってヤツなんだろうとつくづく感じる。権利期間も先進国の中では唯一、出願日からではなく、公開日からとなっている問題点もあり、今後しばらくは悩まされることになるだろう。少なくともGIFが衰退する方が先なのは間違いなさそうだ。 前述したようにGIFフォーマット自体はライセンスフリーであり、その規則に従う限り自由に使用することができる。問題なのはその圧縮法であるLZWだ。 |
||||||||||||||
| 問題の特許とは? | ||||||||||||||
| さて、LZW法の利用に問題があることは分かったが、問題の特許とは一体どんなものなのだろうか?その点について少しご紹介したいと思う。 ユニシスはLZW法に関して2つの特許と幾つかの公開特許を有している。その内容も圧縮に関わる物や復元に関する物など多岐に渡り、正にLZW包囲網と言わんばかりの様相を呈している。中でも基本となる特許である「データ伸長法および装置ならびにデータ圧縮伸長法および装置」(特許番号:第2610084号)はLZW法を利用する上での大きな障壁となっている。興味のある方は、実際に読んでみるのも良いだろう。 さてこの特許だが、ほとんどそのままLZWの圧縮・復元理論を特許にしてしまったような構成になっており、なるほど普通にGIF展開などをコーディングすれば見事に抵触してしまうように出来ている。敵ながら天晴れと言う他はあるまい。 この様に、特許として認められているのは圧縮と復元に関する部分であるため、生成されたGIF画像やTIFF画像そのものには何ら問題は発生しない。問題はそれをどうやって作成し、どうやって閲覧するか、その点のみにある。 |
||||||||||||||
| LZW法とは? | ||||||||||||||
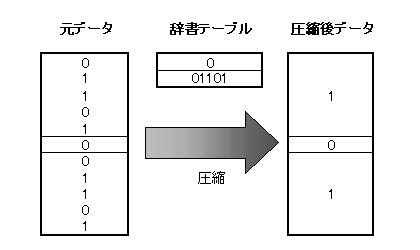
| LZWとは、Lempel, Ziv,
Welchの3人によって考案された圧縮方法であり、いわゆる辞書方式と呼ばれる圧縮法の一つである。 ここで辞書テーブルを利用した圧縮について少し説明しよう。 テーブルNo.0=「0」 としてやることにより、圧縮後のデータは「101」という3ビットに収まってしまう。これがテーブル型圧縮の基本である。
しかしながら、辞書テーブルを利用している圧縮法というのは他にも基本となるLZ法や、ZIP・PNG等にも採用されているLZ77法などがあり、テーブルを利用しているというだけでは問題の特許に触れることは無い。 では、ユニシスの特許(あるいはLZW法)には一体どんな特許性があるのだろうか? それはひとえに辞書テーブルの扱いにある。一つは辞書テーブルが時々刻々と動的に変化する点、もう一つは辞書テーブルに追加するデータ列の選択手法にLZW法ならではの特徴が見られる。これによって、パターンが途中で変化する場合でも柔軟に対応することができ、高圧縮率と高速性を見事なバランスで両立させている。 詳しい説明はここでは省略させていただくが、興味があればGIFの仕様書やその手の参考文献などがあるので、そちらを参照されたい。 |
||||||||||||||
| 目的 | ||||||||||||||
| 最近ではGIFの代替フォーマットとしてPNG等も普及の兆しを見せつつあり、いずれ何らかのフォーマットにより完全にGIFが置き換えられていく事も考えられる。故に、これから作成される画像に関してはPNGなりJPEGなり他のフォーマットを使用することでGIFの利用を(個人的に)避ける事も可能である。つまり、敢えてこの時期にGIFエンコーダーを作成する必要性は薄い。 対するGIFデコーダの方はと言えば、これまでに蓄積された大量のGIF画像が存在する上、中には(私の様に)GIFを使い続ける人もいるだろう。要するに、デコーダの方は使わないと言う訳にはいかないのである。 そこで、今回はユニシスの特許に触れないLZW復号化手法を考案すること、及びライセンスフリーのGIFデコーダを開発する(のをお手伝いする(^^;)事を目的としたいと思う。 |
||||||||||||||
| 特許を回避するためには? | ||||||||||||||
| まず、ユニシスのLZW展開に関する当該特許を解析してみる事にしよう。当然、請求項はチェックしなくてはならない。請求項とは特許の生命線とも言うべき権利範囲を記した物であり、そこに記載されている物が特許の全てを物語っていると言っても過言ではない。その請求項であるが、全部で20項目ある。そのうち第1,第8,第15および第18項は独立したクレームであり、残りの16項目はそれぞれいずれかのサブクレームとなっている。 つまりは、この第1,第8,第15および第18項を満たさない方法でGIFの展開を行えば、全く問題ないという事が言える。そして、それぞれの請求項を見てみると第15項および第18項の方は「データ圧縮伸長」に関する発明であり、今回の検討に直接影響を及ぼす事はない。また、第8項に関しては「データ伸長装置」についての発明であり、これもまた該当しない。従って、今回問題になるなのは「データ伸長方法」を記した第1項のみという事になる。 さて、問題の第1クレームにはどんな事が書いてあるのだろうか。残念ながらここに全てを記すわけにはいかないが、概要だけ簡単に説明する事にしよう。 要するに
という段階を含む復元方法である、と書かれている。これから一つでも外れていれば特許には引っかからないわけだが、だからと言って「扱うのはデータ文字列ではなく画像データだからノープロブレム!」という訳にも行かないだろう。当然、パテントに一休さん的”とんち”は通用しないし、実際問題として実施例の中でそういった応用例も明記されている。 そこでふと気になったのは辞書テーブルである。このクレームの中では何度も「前記メモリ」という単語が出てくる。たとえば『対応する符号信号を用いて、前記メモリから検索可能な形態で、前記メモリにストアすること~』というくだりがあるが、ここで言っている前記メモリとは、正確には「前記符号信号に対応するデータ文字ストリングをストアするメモリ」の事を指している。何のことは無い。要するに、上で説明した辞書テーブルそのものである。LZW法も辞書テーブルを利用する圧縮法の一つであるため、クレーム中に辞書テーブルの用法が出てくるのも当然と言えば当然なのであるが、ここで一つの疑問は浮かんでこないだろうか? そう、本当に辞書テーブルは必要なのだろうか? LZW法はもともと辞書テーブルを利用することを前提に作られた圧縮法であり、また特許もそれに準じて書かれている。ならば辞書テーブルを利用しないでLZW法と同じ事を実現してしまえば、それはもうLZW法ではなく、特許にも触れることはない。 実際、これから述べる方法を用いれば、上の段階の内3,5,6については該当しなくなる。依然として1,2,4には該当しているわけだが、残ったこれらの段階に一体何の特許性があるというのだろうか? |
||||||||||||||
| 辞書テーブルを使用しないLZW復号化 | ||||||||||||||
| しかし、辞書テーブル利用を前提としたLZW法において辞書テーブルを全く使わずに復号を行うことは可能なのだろうか。その点について検証してみたい。 まず、普通にテーブルを利用した場合では圧縮後の符号化データがそのままテーブルの番号を指し示しており、指定されたテーブルの内容をそのまま出力結果とする事ができる。これに対してテーブルを利用しない場合では、符号化データを受け取った後に、それが一体どんなデータ列を指し示しているのかを逐次求めなければならない。 ここまで聞いて不思議に思う人も多いだろう。テーブルが無いのに、本来テーブルに格納されているべきデータ列を取得出来るとは思えないかも知れない。
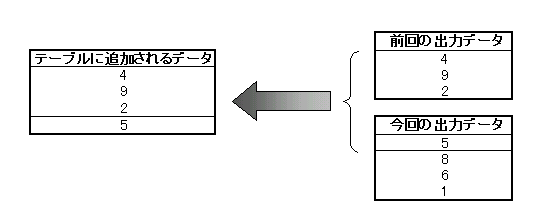
問題なのは符号化コードが(色数-1)より大きくなった場合。この場合は必ず2個以上のデータが格納されている。LZW法では展開時に符号化コードに対応するデータ列を出力すると、必ず何らかのデータ列をテーブルに書き加える事になっている。このとき書き込まれるデータは「前回の出力結果」に「今回の出力結果」の先頭1個を付け足した物である。
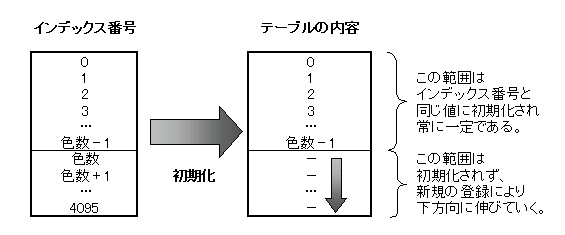
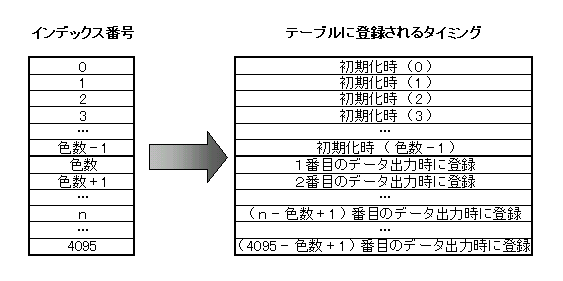
したがって、前回の出力結果が無い一番最初(0番目)の出力時以外は、必ずデータ出力後にテーブルへ上記のデータ列が加えられる。つまり、5番目のデータを出力した後には、テーブルには5個のデータが新しく加わっている事になる。 では、これをテーブルを使わないで求めようとするとどうなるか?まず、色数が8色の場合で考えてみる。突然14という符号化データが現れた。テーブルへの書き込みはいっさい行っていない(と言うよりテーブルそのものが存在しない)ので、14が一体何を指すのか分からない。しかし、ここで一つの手がかりはある。それは、求めるべきデータ列は本来「7番目のデータを出力する際にテーブルに登録されるはずだった物」である、という事である。何故かというと、テーブルは初期化時に(色数-1)である7まで埋められており、それ以後は最初の一回を除いて毎回一個づつ増えていくからである。
ここまで分かってしまえば、しめたもの。上の説明で行くと、ここでテーブルに書き込まれるはずであったデータは ”(6番目の出力データ列)+(7番目の出力データ列の先頭1個のデータ)” である事も自ずと分かってしまう。 さあ、後一息。今度はその(6番目の出力データ列)と(7番目の出力データ列の先頭1個のデータ)を求めてみよう。もう既に6番目と7番目の出力を行っている訳で、そのデータを保存しておけば良いのだが、テーブルを使わないと決めた以上それは出来ない相談である。従って二度手間になるのを承知で、再び6番目と7番目の出力データを求める。 この様に、符号化コードが(色数-1)より大きい場合は、 ”{(符号化コード-色数)の出力データ列}+{(符号化コード-色数+1)の出力データ列の先頭1個}” が求めるべき出力結果になる。ここで(符号化コード-色数)番目や(符号化コード-色数+1)番目の符号化コードも(色数-1)より大きかった場合は、さらにそれを求めるために同じ事を繰り返す必要がある。そして、いずれ符号化コードが(色数-1)以下になるとデータが確定し、一番上層の符号化コードまで確定した段階で完全な出力データが得られる。 少しでもプログラムを囓ったことのある方なら説明するまでもないだろうが、上のような処理は再帰関数を用いれば非常に簡潔に記述する事ができる。ただし、ネストする数によっては非常に重い処理になってしまう事も想像に難くない。しかし、テーブルを使わずしてLZW復号化を実現する以上、ある程度のリスクは覚悟しなければならないのは当然である。もし、これが本家のLZWより高速であるのならば、私が特許を書いている所だ。ただ利点が全く無いというわけでもなく、テーブルへの書き込みが発生しないことから、メモリアクセス(主にライト動作)の低減やテーブルに使用されるべき僅かなメモリを節約できるというメリットも存在する。特に圧縮率の非常に悪い画像などを展開させた場合は、本家を上回る速度が出るのではないかと考えられる。 さて、これで完璧・・・と言いたいところではあるのだが、やらなければならない仕事はもう一つ残っている。今までの例では符号化コードに対するテーブルの内容は既に決定されている事を暗黙の了解として話を進めてきた。実際、殆どの場合はその通りなのだが、極希に未だ未登録のテーブル番号を指定してくる符号化コードの存在があることも事実である。この様な場合はどうするのかと言うと、一つ前の符号化コードから得られた出力データとその出力データの先頭1個を連結した物を今回の出力データとし、それをそのままテーブルにも登録する。何故そのような処理を行うのかについては、話が長くなるので割愛させて戴くが、この様な場合についてもテーブルを使用しない場合の処理を考えなくてはならない。 ”{(一つ前の符号化コード)の出力データ列}+{(一つ前の符号化コード)の出力データ列の先頭1個}” である。これも再帰を伴う処理になるのだが、内容的には先ほどと変わらないため説明は省略させていただく。 以上の処理を各符号化コードに対して順番に実行していくと、完全な復元データを得ることが出来る。参考までに、処理の流れをC言語風に記してみた。このサンプルでは、画像の色数が8色、圧縮後の符号化コードサイズを1バイト固定、とした場合の例である。配列lzw[]に圧縮データを格納しておくと、配列out[]に展開されたデータが返ってくるという寸法だ。分かり易さを重視したために(出力が8ビットアラインされている等)おかしな所も多々あるが、大体こんな感じで書いていけばLZWの展開が行えるだろう。 char lzw[256] =
{2,4,8,7,5,10,13,12,0,9}; //元の圧縮データ なお余談ではあるが、なぜここでお得意のF-BASIC386による記述を行っていないのかと言うと、アルゴリズムの関係上、再帰をスマートに表現するにはC言語の方が適当であったという理由に他ならない。プラットフォームに依存しないと言う意味でも好都合であろう。ちなみにF-BASIC386でも書けなくは無いのだが、到底実用的な速度にはならないだろう。 |
||||||||||||||
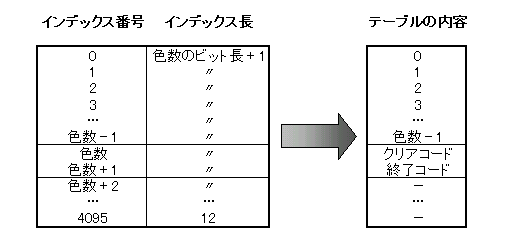
| 実際にGIFの展開を行う | ||||||||||||||
| これまでの例で示した物はあくまでLZW復元の為の説明であり、実際にGIF展開を行う場合にはGIF特有の点も考慮しなくてはならない。ここではその辺りについて説明する。 まず、GIFがLZWに対して拡張を行っている点としては、クリアコードと終了コードの存在が挙げられる。それぞれ辞書テーブルの特定の番号に割り当てられており、その番号を指し示す符号化コードが現れた場合は、定められた処理を行う必要がある。 さらに、GIFでは入力されてくる符号化コードのビット長が可変であるという特徴がある。少しでもビットを切りつめて、出来るだけたくさんのデータを詰め込もうという事なのだろうが、本理論においては過去の符号化コードを利用しなくてはならない場面が頻繁に出現するため、これにも注意を要する。なお、このビット長は最大でも12である。 また、テーブルのエントリ数は最大4095までと決められている。これを超えた場合はテーブルへのデータ登録を行わないようにしなければいけないのだが、本理論では元々テーブルへの書き込みなど行っていないので、無視してかまわない。
以上の様な点に気を付けてコーディングすれば、完全なGIFデコーダが作成出来ると思うのだが、いかんせん発案者本人である私も未だ作成していない為、本当に出来るのかどうか定かではない。<理論的に出来ないはずは無いのだが・・・。 |
||||||||||||||
| 本当に大丈夫なのか? | ||||||||||||||
| 以上のように、ユニシスの特許に触れずにLZWの展開プログラムを作成することは可能であると思われる。しかしながら、これはあくまで私の考えであって、ユニシス側がこれを見てどう捉えるかは定かではない。ただ、快く思わないことだけは確かだろう。 また、仮にユニシスの特許問題を回避できたとしても他の特許に触れる可能性がゼロであるとは言えない。少なくとも現時点では、日本国内においてユニシスが取得している他の特許に引っかかることは無いと思うが、他社がそれを所持しているかも知れない。 更に言えば、この程度の理論はプログラムを囓ったことのある人間ならば誰にでも思いつく方法であるという点も、考慮しなければなるまい。プログラマとしても未熟であり、ましてや法律関係では全くの素人である私の理論である。事情通の人が聞いたなら一笑に付されて終わり・・・なんて事も無いとは言えない。いや、ひょっとしたら同じ方法、あるいはもっと良い方法が既に存在しているかも知れないのだ。 |
||||||||||||||
| GIFエンコード | ||||||||||||||
| これまではGIFのデコードの話しかしてこなかったが、最後にエンコードについても少しだけ触れておこう。実はエンコードに関してもテーブルを使わずに行うことは可能である。ただし、これから圧縮しようとしているデータ列がテーブル内に存在しているかどうかをチェックする必要がある関係上、処理は非常に重くなることが想像される。 今回のアルゴリズムでは辞書テーブル内の特定のエントリを返す関数を利用しているが、エンコードの場合は「特定」ではなく、全てのテーブルの中から同じ物があるかどうかのチェックを行わなくてはならない。従って、実際の処理としては今までに作成されているであろうエントリを全て一つづつ抜き出し、圧縮しようとしているデータ列と同じであるかを調べることになる。さらには、「辞書テーブル内の特定のエントリ」を求める方法も展開時に比べて面倒な処理になることが予想される。まぁ壁は高い方が良いという考えの持ち主であれば、挑戦してみるのも悪くはないだろう。 ところで、実はGIFエンコードに関してはとっておきの裏技がある。その方法は非常に単純明快であり、しかも100%ユニシスの特許に抵触しない。 その方法を説明する前に、まずLZWのテーブル構造を思い出して欲しい。0~(色数-1)番目のテーブルはあらかじめ初期化されている、とご説明したのを覚えているだろうか?しかも、ここに格納されている値はテーブル番号のそれと全く同一の物である。また、テーブルへの書き込みは常に「追加」であり。既に存在しているテーブルの内容が書き換えられることはない。仮に初期化コードが現れてテーブルがクリアされたとしても、「初期化」であるから0~(色数-1)のテーブルの値はまたしてもテーブル番号と同一の値に設定される。 つまるところ、何時いかなる時であっても0~(色数-1)のテーブルの値はテーブル番号と同じなのである。ここまで説明すれば分かっていただけるだろうか。そう、GIFエンコード時には元データと同じ値をそのまま圧縮コードとして書き込んでいけばいいのである。それを受け取ったデコーダ側でもそれをそのまま出力する事になるので、どんなデコーダであっても表示可能だ。無論、テーブルなど要らない。 ただ、元データと出力結果が同じと言うことはつまり、全く圧縮になっていないのである。しかも、GIF特有のクリアコードと終了コードの存在により、必ず圧縮前よりも大きなサイズになってしまう。したがって、どうしてもGIFでなければならない理由が無い限りは、この方式によるエンコーダーは利用しない方が良いだろう。 |
||||||||||||||
| 最後に | ||||||||||||||
| さて、今回のGIF問題解決に関する考察は如何だっただろうか? 内容的に若干難しい所はあったかも知れないが、ユニシスのライセンス問題に対する一つの指針になったのではないかと思う。 もっとも、しつこいようではあるがこれで本当に大丈夫なのかどうか実際の所私にも良く分かっていない。もし、もっといい方法がある、或いはこの方法では駄目だとか、何か情報をお持ちの方は是非ご連絡して欲しい。 |
||||||||||||||
| お願い | ||||||||||||||
| もし、この方法を利用したGIFデコーダを公開される場合は、下記までご連絡していただきたい。別にライセンス料を取ろうとかそう言う事では無いのだが、私の知らないところで問題が発生するのを予防したいというのがその目的である。 |
||||||||||||||
| 免責事項 | ||||||||||||||
| この方式によるデコーダを作成する事によって生じる、いかなる不利益や損害に対しても私は一切の責任を負わないこととする。 |
||||||||||||||
|
連絡先 | |||||||||||||
| DJ☆Uchi [PEB04756@nifty.com] | ||||||||||||||
| 有限会社Uchi 渉外管理室 |
@nifty ID:PEB04756