"Modular Regression Testing": Connections to Component-Based Software
Bruce W. Weide
Dept. of Computer and Information Science
The Ohio State University
2015 Neil Ave. Columbus, OH 43210
Tel: (614)292-1517, fax: (614)292-2911
Email: weide@cis.ohio-state.edu
URL: http://www.cis.ohio-state.edu/rsrg
Abstract
An important problem in software testing is regression testing, which involves repeating execution of a test suite after the software has been changed to try to reveal defects introduced by the change. One reason this is important is that it is often very expensive. If the test suite is comprehensive then it can take a lot of time and resources to conduct and evaluate the new test. Some commercial vendors routinely do regression testing after even minor changes, and it is not unusual for each regression testing session to run overnight or even longer (especially if human attention is required to decide whether the software is responding appropriately). Component-based software seems to offer a possible solution to this problem because a common kind of change is for one component to be simply replaced by another. Is it possible to confine regression testing of software that has undergone such component-level maintenance to the "vicinity" of the replaced component? Or does the entire system really have to be tested again? We outline an approach to answering these questions that reinforces the importance of something we have argued before on two different grounds: Software which is not designed to support modular reasoning about its behavior is inherently fragile and costly to maintain -- including being costly to regression test.
Keywords: component-based software, modular reasoning, regression testing, software testing.
Workshop Goals: To discuss current technical problems involving component-based software with others who have thought about it for awhile.
Working Groups: Specification, testing, and verification; component-based (as opposed to generative approaches) to reuse.
1 Background
In at least four papers -- three at previous WISRs [Weide 92, Weide 93, Hollingsworth 95] and one at ICSE [Weide 95] -- we have argued that:
Our call has long been to pay close attention to these "microarchitectural" issues [Hollingsworth 95] when designing, specifying, and implementing software components and systems built from them, lest you should miss the trees for the forest of "macroarchitectural" and non-technical issues. If software itself is poorly designed at the foundational level, no amount of software architecture knowledge or tool support or managerial savvy can make that software economically maintainable.
We have based our arguments on two complementary viewpoints: first principles about good design, and observations about the difficulty of reverse engineering of poorly-designed software. Yet it is probably optimistic for us to suggest that these arguments have had any notable impact on software engineering practice. So, we're still trying to explain why the modular reasoning property is so important. The question considered in this paper is whether relating our work to the problem of regression testing of software might provide new insights that could help more people understand what we've been talking about all this time.
2 Position
Careful consideration of the problem of regression testing of component-based software, comparing situations where the modular reasoning property does and does not hold, sheds considerable light on both the importance of the property and on the kinds of design flaws that thwart it.
3 Approach
Assume you have a software system written in C++, and its "components" are simply C++ functions (which in C++ may actually be procedures, i.e., operations with side-effects on their arguments and/or global or static data). For simplicity, assume there are no classes, templates, inheritance, etc. These assumptions are convenient for this paper because it is easy to relate the scenario to actual software most people have dealt with, and because they simplify the argument yet still allow the main point to come through.
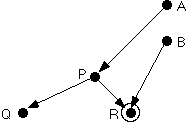
Part of such a software system is shown in Figure 1. Nodes represent C++ functions and arcs represent calling relationships; circles around nodes will be explained later. So, for example, P calls Q and R; B calls R; etc.
Now consider what happens if you change this software system by replacing P by P', leaving the situation illustrated in Figure 2. You might have made this substitution because P' (allegedly) computes exactly the same thing as P, but does it a lot faster by calling R, S, and T than by calling Q and R.
Figure1
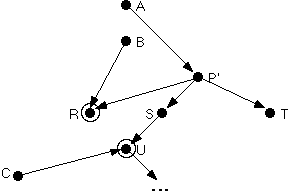
Figure 2
In an ideal world you should not have to regression test the whole system just because of this minor maintenance activity, any more than a mechanic should have to completely road-test your car on the test track just because he changed the oil. You might hope to use the following method instead:
The question is whether this approach, which we call modular regression testing, is sound. That is, if P' actually gives the same results as P for the logged calls, could a complete traditional regression test of the entire system possibly reveal any defects? If a complete traditional regression test could not reveal other defects, then modular regression testing is sound and can safely be used to achieve the same degree of confidence as a complete regression test -- and it might be far less expensive. If a complete traditional regression test might be able to reveal other defects, then you need a complete test anyway in order to gain the same degree of confidence, and modular regression testing is not sound.
3.1 One Factor Affecting the Soundness of Modular Regression Testing
After some reflection, it should be clear that there are certain conditions under which modular regression testing is sound, and other conditions under which it is not. This short paper can't get into all of them, but it is relatively easy to motivate the issues involved by considering one specific issue. Let's call a component clean if its observable behavior does not depend on any "static" data values kept privately within the component. If a component is not clean, let's call it dirty. (We don't mind the value judgments implied by this choice of terminology.) In Figures 1 and 2, dirty components are shown inside circles. For example, R might store and retrieve some information in a private temporary file that outlives a given call. U's observable behavior might depend on a static variable recording the number of times U has been invoked.
The issue here is not whether P and P' themselves are clean or dirty, but whether the components they call are clean or dirty. Both P and P' call R, which is dirty. These calls cause no problem if P and P' give identical answers to their callers. But what about other calls to R from elsewhere in the system, e.g., from B? Similarly, the indirect calls from P' to U (through S) might affect the outcomes of other calls to U, e.g., from C.
3.2 The "Expanding Module Phenomenon"
The above problems are surmountable, if you to expand the hypothetical "module boundary" through which calls are logged so the interior includes more than just P itself. You can record all calls to P (P') that cross the expanded module boundary, e.g., from A; all calls across the boundary to the dirty component R, e.g., from B; all calls across the boundary to the dirty component U, e.g., from C; and all calls across the boundary to the clean component S whose behavior depends on that of the dirty component U, e.g., from D.
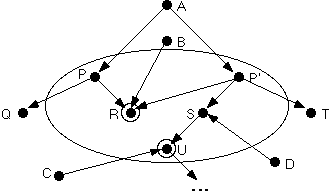
Figure 3
The expanded module boundary, shown as an oval in Figure 3, is defined by constructing all call paths starting from P and P', including within the boundary all components on each such path through the last dirty component on that path. This subassembly of (actual) components then becomes a (mythical, from the standpoint of the source code) "component". In other words, P' can't be regression-tested alone; you have to regression-test the entire expanded module induced by the proposed substitution of P' for P. Still, this might involve far less work than regression-testing the entire system.
But would it really be less work? How big is the expanded module for typical "real" software maintenance activities? We have claimed [Weide 95] that, for real programs, the modular reasoning property frequently does not hold for a given component because there are quite a few components that are dirty in the sense explained above, or in other senses (e.g., their use of visible pointers with potential aliases; reference semantics; implementation inheritance). That is, we have claimed that if you try to reverse engineer a typical software system, you will be stymied because you can't tell from information in the individual components, e.g., P and P', whether it is possible to substitute P' for P without breaking something in the far reaches of the system. Therefore, you need to look at potentially the entire system to check for possible weird interactions. The validity of this claim is an empirical question. The idea of modular regression testing suggests one way to test the claim, and even to measure it. With current rather sophisticated program analysis tools [Harrold 95] it should be possible to construct the expanded module for any proposed component-level substitution. We are currently considering how to carry out such an empirical study in an attempt to see how severe the "expanding module phenomenon" really is. Software designed to support the modular reasoning property, by contrast, simple does not suffer from this phenomenon at all.
4 Comparison
There has been plenty of interesting work recently on the difficulty of regression testing and on how to use program analysis to limit regression testing to test points that have the potential to reveal defects, e.g., [Rothermel 96, Rothermel 97, Rothermel 98]. But, to our knowledge, the proposed modular regression testing technique has not been previously suggested. Perhaps this is because it is readily apparent to those in the testing community that the idea of modular regression testing of existing software is doomed to failure because our earlier claim about the intractability of reverse engineering is essentially correct -- and this is tantamount to the unsoundness of modular regression testing as originally outlined in Section 3 above. On the other hand, even if you don't actually try to carry out modular regression testing in practice, the idea seems to shed some light on determining how well or how poorly a given software system is structured from the standpoint of the modular reasoning property.
References
[Harrold 95] Harrold, M. J., Larsen, L., Lloyd, J., Nedved, D., Page, M., Rothermel, G., Singh, M., and Smith, M., "Aristotle: a system for the development of program-analysis-based tools," Proceedings of the 33rd ACM Annual Southeast Conference, ACM, 1995, pp. 110-119.
[Hollingsworth 95] Hollingsworth, J.E., and Weide, B.W., "One Architecture Does Not Fit All: Micro-Architecture Is As Important As Macro-Architecture," Proceedings 7th Annual Workshop on Software Reuse, St. Charles, IL, August 1995, 5 pp.
[Rothermel 96] Rothermel, G., and Harrold, M. J., "Experience with regression test selection," Empirical Software Engineering Journal, Vol. 2, No. 2, 1997, pp. 78-187.
[Rothermel 97] Rothermel, G., and Harrold, M. J., "A safe, efficient algorithm for regression test selection," ACM Transactions on Software Engineering and Methodology, Vol. 6, No. 2, 1997, pp. 173-210.
[Rothermel 98] Rothermel, G., and Harrold, M. J., "Empirical studies of a safe regression test selection technique," IEEE Transactions on Software Engineering, Vol. 24, No. 6, 1998, pp. 401-419.
[Weide 92] Weide, B.W., and Hollingsworth, J.E., "Scalability of Reuse Technology to Large Systems Requires Local Certifiability," Proceedings 5th Annual Workshop on Software Reuse, Palo Alto, CA, October 1992, 7 pp.
[Weide 93] Weide, B.W., Heym, W.D., and Ogden, W.F. "Procedure calls and local certifiability of component correctness," Proceedings 6th Annual Workshop on Software Reuse, Owego, NY, October 1993, 5 pp.
[Weide 95] Weide, B.W., Heym, W.D., and Hollingsworth, J.E. "Reverse engineering of legacy code exposed," Proceedings 17th International Conference on Software Engineering, ACM, Seattle, WA, April 1995, pp. 327-331.
Biography
Bruce W. Weide is Professor of Computer and Information Science at The Ohio State University in Columbus. He received his B.S.E.E. degree from the University of Toledo and the Ph.D. in Computer Science from Carnegie Mellon University. He has been at Ohio State since 1978. Professor Weide's research interests include various aspects of reusable software components and software engineering in general: software design, formal specification and verification, data structures and algorithms, and programming language issues. He is co-director of the Reusable Software Research Group at OSU, which is responsible for the RESOLVE framework, discipline, and language for component-based software.
This work is supported by the National Science Foundation under grants DUE-9555062 and CDA-9634425, by the Fund for the Improvement of Post-Secondary Education under project number P116B60717, and by Microsoft Research. Any opinions, findings, and conclusions or recommendations expressed in this paper are those of the authors and do not necessarily reflect the views of the National Science Foundation, the U.S. Department of Education, or Microsoft.