Increasing Opportunities for Reuse through Tool and Methodology Support for Enterprise-wide Requirements Reuse and Evolution
K. Suzanne Barber, Thomas J. Graser, and Stephen R. Jernigan
The Laboratory for Intelligent Processes and Systems
The University of Texas at Austin
24th and Speedway, ENS 240
Austin, TX 78712
tel: 512-471-6152 fax: 512-471-3316
Email: barber@mail.utexas.edu
URL: http://www.lips.utexas.edu
Abstract
As more organizations attempt to reuse previous development efforts and incorporate legacy systems, typical software development activities have transitioned from unique ground-up coding efforts to the integration of new code, legacy code, and COTS implementations. This transition has brought on a whole new set of development issues, including resolving mismatches between integrated components and tracing legacy and COTS components to requirements. This paper presents the Systems Engineering Process Activities (SEPA) methodology, which SEPA aids the reuse and integration process by emphasizing support for requirements management, monitoring, and traceability. The SEPA methodology supports the development process in three main areas: (i) requirements gathering, analysis, and verification prior to design; (ii) separation of domain-based and application-based (i.e. implementation-specific) requirements; and (iii) component-based development.
Keywords: Requirements engineering, Software reuse, Software engineering methodology, CASE tools, DSSA
Workshop Goals: To discuss approaches for monitoring evolving requirements, maintaining mappings from requirements to implementations, and identifying viable portions of respective implementation reuse.
Working Groups: Tool support for requirements engineering and reuse
1 Background
As with all software development efforts, gathering, monitoring, and managing requirements is a significant aspect to a successful integration and reuse effort, and failures can often be attributed to poorly defined and poorly managed requirements. According to Alford, "In nearly every software project which fails to meet performance and cost goals, requirements inadequacies play a major and expensive role in project failure" . While development of a requirements specification seems trivial in many cases, it is probably the part of the process which leads to more failures than any other . The process of gathering, managing, and analyzing requirements has a direct affect on the cost of system development, integration, and subsequent maintenance. In fact, the need for maintenance can be attributed to (i) the satisfaction of evolving user requirements and (ii) changes needed in a software implementation to address requirements not addressed in original delivery. The root of the latter lies in poor requirements gathering and analysis and an untraceable translation from requirements to a system design. Inadequate verification and validation often fail to detect delivered systems that fall short of their intended purpose. In most domains, the evolution of user requirements is inevitable. Changes in requirements often occur during system development that are not reflected in the final product. Needs may also change after system development, as the benefits of new technologies are recognized and domain processes evolve.
2 Position
Large scale code reuse is not practical without a corresponding reuse of the requirements from which the code was created. By emphasizing requirements reuse (e.g. artifacts from requirements gathering and analysis activities) the developer increases chances for implementation (e.g. code, COTS tools) reuse since individual requirements often map to large portions of an implementation. However, while requirements reuse is often suggested, current methodology and tool support is lacking in this area.
3 Approach
To increase the opportunities for reuse, developers should consider reuse of artifacts throughout the analysis, design, and implementation phases -- the opportunities for reuse are vast and should not be limited to code alone. The U.S. Department of Defense suggests that coding should only consume about 10% to 15% of total software development time, so an emphasis on analysis and design reuse is more profitable. While code reuse typically occurs only at lower-level system design artifacts, analysis and design reuse often results in whole collections of related artifacts being reused . Methodologies can further increase odds for reuse by identifying potential reuse at all system levels (e.g. entire system, subsystem, code function) and among all participating elements (e.g. new development, legacy systems, and COTS components). To achieve this degree of reuse among what are often incompatible implementations and architectures suggests making reuse a reality at a higher, more abstract level.
3.1 Requirements Reuse in System Integration
The integration effort which represents a large part of today's component-based software development typically falls into one of the following scenarios:
COTS integration from multiple developers. The development environment has moved beyond sole source component solutions.
COTS integration with new customized portions. Systems are often a hybrid of COTS portions and customized portions, where business logic is added to custom components that take advantage of basic services (e.g. word processing, data storage) provided by COTS components.
Integration of legacy, COTS, and new components. Many businesses have a large investment in existing, legacy systems that have a proven record of enabling essential business processes. It is often cost prohibitive to rebuild these systems, yet new functionality must be incorporated.
The difficulty in integrating disparate components has been a significant barrier to realizing code reuse on a large scale . With the difficulty encountered in integration, each new system often becomes as much a new invention as if it had been created from scratch. As a result, programmers often assume that writing their own code is easier than integrating someone else's code. Typical issues aggravating the integration effort include the following:
Current methodologies lack the ability to reuse requirements in determining if intended end-user needs for a new system are similar to those of a previously developed system or portions of new requirements are related to portions/components of previously developed systems.
Current methodologies lack the ability to reuse analysis, design, and code artifacts from previous implementations.
It is a rare opportunity when new systems can be developed entirely from COTS software components designed for seamless integration. The addition of "glue code" is typically necessary to aid integration. While the use of COTS components may reduce programming effort, this additional level of effort represents value added which must be factored into the total cost in development.
3.2 Monitoring Requirements Evolution to Facilitate Reuse
When requirements are established, they reflect the needs of the domain, organization, and specific implementation. However, these needs continue to evolve. Therefore, a methodology and its associated tools should support a parallel "requirements evolution" process. Given that requirements guide the implementation process, it should be possible to trace an implementation back to requirements. As requirements evolve, tool support can allow the corresponding traces to implementations to be carried along, providing guidance as to how the old implementation may satisfy new requirements. Further, the set of new requirements which are not addressed by old requirements provide an indication as to the degree of rework required (expressed in requirements) and guide additional development. Factoring in requirements evolution as an integral part of system development and maintenance, the development cycle becomes an issue of integration on two levels:
mapping, evolving, and integrating requirements previously gathered, analyzed, and verified into new requirements and
integrating technologies inferred by the traceability links from integrated requirements.
3.3 Support for Integration and Requirements Reuse in the Systems Engineering Process Activities (SEPA)
The Systems Engineering Process Activities (SEPA), developed at the Laboratory for Intelligent Process and Systems at the University of Texas at Austin, builds upon both the Domain-Specific Software Architectures (DSSA) methodology and popular object-oriented (OO) approaches by focusing on knowledge engineering activities critical for effective domain analysis. DSSA is a joint industry/university research effort which was initiated to demonstrate the benefits of large-scale component-based software reuse within the avionics domain by creating a multi-media workstation-based, process-oriented, software composition environment that uses constraint-based reasoning to assist the user in application generation and verification . Similar to DSSA, SEPA highlights the need to distinguish between domain requirements (e.g. the primary task of a Payroll Dept. is to issue payroll warrants) and application requirements (e.g. all payroll warrants must be processed within 8 hours), while also promoting the identification and specification of appropriate "domain components" and corresponding "technology solutions." Domain components represent an object-oriented partitioning of domain tasks (e.g. issue payroll warrants) across responsible parties (e.g. "Payroll Issuer") without designating a particular implementation. To realize an actual system implementation, the system designer must select appropriate technology solutions based on application requirements to satisfy chosen domain components based on domain requirements. A technology solution need not be a hardware or software implementation; the most appropriate solution may be an individual playing the role of a domain component (e.g. Fred Smith is best selection as a "Payroll Issuer" because he is able to process all payroll in less than 8 hours).
Object-oriented development provides widely acknowledged benefits such as the reuse of existing code, extensibility, and simplified maintenance. Object-oriented analysis (OOA) focuses on "what" must be done while object-oriented design (OOD) focuses on "how" it is done. The importance of this distinction is that "what" an object does is less dynamic over time than "how" the object does it. SEPA borrows and extends this "what vs. how" phenomenon to defining domain components and identifying applicable technology solutions. Domain requirements are quite stable and relatively resilient to technological changes, while application requirements are more dynamic and exhibit a greater degree of vulnerability to changes in technology. By representing the requirements separately, the analysis of the more stable domain requirements can be reused in future development efforts.
SEPA extends DSSA by formalizing the analysis and design methodology and providing tool support throughout the process. For example, the SEPA tools aid the process of gathering and representing requirements knowledge and accommodate the coexistence of contrasting (and often conflicting) requirement perspectives. These contrasting perspectives are subsequently unified and used to derive domain-based components and specific application requirements. Decisions made by the design engineer during tool usage are captured and provide traceability throughout the entire SEPA process.
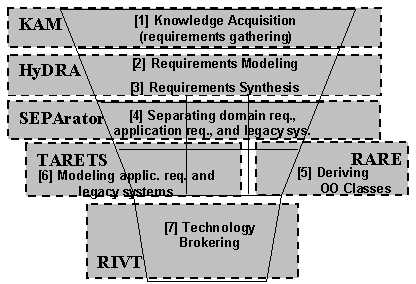
The SEPA funnel (Figure 1) depicts how user requirements are gathered, narrowed, refined, and structured into a component-based system design specification. The SEPA methodology and tool suite provide integrated support for the following activities in the development cycle:
Figure 1: SEPA Methodology Activities Funnel and Supporting Tools
4 Comparison
As with methodologies, tool suites should support the entire analysis, design, development, and maintenance as seamlessly as possible. While commercial tools have done an adequate job of addressing the latter half of this lifecycle, support for requirements gathering and analysis has been limited. Available tools emphasize system design and code generation since the business case has been established in the area and developers can reap immediate benefits.
A similar research effort that aligns with SEPA's is the ADAGE tool suite supporting the DSSA methodology. ADAGE tools have had success with domain component representation and subsequent component-based code generation. Less emphasis has been placed on supporting requirements gathering and analysis. Future collaborations will leverage SEPA's support for requirements gathering and analysis, object-oriented component derivation, and requirements traceability with ADAGE's support for component representation and code generation.
References
[1] M. Alford and J. Lawson, "Software Requirements Engineering Methodology (Development)," U.S. Air Force Rome Air Development Center RADC-TR-79-168, June 1979 1979.
[2] M. Dorfman, "Requirements Engineering," in Software Requirements, R. H. Thayer and M. Dorfman, Eds. Los Alamitos, CA: IEEE Computer Society Press, 1997, pp. 7-21.
[3] U. S. Department of Defense, "Guidelines for Successful Acquisition and Management of Software-Intensive Systems," Department of the Air Force, Software Technology Support Center 1996.
[4] D. Garlan, R. Allen, and J. Ockerbloom, "Architectural Mismatch or, Why it's hard to build systems out of existing parts," presented at 17th International Conference on Software Engineering, Seattle, Washington, 1995.
[5] W. Tracz, "DSSA (Domain Specific Software Architecture) Pedagogical Example," ACM SIGSOFT Software Engineering Notes, vol. 20, pp. 49-62, 1995.
[6] Rational, "Unified Modeling Language," http://www.rational.com/uml: Rational Software Corporation, 1998.
[7] Verilog, "Verilog ObjectGEODE," . http://www.verilogusa.com/home.htm, 1997.
[8] D. Harel, "STATEMATE: A working environment for the development of Complex Reactive Systems," in Software State-of-the-Art: Selected Papers, T. DeMarco and T. Lister, Eds. New York: Dorset House, 1990, pp. 322-338.
[9] W. Tracz, "What is ADAGE?," . http://www.owego.com/dssa/adage/1.html, 1995.
Biography
K. Suzanne Barber (barber@lips.utexas.edu), http://www.lips.utexas.edu
Dr. Barber established the Laboratory for Intelligent Processes and Systems at UT-Austin in 1992. Her current research examines 1) formal systems and software engineering analysis & design methodologies, modeling techniques, and tools, 2) distributed, knowledge-based planning and control systems, and 3) knowledge representations. The research focuses on the development of domain-specific component-based systems and the realization of distributed, autonomous agent-based systems. The Domain Specific System Architectures course, developed by Dr. Barber, highlights those systems engineering approaches employed in her research efforts.
Dr. Barber began her career at The Robotics Institute at Carnegie Mellon University where her research resulted in a language and user interface, providing semantics and teaching strategies enabling interactive human-to-machine communication during the definition and performance of robotic assembly tasks. She later joined the Automation and Robotics Research Institute (ARRI) where her research results included an object-oriented system encapsulating design information and application behavior specifications to adaptively plan manufacturing tasks. Dr. Barber actively collaborates with NCMS, NIST, NSF, and DoD research programs and is a member of IEEE, AAAI, ACM, and ASEE.