Bill Frakes
Virginia Tech
Computer Science Department
Falls Church, VA 22042
Tel: (703) 698-4712
Fax: (703) 698-6062
Email:
wfrakes@vt.edu
Domain engineering is central to systematic reuse. Is it possible to automate this complex process? This paper discusses this question and provides a basis for the working group on domain engineering tools.
Keywords: Domain Analysis, Domain Implementation, Tools, CASE
Workshop Goals: Discuss, Summarize, Exchange, Record, Advance
Working Groups: Domain Engineering Tools
Domain engineering can be automated in part.
Introduction
Engineering progress often involves making the work of unusually capable people more routine so that can it be done by average people. This is done by defining a repeatable process, and automating as much of the process as possible. Compiler development is a case of this. Unusually capable people were required to build early compilers and to develop the theory of compiler design. Once this was done, however, the compiler building process was routinized and many aspects of it, such as lexical analysis and parsing, were automated. The result is that today average software engineers can create compilers. Can the same happen in domain engineering?
Domain engineering has two phases; domain analysis and domain implementation. To make domain engineering routine, we will need repeatable processes for domain analysis and implementation. Is this possible? Lets look first at domain analysis.
Domain Analysis
Several years ago, Don Batory remarked that he thought it would be impossible to have a repeatable process for domain analysis since domain analysis was essentially the same as scientific discovery, which had never been reduced to a reliable step by step process. While this is certainly true, some work on the automatic identification of scientific laws has been reported[1]. On the other hand, attempts to build intelligent automated statistical analyzers largely failed[2]. Herbert Simon speculates that this may be because the input data for statistical analysis is noisy, while the scientific law data is much less so. It may be fruitful to reflect on the noisiness of typical input data for domain analysis.
Today, there are several methods proposed for domain analysis (see [3][4] for a review) including FODA, DARE, ODM, and DSSA. Though the methods are similar, they vary in their terms, notations, and emphases. In this they are similar to software design methods. They may also be as vague as design methods' about how to actually do the task at hand. The "magic happens" aspect of design is well known, and CASE tools for design reflect this, being largely drafting and database tools. There is still a lot of "magic happens" in the domain analysis process as well.
Domain analysis methods are still evolving. They seem to progress according to a simple generate and test method in which the methods' creators posit a method, test it in the field, and then modify it based on their experience.
In the DARE project, we tried to see how much of domain analysis we could automate. What we found was that we could create a repeatable process for some of domain analysis, and automate it. For other parts we could not. Much of the text analysis thread of DARE, for example, can be automated, but the actual creation of a generic architecture by integrating domain information still requires a good human domain analyst--"magic happens".
Domain Implementation
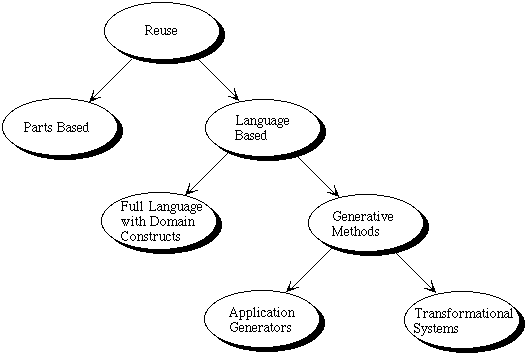
The diagram below shows the various technical approaches to reuse. Much of the work on domain implementation has focused on methods for creating reusable parts, and on methods for creating application generators and meta-generators.
On the parts side, a lot of good work has been done on design, though it seems impossible to say exactly what properties a reusable part must have, and no detailed general theory of reuse design has yet emerged. On the other hand, the commercial market for parts has boomed, driven by developments in C++, Visual Basic, and Java.
Many generators such as draco, genesis, avoca, etc have been reported as have generator creation tools such as metatool and refine (these were reviewed in [5]). The following diagram is a high level generic architecture for generators.
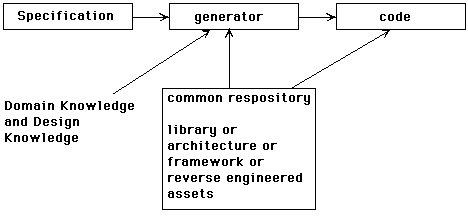
For generators a theory may have emerged based on analysis of tools like genesis and avoca, though this covers only a subset of generative and transformational technology.
Integration of DA and DI
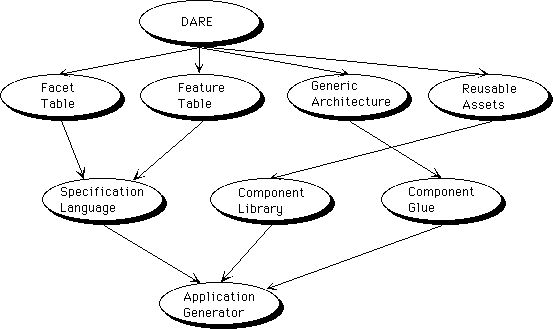
The last piece of automating domain engineering is to combine the domain analysis and domain implementation phases into a coherent whole. This will involve mapping domain analysis outputs to domain implementation inputs, as a first step to integrating the tools for each. Some early work on this had been reported[6] which mapped the outputs of DARE to the inputs of Metatool as can be seen in the figure below. For example information from facet tables and feature tables in DARE are used as inputs to Metatool's specification language.
1. Langley, P., et al., Scientific Discovery: Computational Explorations of the Creative Processes. 1987, Cambridge, MA: M.I.T. Press.
2. Gale, W.A., Artificial Intelligence and Statistics. 1986, Reading, MA: Addison-Wesley.
3. Arango, G., Domain Analysis Methods, in Software Reusability, W. Schaefer, R. Prieto-Diaz, andM. Matsumoto, Editor. 1994, Ellis Horwood: New York.
4. Wartik, S. and R. Prieto-Diaz, Criteria for Comparing Reuse-Oriented Domain Analysis Approaches. International Journal of Software Engineering and Knowledge Engineering, 1992. (Oct.).
5. Devanbu, P. and W. Frakes, Generative Techniques for Reuse. Tutorial at ICSR-2, Lucca, Italy, 1993.
6. Devanbu, P. and W. Frakes, Introduction to Domain Analysis and Domain Engineering, Tutorial at ICSR-4, Orlando, FL. 1996.