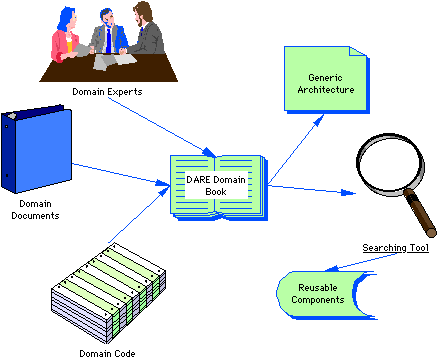
Figure 1: DARE Domain Analysis Process
Software Engineering Guild
Sterling, VA 20165 USA
Email:
wfrakes@vt.edu
Ruben Prieto-Diaz
Reuse Inc.
Fairfax, VA 22033 USA
Email:
70410.1176@compuserve.com
Chris Fox
Computer Science Dept.
James Madison U.
Email:
fox@mutt.cs.jmu.edu
DARE users produce a Domain Analysis Book that contains all domain analysis inputs, outputs, and supporting material (table of contents, index, glossary, citations, and so forth).
Figure
1: DARE Domain Analysis Process
Figure 1 is a graphical summary of DARE's process model. There are three major components to the domain analysis process--document analysis, code analysis, and analysis of domain expert information.
Domain documents are processed using sophisticated information retrieval procedures which help the analyst extract important domain concepts.
Information from code sources is derived with static analysis tools. This program structure information is used for commonality analysis--the identification of common parts and structures of the various systems in the domain. Knowledge from domain experts is captured via a multi-stage knowledge acquisition process that yields generic architectures--architectures that describe the commonalities and variabilities of systems in a domain.
All domain information is stored in a database. Users interact with the database via a windowed interface to extract and analyze data about domains. DARE is implemented in C under UNIX and Motif on a Sun Sparcstation.
We have made several observations about domain analysis while developing DARE. The primary purpose of domain analysis is to develop a generic architecture for a domain. This is a complex intellectual task, and we would like to use information from software and document artifacts in the domain to guide the process, as described above. The problem is that software and document artifacts represent the solution space while domain architectures represent the problem space. The solution space artifacts are often at a much lower level of abstraction that needed in the domain generic architecture.
Consider, for example, trying to extract high level architecture information from C code. There are good tools such as cflow, cscope, and CIA for analyzing the code. The problem is that the units of analysis will be tokens, lines of code, function, and dot-c and dot-h files. Information at this level may be indicative, but it is unlikely to directly map to the high level architectural structures in a domain generic architecture.
The same is true of the structures that can be extracted from textual documents in the domain. Structures such as conceptual clusters and facet templates can be used as evidence for architectural structure, but are unlikely to provide the architectural structure directly. Thus, the extraction of domain information from domain experts is of primary importance.
DARE's expert support tool captures and organizes domain expert knowledge into a text compatible format. Although conceptually simple at a high level, defining and specifying how it should work and what the inputs and outputs are is challenging. After considering several alternatives to its scope and implementation, we decided to make this tool simple and easy to use by domain experts and analysts. Rather than concentrating on elaborate AI techniques (i.e., production rules, frames, inference engines, knowledge base) our tool will rely on asking experts to define a generic architecture for the domain. The definition of the generic architecture is captured by answering specific questionnaires and by the expert drawing an architecture directly into DARE.
This approach, complemented by a method and examples, will provide the domain analyst with alternative domain architectures generated by different experts. The main goal of the expert support tool is to help the analyst postulate an initial domain architecture. In the first step, the experts define specific systems with which they are familiar. The information about specific systems is captured in a questionnaire. Answers include a system architecture and domain architecture components. Experts are then asked to provide domain information including a domain architecture. The analyst analyzes the information provided by the experts and postulates a generic architecture. Although this process is method intensive rather than tool intensive, DARE provides the basic support for organizing and structuring the information to facilitate the tasks.
After the system and domain questionnaires have been defined. The tool will ask the expert to enter the answers using formatted screens. Questions are of two categories: those requiring specific values (i.e., What platform is used?) and open questions (e.g.., describe the functionality of the system.) Specific questions will have a pop-up window with a list of all possible answers. This will force experts to select one value from a controlled vocabulary resulting in normalized responses. Open questions will be in text form and processed as text input by the text analysis tool.
We ran a small test of the approach. Two people acted as experts, one each for different metrics tools: ccount and RL. Both systems are functionally similar, but have different implementations and use different approaches. Each expert went through the system and domain questionnaires, and each produced a high level domain architecture. Two other subjects played the role of domain analysts and consolidated the experts' response into a generic architecture for metrics tools, highlighting similarities and variabilities. Variabilities were captured as potential parameters. The test suggested that the approach we are taking is viable.
Bios
Bill Frakes , is president of the Software Engineering Guild, and is an associate professor of Computer Science at Virginia Tech. He has been manager of the Software Reuse Research Group at the Software Productivity Consortium, and supervisor of the Intelligent Systems Research Group at AT&T Bell Laboratories. He is author of Software Engineering in the UNIX/C Environment (Prentice-Hall, 1991), and Information Retrieval: Data Structures and Algorithms (Prentice-Hall, 1992), and Third International Conference on Software Reuse : advances in software reusability ( IEEE CS Press, 1994). He chairs the IEEE TCSE committee on software reuse, was general chair of the Third International Conference on Software Reuse, and was co-editor of the IEEE Software special issue on systematic reuse (Sept. 1994).
Ruben Prieto-Diaz is president of Reuse Inc. He has been principal member of the Software Reuse and Measurement Group at the Software Productivity Consortium, principal scientist at The Contel Technology Center, and a senior member of the technical staff at GTE Laboratories where he was principal architect of the GTE Asset Library System. He is author of Domain Analysis and Software Systems Modeling (IEEE CS Press, 1991), and developer of a domain analysis method currently used by STARS. Ruben was the keynote speaker at the recent Software Reuse Symposium in Seattle.
Chris Fox is associate professor of computer science at James Madison U. He has been a distinguished member of the technical staff at AT&T Bell Laboratories, and manager of software research and development at Lockheed. He is the author of Information and Misinformation (Greenwood Press, 1982), and author of Software Engineering in the UNIX/C Environment (Prentice-Hall, 1991). He has an M.S. from Michigan State and an M.S. and Ph.D. from Syracuse University.