
The CAPS software base stores components in an object-oriented database and uses PSDL specifications as the basis for high recall queries. Each stored component consists of a PSDL specification, a PSDL description of the implementation, the implementation code, and a normalized version of the PSDL specification. The syntax and semantics of the PSDL specification are used to direct the search for a component.
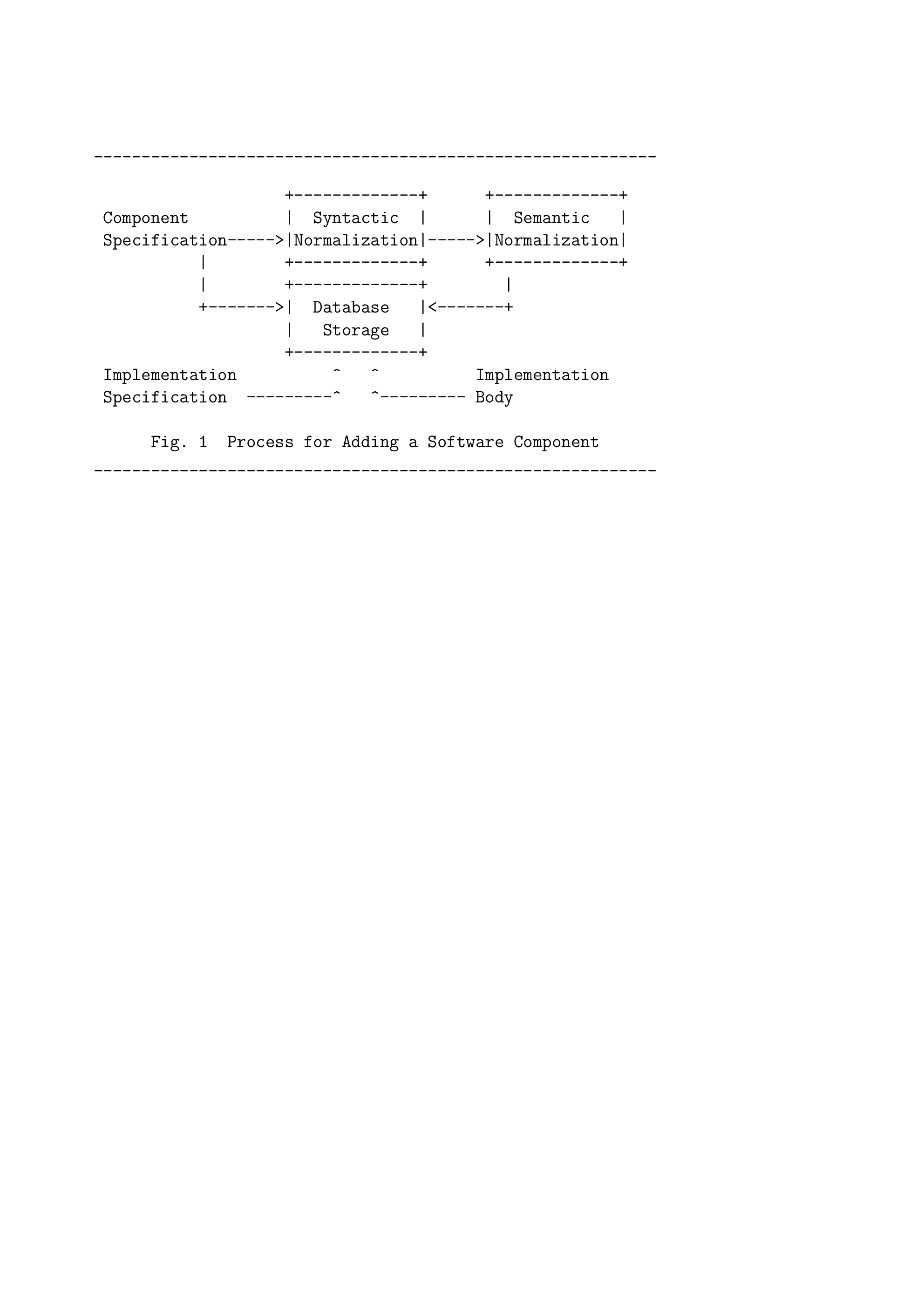
Figures 1 and 2 summarize the steps necessary to store components in the software base and to retrieve them using a given query specification. Components to be stored must first pass through syntactic and semantic normalization (see Figure 1). The normalization processes transform the component's PSDL specification to facilitate later matching. Syntactic normalization involves primarily format changes and statistical calculations while semantic normalization involves specification expansion and transformations.
Figure 2 shows the general process for component retrieval. A query for a library component is formed by constructing the PSDL specification for the desired component. The query specification is syntactically and semantically normalized and then matched against the stored specifications.
The retrieval process starts with a faceted classification step in which attributes that are derived from the PSDL specification are used as a multi-attribute index to select a subset of the database to serve as the starting point for the rest of the process. A major difference between the CAPS approach and other systems that use multi-attribute searches is that the attribute values are derived from the formal specification by a repeatable and completely automatic process. This ensures that components are eliminated from consideration only if they could not possibly satisfy the query.
After selection of a database partition based on the multi-attribute index, the partition is exhaustively scanned and passed through the syntactic matching filter.
The components that remain are then passed through several semantic matching filters. Syntactic matching of the query component takes place before semantic matching because syntactic matching is faster than semantic matching and is used to partition the software base quickly in order to narrow the list of possible candidates that the semantic matching algorithm must consider. Semantic matching is time consuming and must be applied to as small a candidate list as possible.
The main benefit of syntactic matching is speed whereas the advantage of semantic matching is accuracy. Accuracy is required in order to reduce the number of reusable components that a designer will have to evaluate before making a selection. Many functions or types with different behaviors can have syntactically identical interfaces. Clearly we cannot rely on syntax alone to provide us a sufficiently fine grained search.
A semantic process alone would be unacceptable because semantic matching would have to be applied to every software base component causing the search process to be impractically time consuming. For a more detailed discussion of the semantic matching mechanisms used by the software base see [Stei 91].